EP47. 聯發科 212.5G SerDes 架構解析

Google 於 2026 年針對資料中心基礎設施進行重大架構轉型,首度針對 AI 晶片導入「訓練」與「推論」雙軌分流的解耦式設計 。其中,專為高併發推論最佳化的 TPU v8i (Zebrafish) 採用了聯發科 (MediaTek) 的高速 SerDes 方案,此舉打破了過去由單一供應商壟斷的局面,進而優化了硬體佈署的總體擁有成本 (TCO) 與功耗表現 。
本報告彙整 ISSCC 2025/2026 與 DesignCon 2026 中,MTK發表的技術文獻,剖析 212.5 Gb/s (224G 世代) PAM4 SerDes 收發器的核心架構。探討在 3nm/4nm 先進製程下,收發器架構為何全面轉向以數位訊號處理 (DSP) 為中心 。同時,針對超高速傳輸在封裝至電路板 (Package-to-PCB) 介面所面臨的插入損耗 (Insertion Loss) 與串擾 (Crosstalk) 等訊號完整性 (SI) 挑戰,解析聯發科提出的實體層陣列佈局與高密度互連解決方案 。
1. Background
1.1. Google v8t and v8i
Google 今年推出的 TPU v8,標誌著其資料中心基礎設施的重大架構轉變。面對日趨複雜的 AI 工作負載,Google 揚棄了過去單一晶片架構的策略,首度導入「訓練」與「推論」雙軌分流的解耦式 (Disaggregated) 設計,以分別最佳化效能與總體擁有成本 (TCO)(請參考: EP26. Google Ironwood)。
雙軌硬體定義 (Dual-Track Architecture)
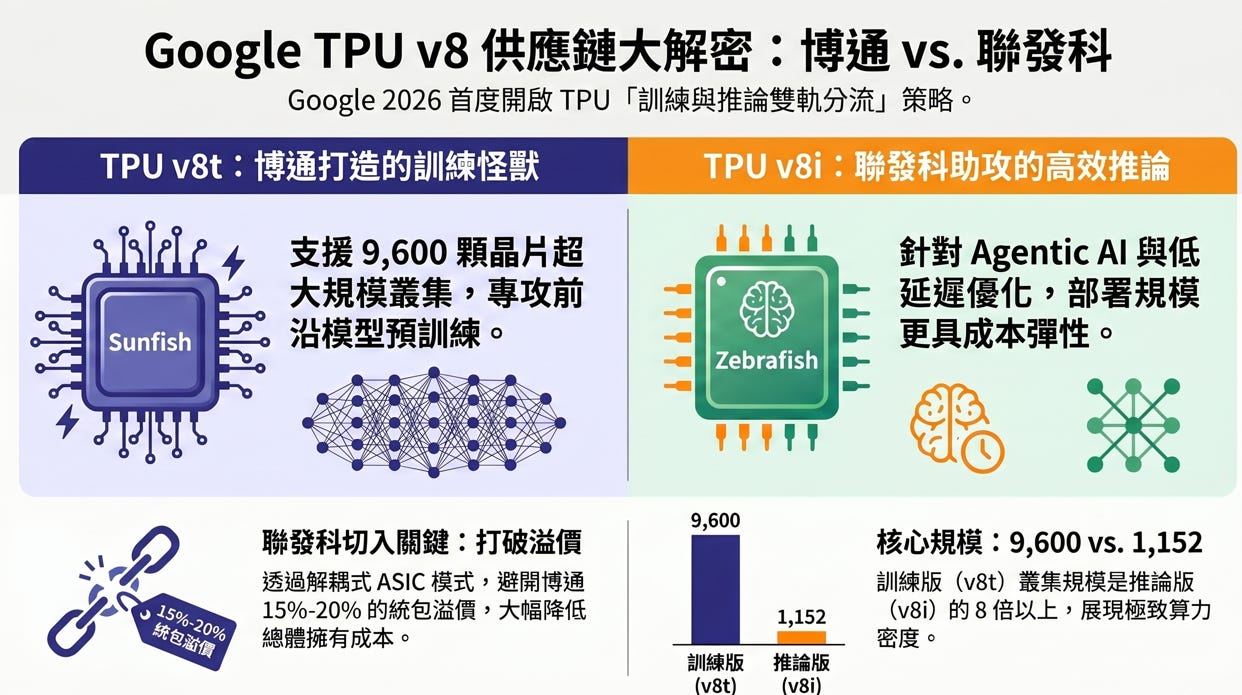
TPU v8t (Sunfish - 訓練專用): 針對大規模模型預訓練與重度嵌入 (Embedding-heavy) 工作負載開發。架構核心著重於建構超大型 Scale-up 網域,叢集規模上限達 9,600 顆晶片。此設計旨在提供高算力密度,確保訓練過程中龐大的參數同步與梯度更新能高效執行。
TPU v8i (Zebrafish - 推論專用): 專為 Agentic AI 及高併發 (High-concurrency) 推論任務最佳化。架構上仍然維持以專屬協定進行 Scale-up 互連,但將單一叢集的規模上限調整為 1,152 顆晶片。確保推論低延遲運算的同時,顯著提升硬體佈署的成本彈性與功耗表現。
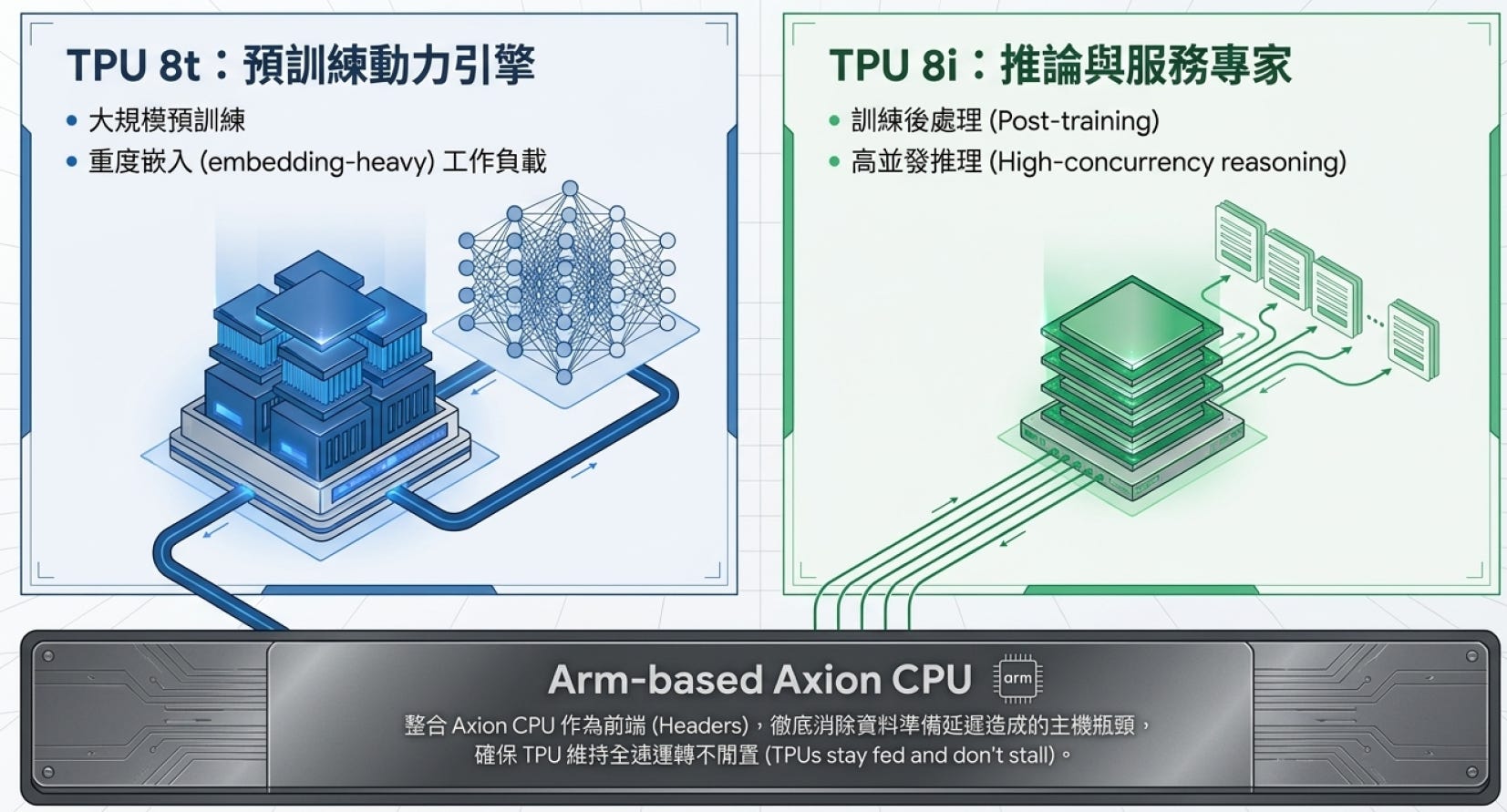
系統級瓶頸消除:Axion CPU 前端整合
無論是 v8t 或 v8i,皆整合了 Arm-based Axion CPU 作為前端 (Headers)。此舉將資料準備 (Data Preparation) 與預處理的工作從 Host 端下放,確保高頻寬的網路不會因為前端 CPU 處理延遲而產生閒置 (Stall),使 TPU 運算管線能維持全速運轉。
供應鏈與 I/O 開發策略 (Broadcom vs. MediaTek)
Google 將晶片的「運算核心 (TensorCore 等)」與「實體層 I/O」拆分。核心邏輯由 Google 自研,而至關重要的 ICI 實體層則依據應用場景,交由兩家廠商各自發揮:
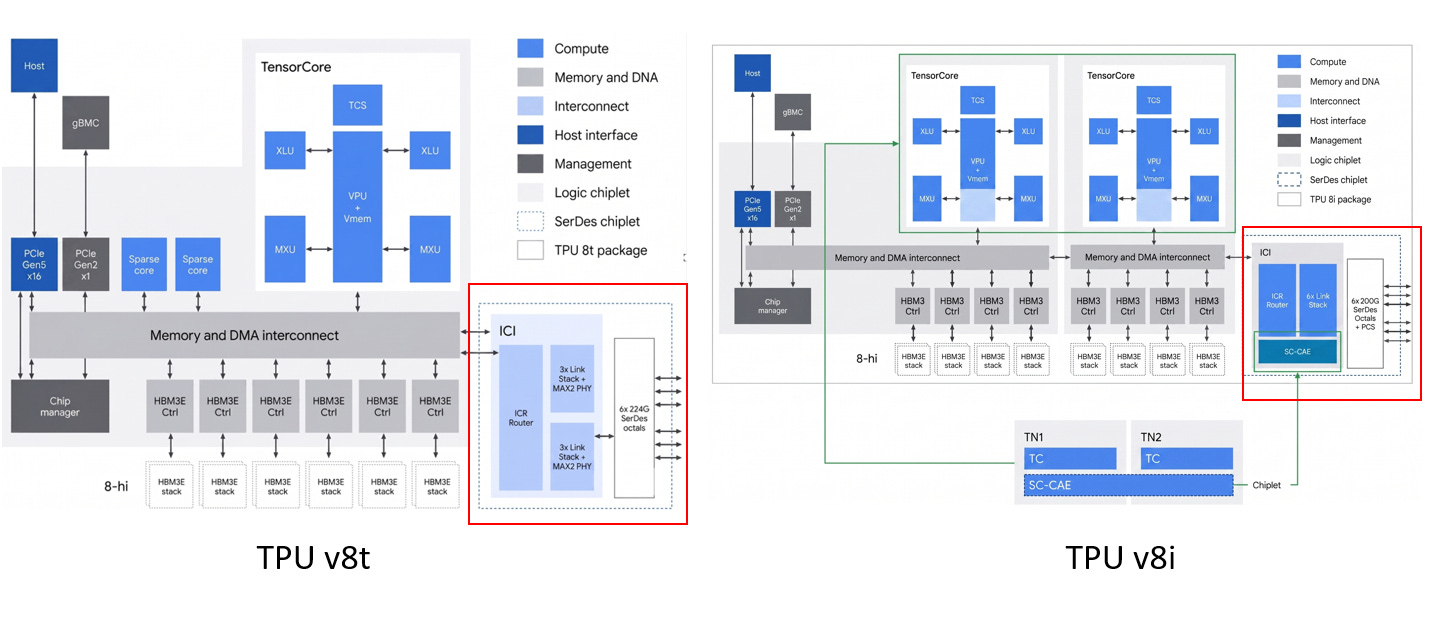
ICI 架構設計差異 (v8t vs. v8i)
ICI (Inter-Core Interconnect) 的關鍵地位
專屬協定: 採用 Google 自家通訊協定,專為 AI 模型訓練的高頻寬、低延遲資料交換而設計。但SerDes IP (由 Broadcom 與 MediaTek 開發) 遵循 OIF CEI 與 IEEE 的物理規範
算力底層: 直接決定單一叢集 (Scale-up) 的規模上限,且在晶片設計上佔據極大的實體面積與運作功耗。
source: Google
雙軌供應鏈分工 (BRCM vs. MTK)
Broadcom (負責 v8t 訓練端): 提供業界頂規的 224G SerDes,專注於極限效能與長距離訊號穩定,支援高達 9,600 顆晶片的超大叢集。
MediaTek (負責 v8i 推論端): 透過最佳化的低功耗 200G SerDes 與小晶片封裝技術,支援 1,152 顆晶片叢集。此舉打破單一供應商壟斷,大幅優化推論場景的總體擁有成本 (TCO) 與能效比。
1.2. 200Gbps 標準制定
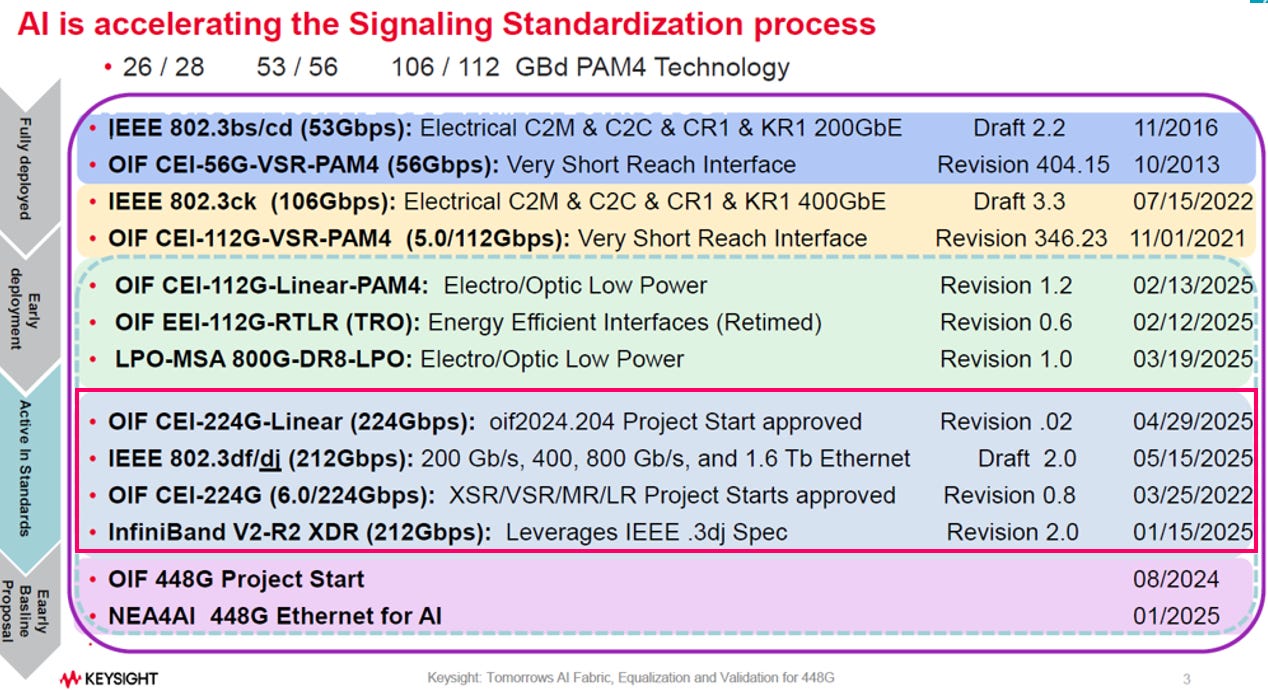
針對 200G (224Gbps) 世代的標準制定,OIF、IEEE 與 InfiniBand 三大組織呈現的高度互賴關係(請參考:EP30. Ethernet Update )
source: Keysight
OIF (奠定物理基礎):
專注於最底層的電氣實體層 (CEI, Common Electrical Interface) 規範。負責定義晶片與模組間各類傳輸距離 (從極短距 XSR 到長距 LR) 的物理邊界,並同時推進傳統 Retimed 與低功耗 Linear 直驅技術。
IEEE (制定系統標準):
建構於實體層物理可行性之上,主導完整的乙太網路系統協定 (如 802.3dj)。負責規範媒體存取控制 (MAC)、實體編碼 (PCS) 與前向錯誤更正 (FEC),將底層訊號封裝為 1.6T 規模的網路架構標準。
InfiniBand (硬體生態收斂):
在 200G (XDR) 節點產生重大策略轉變,放棄獨立開發底層物理規格,轉而直接沿用 IEEE 802.3dj 規範。此舉使其能完全共用乙太網路的硬體與光模組生態系以降低成本,同時保留自身上層低延遲專屬協定的優勢。
OIF 確立了 224G 電氣訊號的物理邊界;IEEE 將其封裝為可大規模部署的 1.6T 乙太網路系統標準;而 InfiniBand 則務實地採納了 IEEE 的實體層規範以降低硬體開發成本。
200G vs. 212.5G :
邏輯速率 (200 Gbps) 與底層實體線速 (212.5 Gbps) 之間的落差,來自於維持高速訊號完整性所需的通訊協定開銷 (Protocol Overhead):
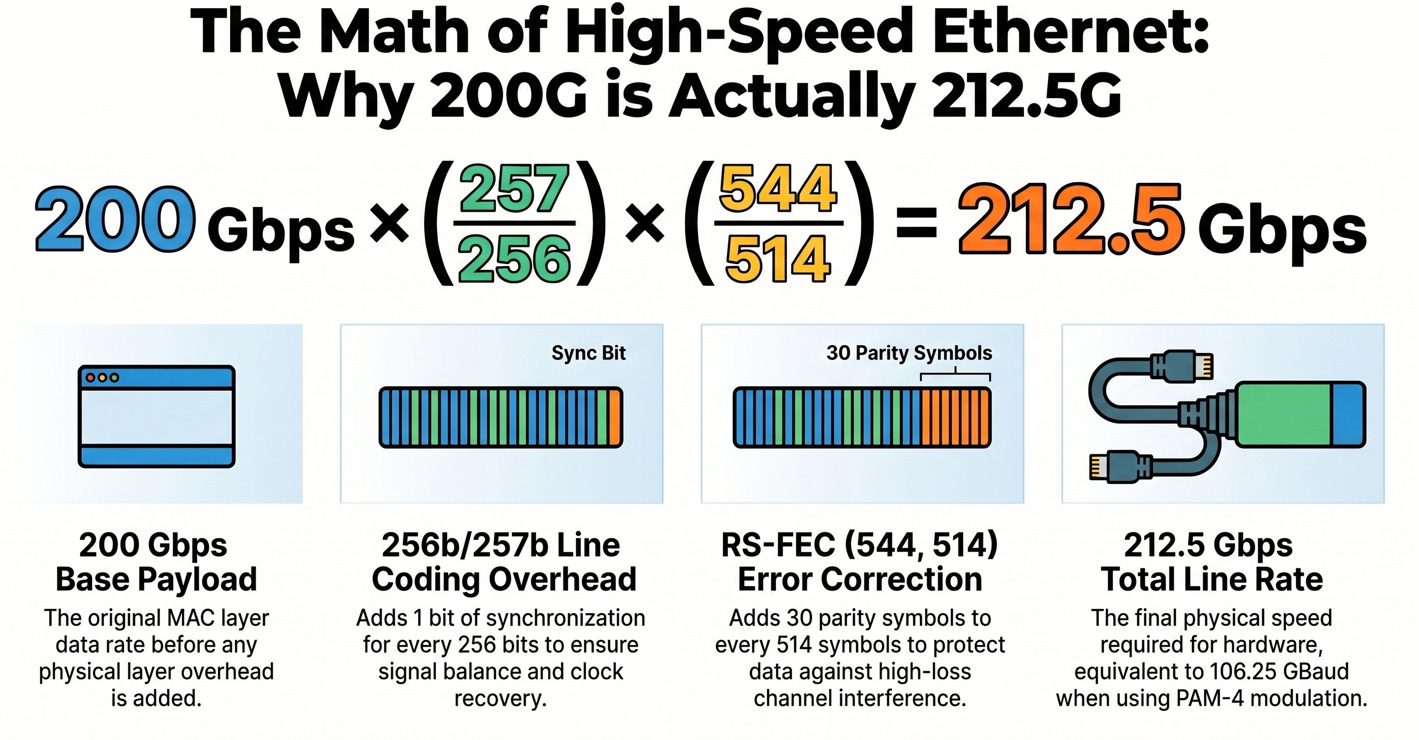
在此 212.5 Gbps 的線速下,搭配 PAM4 調變技術 (每個符號 2 bits),硬體底層真實面對的物理指標為 106.25 GBaud (符號率) 與 53.125 GHz (Nyquist 頻率)。因此,底層硬體與通道設計皆是以 212 Gbps 等級作為基準,而非 200 Gbps
1.3. DSP based Transceiver Design
200G+ (即 224G 世代) 標誌著 SerDes 設計哲學的根本性重構:「物理極限」與「半導體製程微縮」共同驅動的典範轉移,收發器 (TRX) 架構將全面轉向 DSP 架構(請參考: EP23. 448G SerDes)。
收發器 (TRX) 架構的本質轉變:
從新舊 SerDes 架構方塊圖的對比可以發現,傳統依賴類比電路處理訊號的時代已經過去:
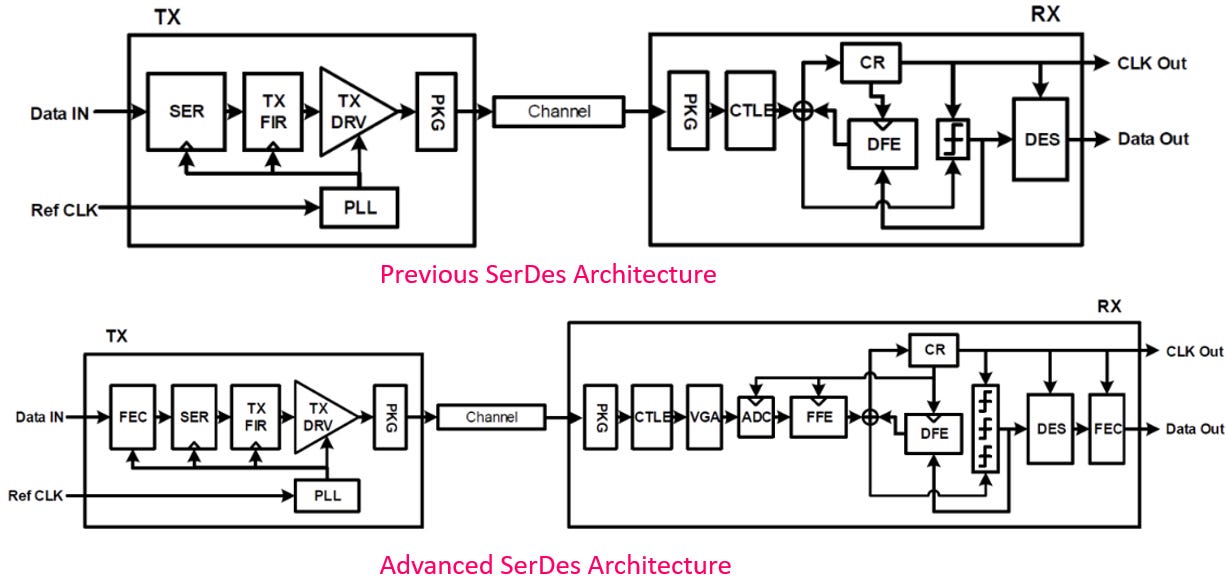
傳統架構 (Analog/DSP mixed): 過去的接收端 (RX) 高度仰賴類比領域的等化器 (如 CTLE 與類比 DFE) 來補償訊號,最後才進行取樣。
先進架構 (Advanced DSP-centric): 200G+ 的設計在 RX 端的極早期就導入了 ADC (類比數位轉換器)。訊號經過初步放大 (VGA/CTLE) 後立刻被數位化。隨後繁重的等化工作 (如 FFE 與 DFE) 以及時脈恢復 (CR),全部轉交給強大的 DSP 在數位領域中進行運算。同時,FEC (前向錯誤更正) 也更深地整合進 TX 與 RX 的資料鏈路中。
物理通道損耗的極限:為何非 DSP 不可?
OIF CEI 的演進表揭示了物理現實:

source: DesignCon26
在 224G 世代 (對應 112 GBaud PAM4),其 Nyquist 頻率高達 56 GHz。
在 56 GHz 的高頻下,即便只是 1 公尺的銅纜,其插入損耗 (Insertion Loss) 也高達驚人的 40 dB。
傳統的類比等化器根本無法處理如此嚴重的訊號衰減、通道反射 (Reflection) 與串擾雜訊。只有高解析度 (如 7b DAC/ADC) 配合 DSP 強大的演算法 (如複雜的非線性補償),才能從這 40 dB 的損耗泥沼中還原出正確的訊號 (達到 1x10-4 的 Pre-FEC BER 目標)。
先進製程 (3nm/4nm) 的微縮經濟學:數位紅利
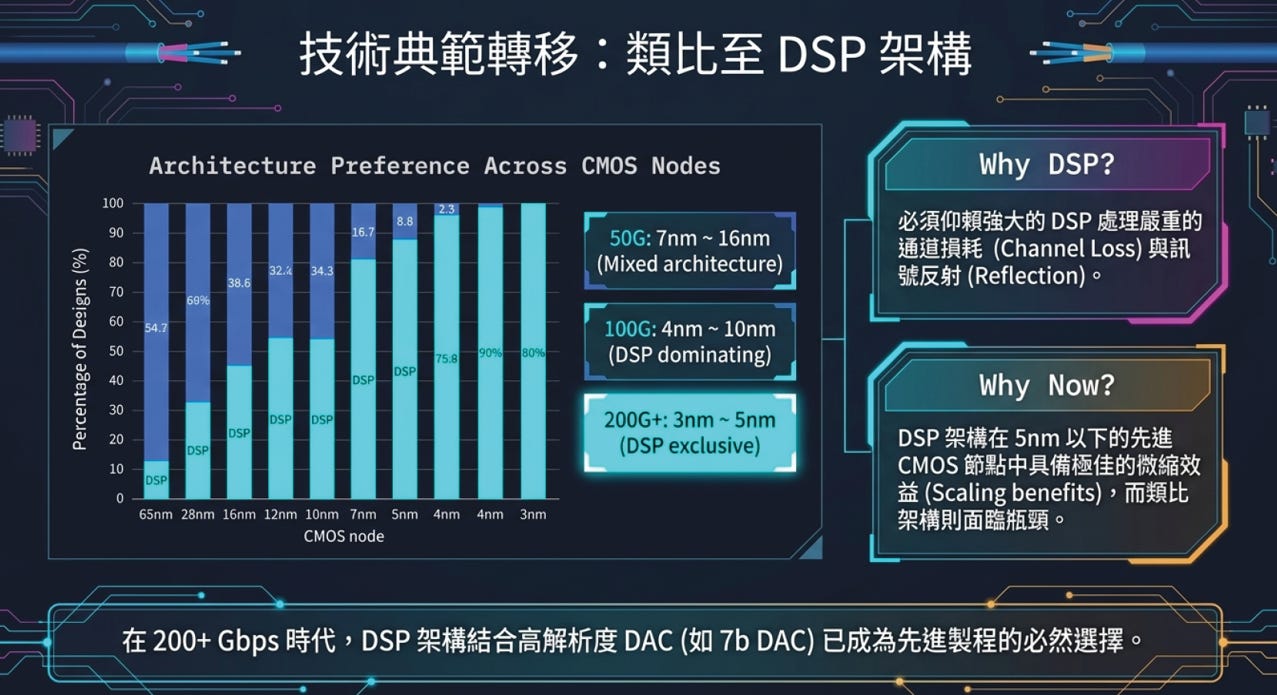
類比電路的瓶頸: 類比電路 (Analog) 在 5nm 以下的先進製程中,幾乎享受不到微縮紅利 (Scaling benefits)。也就是說,用 3nm 做類比電路,面積降不下來,功耗也未必更好,反而設計難度大幅增加。
數位邏輯的爆發: 相對地,DSP (純數位邏輯) 能夠完美吃滿先進製程的 PPA (效能、功耗、面積) 紅利。在 3nm/4nm 製程下,塞入更龐大、運算力更強的 DSP 區塊變得極具經濟效益。
在 200G+ 時代,「用龐大的數位算力來彌補糟糕的類比物理通道」 已成為必然。這不僅是因為訊號太差需要 DSP,更是因為在 3nm/4nm 先進製程下,把所有複雜度推向 DSP 是成本最低、效能最佳的系統級架構選擇。
1.4. Insertion Loss
224G (200G+) 世代的實體層設計,插入損耗 (Insertion Loss, IL) 的預算分配確實經歷了重大的結構性改變。
測試規範基準點的轉移:從 Ball-to-Ball 到 Bump-to-Bump

source: DesignCon26
112G 世代: OIF 的長距 (LR) 規範主要是基於「封裝錫球到錫球 (Ball-to-Ball)」來定義。
224G 世代: 由於高頻訊號在封裝基板內部的衰減變得極為劇烈,OIF CEI-224G-LR 將合規定義的邊界向內推至「裸晶凸塊到凸塊 (Bump-to-Bump / Die-to-Die)」。這意味著訊號完整性的評估必須將整個 IC 封裝內部路徑(包含載板與走線)完全納入考量。
Loss Budget 的結構性擠壓:Package 成為最大負擔
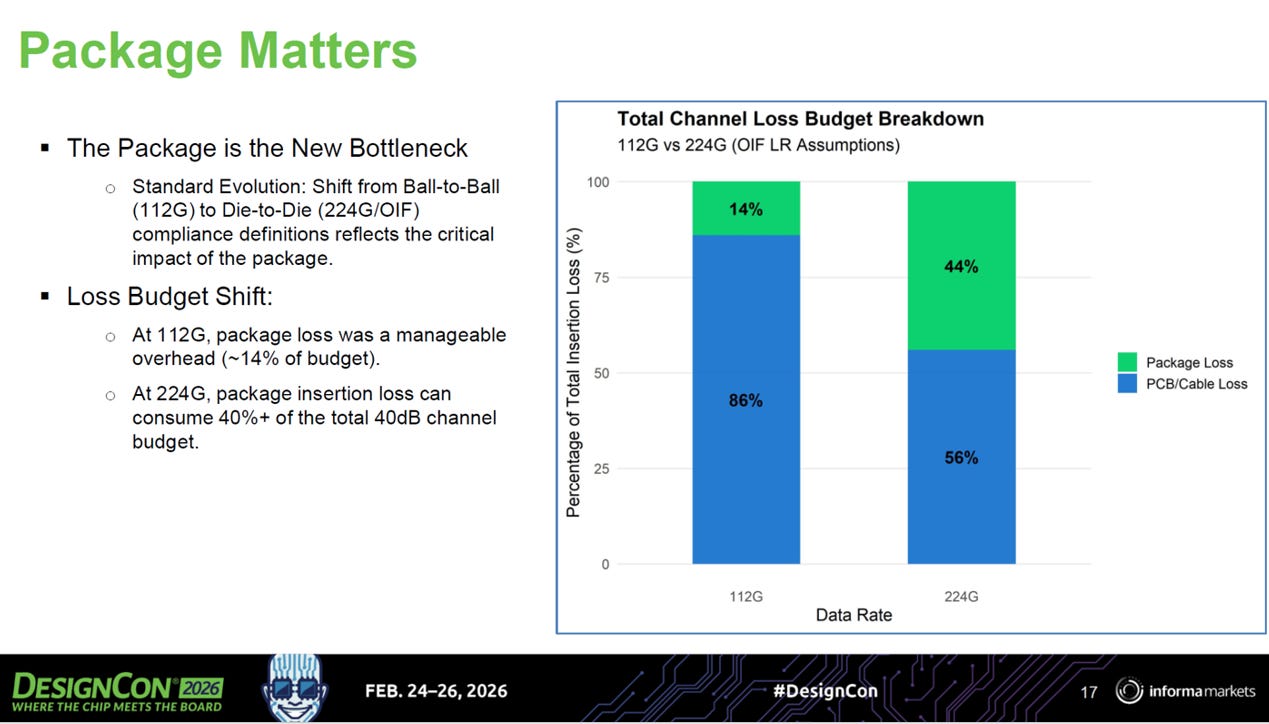
source: DesignCon26
總預算極限: 在 224G-LR 規範中,Bump-to-Bump 的總插入損耗預算被嚴格限制在 40 dB。
封裝損耗佔比飆升: 在 112G 時代,封裝損耗 (Package Loss) 僅佔整體預算的 14%,屬於相對可控的開銷。然而到了 224G,高階封裝的插入損耗佔比暴增至總預算的 44% 以上,成為整個通道中最主要的衰減來源。
實體通道 (Channel) 預算大幅縮水
依據資料損耗預算分配如下: 40 dB (總預算) - 9 dB (Tx 端封裝) - 9 dB (Rx 端封裝) = 22 dB (實體通道)
扣除收發兩端共 18 dB 的封裝損耗後,真正留給外部實體通道(包含主機板 PCB 走線、連接器、背板或銅纜)的餘裕僅剩下 22 dB。
相較於 112G 時代 PCB/Cable 享有 86% 的損耗預算,224G 時代留給外部通道的預算空間已縮減至 56%。
針對 200G+ (224 Gbps) 世代的高速 I/O 實體層設計,封裝內外的物理結構對訊號完整性 (Signal Integrity) 帶來了極大的挑戰。以下簡述兩大核心物理現象:
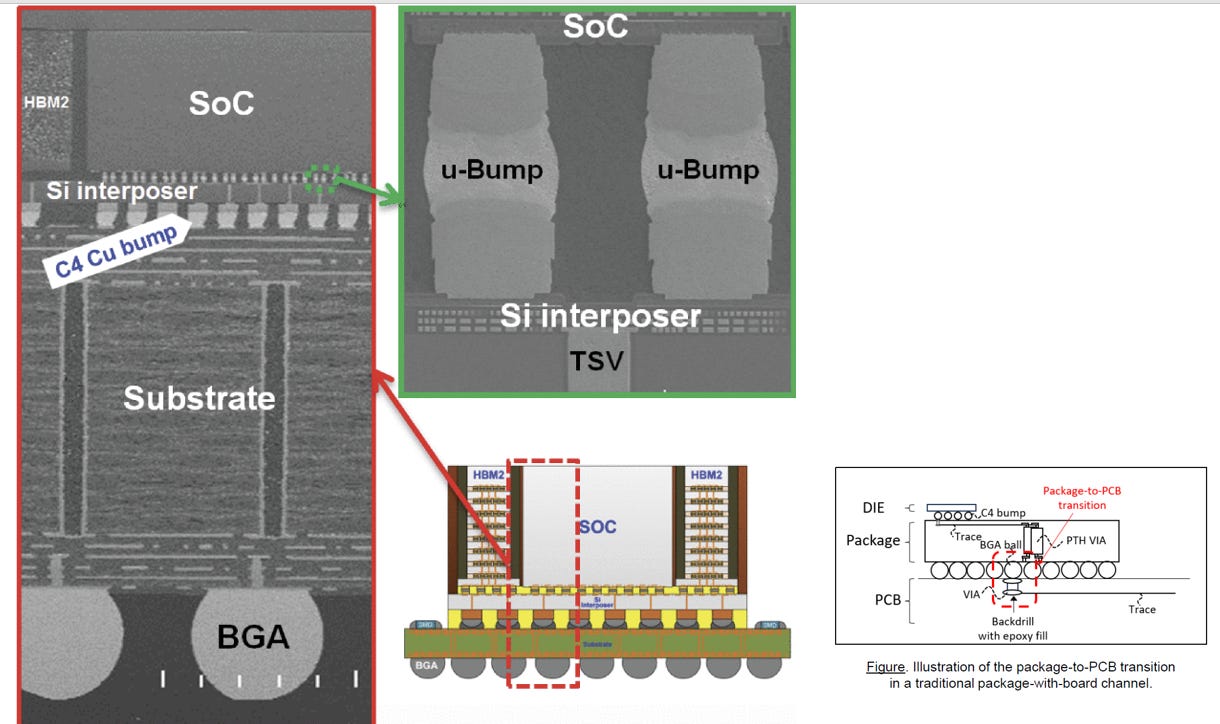
Package-to-PCB 介面轉換與空腔共振 (Cavity Resonance)
物理機制: 在封裝基板 (Substrate) 透過 BGA 錫球連接至主機板 (PCB) 的交界處,包含了 BGA 錫球、PCB 上的訊號導通孔 (Signal Via)、接地孔 (Ground Via),以及封裝與 PCB 各自的金屬參考平面 (Reference Planes)。這些立體結構交織出了一個微小的半封閉物理空間。
高頻衝擊: 在 224G (Nyquist 頻率高達 56 GHz) 的極端高頻環境下,這個微小空間的物理尺寸會與高頻訊號的波長產生交互作用,形成所謂的「空腔共振 (Cavity Resonance)」。 當訊號頻率命中該空腔的共振頻率點時,電磁能量會被困在此空間內來回震盪,無法往下游傳遞。這會導致通道的插入損耗 (Insertion Loss) 在特定頻段出現斷崖式的巨大衰減 (Resonance Suck-out),同時將能量輻射出去,大幅增加相鄰通道間的串擾與 EMI 問題。
高階封裝 (如 CoWoS-S) TSV 的高頻損耗與串擾
物理機制 (MOS 寄生結構): CoWoS-S 依賴大面積的矽中介層 (Silicon Interposer)。其內部的矽穿孔 (TSV) 是由中心的「銅柱 (金屬)」、外圍包覆的「二氧化矽 (絕緣層)」,以及最外層的「矽基板 (半導體)」所構成。這在物理上形成了一個標準的 Metal-Oxide-Semiconductor (MOS) 結構,伴隨極大的寄生電容。
高頻衝擊 (Loss & Crosstalk):矽基板並非完美的絕緣體,而是帶有微導電性。224G 的超高頻電磁場會輕易穿透微薄的絕緣層,透過 MOS 寄生電容「洩漏」到矽基板中,引發強烈的渦電流 (Eddy Current)。這些渦電流會直接將高頻訊號的能量轉化為熱能耗散,造成極度嚴重的介電損耗。
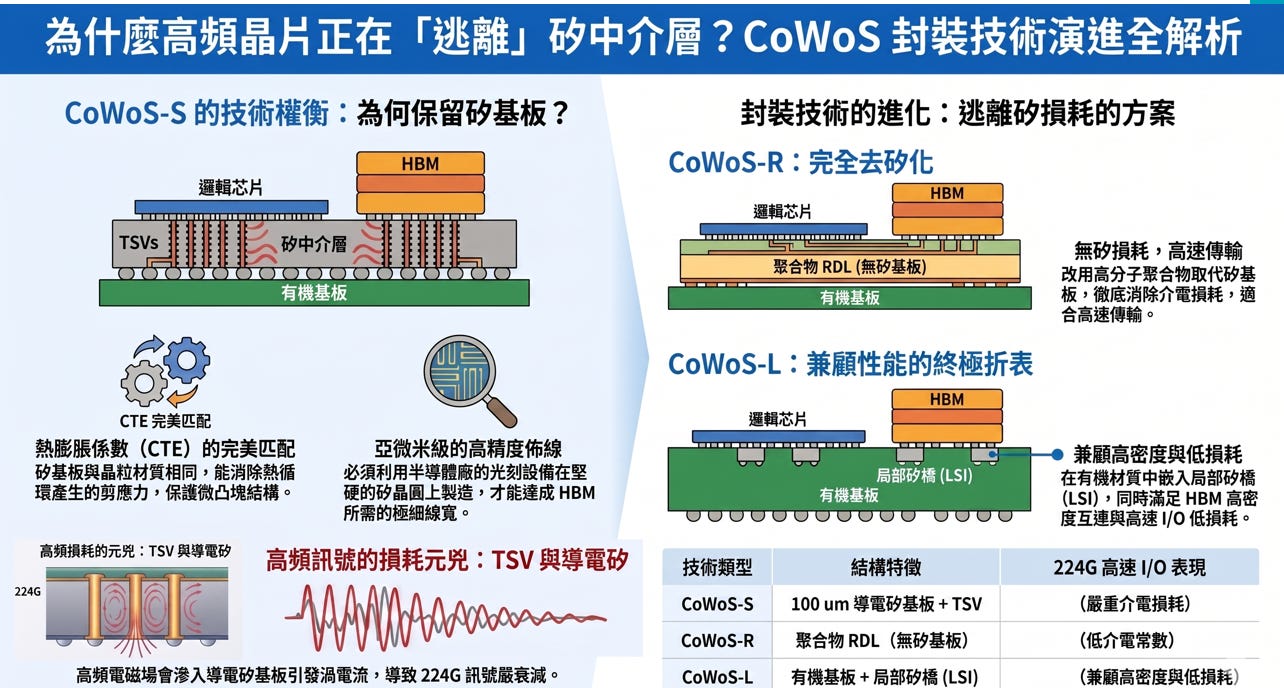
為了克服這兩大物理瓶頸,系統端必須透過更精密的 PCB 疊層設計與背鑽 (Backdrill) 技術來抑制 BGA 區域的空腔共振;而在封裝端,這也是台積電發展 CoWoS-R 與 CoWoS-L (利用有機絕緣基板取代大面積矽基板) 以解決高頻損耗的原因。
2. 聯發科 212.5Gb/s 收發器技術
2.1. 發射器架構
2.1.1. DAC-based Transmitter 架構
在 200G+ (即 212.5 Gbps / 106.25 GBaud PAM4) 世代,發射端 (TX) 已全面轉向 DSP 數位訊號處理結合 DAC 數位類比轉換器 的架構
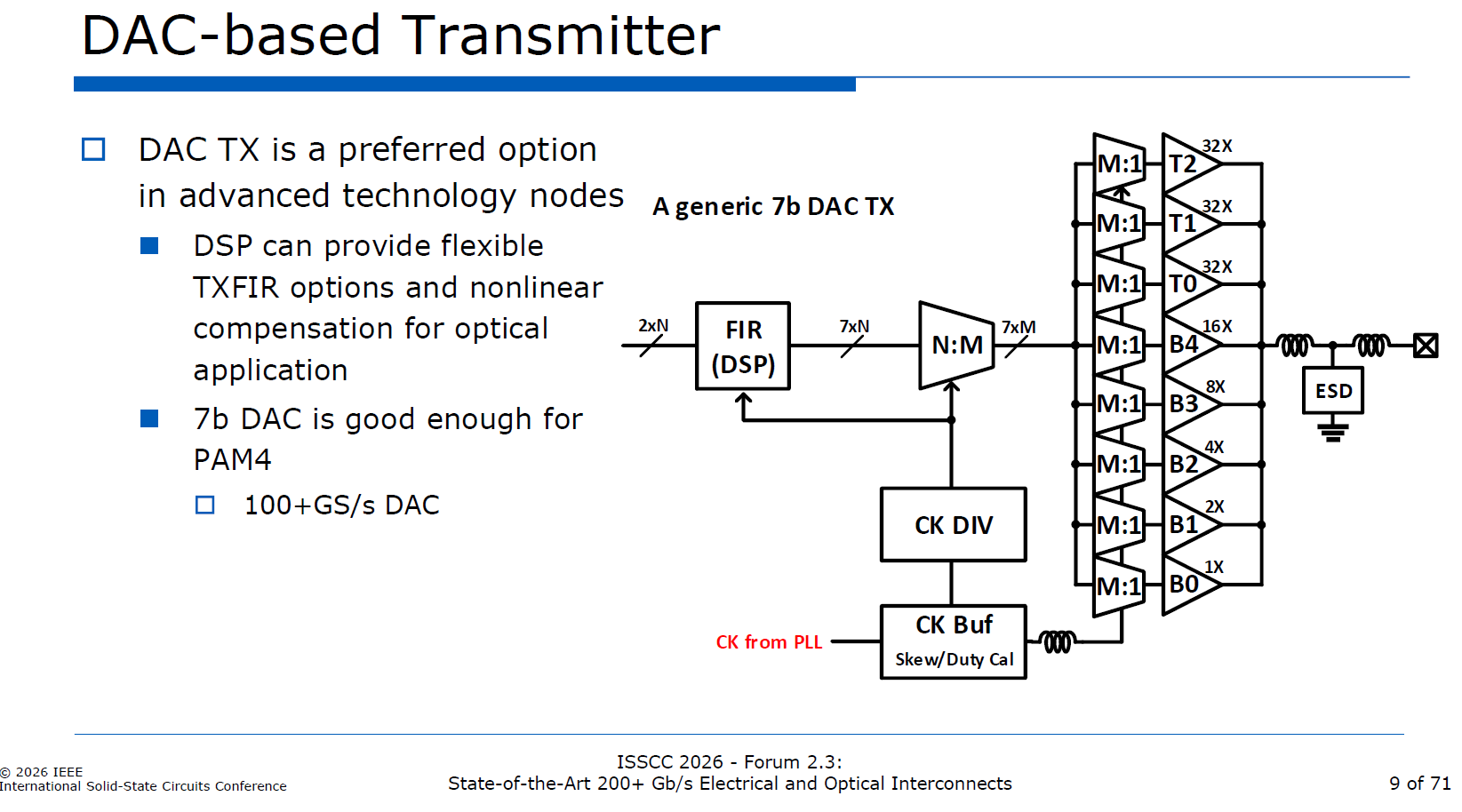
source: ISSCC26
200G+ TX 架構
數位掛帥 (DSP-Centric): 為了應對 224G 世代極端惡劣的通道物理環境,TX 架構全面擁抱數位化,利用先進製程 (3nm/4nm) 的紅利,透過強大的 DSP 執行複雜的 FIR 等化與非線性補償。
DAC 取代傳統驅動: 放棄純類比驅動,改採 7-bit 解析度的數位類比轉換器 (DAC),精準合成滿足高訊噪比要求的 PAM4 波形。
突破 100+ GS/s 取樣頻率的關鍵設計
縮短資料路徑: 採用「MUX 與 DRV 融合」技術,將最後一級多工器直接疊加在驅動電晶體上,消除中間緩衝級的寄生電容。
四相時脈 (Quarter-Rate): 利用四個相差 90 度的時脈輪流驅動開關,讓內部 PLL 僅需產生資料傳輸率四分之一的時脈頻率 (例如 112 GBaud 僅需 28 GHz 時脈),大幅降低高頻設計難度。
Inductive Peaking: 利用電感突波 (Inductive Peaking),抵銷寄生電容效應, 以延伸頻寬,並將 ESD 防護元件打散整合進傳輸線模型中,避免單一巨大寄生電容拖垮高頻響應。
7-bit 分段式 DAC (Segmented DAC) 解碼邏輯
目的:消除高頻突波。 若純用二進制控制,在特定數值跨越 (如 63 跳 64) 時,多個電晶體同時開關會引發嚴重的電壓突波 (Glitch) 與非線性失真。
分段策略: 7-bit 數值被拆解為 8 條硬體控制線
二進制區段 (B0-B4): 處理 0 到 31 的精細微調。
溫度計區段 (T0-T2): 處理 32 倍數的大幅度跨越 (32, 64, 96)。
這 3 條線採用溫度計編碼 (Thermometer code),意即必須依序開啟 (先開 T0,再開 T1,最後 T2)
運作結果: 透過將高位元 (MSB) 轉換為溫度計編碼依序開啟,確保在數值大幅變動時,硬體開關的切換數量降至最低,從而在 100+ GS/s 的極限頻率下維持完美的 PAM4 眼圖品質。
解碼實例 (Decoding Examples)
輸入值 15: 尚不足 32。T0-T2 全關。B 區段顯示 01111 (B3, B2, B1, B0 開啟)。
輸入值 50: 50 = 32 + 18。
開啟 T0 (取得 32)。
剩餘 18 由 B 區段處理,開啟 B4 (16) 與 B1 (2)。
輸入值 100: 100 = 32 + 32 + 32 + 4。
開啟 T0, T1, T2 (取得 96)。
剩餘 4 由 B 區段處理,開啟 B2 (4)
2.1.2. 100+ GS/s 設計的關鍵特徵
要在單通道達成超過 100 GS/s 的轉換率,實體層電路必須在極限高頻下克服時序與寄生效應的物理限制
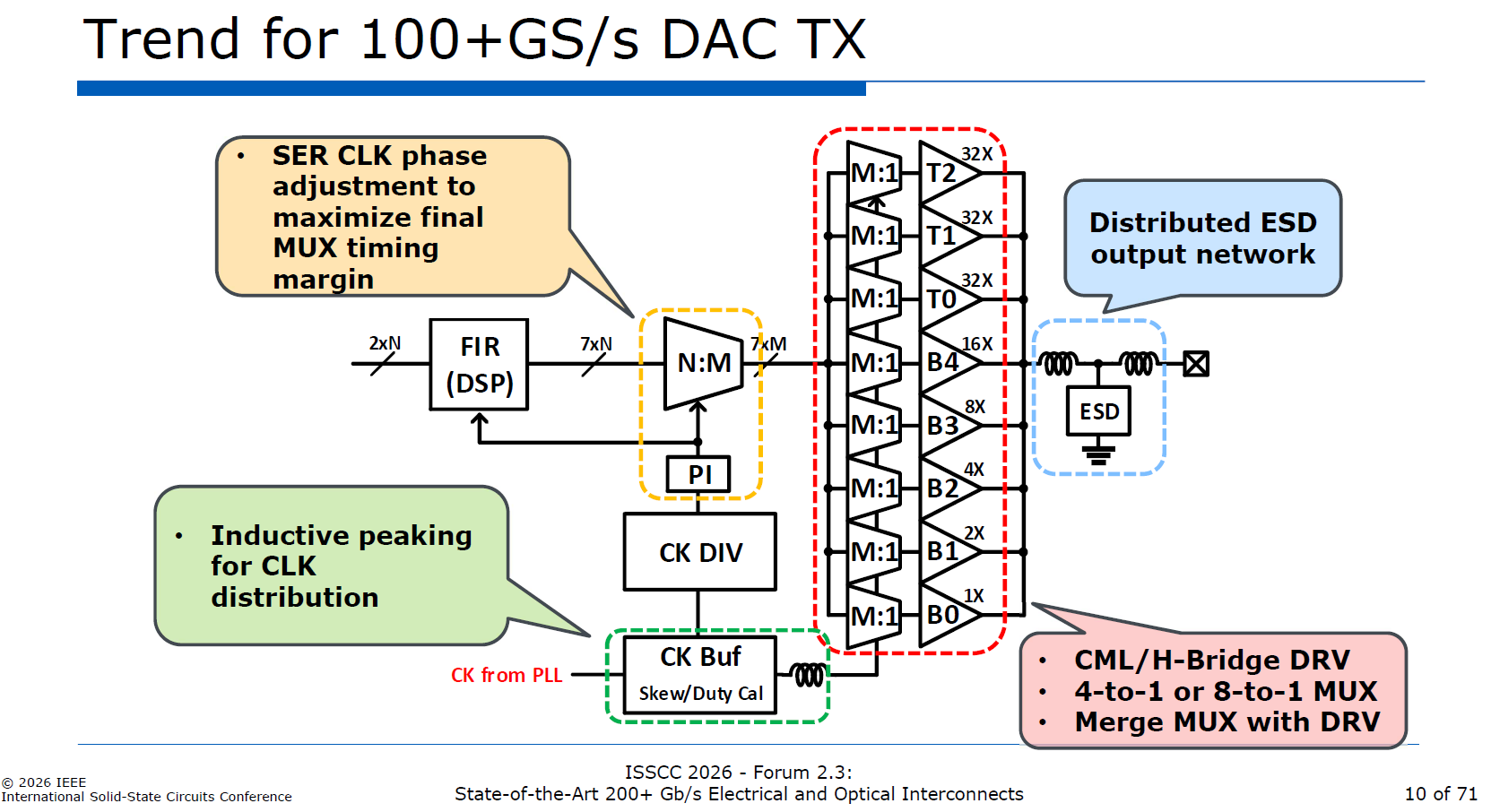
source: ISSCC26
時序餘裕最大化 (Maximize Timing Margin): 在N:M多工器加入相位內插器 (PI, Phase Interpolator)。這允許系統精準微調序列時脈的相位,補償晶片內部的延遲變異,確保在高頻率下資料取樣的正確性。
電感突波技術 (Inductive Peaking): 在時脈分配網路 (CLK distribution) 與緩衝器 (CK Buf) 中廣泛加入電感。利用電感的物理特性抵銷電晶體的寄生電容,藉此擴展頻寬,維持高頻時脈邊緣的銳利度。
MUX 與 DRV 融合 (Merge MUX with DRV): 放棄傳統「先多工、再緩衝、後驅動」的串列設計,將 4:1 或 8:1 的最後一級多工器直接與輸出驅動器結合,大幅減少訊號路徑上的節點與寄生電容。
分散式 ESD 網路 (Distributed ESD): 輸出端採用將 ESD 防護二極體與電感 (通常為 T-coil 結構) 交錯配置的設計,將 ESD 的巨大寄生電容吸收進傳輸線模型中,以保護晶片同時不犧牲超高頻頻寬。
2.1.3. 真實電路剖析:紅框區域(Merged 4:1 MUX & DRV)
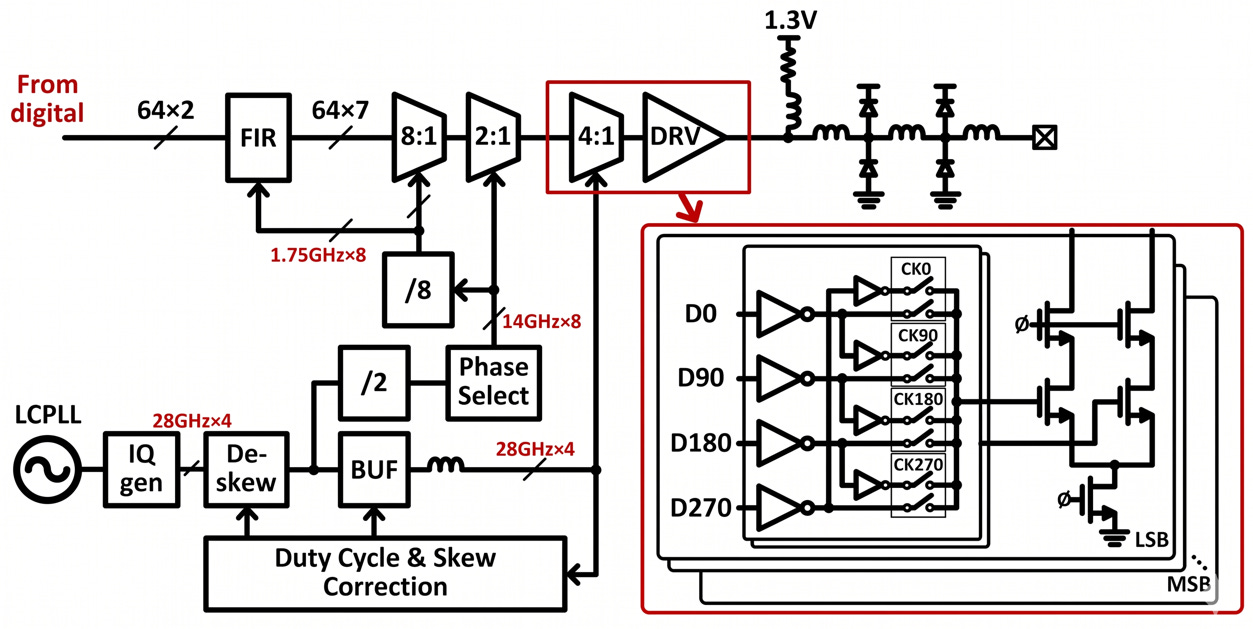
source: ISSCC25
四分之一速率時脈架構 (Quarter-Rate Architecture): 觀察紅框內部,資料流分為四路 (D0, D90, D180, D270),並由四個相差 90 度的正交時脈 (CK0, CK90, CK180, CK270) 控制開關。 這種設計極為關鍵:這代表時脈頻率只需要是最終資料符號率 (Baud Rate) 的 四分之一。例如,要產生 112 GBaud 的訊號,PLL 只需要提供 28 GHz 的時脈。這大幅降低了時脈產生器與分配網路的功耗及設計難度。
無縫接軌的序列化與驅動 (Direct Drive): 資料通過由四相時脈控制的開關 (圖中標示的 Switches) 進行 4:1 序列化後,沒有經過額外的緩衝級,而是直接連接到右側 CMOS 驅動電晶體 (推輓式或反相器架構) 的閘極。這種縮短路徑的作法,是確保頻寬能支撐 100+ GS/s 的核心手段。
DAC 切片堆疊 (Slice Stacking): 紅框代表的僅是 7-bit DAC 中的一個切片 (Slice)。圖中右下角標示了多層堆疊的陰影,並註明從 LSB 到 MSB,代表整個 TX 是由127 個這樣的「4:1 MUX + DRV」基本單元並聯而成。DSP 輸出的數位碼會決定在特定時間點,有多少個切片被「打開」,進而在 1.3V 終端電阻與電感網路上,加總出精確的 PAM4 類比電壓準位。
2.2. 先進時鐘系統
針對 200G+ (224G PAM4) 世代的先進時鐘系統 (Clocking System) 設計,實體層規格迫使鎖相迴路 (PLL) 架構必須進行升級:
2.2.1. 224G PAM4 PLL/Clock 的系統要求

source: ISSCC26
架構與頻率的對應關係:
PLL 的輸出頻率取決於 TX 最終多工器 (MUX) 的架構。
若採用 8:1 MUX (八分之一速率),PLL 需提供 14 GHz 的時脈 (112 / 8 = 14)。
若採用主流的 4:1 MUX (四分之一速率),PLL 需提供 28 GHz 的時脈 (112 / 4 = 28)。高頻率會顯著增加 CMOS 電路的功耗與設計難度。
極致的抖動限制 (Jitter Budget):
為確保 PAM4 眼圖的清晰度,整個時鐘路徑的隨機抖動 (Random Jitter, Rj) 必須被嚴格控制在 小於 90 fs (飛秒)。這對 VCO (壓控振盪器) 的相位雜訊 (Phase Noise) 提出了極高的要求(請參考: EP28. Jitter )。
VCO 設計的物理權衡:
要降低 VCO 的相位雜訊以滿足 90 fs 的要求,通常必須犧牲其頻率調諧範圍 (Tuning Range)。這會導致系統只能在單一窄頻段運作;若需支援多種傳輸速率,則必須在晶片內佈建多個 VCO,進一步增加面積與複雜度。
2.2.2. 電路設計區塊:Fractional-N DPLL
針對高速 SerDes 設計的 DPLL 核心架構。其中紅框標示的 TDC 與 IQ Gen 是達成上述嚴苛要求的關鍵電路區塊:
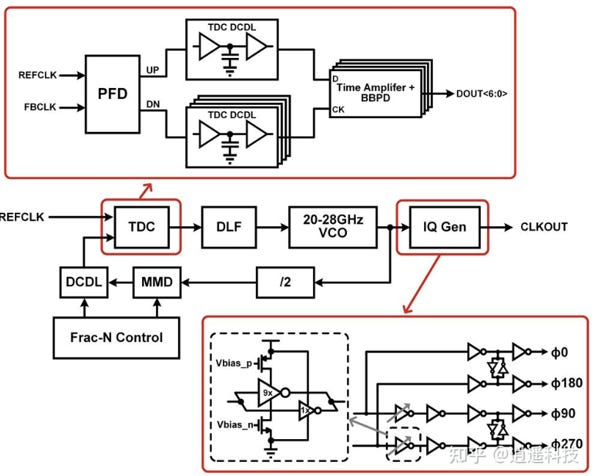
source: ISSCC25
TDC (Time-to-Digital Converter, 數位時間轉換器)
傳統類比 PLL 使用電荷泵浦 (Charge Pump),而 DPLL 則使用 TDC 將參考時脈 (REFCLK) 與回授時脈 (FBCLK) 之間的「相位誤差時間」直接轉換為數位訊號 (DOUT)
Time Amplifier (時間放大器) + BBPD: 為了達成小於 90 fs 的總體抖動目標,TDC 必須具備極高的解析度與極低的量化雜訊。電路中在鑑相器 (PFD, Phase Frequency Detector) 之後加入了延遲線 (DCDL, Digitally Controlled Delay Line) 與時間放大器陣列。時間放大器能將皮秒級的微小相位誤差放大,再交由 BBPD (Bang-Bang Phase Detector) 進行數位判決,藉此大幅提高時間解析度,精準追蹤並消除相位誤差。
IQ Gen (正交時脈產生器)
在 28 GHz 的高頻 VCO 輸出後,必須透過 IQ Gen 產生多相位的時脈,以驅動 TX 端的 4:1 MUX
四相正交輸出: IQ Gen 負責將單一頻率轉換為相差 90 度的四個相位 (0度、90度、180度、270度)。這正是支援四分之一速率 (Quarter-Rate) 架構不可或缺的基礎。
交叉耦合鎖存結構 (Cross-coupled Latch): 觀察其底層邏輯圖,除了標準的反相器 (Inverter) 鏈之外,上下路徑之間加入了交叉耦合的結構 (圖中標示雙向箭頭的反相器符號)。這種設計能強制各相位之間保持嚴格的 90 度正交關係,並自我修正工作週期失真 (Duty Cycle Distortion)。若這四個相位的間距不完美,將直接轉化為傳輸訊號的確定性抖動 (Deterministic Jitter, Dj),因此這段電路的對稱性佈局至關重要。
2.3. 接收器架構
2.3.1. DSP-Based RX架構
針對 200G+ (224 Gbps PAM4) 世代的接收端 (RX) 設計,架構已從傳統的純類比等化,全面演進為 DSP-Based RX (基於數位訊號處理的接收器)。
類比前端 (Analog Front-End, AFE)
雖然核心處理交給了數位端,但進入 ADC 之前的極高頻類比訊號仍需進行初步的整理與放大:
終端與靜電防護 (Termination & ESD): 採用分散式 ESD (Distributed ESD) 網路,搭配電感形成 T-coil 結構,以吸收 ESD 二極體的寄生電容。同時具備 Die 內建的 AC 耦合電容 (On-die AC couple),確保高頻頻寬。
訊號重塑 (CTLE & VGA): 連續時間線性等化器 (CTLE) 與可變增益放大器 (VGA) 負責初步補償高頻損耗並放大訊號。為了在 200G+ 的極限頻率下提升增益,設計趨勢是同時使用 N-MOS 與 P-MOS 來加倍轉導 (Gm),並導入基於諧振器的高頻突波技術 (Resonator-based high-frequency peaking) 來延伸頻寬。
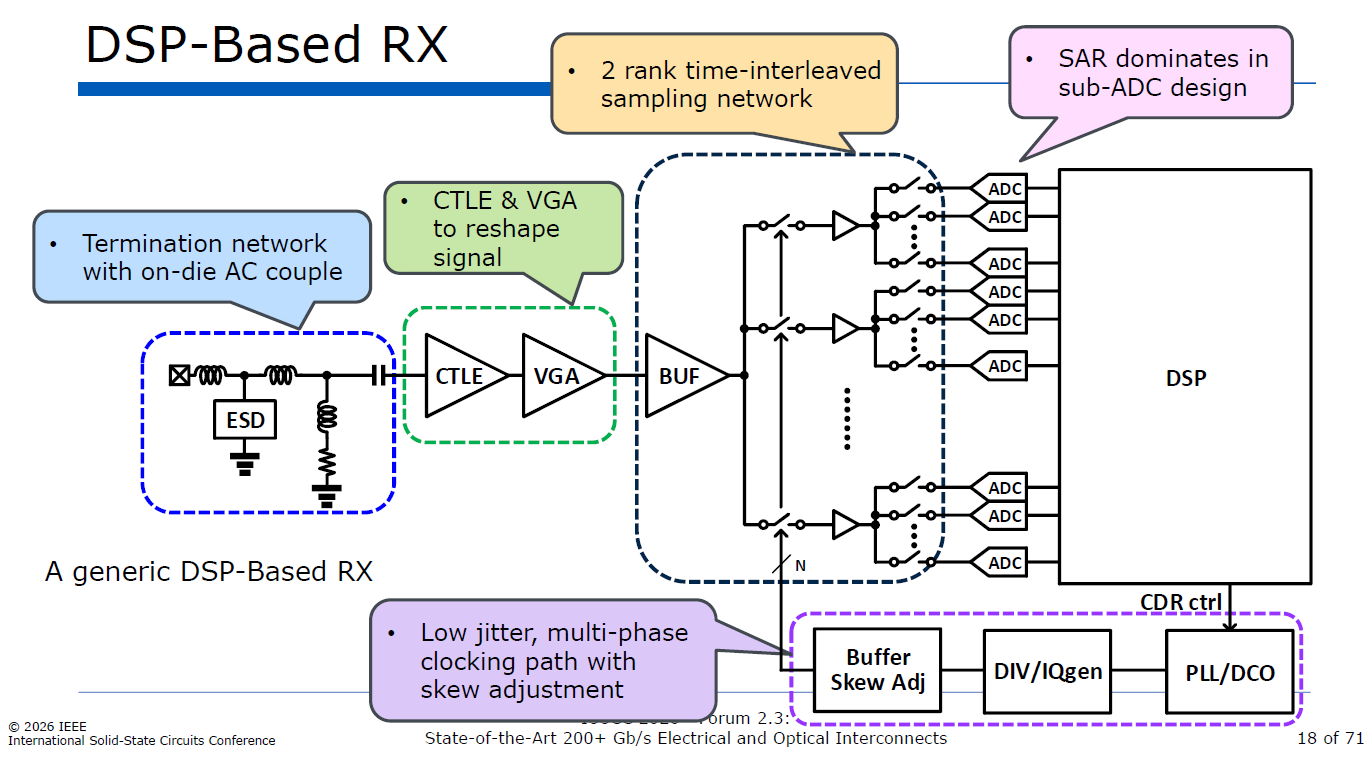
source: ISSCC26
時間交錯取樣網路 (Time-Interleaved Sampling Network)
這是 DSP-Based RX 跨越 100+ GS/s 物理極限的核心關鍵。單一 ADC 絕對無法跑到 100 GHz 以上,因此必須採用「分工合作」的架構:
兩級時間交錯 (2-rank Time-Interleaved): 訊號通過緩衝器 (BUF) 後,會先被切分為多路(如圖中紅框所示),接著每一路再向下細分。
16 路並行與 Sub-ADC: 目前 200G+ 的主流趨勢是在第一級使用 16 路交錯的追蹤保持電路 (16-way interleaving in 1st rank T/H)。最終訊號會送入龐大的 Sub-ADC 陣列。透過這種高度平行的架構,單個 Sub-ADC 的運作速度只需降到約 1 GS/s,大幅降低了設計難度與功耗
SAR ADC 主導: 在 Sub-ADC 的設計上,逐漸由逐漸由連續漸近暫存器 (SAR, Successive Approximation Register) 架構主導,因其在先進製程中具有極佳的能效比與面積優勢
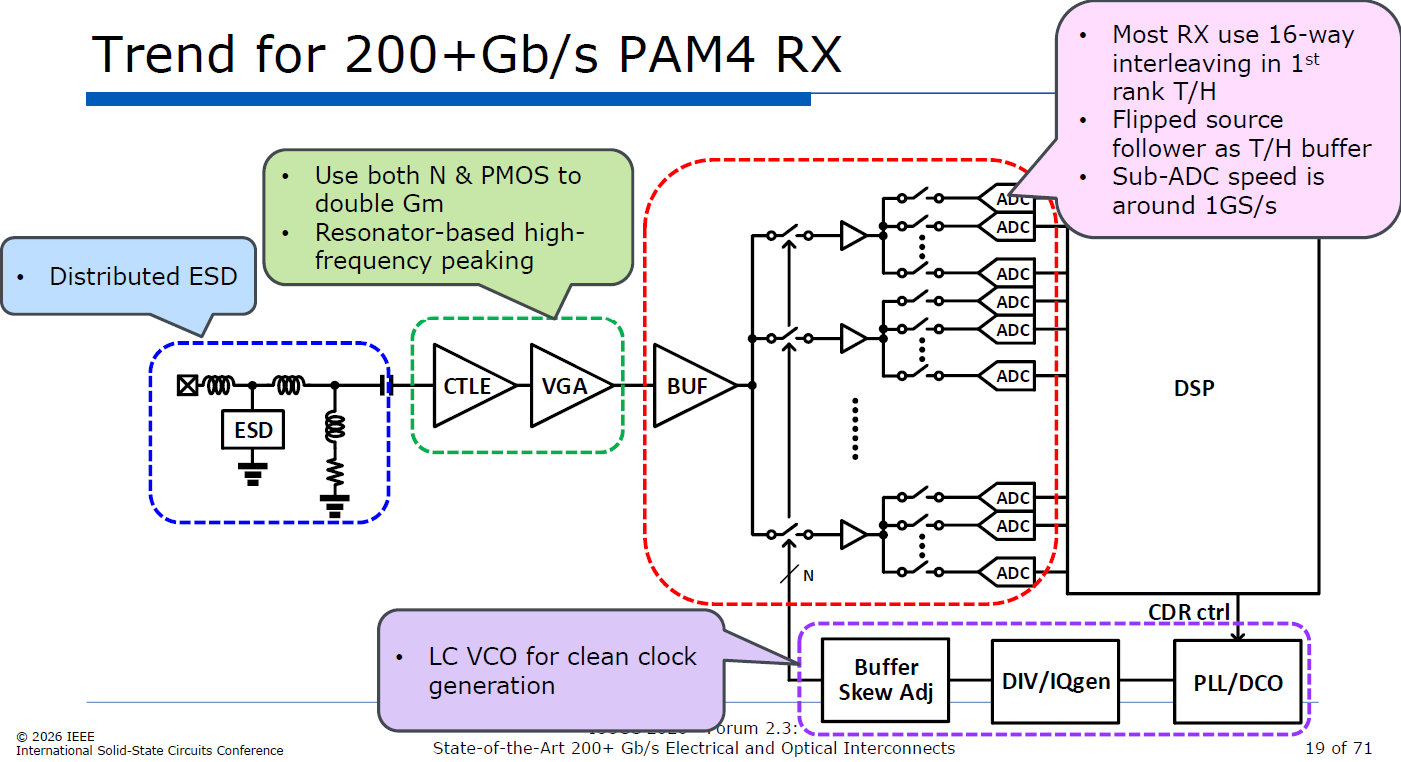
source: ISSCC26
數位核心與時鐘回饋 (DSP & Clocking)
DSP 處理: 經過 ADC 數位化後的平行資料流,會送入龐大的 DSP 引擎。DSP 利用強大的演算法執行複雜的 FFE/DFE 等化、非線性補償以及 FEC 解碼,還原出最終的資料。
低抖動時鐘系統 (Low Jitter Clocking):
RX 必須從接收到的資料中精準萃取時脈 (CDR, Clock Data Recovery)。DSP 會計算出相位誤差,並反饋控制訊號 (CDR ctrl) 給底層的 PLL/DCO。
為了提供極度乾淨的取樣時脈給龐大的 Sub-ADC 陣列,通常採用 LC VCO 來產生低相位雜訊的時脈,並配備具備偏斜調整 (Skew Adjustment) 功能的多相時脈路徑,確保交錯取樣的精準度。
2.3.2. RX 電路架構
下圖展示了一個高度整合的 224G 接收端完整系統方塊圖,明確劃分了類比前端與數位後端:
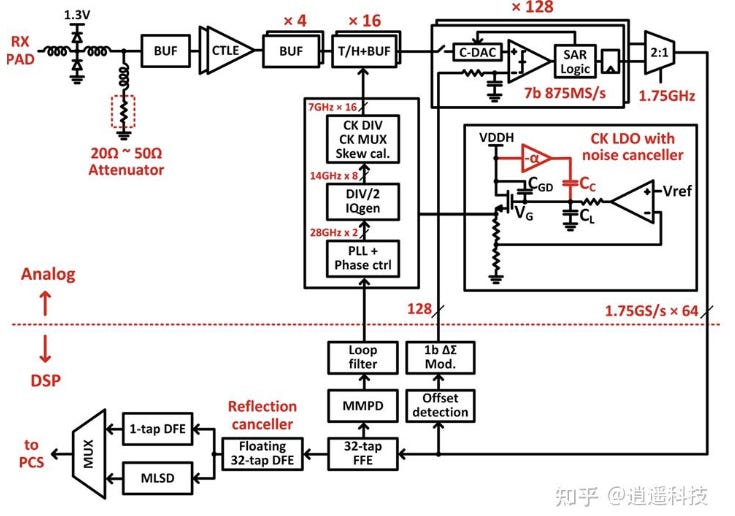
source: ISSCC25
類比前端 (Analog Front-End):
訊號由
RX PAD進入,首先經過具有靜電防護與20Ω ~ 50Ω 可調衰減器 (Attenuator)的終端網路。接著訊號進入由
CTLE與多級緩衝器 (BUF) 組成的線性等化與放大路徑,以補償通道的高頻損耗。
時序與取樣網路 (Time-Interleaved ADC):
這是跨越頻寬限制的核心。系統採用高度平行的時間交錯架構:訊號經過
x 4的第一級分割後,進入x 16的 T/H + BUF (追蹤保持與緩衝器)。最終,訊號被送入由 128 個 獨立的 7-bit SAR ADC 所組成的龐大陣列 (標示為
x 128),每個 Sub-ADC 僅需以相對較低的875 MS/s運作,共同組成破百 GS/s 的總取樣率。
低雜訊時鐘系統:
PLL 產生
28 GHz的主時脈後,經過除頻與正交相位產生器 (IQgen) 轉換為14 GHz x 8,再進一步除頻與相位校準為7 GHz x 16,精準驅動 T/H 開關。圖中特別點出供給 ADC 參考電壓的
CK LDO with noise canceller,利用負回授迴路主動消除電源雜訊,確保 SAR ADC 的量化精度。
DSP 數位後端:
數位化的資料 (
1.75GS/s x 64) 進入 DSP 引擎。這裡執行了龐大且複雜的演算法:包含32-tap FFE(前饋等化)、Floating 32-tap DFE(浮動式決策回饋等化) 加上Reflection canceller(反射消除器),最後甚至可選用MLSD(最大概似序列偵測) 來榨出最後一絲訊噪比 (SNR),最終將還原的資料送往 PCS 層
深入解析 T/H + BUF (追蹤保持電路與緩衝器)
在時間交錯 ADC 架構中,第一級的追蹤保持電路 (T/H) 是頻寬的絕對瓶頸。下圖揭示了為了在 100+ GS/s 頻率下維持高頻響應,設計師所採用的電路技巧:
翻轉源極隨耦器 (Flipped Source Follower, FSF) 作為緩衝器
傳統的源極隨耦器在高頻下頻寬受限且線性度較差。下圖右上角的電路圖顯示,設計師採用了 FSF 架構。透過將 NMOS 的源極作為輸出,並在閘極與源極之間建立正回授,能顯著降低輸出阻抗,大幅推升頻寬,使其能有效驅動後端龐大的 ADC 陣列電容負載
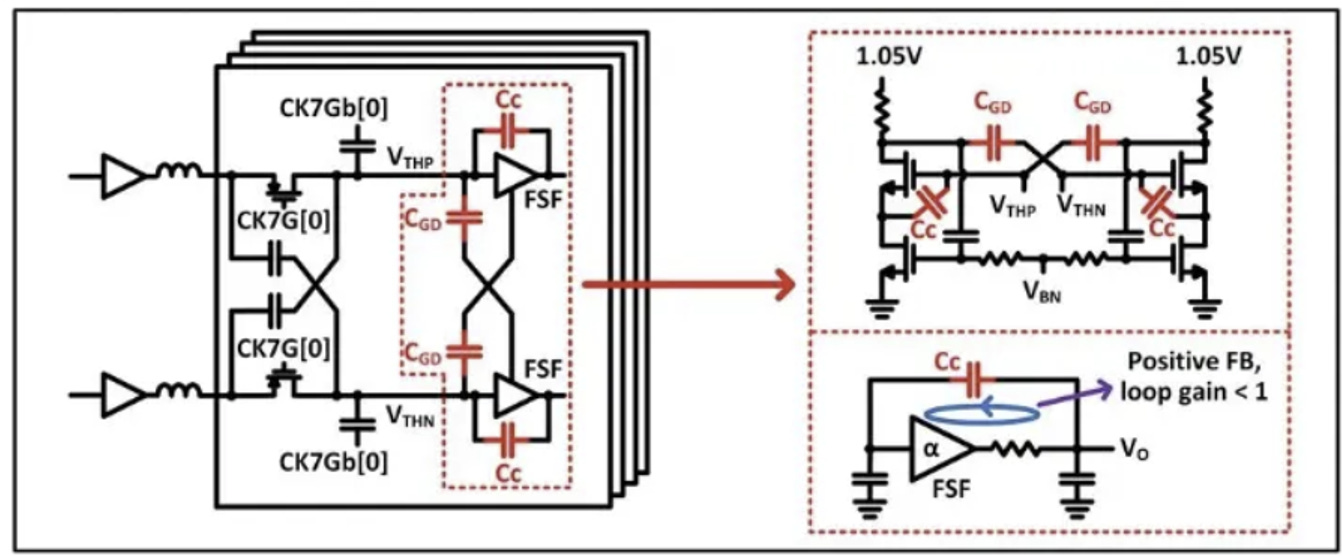
source: ISSCC25
中和電容 (Neutralization Capacitance, Cc) 與正回授突波 (Positive Feedback Peaking)
米勒效應的抵銷: 高速 CMOS 電路最怕的就是閘極到汲極的寄生電容 (CGD)。在差動電路中,設計師交叉加入了中和電容 (Cc) (見圖二右上角的交叉紅線)。這能抵銷 CGD 帶來的米勒電容倍增效應,大幅改善高頻穩定性。
主動頻寬延伸 (Active Peaking): 觀察圖二右中標示的等效迴路:藉由刻意調整 Cc 的大小,設計師在 FSF 內部創造了一個「環路增益小於 1 的正回授 (Positive FB, loop gain < 1)」。
這個微弱的正回授不足以讓電路變成振盪器,但卻能在高頻段人為地製造出一個「突起 (Peaking)」。
觀察圖二右下的頻率響應圖 (TH PAC Gain):當採用較大的 Cc (
LargeCc, 紅線) 時,電路在7 GHz,14 GHz,21 GHz,28 GHz等高頻點的增益被顯著拉高 (Gain peaking),這完美補償了 T/H 開關電路本身的 RC 衰減,成功將整體 T/H 的頻寬向外延伸。

source: ISSCC25
代價與權衡: 凡事皆有代價。圖二左下的時域脈衝響應 (Extracted TH SBR) 顯示,較大的 Cc雖然帶來了高頻 Peaking (讓主脈衝變高變窄),但卻在 16 個 UI (單位區間) 之後引發了微小的「記憶效應 (Memory effect)」。這代表先前的取樣會微弱地干擾後續的取樣,這部分必須仰賴 DSP 後端的 DFE 演算法來予以消除。
2.4. 性能結果
MediaTek採用 4nm 製程開發的 212.5 Gb/s (106.25 GBaud PAM4) SerDes 晶片,測試結果如下:
類比前端 (AFE) 與高頻響應表現
下圖揭示了類比電路在 100+ GS/s 頻率下的控制力:
精準的 CTLE 峰值補償: 右圖的 CTLE 頻率響應圖顯示,其增益突波 (Peaking) 最大值精準落在 56 GHz,這正是 112 GBaud PAM4 訊號的 Nyquist 頻率。在此頻率下提供了近 17 dB 的主動補償。
極佳的眼圖線性度: 左圖的 Real-Time Eye 顯示,SNDR (訊號與雜訊失真比) 達 35.5 dB,且代表 PAM4 四個階層對稱性的 RLM 指標高達 98.5 (理想值為 100),顯示其 DAC 輸出與類比驅動的線性度極佳。
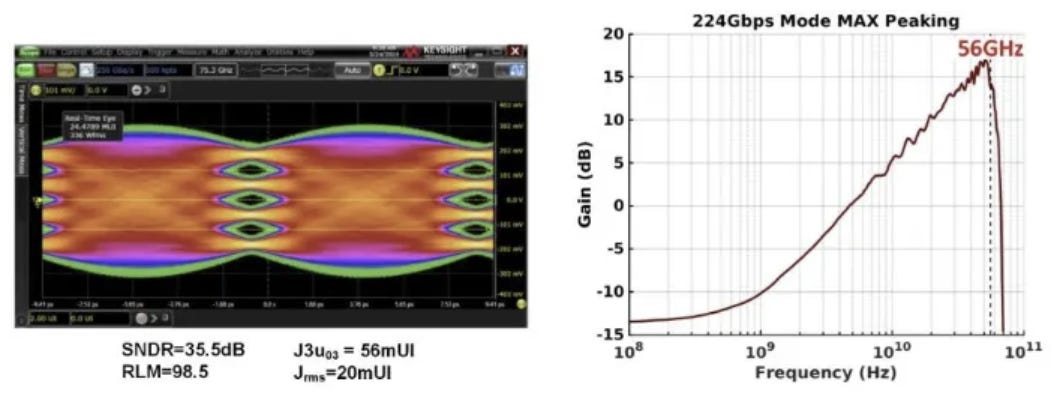
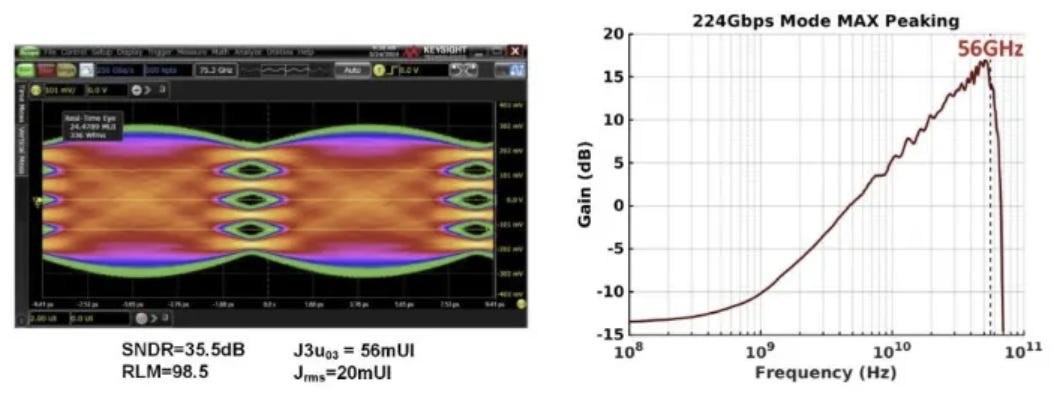
source: ISSCC25
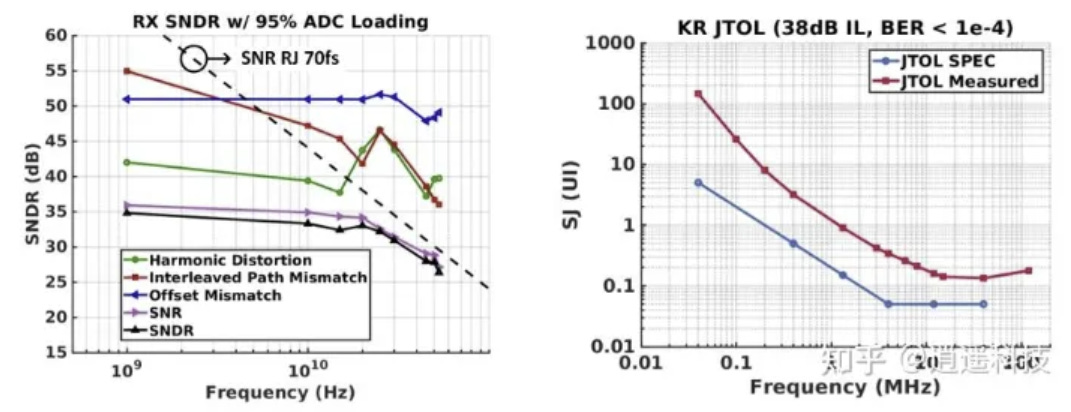
雜訊控制與抖動容忍度 (Noise & Jitter Tolerance)
ADC 交錯誤差抑制: 下左圖的 RX SNDR 拆解圖中,雖然使用了 16 路甚至 128 路的交錯取樣網路,但「交錯路徑不匹配 (Interleaved Path Mismatch)」(紅線) 所造成的失真被良好地控制住,確保整體 SNDR 在全頻段皆維持在健康水準。
強健的 JTOL: 下右圖的抖動容忍度 (KR JTOL) 測試,是在 38 dB 的嚴苛損耗且 BER < 1e-4 的條件下進行。實測結果 (紅線) 在各個頻段皆大幅超越規格要求 (藍線),證明其 PLL 與時鐘數據恢復 (CDR) 系統的追蹤能力極為強悍。
source: ISSCC25
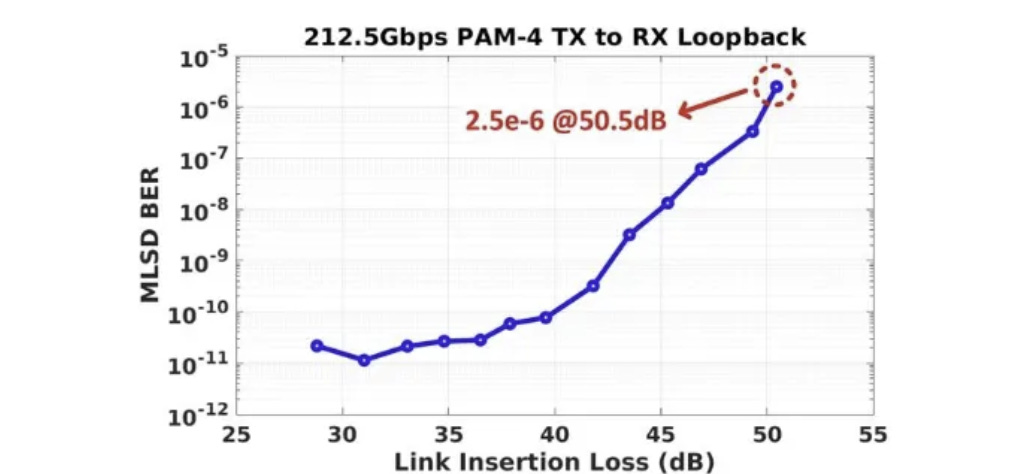
極限通道損耗容忍度 (Extreme Insertion Loss Tolerance)
突破 40dB 極限: 現行 OIF CEI-224G-LR 的長距規範,其通道插入損耗 (Insertion Loss, IL) 預算上限為 40 dB。
MLSD 發威: 藉由數位後端強大的 MLSD (最大概似序列偵測) 演算法,此晶片在高達 50.5 dB 的極端通道損耗下,依然能維持 2.5e-6 的 Pre-FEC BER (前向錯誤更正前誤碼率),完美符合多數 FEC 的解碼門檻 (通常要求 1e-4 到 1e-3 等級)。這大幅增加了系統廠在背板與銅纜佈線上的物理彈性。
source: ISSCC25
業界指標比較 (PPA 綜合評估)
功耗表現 (Power): 總功耗為 5.3 pJ/b (類比 3.5 + 數位 1.8)。雖然絕對數值高於部分競爭者,但這是建立在它能突破性地支援 50.5 dB IL (遠超對手的 31.6 dB 或 40 dB) 的基礎上。考慮到其強大的等化算力,此能效比在極端長距 (LR) 應用中依然極具競爭力。
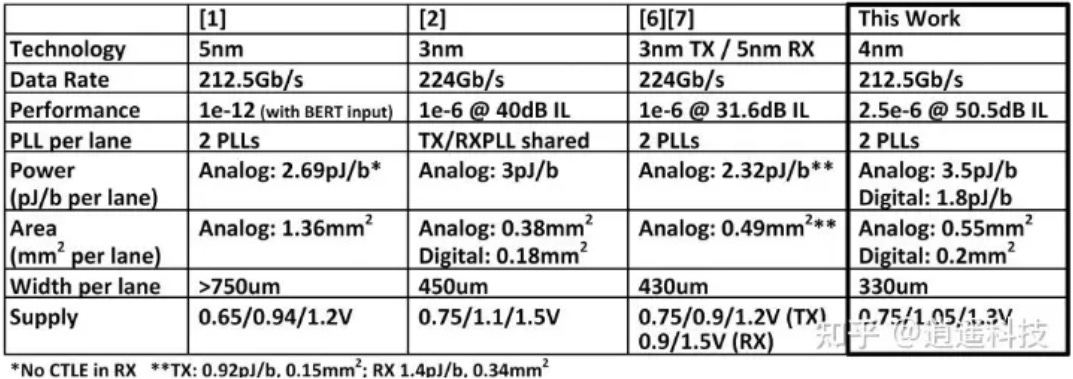
面積與佈局優勢 (Area & Width): 其單通道總寬度僅 330 um (類比 0.55 mm² + 數位 0.2 mm²),是表中佈局最緊湊的設計。這對於需要在一顆 ASIC 邊緣塞入數百個 SerDes 通道 (如 AI 交換器) 的高密度封裝極具戰略價值。

source: ISSCC25
212.5 Gb/s SerDes 實體層 (PHY) 採用 8 通道 (8-lane) 的對稱式緊湊佈局(1.6T=8x200G),其核心配置與架構指標如下:
中央共享資源 (置中設計): 佈局正中央垂直配置了 CMN (共用電路區塊) 與 JCPLL (Jitter Clean 鎖相迴路) 。CMN 集中提供跨通道的偏壓、參考訊號與控制介面,JCPLL 則負責提供低抖動的高頻時脈。置中配置能讓兩側通道對稱且就近取用資源,有效縮短時鐘分配路徑並節省整體佈局面積。
兩側對稱通道 (由上至下配置): 左右兩側各對稱排列 4 個通道,每個通道內部由上至下依序分為三個功能區段 :
TX (發射器區塊): 位於最上方,整合了高解析度分段式 DAC、多工器與輸出驅動器融合電路 。
RX (接收器區塊): 位於中段,包含類比前端的連續時間線性等化器 (CTLE)、可變增益放大器 (VGA) 以及時間交錯取樣網路的追蹤保持電路 。
DSP (數位後端區塊): 位於最下方,佔據底端顯著的佈局面積,專門提供複雜等化演算法(如 FFE/DFE 與反射消除)所需的強大數位算力 。
3. MTK solutions for SI
3.1. 訊號完整性 (Signal Integrity)的挑戰
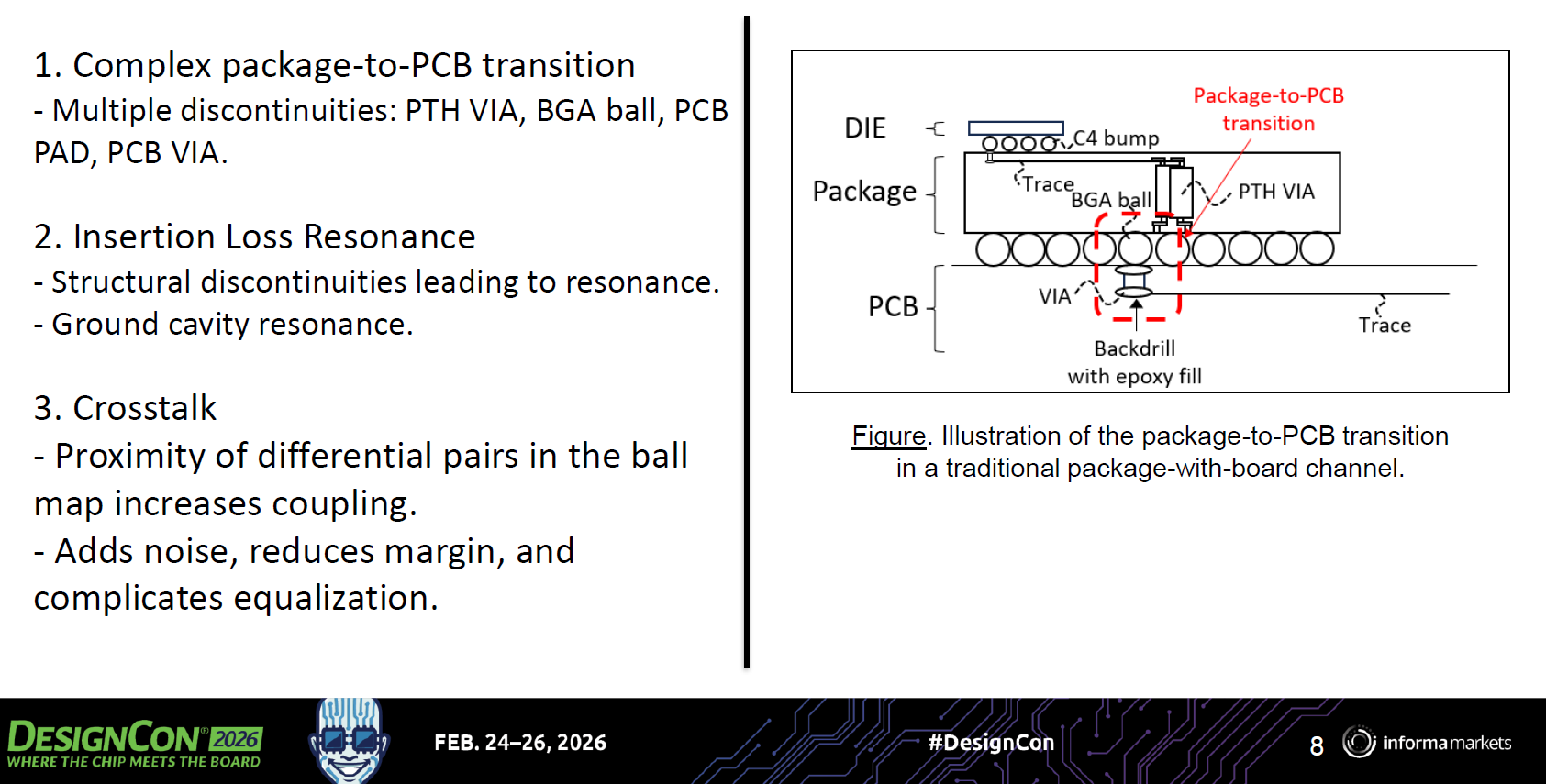
在 224G 等級的超高速傳輸中,封裝到電路板 (Package-to-PCB) 的過渡區域是訊號完整性 (Signal Integrity) 面臨最嚴峻考驗的瓶頸之一。主要涵蓋以下電磁挑戰:
source: DesignCon26
複雜的物理結構不連續性 (Complex Structural Discontinuities)
高速訊號從封裝內部傳遞到主機板走線,必須連續穿過多種截然不同的物理介面:
傳輸路徑: 封裝走線 -> BGA 錫球 (BGA Ball) -> PCB 焊墊 (PCB PAD) -> PCB 鍍通孔 (PTH VIA) -> PCB 走線。
阻抗衝擊: 每一次實體結構與材質的轉換,都會造成阻抗不連續,進而引發嚴重的訊號反射。圖中特別標示出,為了將這種反射降至最低,必須在 PCB 端採用背鑽技術並填充環氧樹脂 (Backdrill with epoxy fill),以切除多餘的導通孔短截線 (Via Stub)。
高密度腳位引發的嚴重串擾 (Crosstalk)
近接耦合效應: 為了滿足 AI 與網路交換晶片龐大的 I/O 頻寬,差分訊號對 (Differential pairs) 在 BGA 腳位分佈圖 (Ball map) 中被壓縮得極度緊密。
系統級負擔: 物理距離的拉近會引發強烈的電磁耦合,大幅增加通道間的串擾雜訊。這不僅會直接吃掉寶貴的訊號餘裕 (Margin),還會讓接收端 (RX) 數位訊號處理器 (DSP) 的等化補償演算法變得異常複雜且耗電。
接地空腔共振引發的損耗 (Ground Cavity Resonance)
在極高頻環境下,封裝與 PCB 之間的 BGA 陣列、接地導通孔與金屬參考層,會構成微小的半封閉電磁空腔 (Cavity)。當訊號頻率命中其共振點時,能量會被大量困住並耗散,導致通道的插入損耗出現斷崖式的深谷。

source: DesignCon26
共振頻率的決定因素: 高階共振模式的截止頻率,主要受到 PCB 端的接地導通孔陣列 (Ground via array) 排列方式所控制,而非僅僅取決於 BGA 錫球的間距 (Pitch)。
PCB 與 BGA 區域的差異: 由於 PCB 材料的介電特性 (Dielectric properties) 與結構厚度與封裝載板不同,PCB 區域的空腔共振頻率實際上會低於 BGA 區域。因此,硬體設計階段必須透過特徵模態分析 (Eigenmode Analysis),謹慎評估正方形 (Square) 或六角形 (Hexagonal) 的接地孔陣列佈局,以避開 224G 訊號的關鍵頻段。
空腔共振的激發理論
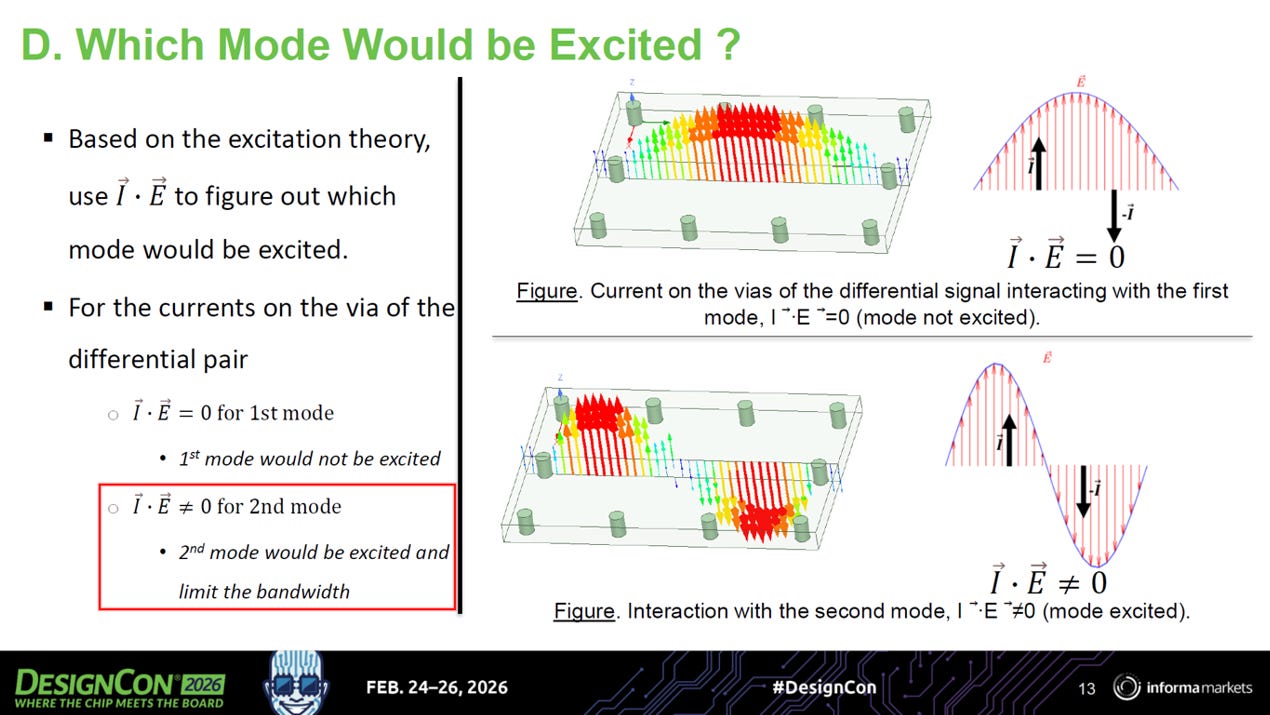
source: DesignCon26
核心關鍵:激發取決於「極性對齊」
決定一個空腔共振會不會發生破壞性影響的關鍵,在於差分訊號的電流方向 (I) 是否與該共振模態的電場極性 (E) 產生耦合 (I · E ≠ 0)
第一模態 (低頻共振) ➡ 安全: 第一模態的電場在兩個導通孔 (Via) 處都是相同的極性 (如:都是正)。但差分訊號的電流是一正一反,兩者作用後完美互相抵銷 (激發量為 0)。因此,第一模態不會被激發,不會破壞訊號。
第二模態 (高頻共振) ➡ 災難: 第二模態的電場在兩個 Via 處剛好是一正一反。這完美順應了差分訊號一正一反的電流方向,導致能量強烈疊加 (激發量 ≠ 0)。訊號能量會被大量吸入空腔中耗散,形成嚴重的插入損耗斷層,直接限制通道的高頻可用頻寬。
3.2. MTK Solutions
3.2.1. 六角形陣列佈局
在 224G 高速傳輸系統中,PCB 接地導通孔 (Ground Via) 的排列方式會直接決定「接地空腔共振 (Ground Cavity Resonance)」的頻率落點。將陣列佈局由正方形 (Square) 改為六角形 (Hexagonal),是高頻硬體設計中,將破壞性共振推離關鍵訊號頻段的核心策略。
共振頻率偏移 (Resonance Frequency Shift)
在維持相同的接地孔間距 (0.95mm) 的基準下,兩種佈局的特徵模態分析 (Eigenmode Analysis) 展現出截然不同的共振頻率 (f1 為第一階共振,f2 為第二階共振):
正方形陣列 (Square Lattice): f1 落於 49.4 GHz,f2 落於 67.2 GHz。
六角形陣列 (Hexagonal Lattice): f1 被顯著推升至 54.5 GHz,f2 提升至 72.3 GHz。


source: DesignCon26
物理機制的改變 (Cavity Size Reduction)
共振頻率之所以會發生位移,純粹是幾何空間堆積效率所引發的電磁邊界變化:
極致的空間緊湊性: 六角形佈局 (蜂巢狀排列) 在二維平面上能達成最緊密的堆積 (Compact package design)。
縮小等效空腔: 這種緊密的排列,在物理上大幅縮小了由多個接地孔所圍成的「等效空腔體積 (Smaller ground cavity size)」。
微波共振特性: 依據電磁學中的共振腔原理,腔室的物理尺寸越小,其對應的自然共振頻率就會往更高頻移動。
對 224G 系統設計的關鍵決策意義
這項頻率的推移對 224G (112 GBaud PAM4) 的訊號完整性具有決定性的影響。224G 訊號的 Nyquist 頻率大約落在 53 GHz 至 56 GHz 區間:
正方形佈局的致命傷: 其 49.4 GHz 的第一階共振點會直接落在 224G 訊號的主能量頻帶內部。這會導致該頻段的電磁能量被空腔大量困住並耗散,引發嚴重的插入損耗斷層 (Insertion Loss Resonance Sucks-out)。
六角形佈局的救援: 將第一階共振點推升至 54.5 GHz 後,共振點被移至訊號主頻帶的極端邊緣。這大幅減輕了對主要資料載波能量的吞噬效應,為接收端 (RX) 的 DSP 爭取到能夠將訊號等化還原的寶貴餘裕 (Margin)。
3.2.2. HDI 技術介入
核心策略:縮小接地空腔尺寸 (Shrinking the Ground Cavity Size)
共振腔的物理尺寸與其共振頻率成反比。要提高共振頻率,最直接有效的方法就是縮小圍繞訊號導通孔 (Signal Via) 的「接地圍牆」範圍。
具體工程手法:引進 HDI 技術重新配置 Ground Via
傳統佈局的瓶頸 (圖 E): 在傳統的 PKG-on-PCB 介面中,接地導通孔 (Ground Vias,圖中的綠柱) 通常直接放置在 BGA 焊墊的正下方。這導致圍繞中間兩個藍色差分訊號孔的空腔空間較大。在這種佈局下,第二階共振頻率大約落在 72.3 GHz,當運作頻率超過此點時,訊號完整性就會受到共振激發的嚴重破壞。
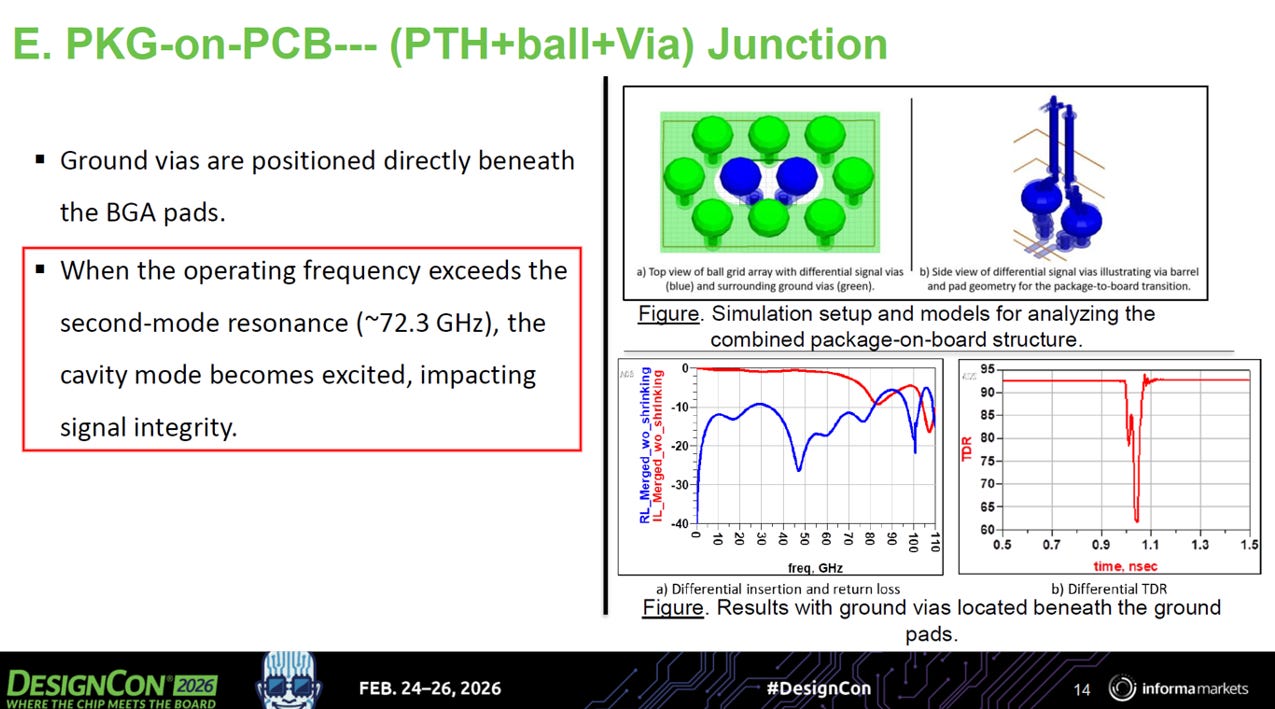
source: DesignCon26
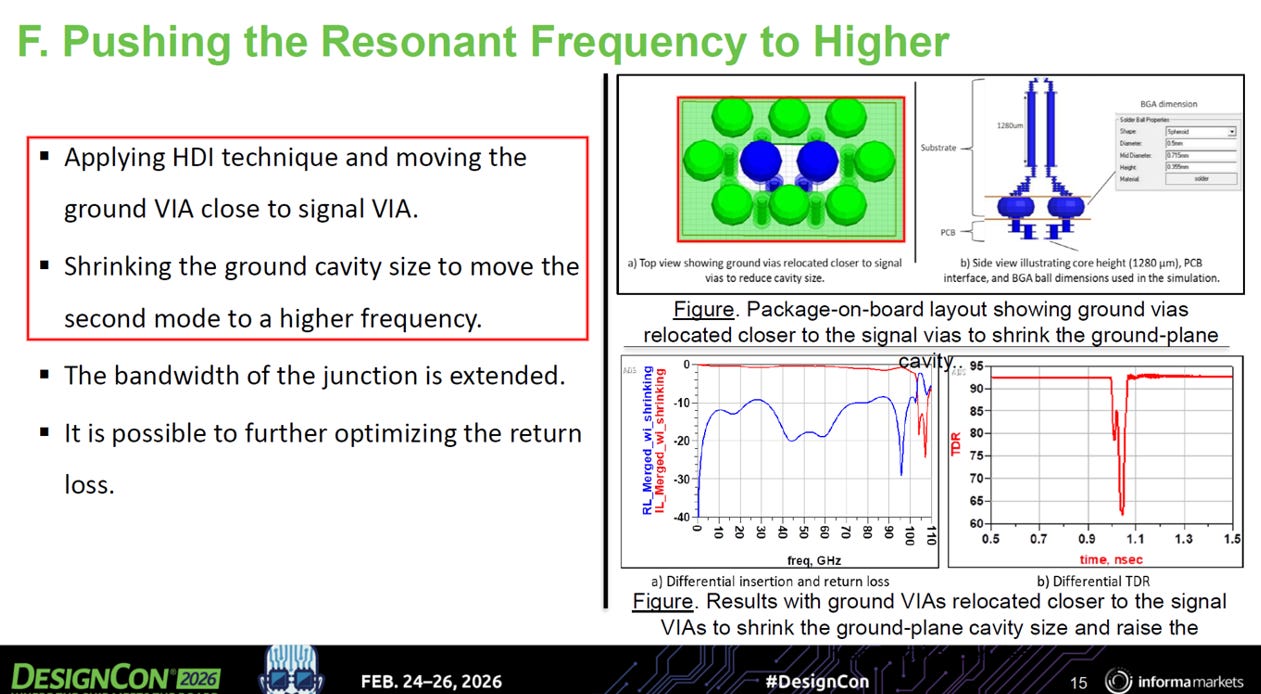
HDI 技術介入 (圖 F): 為了解決這個問題,設計師導入了高密度互連 (HDI, High Density Interconnect) 技術。HDI 允許在 PCB 內部進行更精細、更密集的鑽孔與佈線。
source: DesignCon26
向內逼近 (Relocating closer to signal vias): 如圖 F 右上角的俯視圖所示,設計師利用 HDI 技術,將周圍的 Ground Vias (綠柱) 刻意往內側移動,使其更加逼近中心的差分 Signal Vias (藍柱)。
物理結果與頻寬延伸: 這個物理上的「向內靠攏」動作,實質上壓縮了訊號孔周圍的電磁空腔體積。空腔變小了,其對應的第二階共振頻率就被硬生生地往更高頻段推移(遠離 72.3 GHz,向 100 GHz 逼近)。觀察圖 F 右下角的頻率響應圖 (紅色曲線),可以發現原本在 70-80 GHz 附近的插入損耗 (IL) 陡降現象被有效延後了,整體接合處的可用頻寬 (Bandwidth of the junction) 獲得了實質的延伸。
將共振頻率推高,仰賴的是打破傳統「直上直下」的 BGA 佈線思維。透過 HDI 技術的微孔能力,將接地孔陣列刻意向訊號孔緊縮,人為製造更狹小的電磁空腔,藉此將破壞性的共振陷阱移出 224G 訊號的關鍵運作頻段之外。
3.2.3. 串擾抑制
差分訊號對 (Differential Pairs) 之間的「幾何排列方向 (Orientation)」直接影響通道間的串擾 (Crosstalk) 雜訊。這對於 200G 世代的晶片佈局 (Floorplanning) 具有決定性的指導意義。
幾何排列的複雜性 (Orientation Configurations)
在 BGA 錫球陣列中,為了將大量的 I/O 腳位擠入有限的面積,相鄰的差分訊號對 (圖中的藍色球與紅色球) 無法總是保持完美的平行。
正方形陣列 (Square Grid): 由於水平與垂直的物理限制,產生了多達 23 種 不同的差分對相對位置排列 (如 Edge-coupled, Broadside-coupled, 各種角度的偏移等)。
六角形陣列 (Hexagonal Grid): 雖然堆積更緊密,但由於其幾何對稱性,差分對的相對排列種類減少至 17 種。
這意味著硬體工程師在進行佈線時,訊號會隨機遭遇這數十種不同的電磁耦合場景,每種場景的串擾強度都不一樣。

source: DesignCon26
串擾結果的對比 (PSXtalk & ICN Results)
這些不同排列方式在 50G, 100G, 以及 200G (灰線) 運作頻率下的串擾測試結果。關注兩個指標:PSXtalk (總和功率串擾,越低越好) 與 ICN (總積分串擾雜訊,越低越好)
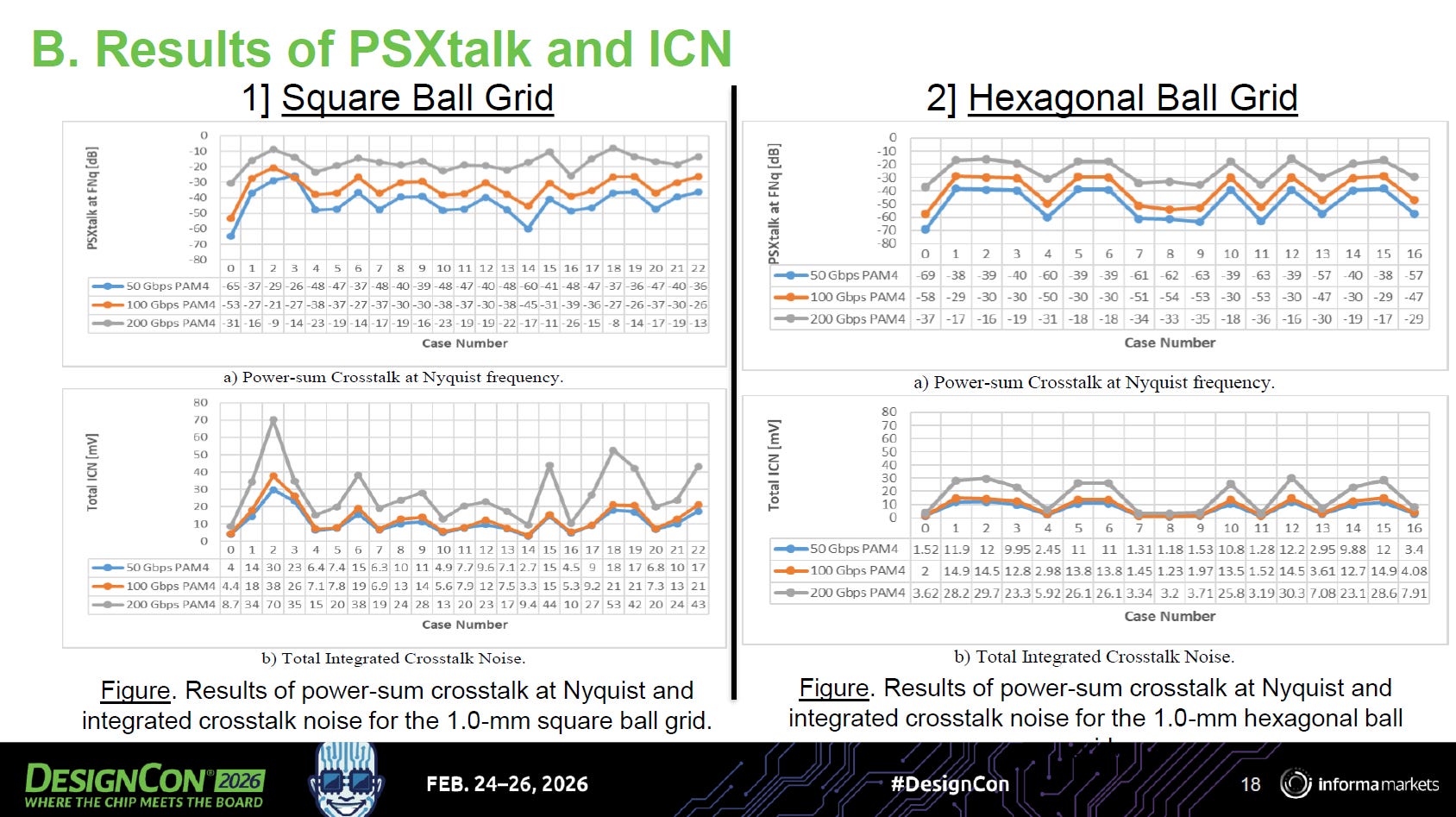
source: DesignCon26
致命的幾何排列 (Worst Cases): 觀察左側的正方形陣列圖表 (特別是灰色的 200G 曲線)。在特定的 Case Number (例如 Case 2, Case 15, Case 19),其 ICN 雜訊會出現劇烈的突波 (Spikes),甚至飆升超過 60 mV。這些特定的「面對面 (Broadside)」或「緊密斜角」排列,會導致兩對差分訊號的電磁場嚴重重疊,引發嚴重的串擾。
六角形陣列的雜訊抑制優勢 (Hexagonal Superiority): 觀察右側的六角形陣列圖表,情況出現了戲劇性的好轉。
雜訊峰值被削平: 即便是在最糟的排列下,其 ICN 雜訊的最高峰值也僅在 30 mV 左右,只有正方形陣列最糟情況的一半。
一致性極高: 不論是哪一種 Case,六角形陣列的串擾曲線起伏都相對平緩。這代表不論工程師怎麼佈線,通道間受到的干擾都非常穩定且可預期。
總結:六角形佈局的系統級價值
將 BGA 陣列由正方形改為六角形,除了先前提到能「推高空腔共振頻率」之外,在這裡展現了第二個巨大的系統級優勢:大幅降低並穩定了差分對之間的串擾雜訊。
這對 DSP 設計工程師來說是個天大的好消息。因為串擾雜訊如果忽高忽低 (如正方形陣列),DSP 的等化器 (Equalizer) 就必須花費極大的功耗與算力去動態適應。而六角形陣列提供了一致且較低的雜訊基準,能顯著減輕 224G 晶片內部的運算負擔。
3.2.4. 封裝互連演進
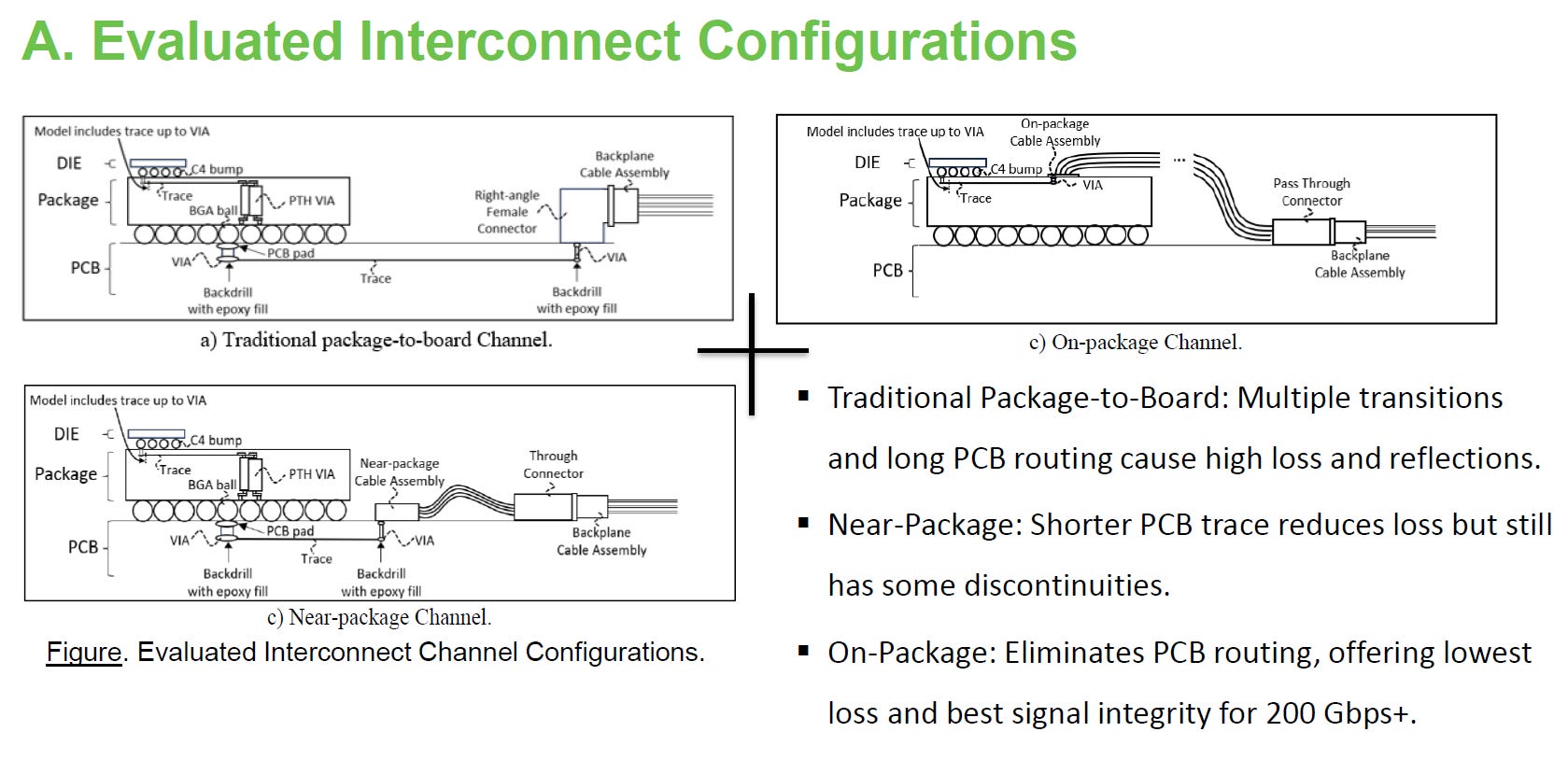
source: DesignCon26
傳統與近封裝架構的物理極限: 只要訊號還需要往下走,穿透 BGA 錫球與 PCB 導通孔 (Via),就無可避免地會落入「空腔共振 (Cavity Resonance)」與嚴重的阻抗不連續陷阱,導致 224G 高頻訊號產生衰減。
On-Package 的終極優勢 (繞過 PCB): 透過直接在封裝層面接上高頻纜線 (如 CPC, Co-Package Copper) 或光學模組 (CPO),徹底捨棄主機板 (PCB) 走線。這從根本上消除了 BGA 介面的共振問題,並將傳輸損耗降至最低,是目前確保 200G+ 訊號完整性最有效的架構解答(請參考: EP43. 400G高速互連技術解析:共封裝銅纜 (CPC)的挑戰)
4. 結論
邁入 200G+ (224 Gbps) 世代,極端的物理通道損耗與先進封裝內的介電損耗,使得傳統仰賴類比電路的 SerDes 架構面臨發展瓶頸。聯發科 (MTK) 透過全面數位化的 DSP 架構,結合高解析度 7-bit DAC、四分之一速率 (Quarter-Rate) 時脈架構,以及高度平行的時間交錯 SAR ADC 陣列,成功克服 100+ GS/s 的高頻取樣限制。
在訊號完整性 (SI) 解決方案上,透過改採六角形 BGA 陣列佈局與 HDI 技術限縮接地導通孔 (Ground Via) 的距離,有效將破壞性的接地空腔共振 (Ground Cavity Resonance) 推移至訊號主頻帶之外,並大幅抑制了差分對之間的串擾雜訊。測試數據顯示,該晶片能在高達 50.5 dB 的極端通道損耗下,依然維持優異的前向錯誤更正前誤碼率 (Pre-FEC BER),證明了數位後端 MLSD 演算法的強健性。
MTK 212.5G SerDes 憑藉其在面積與功耗上的競爭優勢,為 Google TPU v8i 提供了穩定的高速 I/O 底層支撐,進一步確立了其在高效能 AI 晶片供應鏈中的技術地位。
[Reference]
E-Hung Chen, ISSCC26, “State-of-the-Art 200+ Gb/s Electrical and
Optical Interconnects“
DCON26_SLIDES_Track07_Advancing Signal Integrity for High-Speed SerDes From Package-Board Constraints to On-PackageIn_188_156