EP39. 突破 200Gbps 傳輸極限:NVIDIA 微環調變器技術探討

隨著 AI 運算工作負載的快速擴張,資料中心正從以 CPU 為中心的架構轉向 GPU 驅動的系統,這對互連頻寬密度與功耗提出了嚴苛的要求 。在此背景下,共同封裝光學 (CPO) 架構被視為具備高度潛力的解決方案,相較於傳統可插拔光模組,CPO 能顯著提升能源效率並縮短高速電氣路徑 。
NVIDIA 於 2025 年 GTC 大會上發布了基於 TSMC COUPE 平台的 1.6 Tbps CPO 交換器,展示了矽基微環調變器 (Micro-Ring Modulator, MRM) 在高密度光學互連中的實用性 。在 OFC 2026 的最新文獻中,NVIDIA 進一步探討了將 MRM 推升至單波 200Gb/s (100 Gbaud PAM-4) 速率的技術路徑 。本文將基於該文獻,從電學頻寬展延、光學動態特性,以及光電熱協同模擬三個維度,解析 200Gbps MRM 設計背後的物理機制與工程權衡。
1. Background: 矽光子調變器
1.1. Modulators for SiPH of CPO
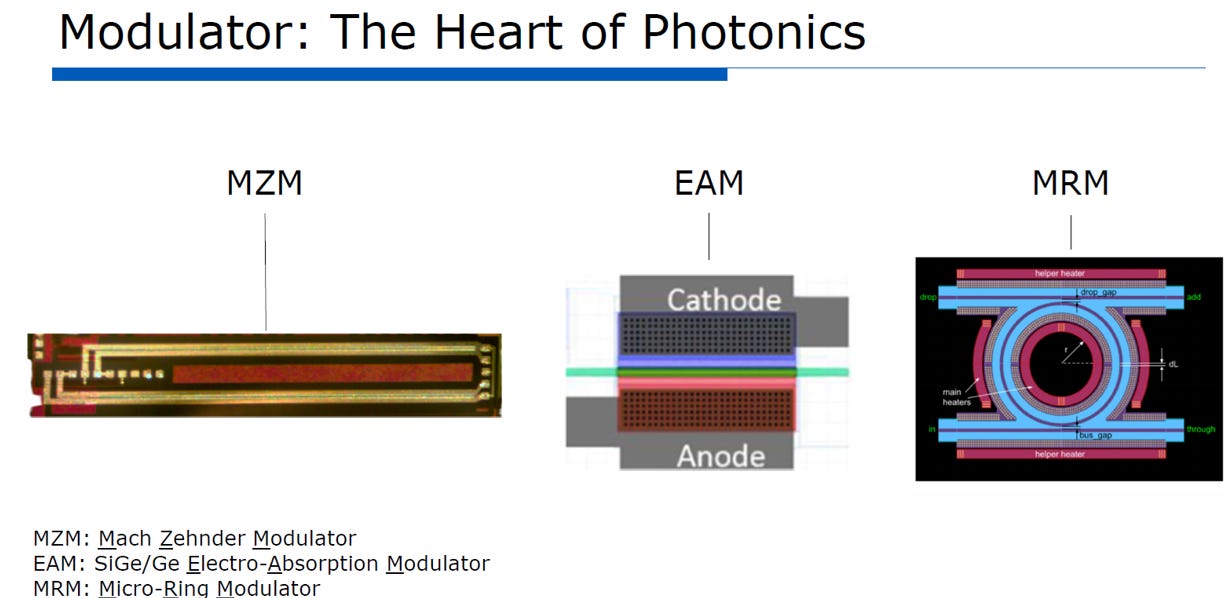
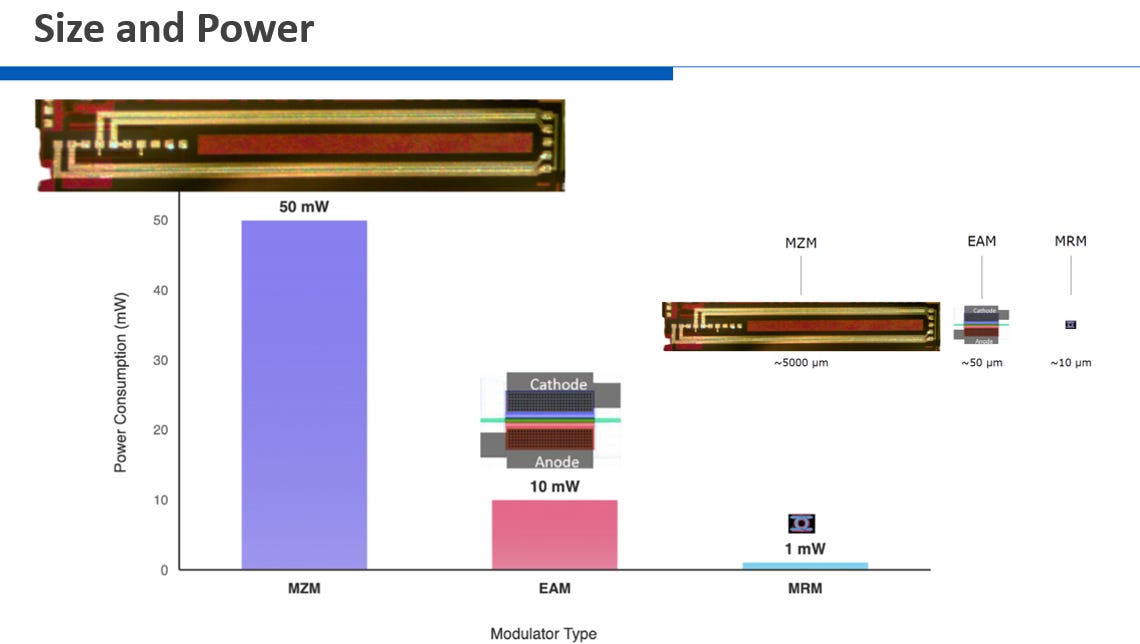
在共同封裝光學 (CPO)架構中的矽光子 (Silicon Photonics, SiPh) ,光調變器 (Modulator) 扮演「電光轉換(EO)」的核心角色。它負責將晶片運算出的高速電子訊號,轉換為光纖中傳輸的光訊號。由於資料中心與 AI 運算對頻寬密度、功耗與散熱的要求日益嚴苛,產業界在調變器的選擇上出現了不同的技術路線。各家大廠依據其系統架構的需求與權衡 (Trade-off),分別有 MZM、EAM 與 MRM 三種主要技術(請參考EP14. SiPH MRM介紹; EP27. Marvell + Celestial AI = ?)。
source: Lightmatter
source: Lightmatter
MZM (Broadcom 採用):主打訊號穩定
優勢: 訊號品質最佳,且不易受溫度變化影響。
劣勢: 物理體積最大,難以滿足極致的封裝密度需求。
定位: 適用於傳統要求高可靠性與長距離傳輸的網路交換器。
EAM (Celestial AI採用):主打平衡與低功耗
優勢: 體積適中,驅動電壓極低,有助降低動態功耗。
劣勢: 光損耗較高,且需特殊材料 (鍺) 增加製程複雜度。
定位: 適用於距離較短但需兼顧密度與功耗的晶片或機架間互連
Marvell 已於 2026 年初完成對Celestial AI的收購(高達 32.5 億美元)
MRM (NVIDIA 採用):主打極致頻寬密度
優勢: 體積極小 (微米級),極易實現分波多工 (WDM),提供最高的頻寬密度。
劣勢: 對溫度極度敏感,易導致訊號遺失。
定位: 透過先進的 3D 封裝 (如 TSMC COUPE) 與微型加熱迴路克服熱控制難題,專攻 AI 運算所需的極高密度互連。
source: Lightmatter
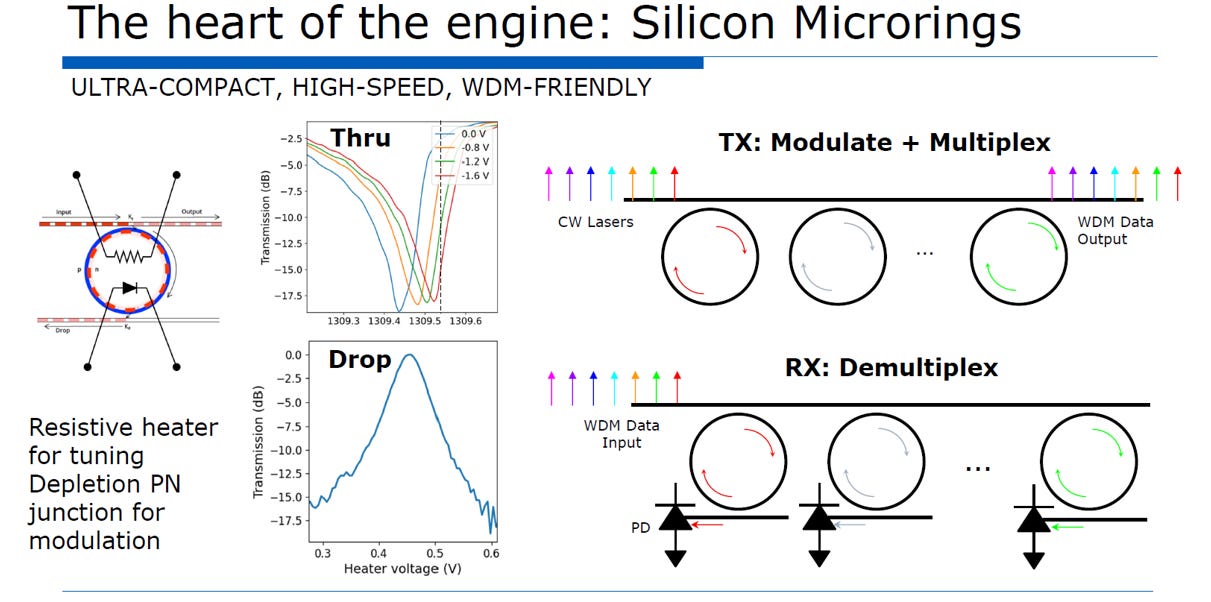
1.2. Si based MRM
矽基微環調變器 (Silicon-based Micro-Ring Modulator, MRM) 是利用光學共振原理進行電光轉換的核心元件。
source: Intel
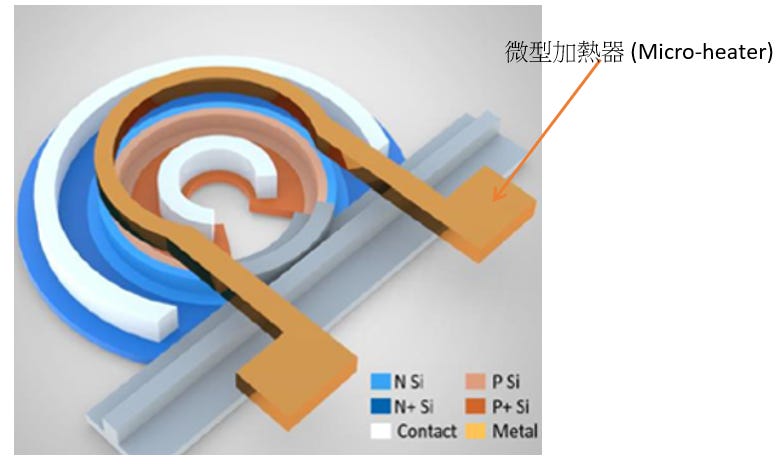
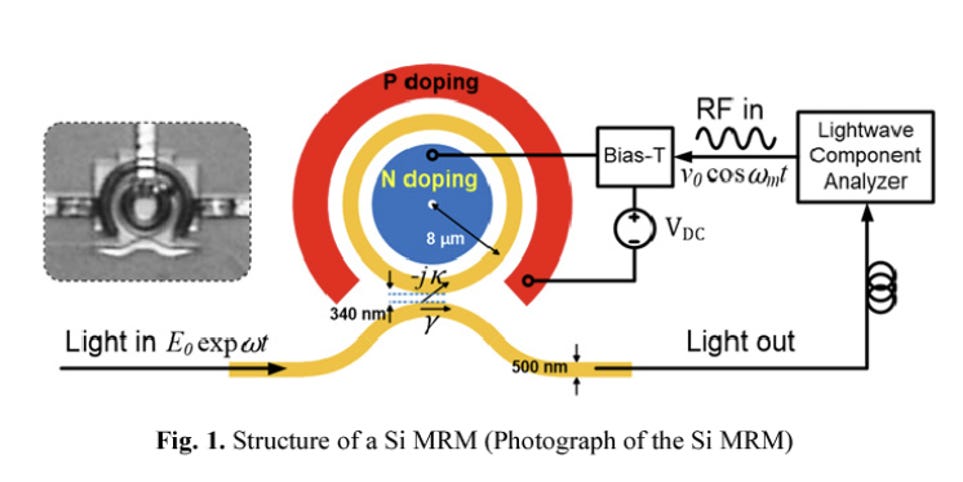
物理結構 (P-N Junction, Contact, Heater)
P-N 接面 (P-N Junction):
微環波導的核心區域由摻雜的矽構成,形成 P 型 (圖中淺橘色 P Si) 與 N 型 (圖中淺藍色 N Si) 半導體介面。這是執行高速光調變的主動區。為了與金屬電極建立低電阻的歐姆接觸,波導外圍會進行高濃度摻雜,形成 P+ Si 與 N+ Si 區域。
接觸電極 (Contact):
圖中以白色標示的區塊。這些是導電通孔 (Vias),負責將高濃度的 P+ 與 N+ 矽結構往上連接至電子積體電路 (EIC) 的金屬佈線。高速驅動電訊號便是透過這些 Contact 注入 P-N 接面。
微型加熱器 (Heater):
位於波導上方的金屬環形結構 (箭頭所指處)。矽的折射率具有顯著的熱光效應 (Thermo-optic effect),微環的共振波長會隨環境溫度漂移。加熱器透過輸入低頻直流電流產生焦耳熱,提供局部的溫度控制,將微環的共振波長精確「鎖定」在雷射的工作波長上。
運作核心物理機制 (Plasma Dispersion 原理)
純矽材料缺乏天然的線性電光效應 (普克爾效應 Pockels effect),因此矽光子技術必須依賴電漿色散效應 (Plasma Dispersion Effect,或稱自由載子色散效應) 來改變光學特性。
載子濃度與折射率的關聯: 根據此物理原理,當矽材料內部的自由載子 (電子與電洞) 濃度發生改變時,會同步改變矽波導的「折射率」與「光吸收係數」。
空乏型調變 (Depletion Mode): 在 MRM 中,最常採用逆向偏壓 (Reverse Bias) 來操作 P-N 接面。施加電壓會改變 P-N 接面中間「空乏區 (Depletion Region)」的寬度,進而將載子推開或拉回。這種載子濃度的瞬間抽離或注入,會引發波導有效折射率的改變,這是達成超高速 (如 100Gbps 或 200Gbps) 訊號調變的物理基礎。
source: Lightmatter
source: Intel
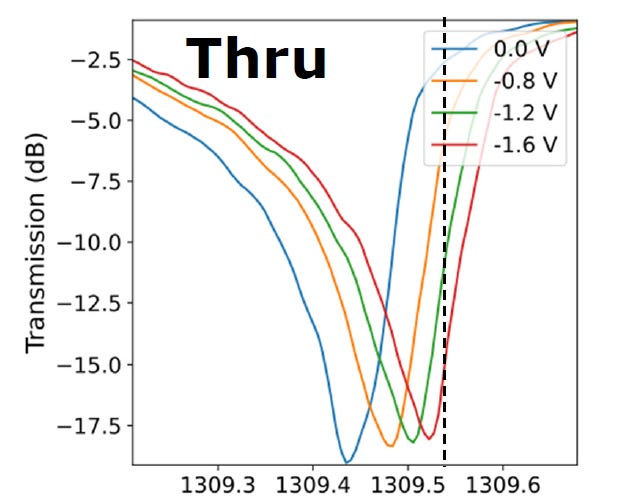
在矽光子微環調變器 (MRM) 的實務設計中,將雷射載波 (λin) 設定在共振頻譜的左側 (較短波長、高頻率端,稱為 Blue-detuned),而非右側,主要是基於熱穩定性的物理考量。
決定性原因:熱穩定性 (Thermal Stability) 與負回饋機制
矽材料具有極強的熱光效應 (Thermo-optic effect),即溫度上升會導致折射率增加。當強功率的雷射光耦合進入微環內部時,光學損耗 (如雙光子吸收或載子吸收) 會產生熱能,使微環局部升溫。這個熱效應會使整個共振頻譜向右側 (長波長端,即紅移 Red-shift) 偏移:
若將 λin設在左側 (目前作法):
當微環發熱導致頻譜向右偏移時,共振谷底會「遠離」固定的雷射波長 λin。這會導致耦合進入微環內部的光能量減少,發熱量隨之降低,微環逐漸冷卻並將頻譜拉回原位。
這是一個負回饋 (Negative Feedback) 系統,能自動維持光學工作點的動態穩定。
若將 λin設在右側 (不被採用):
當微環發熱使頻譜向右偏移時,共振谷底反而會「靠近」雷射波長 λin。這會導致更多的光能量進入微環,產生更多熱量,促使頻譜進一步右移。
這是一個正回饋 (Positive Feedback) 系統,會引發「熱失控 (Thermal Runaway)」或雙穩態現象,導致調變器完全失去控制。
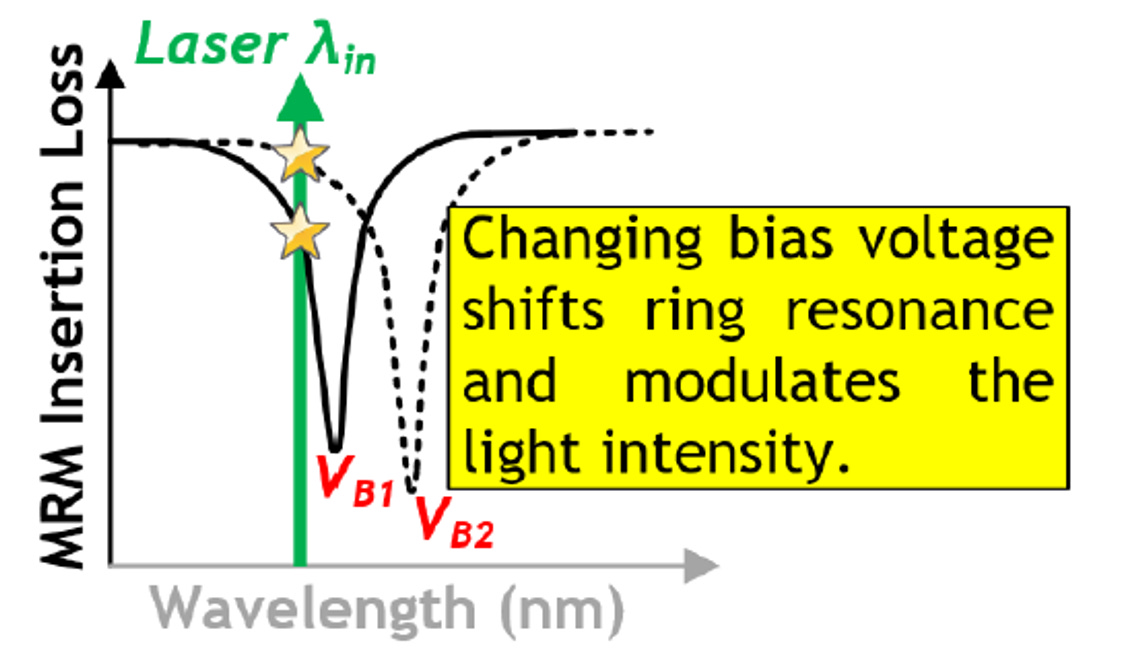
配合空乏型 (Depletion-mode) 調變機制
當施加更大的逆向偏壓 (由 VB1)增加到 VB2) 時,PN 接面的空乏區變寬,自由載子被抽離。
根據矽的光學色散物理,載子濃度下降會導致矽的折射率上升。折射率上升同樣會使共振頻譜向右側 (紅移) 偏移。
當 λin鎖定在左側斜坡時,頻譜從VB1往右移動到 VB2 的過程中,該波長對應的「插入損耗 (Insertion Loss)」會從下方星星,代表光強度弱,訊號 Level 0,到上方星星,代表光強度強,訊號 Level 1。這形成了一個正向的振幅調變邏輯。
1.3. 微環調製器的光學與電學互動
source: IEEE
物理機制的根本差異:共振 vs. 寬頻低通
電學端需要「寬頻低通」:MRM 的輸入端接收的是數位基頻訊號(如 200Gbps PAM4)。數位訊號的頻譜非常寬廣,從 0 Hz (DC) 一直平坦地延伸到50GHz (奈奎斯特頻率)。因此,電氣輸入端必須表現為一個平滑的低通濾波器,讓所有頻率成分都能無失真地通過。
光學端需要「共振」:MRM 的光學本質是一個諧振腔。它必須依靠光波在環內的多次建設性干涉(共振),才能放大微小的折射率變化。既然是共振系統,就必須使用 Optical Q 來量化其能量儲存能力與共振峰的銳利度。
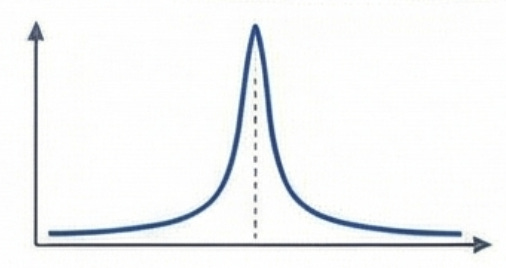
MRM 的建模就是一個多變數的最佳化過程,旨在 200Gbps 的硬性速度要求下,找出電氣參數與光學物理結構的最佳妥協點。
1.4. 首款 200G/lambda 微環調變器
NVIDIA 在 2025 GTC 推出Quantum-X Photonic Switch 的 CPO,基於TSMC COUPE 製程以及業界首款 200G/lambda 微環調變器 (Micro-Ring Modulator, MRM) 設計:
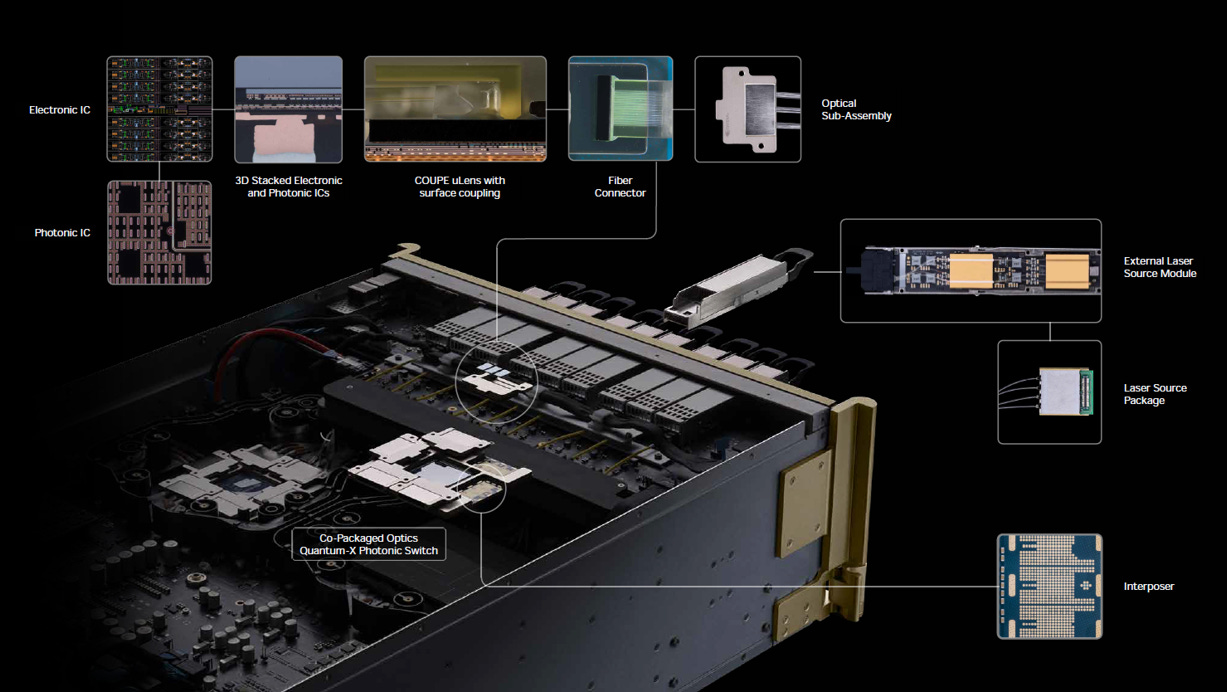
source: Nvidia
極小化尺寸與超高頻寬密度
傳統矽光子多採用體積較大(毫米等級)的馬赫-曾德爾調變器 (MZM),難以滿足 CPO 的高密度需求。MRM 的尺寸僅微米等級,大幅縮小物理尺寸,允許在單一光子積體電路 (PIC) 上高密度佈建光學通道,從而實現數十 Tbps 的總頻寬。
單波長 200G PAM4 訊號處理
此 MRM 設計具備極高的調變頻寬與線性度,能夠直接對接交換器 ASIC 上的 200G SerDes,穩定調變並傳輸單波長 200 Gbps 的 PAM4 高速訊號。
突破熱敏感限制 (波長鎖定)
MRM 先天對溫度變化極度敏感,溫漂易導致諧振波長偏移而遺失訊號。此方案的成功關鍵在於電子積體電路 (EIC) 中設計了精準的閉環控制迴路,透過微型加熱器 (Micro-heater) 進行即時且精確的熱補償與波長鎖定 (Wavelength Locking)
高度依賴 3D 封裝 (TSMC COUPE)
200Gbps MRM 的高效運作需仰賴極低的電氣損耗。TSMC COUPE 技術將驅動 MRM 的 EIC 透過 3D 混合鍵合(Hybrid Bonding)直接覆晶堆疊於 PIC 之上,將電氣傳輸路徑縮至最短,有效降低寄生電容與高頻訊號衰減。
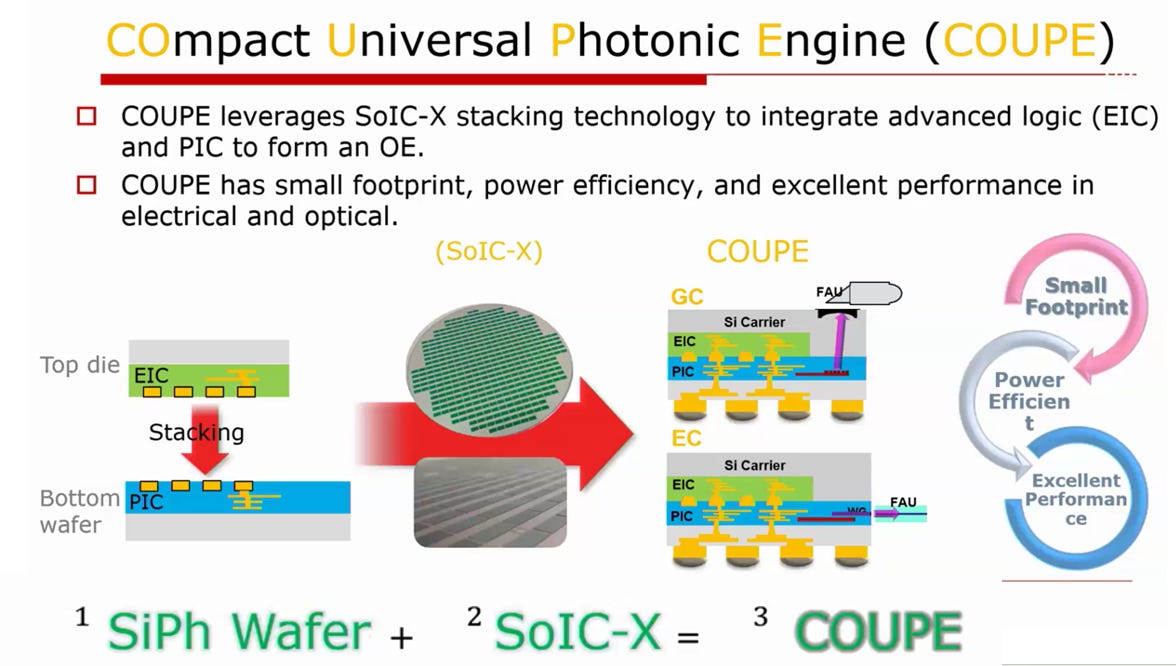
source: TSMC
COUPE 技術透過 3D 封裝與混合鍵合(Hybrid Bonding, HB)技術,將電子集成電路(EIC)與光子集成電路(PIC)直接垂直整合。這種做法徹底縮短了電氣路徑,將 RLC 寄生參數降至最低。在 200 Gbps 速率下,寄生參數的微小波動都會導致眼圖閉合。因此,利用 HB 技術實現的高度受控電氣界面,是確保高速信號完整性的最後一哩路(請參考EP37. 矽光子解析: 從 TSMC PDK 到 Nvidia 黑科技)
2. 電學特性分析
2.1. MRM Small signal model
下兩張圖展示了矽光子(Silicon Photonics)微環調變器的電氣小信號集總元件模型(Lumped-element model)以及其對應的頻率響應分析。這是在進行高速光收發模組設計時,評估電光頻寬極限與阻抗匹配的關鍵模型。
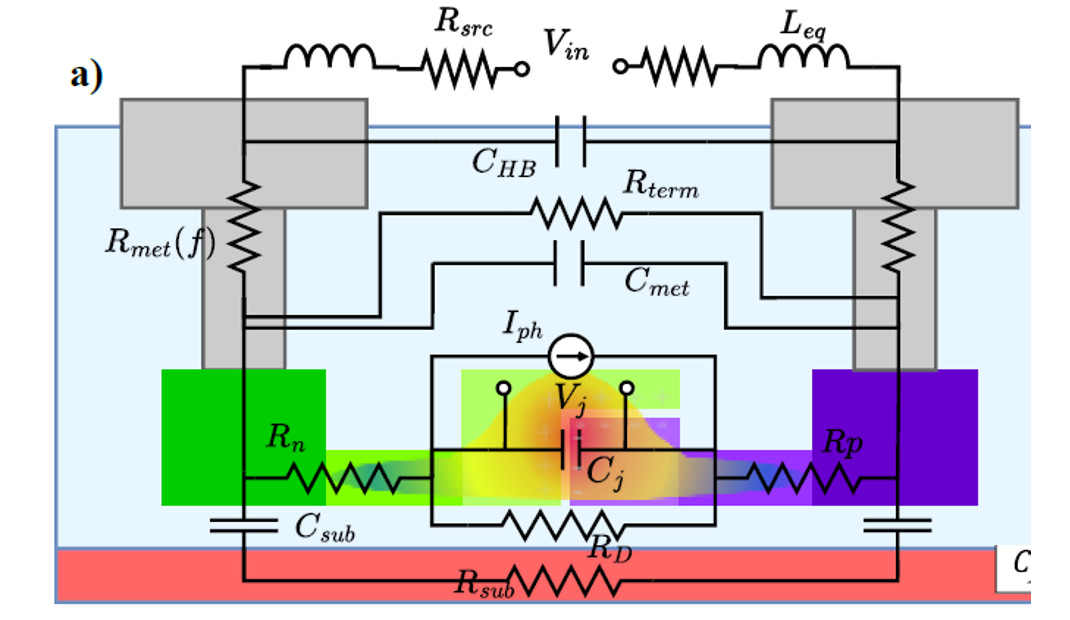
ource: OFC26. M2A.7, Nvidia
完整電氣小信號模型
將 MRM 的實體結構(包含金屬層、PN 接面、基板)對應到等效電路圖上。模型可以分為三個主要區塊:
核心 PN 接面 (Intrinsic Junction):
這是 MRM 產生電光效應(等離子色散效應)的核心。主要由接面電容 Cj 以及 P 型與 N 型摻雜區的串聯電阻(Rp 與 Rn,通常合併看作接面電阻 Rj)組成。Cj 與 Rj是決定元件本質頻寬的最關鍵參數。
寄生網路 (Parasitic Network):
包含金屬佈線與 Pad 帶來的寄生效應,如金屬電阻 Rmet(f)(可能隨頻率因集膚效應變化)、金屬間電容 Cmet、高頻旁路電容 CHB,以及與基板之間的寄生電容 Csub 和基板電阻 Rsub。這些寄生元件會分流高頻訊號,導致頻寬劣化。
外部驅動與端接 (Driver & Termination):
包含驅動端的訊號源阻抗 Rsrc、終端匹配電阻 Rterm,以及等效電感 Leq(通常來自打線 Wirebond、覆晶凸塊 Bump 或特定的電感佈線設計)。
ource: OFC26. M2A.7, Nvidia
系統轉移函數
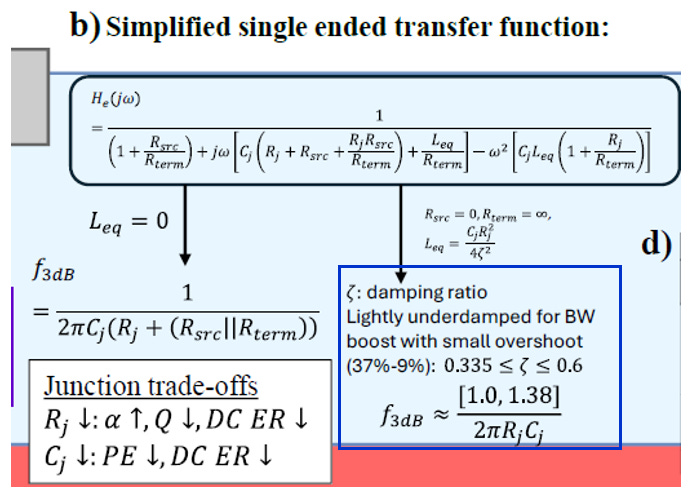
上方圖 的公式He(jω)定義了從輸入電壓到接面電壓的單端傳遞函數。因為模型中同時包含了電容(Cj 等)與電感(Leq),這是一個標準的二階(Second-order)低通濾波器響應系統。
分母中包含了 ω(一階)與 ω2(二階)的項,這決定了系統的阻尼係數與諧振頻率,也直接影響眼圖的品質(如上升時間與 Overshoot)。
簡易 RC 版本 (Leq= 0)
當系統不考慮電感效應(Leq= 0)時,傳遞函數退化為一階 RC 低通濾波器。這是評估 MRM 頻寬最基礎的基準點。
3dB 頻寬公式: f3dB = 1 / [2 * π * Cj * (Rj + ( Rsrc || Rterm))]
物理意義: 系統頻寬完全受限於核心電容 Cj 以及與之串聯的總電阻。這個總電阻包含了元件本身的 Rj,以及外部網路的等效電阻(驅動源電阻 Rsrc 與終端電阻 Rterm 的並聯值)。
若要提升純 RC 系統的頻寬,只能從降低串聯電阻 或 降低接面電容
Trade-offs: 電信號和光信號
降低 Rj(通常需要提高摻雜濃度):
提高摻雜濃度會引入大量自由載子,加劇自由載子吸收效應(Free Carrier Absorption, FCA),
導致光學損耗(α)增加、微環的品質因子(Q factor)下降,進而使直流消光比(DC ER)變差。
降低 Cj(通常需要減少接面面積或降低摻雜濃度):
會導致相位調變效率(Phase Efficiency, PE)下降,同樣會惡化直流消光比(DC ER)
ource: OFC26. M2A.7, Nvidia
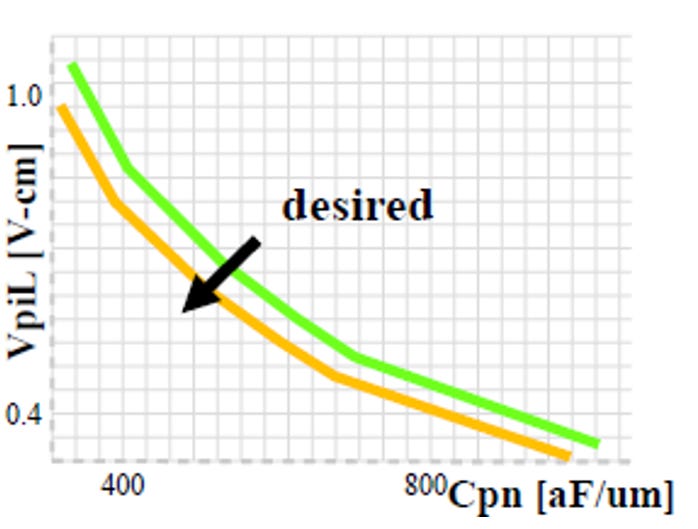
這張圖表展示了矽光子調變器設計中「調變效率」與「電氣頻寬」的物理互斥關係(Trade-off):
VpiL(相位調變效率,Y軸):
數值越小越好。代表能以更低的驅動電壓或更小的元件尺寸達成所需的光相位改變。
VpiL 是衡量光調變器效率的指標,為「達成 180 度相位改變所需的電壓 (Vpi)」與「調變區長度 (L)」的乘積
Cpn(接面電容,X軸):
數值越小越好。代表 RC 延遲越低,元件的高頻頻寬越大。
降低電容意味著削弱了電場對載子的控制力,因此需要耗費更多的電壓來彌補光學效能的不足
2.2. Inductive Peaking
在台積電 (TSMC) 的 COUPE (Compact Universal Photonic Engine) 共封裝光學架構下,電感峰化 (Inductive Peaking) 技術被視為突破電氣頻寬瓶頸、實現 200Gbps 傳輸速率的最佳解決方案。
COUPE SoIC-X 架構:降低寄生與精準控制電感
傳統的光電封裝(如打線 Wirebond 或微凸塊 Micro-bump)會引入極大且難以控制的寄生電感與電容,導致高頻訊號嚴重衰減並產生不可預測的反射。
TSMC 的 SoIC-X 屬於無凸塊 (Bumpless) 的前段 3D 晶片堆疊技術,能將光子晶片 (PIC) 與電子晶片 (EIC) 直接以銅對銅 (Cu-Cu) 鍵合,互連距離縮短至微米等級。這項技術大幅消除了不可控的封裝寄生效應。在寄生干擾被最小化的前提下,晶片設計者才能在佈局中,刻意加入並「精準控制」特定數值的峰化電感 (Peaking Inductor)。這個自訂的電感能夠真正發揮展延頻寬的作用,而不會與隨機的封裝寄生效應疊加而導致訊號失真。
source: OFC26. M2A.7, Nvidia
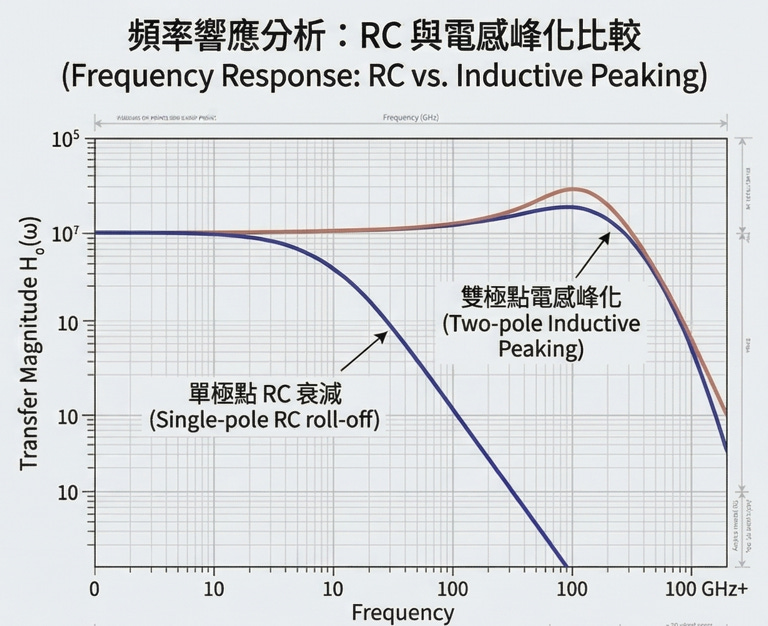
從單極點 (1-pole) 到雙極點 (2-pole):200Gbps 的頻寬展延
在純電阻與電容 (RC) 的系統中,訊號的傳遞函數屬於單極點 (One-pole) 低通濾波器。其高頻響應會隨著頻率增加而呈現平滑衰減,頻寬完全受限於 RC 時間常數,難以滿足 200Gbps(例如 100 Gbaud PAM4)所需的極高頻寬要求。
透過引入上述精準控制的電感 (L),系統會從一階 RC 網路轉換為包含 R、L、C 的雙極點 (Two-pole) 網路。在特定的高頻區段,該電感會與系統的寄生電容產生輕微的諧振 (Resonance)。這個諧振效應能提供額外的增益,剛好補償 RC 網路造成的高頻衰減。這種設計能將 -3dB 頻寬顯著向高頻推移 (Bandwidth Extension),在不改變電晶體或光學接面本質特性的情況下,突破物理限制。

source: OFC26. M2A.7, Nvidia
依賴先進 EDA 工具進行精準電磁模擬
在接近或超過 100GHz 的操作頻率下,晶片上的金屬佈線已不能視為理想導線,集膚效應 (Skin Effect)、鄰近效應與基板損耗變得極為顯著。
為了獲得準確的峰化電感值,傳統基於規則的 RC 萃取工具 (RC Extraction) 已不敷使用。工程師必須仰賴全波 (Full-wave) 或準靜態 (Quasi-static) 的電磁 (EM) 模擬工具,例如 Ansys RaptorX、Cadence EMX 或 Lorentz PeakView。這些工具能對自訂形狀的螺旋電感 (Spiral Inductor) 或傳輸線 (T-coil) 進行 3D 電磁場解析,確保萃取出的等效電感值 (L) 與品質因子 (Q) 完全符合雙極點電路模型所需的參數,藉此避免電感量過大造成的過度峰化 (Overshoot/Ringing),或電感量不足導致的頻寬展延失效
2.3. TSMC COUPE 的封裝優勢
TSMC COUPE (COmpact Universal Photonic Engine) 平台結合 SoIC-X (System-on-Integrated-Chips) 3D 堆疊技術,在光電共封裝架構下帶來的突破性電路設計優勢。SoIC-X 是一種無凸塊 (Bumpless) 的晶圓級 3D 堆疊技術,能將電子晶片 (EIC) 與矽光子晶片 (PIC) 進行超細間距的銅對銅直接鍵合。
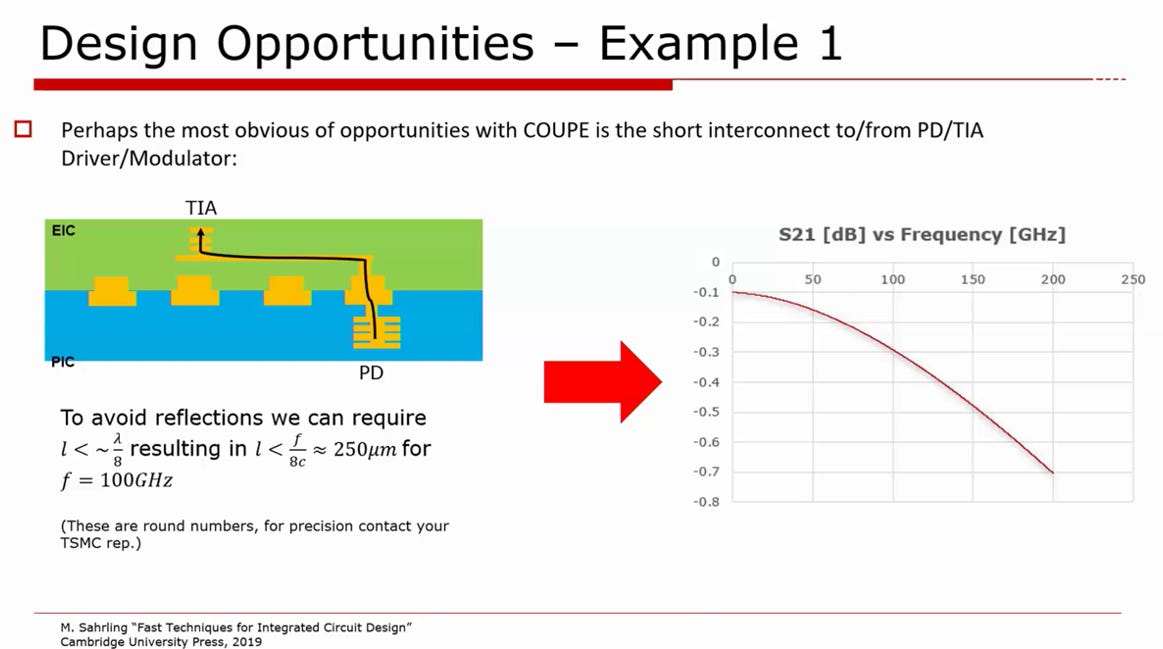
source: OFC25, TSMC
超短互連距離:消除高頻反射與損耗
物理挑戰: 在高頻 (如 100GHz) 傳輸時,為避免嚴重的訊號反射,傳輸線長度必須小於波長的八分之一 (l < 波長/8),這意味著互連長度必須小於 250微米。傳統的打線或微凸塊封裝極難達成此要求,導致高頻訊號嚴重衰減。
SoIC-X 優勢: 透過將 EIC (如 TIA 或 Driver) 直接 3D 覆晶堆疊於 PIC (PD 或 Modulator) 正上方,互連路徑幾乎僅剩下垂直過孔的距離 (遠小於 250微米)
工程效益: 從圖中的 S21 頻率響應圖可以看出,這種極短互連能確保訊號在高頻範圍內維持極低的損耗。這大幅簡化了高頻阻抗匹配的難度,並確保 200Gbps 訊號的完整性
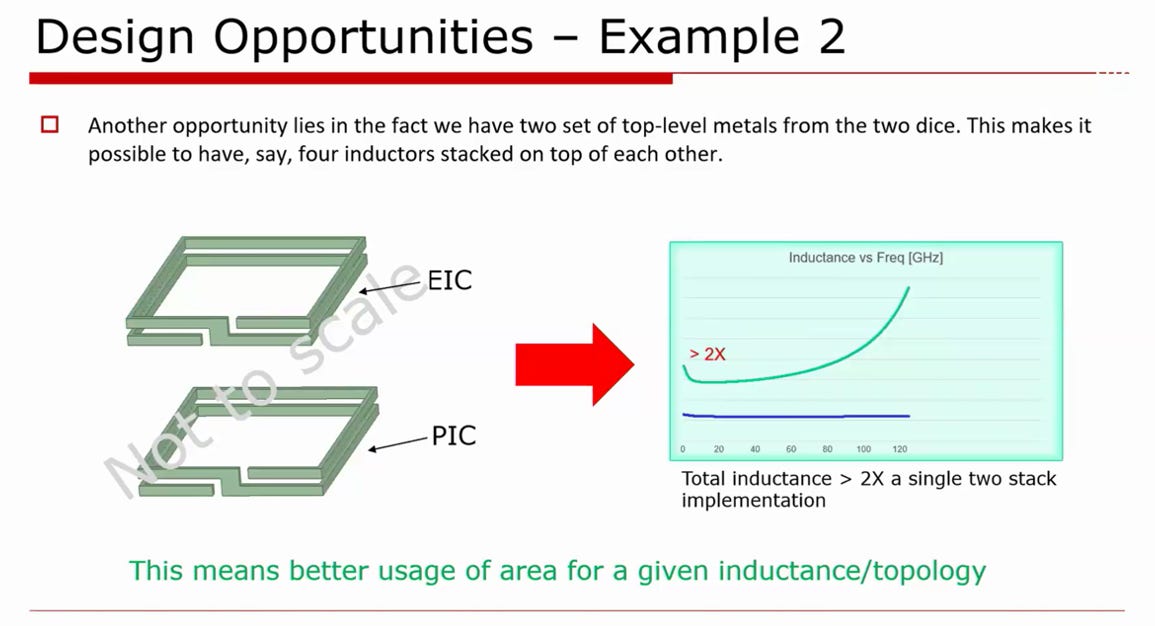
source: OFC25, TSMC
3D 堆疊電感:極大化電感密度與節省面積
物理挑戰: 在高速驅動電路中,常需要使用電感進行峰化 (Peaking) 來擴展頻寬,但傳統平面螺旋電感會佔用極大的晶片面積。
SoIC-X 優勢: 系統現在同時擁有了 EIC 與 PIC 兩顆晶片的頂層金屬線 (Top-level metals)。設計者可以將 EIC 的電感與 PIC 的電感在垂直方向上對齊堆疊
工程效益: 由於兩個電感極度靠近,產生了強烈的互感效應 (Mutual Inductance)。從圖表的綠線可知,總電感量將大於兩個獨立電感相加的兩倍 (>2X)。這代表可以在極小的 XY 平面面積內,實現極大的等效電感值,大幅提升晶片的面積使用效率
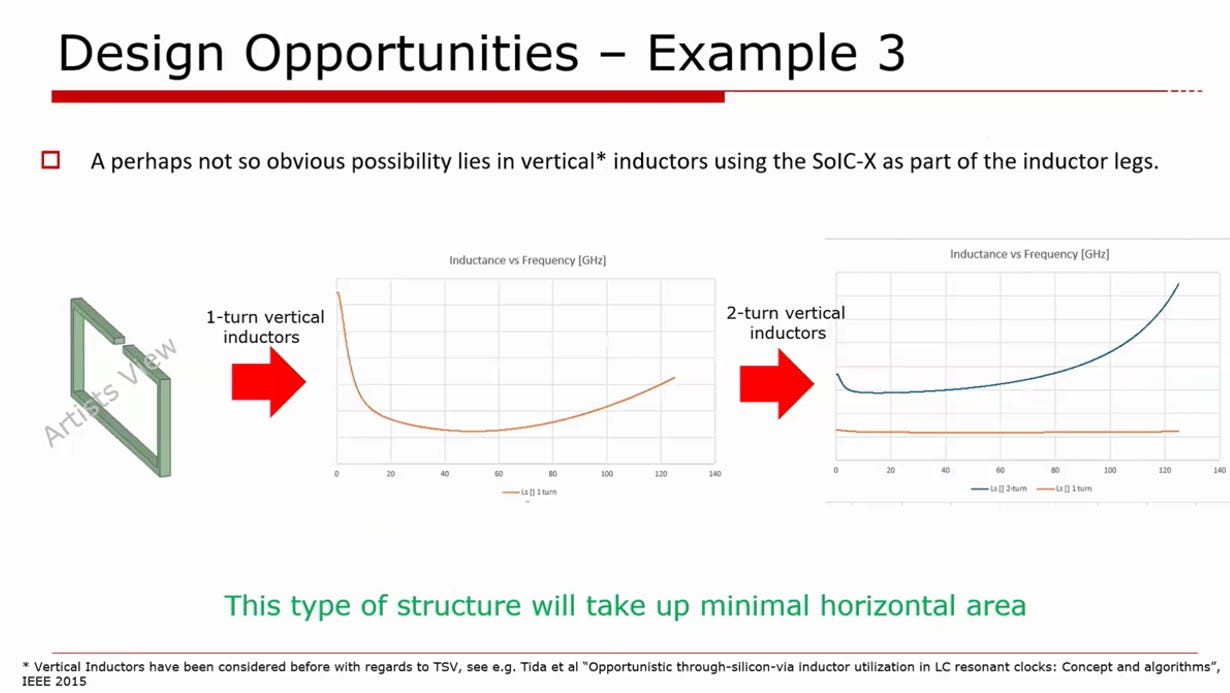
source: OFC25, TSMC
垂直電感結構:實現零平面面積的被動元件
物理挑戰: 即便是堆疊電感,仍需要佔用一定的水平面積
SoIC-X 優勢: 這是一個非常創新的設計概念。工程師直接利用 SoIC-X 介面的銅對銅鍵合柱 (Bonding pads/vias) 作為電感的垂直導電腳 (Inductor legs),結合 EIC 與 PIC 的金屬走線,形成一個跨越兩顆晶片的「垂直線圈」
工程效益: 如圖所示,這種 1-turn 或 2-turn 的垂直電感,其磁場方向平行於晶片表面。最重要的是,它幾乎不佔用任何水平 (Horizontal) 晶片面積。這為空間極度受限的高密度光收發引擎提供了極具價值的設計彈性。
TSMC COUPE SoIC-X 技術不僅僅是將兩顆晶片封裝在一起,它更打破了傳統 2D 電路佈局的限制。它賦予了 IC 設計工程師利用「垂直 Z 軸」維度來縮短關鍵射頻路徑、創造高密度 3D 被動元件的能力,這是實現次世代 200Gbps 甚至更高傳輸速率光學引擎的關鍵硬體基礎。
3. 光學特性分析
3.1. 光學動態特性(Optical Dyanmics)
探討完電氣小信號模型後,本節介紹微環調變器 (MRM) 另一個更棘手的物理限制:光學動態特性 (Optical Dynamics)。在評估 AI 叢集的高速互連架構時,純電氣頻寬已不足以描述全貌。MRM 本質上是一個光學諧振腔,光子在環內的充放電時間 (Photon Lifetime) 構成了獨立於電氣 RC 延遲之外的「光學頻寬」限制。
以下針對 Lorentzian 轉移函數和時域耦合模理論(Coupled Mode Theory, CMT)(請參考 6. 補充說明)下的光學動態、Q 值、失諧量(detuning),以及為何 200Gb/s 必須仰賴動態補償進行解析:
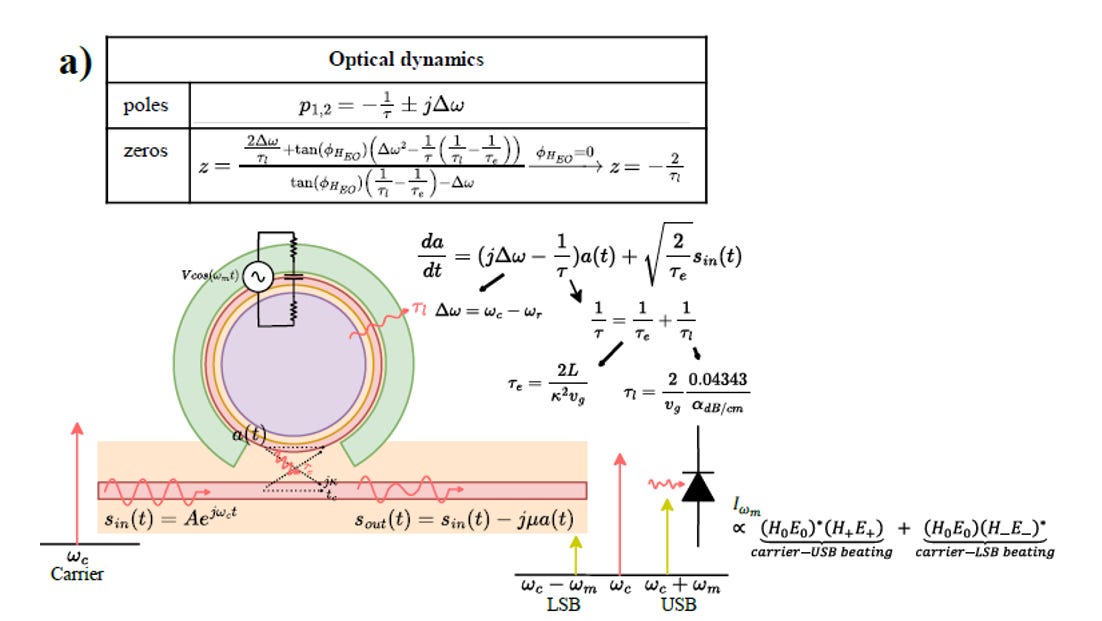
source: OFC26. M2A.7, Nvidia
核心動態方程式與光子生命週期
圖中 da/dt 的微分方程式描述了環內光場振幅 a(t) 的動態變化
方程式中的 1/τ 代表總衰減率,由 1/τe (與直通波導的耦合損耗) 以及 1/τl (環內部的本質損耗) 組合而成
極點 (poles) 公式p1,2 = -1/τ +/- j*∆ ω 清晰顯示了系統的響應極限。實部 - 1/τ 決定了光子在環內存活的時間 (Photon Lifetime)。
光子存活時間越長,光學系統對於高速訊號的反應就越遲鈍,這等同於一個光學低通濾波器
Q 值 (Q-factor) 的雙面刃
品質因子 Q 值與總衰減率 (1/τ) 成反比
高 Q 值的優勢 (效率): 光子在環內繞行圈數多,能大幅提升電光調變效率,讓驅動電路能以極低的電壓推動光信號
高 Q 值的代價 (頻寬): 高 Q 值意味著極窄的 Lorentzian 共振頻譜與極長的光子存活時間。在 100 Gbaud (即 200Gb/s PAM-4) 的極高符號率下,單一符號寬度僅約 10 皮秒 (ps)。如果環的高 Q 值導致光子的存活時間接近或大於 10ps,光腔就會來不及反應電壓的快速切換,造成舊符號的光子殘留並干擾新符號,這稱為光學符號間干擾 (Optical ISI)。
失諧量(Detuning, ∆ ω) 的動態影響
失諧量 ∆ ω 是雷射載波頻率 (ωc) 與微環共振頻率 (ωr) 的差值
靜態偏置: 系統會透過微型加熱器 (Heater) 控制環的溫度,將 ωr 推移到一個固定的 ∆ ω,作為直流工作點。
動態拍頻 (Beating): 在高速調變時,驅動電壓改變了矽的折射率。當 ωr 以 ωm 的頻率被左右拉扯時,會導致正在通過該元件的連續光載波 (ωc) 受到週期性的振幅與相位衰減。圖右下角的頻譜顯示,這個過程會產生上邊帶 (USB) 與下邊帶 (LSB)
非線性失真: 最終光偵測器接收到的電流 (Iωm) 是載波與邊帶的拍頻 (Beating) 結果。由於 Lorentzian 頻譜的斜率是不對稱且非線性的,當高速訊號的邊帶超出微環的光學線性區時,訊號會遭遇嚴重的振幅衰減與群延遲 (Group Delay) 變異。
200Gb/s PAM-4 系統為何必須進入動態補償?
Tx DSP 預先等化 (Pre-emphasis / FFE): 數位訊號處理器必須建立 MRM 的非線性 Lorentzian 模型,在發射端預先增強高頻成分,並非線性地調整不同 PAM-4 眼階的驅動電壓,以「逆向抵銷」光學低通與非線性效應。
光學動態峰化 (Optical Peaking): 利用大訊號驅動時特定的藍移/紅移非線性動態,刻意在某個瞬間製造較大的 ∆ ω 變化量,擠壓光子快速離開共振腔,藉由產生光學的 Overshoot 來拓寬系統的整體等效頻寬
3.2. 光子存活時間
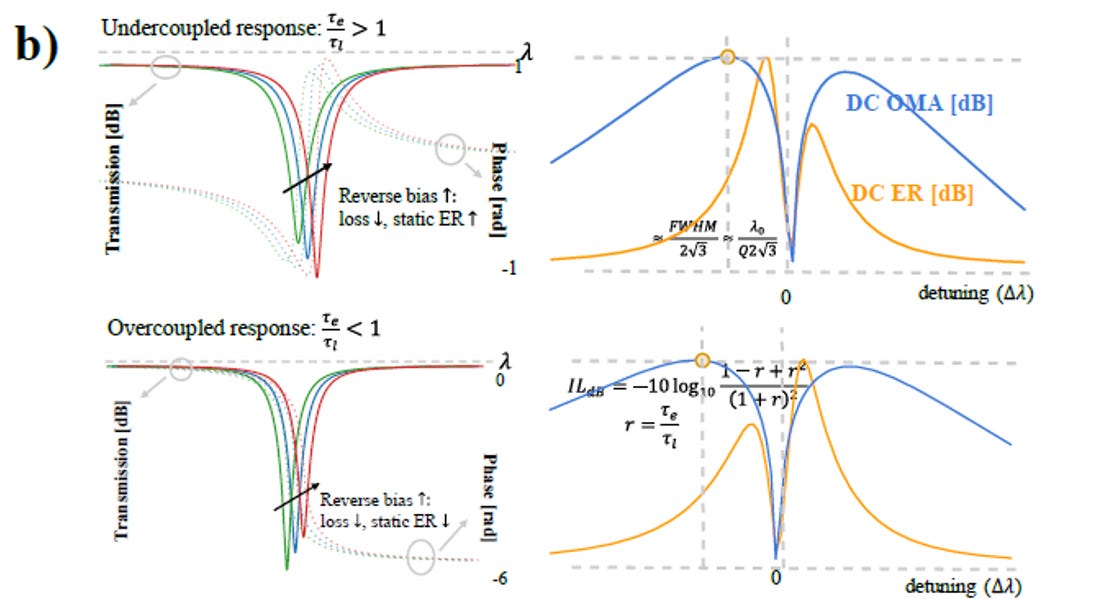
source: OFC26. M2A.7, Nvidia
核心物理量 (光子存活時間):
決定 MRM 光學頻寬的關鍵在於光子在環內的存活時間。時間越長,頻寬越窄(越容易發生高速干擾)。
τe (外部耦合時間): 由微環與直通波導之間的實體間距 (Gap) 決定。間距越小,耦合越強,τe 越小。
τl(內部損耗時間): 由微環內部的波導散射與載子吸收損耗決定。
欠耦合 (Undercoupled, τe>τl ) ── 靜態優、動態劣:
特徵:光子存活時間長,具備極高的 Q 值與極佳的「靜態」消光比。
致命傷:在 200Gb/s 的極速切換下,光子來不及進出微環,導致嚴重的光學符號間干擾 (Optical ISI),因此不適用於極高速傳輸。
過耦合 (Overcoupled, τe<τl ) ── 靜態妥協、動態致勝:
特徵:光波導與微環耦合極強,光子存活時間大幅縮短(Q 值較低)。
優勢:雖然犧牲了部分靜態消光比,但成功拓寬了「光學頻寬」,使光腔的反應速度能跟上 200Gb/s 的訊號切換,這是目前高速系統的主流硬體設計
動態工作點 (Detuning):
系統會將工作點設定在共振頻譜的「斜坡」上,而非谷底,以此在調變幅度 (OMA) 與消光(ER)比之間取得最佳平衡,並依賴後端的 DSP 進行非線性預先補償
微環調變器 (MRM) 的電光頻率響應 (EO S21) 隨著靜態失諧量 (Detuning) 增加而產生的動態變化。
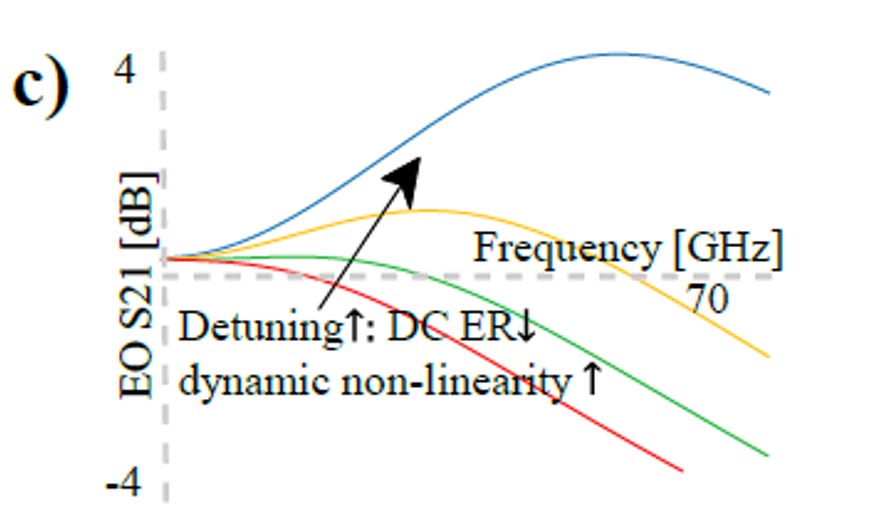
source: OFC26. M2A.7, Nvidia
頻寬 (BW) 變大: 增加偏移量能引發「光學峰化 (Optical Peaking)」效應,提供額外的高頻增益來補償衰減,進而大幅展延系統頻寬。
品質因子 (Q) 與消光比 (ER) 變小: 工作點遠離共振谷底,微環的高 Q 值束縛效應減弱;同時,調變造成的「光功率變化比例」縮小,導致消光比 (ER) 下降
動態非線性增加: 遠離谷底會進入共振曲線的非線性區,容易造成 PAM-4 訊號在高速切換時的眼階失真。要靠Tx DSP 預先等化 (Pre-emphasis / FFE)處理。
OMA 優於 ER 的系統考量: 在 200Gb/s 的極速環境下,接收端判讀訊號的關鍵在於「絕對的光功率差 (OMA)」能否克服熱雜訊。若為追求高 ER(高比例)而將工作點設在谷底,會導致整體光功率過低而無法被偵測。因此,實務上會選擇較大的偏移量以保證頻寬與 OMA,並犧牲部分 ER。
3.3. Summary: Q 值、Detuning、OMA、BW
諧振腔記憶效應與 ISI 的物理根源
高 Q 值意味著光子在微環內的存活時間 (Photon Lifetime, τ) 極長。當傳輸200Gbps PAM-4 訊號時(符號週期為 10 皮秒),若光子存活時間大於符號週期,前一個位元的光子就會殘留在腔體內,與下一個位元的光子產生干涉。這就是所謂的「諧振腔記憶效應 (Cavity Memory Effect)」,也是造成光學符號間干擾 (Optical ISI) 的元凶。因此,系統必須在靈敏度與頻寬之間尋求妥協。
DC OMA 最大化準則 (靜態靈敏度極值)
公式 Δλ ≈ λ0 / (2√3 * Q) 的物理意義,其實是 Lorentzian 共振曲線的反曲點 (Inflection Point),也就是斜率最陡峭的位置。
在這個特定偏移量下,微環對於折射率改變的敏感度最高。
施加微小的驅動電壓,就能獲得最大的光穿透率落差,因此能夠將靜態的 DC OMA 推到絕對極大值。這通常是傳統低速 (如 50G) 系統的首選工作點。
增益頻寬積 (Gain-BW Product) 優化 (動態最佳點)
公式 Δλ ≈ (0.565 * λ0) / Q 揭示了高速系統必須做出的戰略退讓。
請注意數值差異:最大 OMA 點的係數
1 / (2√3)約為 0.288,而最佳動態點的係數是 0.565 (幾乎是 0.288的兩倍)。這意味著,為了達到最佳的動態響應,必須將工作點進一步向外推移(Detuning
Δλ變大),離開斜率最陡峭的地方。雖然這會犧牲一部分的 OMA ,但如前次討論所述,更大的偏移量能引發強烈的「光學峰化效應」,大幅縮短等效的光子存活時間。這個頻率點,正是光學增益與頻寬展延交乘後的系統最佳甜區 (Sweet Spot),能讓 200Gbps 訊號完整通過而不失真
在鎖定雷射波長時,不要停在最亮的地方 (最大 OMA),請繼續往外推兩倍的距離,那是訊號跑得最快、眼圖最漂亮的地方
4. 系統級挑戰
針對 200Gbps 微環調變器 (Micro-Ring Modulator, MRM) 的設計,在微觀尺度下,電學、光學與熱學已形成緊密耦合的「權衡三角」。傳統單一物理域的孤立優化方式已經無法應付此世代的挑戰,必須仰賴 EDA 工具進行動態協同模擬 (Co-simulation) 才能確保穩定輸出與量產可行性。
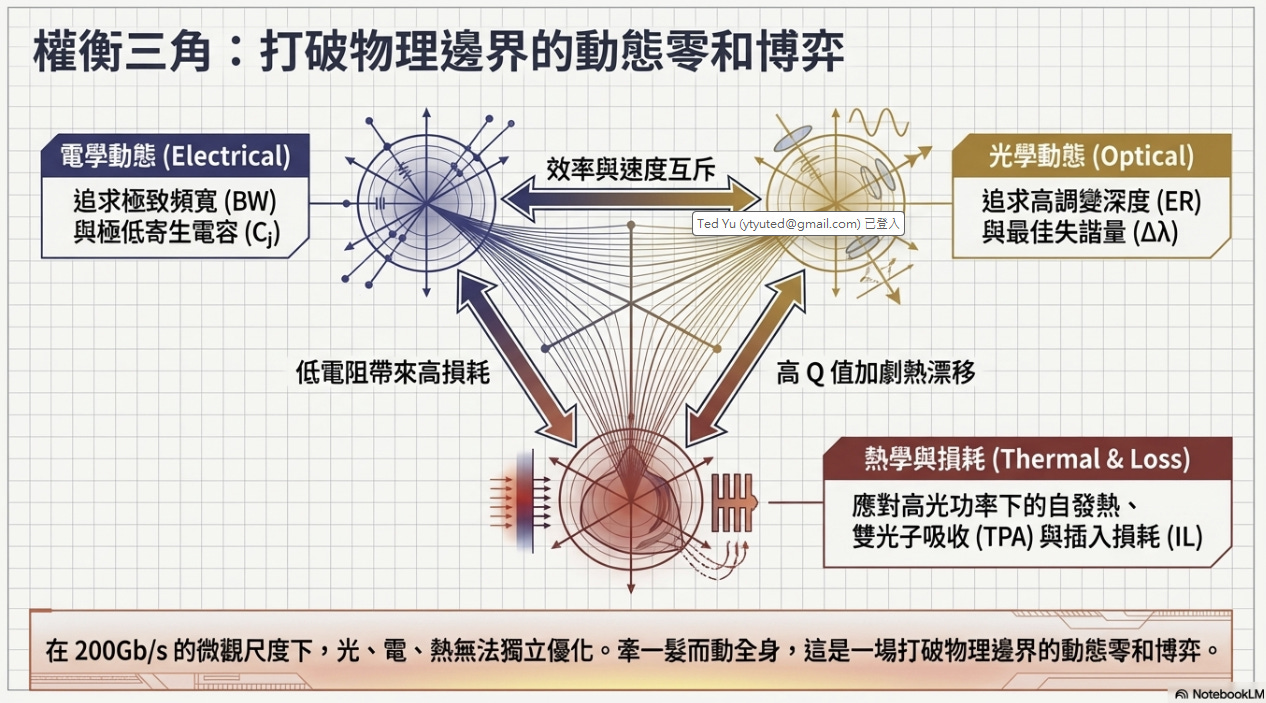
三大物理域的交互影響
在 200Gb/s 的高頻寬需求下,MRM 內部的物理機制呈現零和博弈的特性,任一參數的調整皆會引發連鎖反應:
電學與光學的拉扯 (效率與速度互斥): 電學設計追求極致頻寬 (BW) 與極低寄生電容 (Cj)。然而,若為了降低 RC 延遲而改變波導的摻雜濃度以降低電阻,會引入自由載子吸收效應,直接導致光學損耗增加(低電阻帶來高損耗)。
光學與熱學的拉扯 (高 Q 值加劇熱漂移): 光學設計追求高調變深度 (ER) 與最佳失諧量 (Δλ)。若為了提升調變效率而提高微環的品質因子 (Q 值),會使得共振波長對溫度變化變得極度敏感。微小的溫度波動即可導致波長漂移,使訊號嚴重失真。
熱學與電光的綜合影響 (自發熱與損耗): 高頻操作與高光功率下,必須處理自發熱、雙光子吸收 (TPA) 與插入損耗 (IL) 問題。熱學效應會直接改變矽波導的折射率,進一步破壞光學共振條件與電學驅動的穩定性。
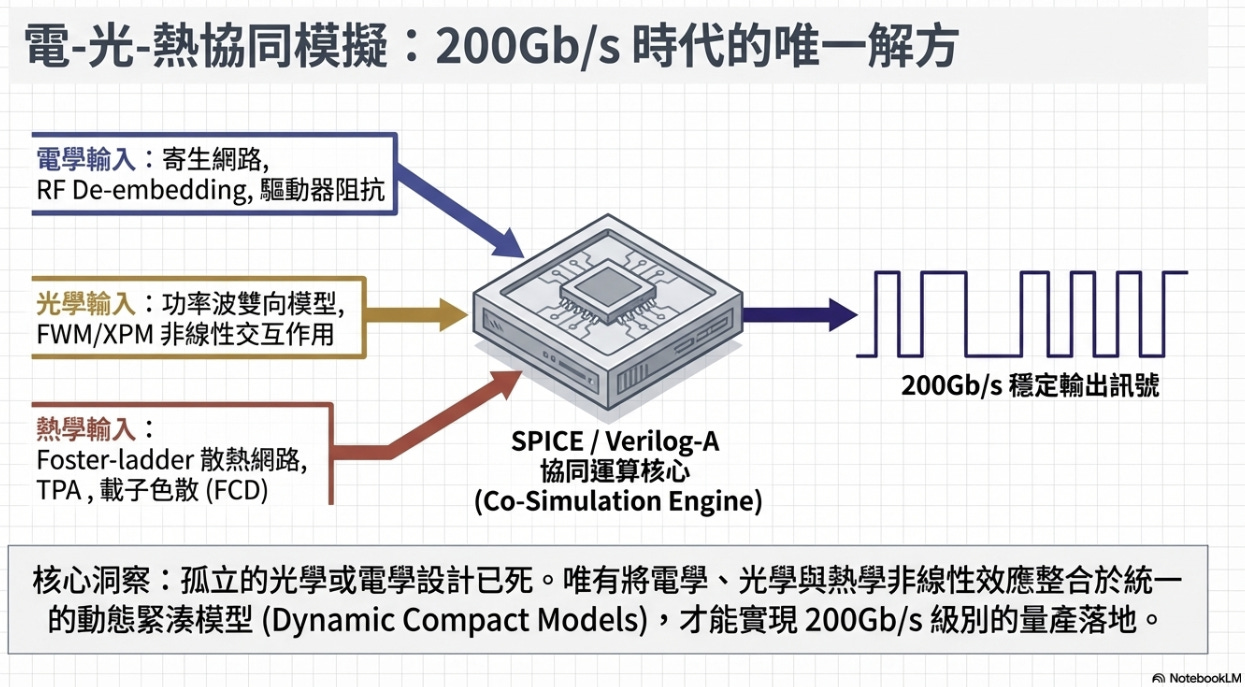
EDA 電-光-熱協同模擬架構
為了突破上述物理邊界,必須將非線性效應整合於統一的「動態緊湊模型 (Dynamic Compact Models)」中,透過 SPICE 或 Verilog-A 協同運算核心進行全域分析:
電學輸入建模: 納入寄生網路萃取、RF De-embedding 技術,以及驅動器阻抗匹配的高頻響應。
光學輸入建模: 處理功率波雙向模型,並計算四波混頻 (FWM) 與交叉相位調變 (XPM) 等非線性交互作用
熱學輸入建模: 建立 Foster-ladder 散熱網路模型,並精確模擬 TPA 與載子色散 (FCD) 所引發的動態熱分佈。
在 200Gbps 時代,只有透過此種將電、光、熱三者耦合的協同模擬引擎,才能在設計階段準確預測並補償非線性失真,獲得穩定的眼圖輸出。
5. 結論
要在單一微環調變器上實現穩定且低損耗的 200Gbps 傳輸,已無法單獨依賴單一物理域的優化。電學上對極致頻寬與低寄生電容的追求,會與光學效率及熱穩定性產生直接衝突 。同時,高光功率下的自發熱、雙光子吸收 (TPA) 及載子色散效應,更為系統設計增加了多重非線性變數 。
NVIDIA 的技術文獻與台積電 COUPE 封裝技術的結合,展示了克服這些物理邊界的可能路徑。未來的 AI 互連晶片設計,必須仰賴將電學、光學與熱學非線性效應整合的動態緊湊模型 (Dynamic Compact Models),透過 EDA 工具進行全域的電-光-熱協同模擬 (Co-simulation) 。唯有透過跨領域的精確權衡與系統級協同設計,矽光子微環調變器才能真正滿足次世代資料中心對兆位元級 (Terabit-scale) 頻寬的嚴苛需求。
6. 補充說明: Journey of MRM
這是一段跨越世紀的技術演進史。矽光子微環調變器(MRM)的發展軌跡,完美詮釋了基礎物理理論如何經過工程學界的迭代,最終在特定的系統架構(CPO)中找到無可取代的定位。
理論萌芽:Lorentz 的阻尼共振模型 (1890年代)
MRM 的物理根基,建立在 19 世紀末 Hendrik Lorentz 對於古典電子振盪的探討。Lorentz 提出,任何具備能量儲存與耗散特性的受驅動阻尼系統,其穩態頻率響應都會呈現特定的對稱曲線。這個被後世稱為「洛倫茲轉移函數(Lorentzian Transfer Function)」的純物理數學模型,雖然最初用於解釋光譜線展寬,卻為百年後的光學共振腔設計定義了靜態光學特徵,包含共振波長、品質因子(Q factor)與直流消光比(DC ER)的基礎極限。
動態建構:時域耦合模理論(CMT)的導入 (2000年至2010年代)
隨著矽光子技術的興起,學者們(如 MIT 的 H. A. Haus 與 Caltech 的 A. Yariv)將巨觀的共振理論引入微米級的矽波導結構中。隨後,為了解決高速通訊的需求,W. D. Sacher 等學者將「時域耦合模理論(Coupled Mode Theory, CMT)」應用於 MRM。 CMT 補足了洛倫茲穩態模型的不足,透過精確計算光子在直通波導與微環之間的動態能量交換,成功解析了光子存活時間(Photon Lifetime)、極點與零點分佈。這使得工程師能夠以微分方程式預測 MRM 在大訊號切換下的光學符號間干擾(Optical ISI)與光學峰化(Optical Peaking)效應,為高速調變奠定了數學基礎。
模組時代的沉寂:不敵 MZM 與 EAM 的先天劣勢
儘管理論完備且具備極小的物理體積 ,MRM 在傳統可插拔光模組(Pluggable Transceivers)時代並非主流首選。其發展受制於兩大物理痛點:
極端的溫度敏感性: 矽具備強烈的熱光效應,微小的環境溫度波動就會導致微環的共振頻譜發生熱漂移,造成嚴重訊號遺失 。
控制迴路的延遲: 傳統模組架構中,電子驅動 IC(Driver/Controller)與光子晶片(PIC)通常分開封裝。要實時監控微環溫度並透過微型加熱器(Micro-heater)進行精確的波長鎖定(Wavelength Locking),其電氣路徑過長,難以實現穩定且低延遲的閉環控制。
因此,在要求長距離傳輸與高環境耐受度的傳統網路交換器中,業界更傾向採用訊號最穩定但體積巨大的馬赫-曾德爾調變器(MZM),或是尋求體積與功耗相對平衡的電吸收調變器(EAM) 。MRM 在此階段多被視為難以駕馭的實驗室元件。
AI 世代的重生:在 CPO 架構中大顯身手
AI 運算叢集的爆發,徹底改變了硬體架構的遊戲規則。當系統需求轉向極致的頻寬密度與極短的互連距離時,MZM 的毫米級體積成為無法克服的物理瓶頸 。此時,MRM 憑藉微米級尺寸與天然支援分波多工(WDM)的優勢,迎來了歷史性的轉折。
真正的關鍵推手是先進 3D 封裝技術的成熟,如台積電的 COUPE(SoIC-X)平台 。CPO 架構為 MRM 解決了過去的致命傷,並釋放了其潛力:
克服熱控制瓶頸: 透過 3D 混合鍵合,EIC 直接覆晶堆疊於 PIC 之上,極短的互連距離讓微型加熱器的閉環控制得以即時且精準地運作,穩定了 MRM 的熱漂移問題。
突破 200Gbps 電氣極限: 無凸塊(Bumpless)的直接鍵合消除了傳統封裝的龐大寄生參數 。工程師進一步利用 EIC 與 PIC 的頂層金屬,設計出極高密度的 3D 垂直堆疊電感,精準實現雙極點電感峰化(Inductive Peaking),一舉將單波長傳輸速率推升至 200Gb/s 的物理極限
MRM 的旅程,是從基礎物理定律(Lorentz)出發,經過嚴謹的應用數學(CMT)建模,在傳統模組架構中歷經挫折,最終藉由半導體 3D 封裝技術(CPO/COUPE)的突破,完成光、電、熱三方協同優化。這不僅是單一元件的勝利,更是系統工程思維克服物理邊界的經典案例。
[Reference]
OFC26 M2A.7: Si Microring Resonator Modulators at >200Gb/s, David Patel Nvidia