EP38. 解析 3.2T 光通訊實體層技術

隨著 AI 模型規模的指數級增長,資料中心底層網路正迎來前所未有的頻寬考驗。矽谷硬體架構先驅 Andy Bechtolsheim 於 ISSCC26 Forums 的深度解析,梳理 2028 年 3.2T (8x400G) 世代的技術藍圖 。當單通道傳輸速率推進至 400G(Nyquist 頻寬達 106 GHz)時,傳統的 PCB 走線與矽光子 (SiPh) 材料皆面臨物理極限的嚴峻挑戰 。為了突破此一瓶頸,產業界正走向兩條壁壘分明的戰略路徑:一條是追求單波長極限、堅守可插拔模組的「Fast & Narrow」路線 ;另一條則是依賴先進封裝、以通道數量換取功耗空間的「Slow & Wide」共同封裝光學 (CPO) 架構 。分享個人對Andy演講資料的心得,歡迎討論。
1. Background
1.1. Andy Bechtolsheim 簡介
Andy Bechtolsheim 是矽谷硬體架構的傳奇人物: Sun 共同創辦人、Google 早期天使投資人、Cisco 前副總裁、Arista 共同創辦人兼首席架構師。以「開放標準戰勝封閉專有」為核心哲學,深刻重塑了現代數據中心與 AI 網路的底層架構。他的四大關鍵影響力如下:

擊敗老東家 Cisco 的封閉體系:
憑藉過去在 Cisco 擔任高階主管的深刻歷練,他深知傳統垂直整合架構的侷限。身為 Arista 共同創辦人,他帶領公司改採通用的「商用晶片(與Broadcom合作)」,憑藉更高的產品迭代速度與彈性,成功在雲端與 AI 後端網路(Backend Networking)市場擊敗了老東家 Cisco。
挑戰 NVIDIA 的網路壟斷:
倡議推動 UEC(超級乙太網聯盟),打造開放、高效的 AI Scale-out 網路標準,正面迎擊 NVIDIA InfiniBand 的獨佔地位,並使 NVIDIA 積極推出 Spectrum-X 乙太網方案。
制定 OSFP 標準:
預見 400G/800G 以上超高速模組(QSFP-DD)面臨的極端高溫瓶頸,強力推動內部空間更大、自帶散熱片的 OSFP 成為業界主流物理封裝標準。
務實堅守「可插拔模組 (Pluggable)」:
針對未來的 1.6T/3.2T 世代,他務實地指出 CPO(共封裝光學)在製造良率與光纖連接上存在工程挑戰。因此,他主張採用 TFLN 等先進材料來發展單波長 400G(Fast & Narrow),藉此在維持「可插拔、易維護」優勢的同時,將光學效率推向極致。
1.2. Pluggable Roadmap

source: ISSCC26 F2_1
LPO (線性可插拔) 的妥協:
Arista 主推的 LPO:維持傳統前面板的長 E-path(保留熱插拔彈性),拔掉光模組內最耗電的 DSP。 訊號一路以純類比方式傳輸,這讓 1.6T 模組功耗直接降低 2/3,兼顧了省電與硬體維護性。
CPO 為了更省電,進一步縮短 E-path(與晶片共封裝),但引發了良率與維護問題。
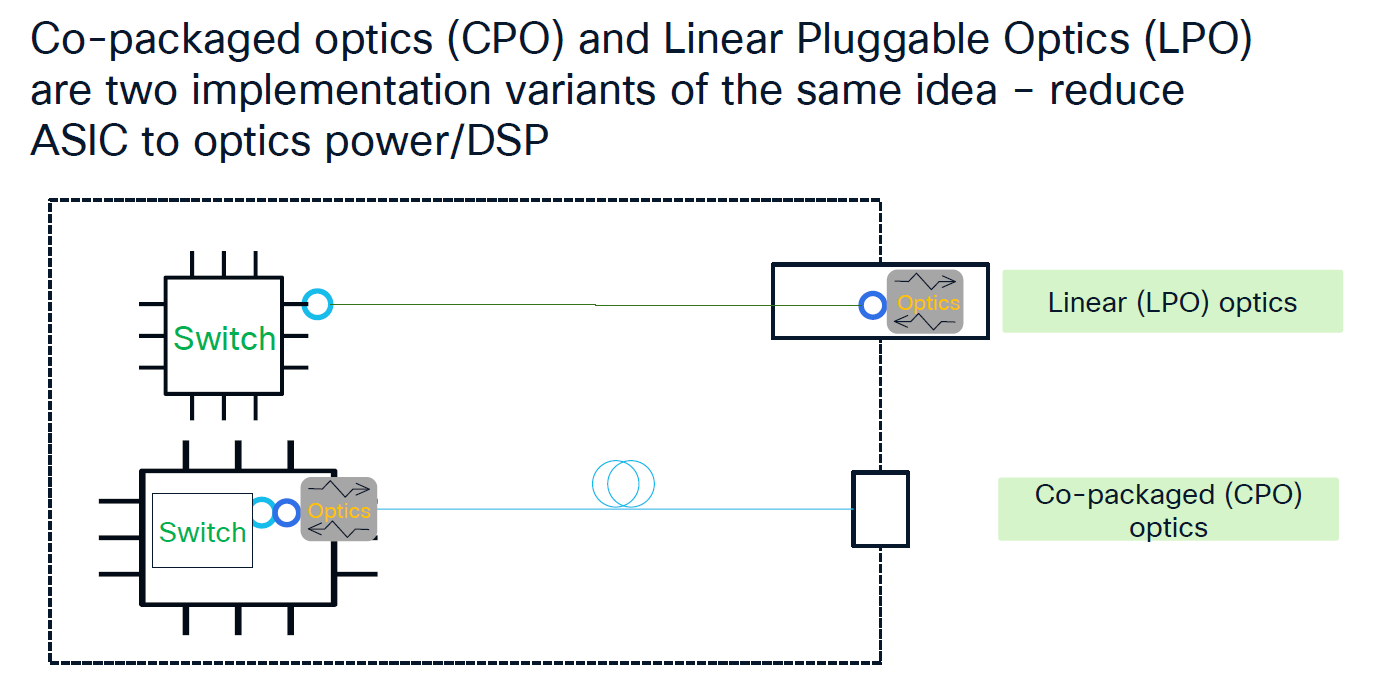
source: Cisco
矽光子 (SiPh) 的優勢:
在 1.6T (8x200G) 世代,單通道 200Gbps(純Si Modulator的上限),矽光子憑藉成熟的 CMOS 晶圓級量產優勢,是成本與良率的最佳平台。
雷射精簡化:
透過高功率連續波雷射與矽光子分光技術,將 1600G-DR8 模組需要的 8 顆雷射大砍至 2 顆(傳統 EML 需要8 顆雷射)。
雷射越少,發熱越低,系統整體的可靠度 (MTBF) 就會大幅飆升。
「上億級產能」的需求:
傳統可插拔模組擁有極度成熟的自動化 SMT 與光學耦合產線,每年能支撐 1 億個以上的海量需求。這是目前「3D 異質先進封裝」CPO 陣營,短期內絕對無法跨越的產能高牆。

source: ISSCC26 F2_1
2024 年(已落地成熟):
800G (8x100G) 目前的量產主力。單通道 100G,矽光子 (SiPh) 技術與傳統 EML 在此世代搭配,功耗尚在可控範圍
2026 年(產能爬坡中):
1.6T (8x200G) 當下(現在)的主戰場。單通道拉高到 200G,為了控制暴增的功耗,系統廠開始推 LPO(線性可插拔) 架構試圖拔掉 DSP。同時,這也是矽光子(SiPH)超越EML,成為市場主力(請參考: EP32. 資料中心光模組發展趨勢)
2028 年(終極深水區):
3.2T (8x400G) 物理極限的決戰點。硬體架構將迎來徹底大換血:必須淘汰傳統 PCB 金手指改用新型高密度連接器(配合 CPC 飛線),且純Si調變器正式退役,交棒給 TFLN 或 InP 等超高頻寬材料。
2. 400G技術挑戰
2.1. Key Items
從「當前世代 (1.6T)」跨越到「次世代 (3.2T)」的關鍵技術轉換:

source: ISSCC26 F2_1
晶片 I/O 翻倍 (High-speed Serdes):
從 212.5G-PAM4 升級到 425G-PAM4。這是驅動所有變革的源頭,正式衝破 106 GHz(Nyquist frequency, 類比元件的BW) 的物理極限(請參考:EP23. 448G SerDes)。
調變器材料換血 (Modulator Technology):
面對 400G/lane,傳統「純矽光子」的調變能力觸頂,必須交棒給 InP、TFLN (薄膜鈮酸鋰) 或有機材料 (Organic),走向異質整合
模組總吞吐量 (OSFP Module):
在維持 8 個通道 (8 Lanes) 的前提下,透過單通道頻寬翻倍,讓單一光模組的總吞吐量從目前的 1.6T 直接飆升到 3.2T 的目標。
實體機構的淘汰賽 (Form Factor):
傳統的 OSFP PCB 金手指插槽完全無法承受 425Gbps(Nyquist frequency: 106 GHz) 的訊號衰減,必須全面強制換成「新型連接器 (New Connector)」
2.2. Modulator Material
2.2.1. 兩條路徑
未來高速光通訊將成兩條壁壘分明的戰略路徑(Fast&Narrow vs. Slow&Wide),這不僅是光學材料的選擇(如 TFLN 對決 SiPh),更是系統架構(可插拔模組 vs. 共同封裝光學 CPO)與風險承擔(昂貴新材料 vs. 先進封裝良率)的全面權衡 。
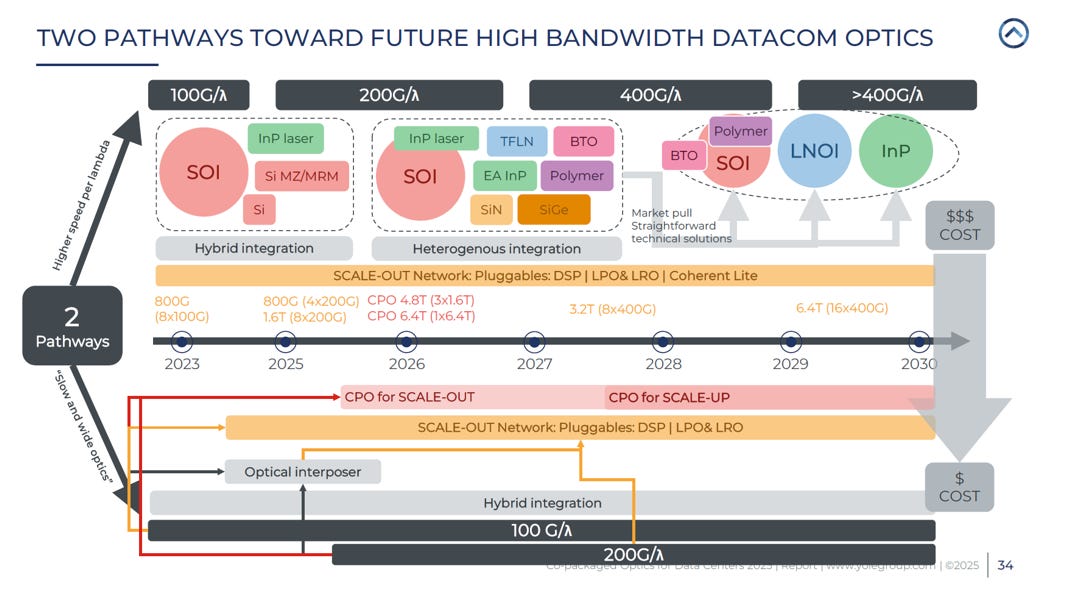
source: Yole
路徑一:Higher speed per lambda
核心邏輯: 也就是 Fast & Narrow。通道數盡量少,提升單一波長的物理極限(從 100G/lambda、200G/lambda 一路硬推到 400G/lambda 甚至更高)
應用場景: 堅守「前面板可插拔模組 (Pluggables)」的天下,包含傳統 DSP 模組,以及 LPO 與 LRO (半線性) 架構,主要用於 Scale-Out 網路
材料的殘酷演進: 這條路越往上走越難。到了 400G/lambda,純矽光子 (SOI) 的調變器就撐不住了,必須用 TFLN、BTO、Polymer (聚合物) 等進行異質整合;到了大於 400G/lambda,甚至得全面換成 LNOI (絕緣體上鈮酸鋰) 或純 InP。
代價: 右側大大的 「$$$ COST」。因為追求極限高頻,需要極度昂貴的新材料與重裝甲晶片,導致整體模組的造價飆高。
路徑二:Slow and wide optics
核心邏輯: 單波長速度不再往上追求極限(停留在 100G/lambda 或 200G/lambda),而是增加平行通道的數量來湊齊 3.2T 或 6.4T 的總頻寬(請參考: EP36. 解析 NVIDIA 次世代光學引擎)
應用場景: 這就是 CPO (共同封裝光學) 陣營的專屬道路。它需要透過先進封裝,將海量的光學通道直接與 Switch/GPU 晶片綁定
材料優勢: 因為頻率較低,它可以繼續沿用最成熟、最便宜的純矽光子平台,避開了 TFLN 等昂貴新材料的製程。
代價: 右側的 「$ COST」 顯示它在光電材料與 SerDes 功耗上確實比較便宜。但它把所有的挑戰都轉移到了隱藏的深水區:極端困難的先進封裝良率與光纖耦合生產。
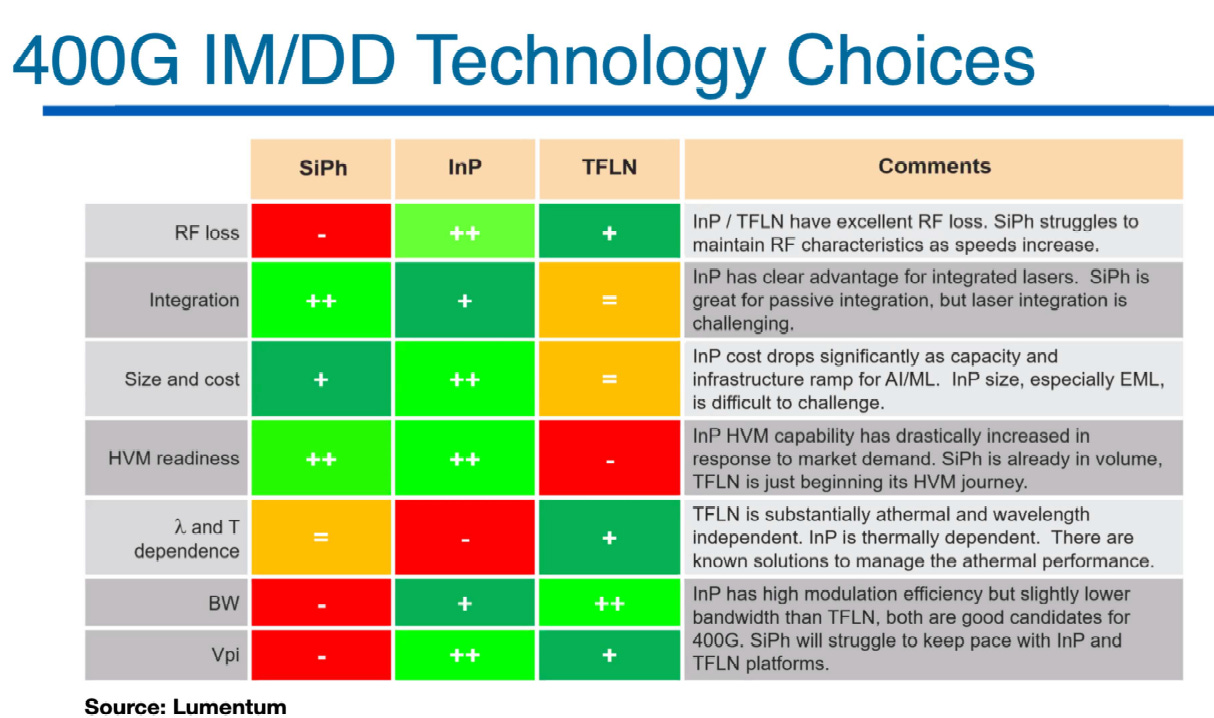
SiPh 矽光子:贏在工廠,輸在物理
護城河 (綠燈): HVM readiness (量產準備度) 與 Integration (被動元件整合)。 挾帶成熟 CMOS 製程的底蘊,它是目前唯一能做到超大規模、低成本量產的平台。
致命傷 (紅燈): BW (頻寬)、RF loss (射頻損耗) 與 Vpi (半波電壓)。 這三顆紅燈完美解釋了為什麼「純矽調變器」必須退役。面對 400G/lane 的超高頻,矽的先天物理特性已經枯竭,推不動就是推不動。
InP 磷化銦:Lumentum的強項
護城河 (綠燈): Size and cost (尺寸與成本) 與 HVM readiness。 EML,InP 不僅射頻特性優異,能自己發光 (主動整合),且在光通訊業界已經具備極高的量產成熟度,是目前 400G 最務實的方案。
致命傷 (紅燈): 溫度與波長敏感度 (Lambda and T dependence)。 InP 非常怕熱,只要溫度一飄移,效能就會下降,必須在模組內搭配精密的溫控線路 (TEC),這給系統散熱帶來了不小的壓力。
TFLN 薄膜鈮酸鋰:
護城河 (綠燈): BW (超高頻寬) 與 溫度獨立性。 它是真正的物理天花板!頻寬碾壓另外兩者,而且幾乎不受溫度影響 (Athermal),完美解決了 InP 怕熱的痛點。
致命傷 (紅燈): HVM readiness (量產準備度)。 它才剛剛踏上高量產 (High Volume Manufacturing) 的艱辛道路,晶圓級的切割、薄膜剝離與異質鍵合良率,都還無法與 SiPh 匹敵(Lumentum的觀點)。
TFLN for Modulators:
TFLN並非只適合 MZM(馬赫-曾德爾調變器),學界與業界同樣有 TFLN MRM(微環調變器)的技術研發。
針對Pluggable 400G/lane 的超高速路徑 (Fast & Narrow),業界選擇 TFLN + MZM,以追求極致的頻寬與訊號品質 。
針對未來CPO使用降頻多通道路徑 (Slow & Wide),由於需要極高密度的調變器陣列,業界仍傾向使用製程最成熟、最易於達成高密度整合的 矽光子微環調變器 (SiPh Micro-Ring-Modulators)
2.1.2. TFLN簡介

source: HyperLight
薄膜化技術 (Thin-Film) 解決尺寸與功耗限制
傳統鈮酸鋰 (LN) 塊材在長途電信中雖具備優異的電光轉換特性,但體積大且耗電。
透過薄膜化技術將 LN 厚度縮減至數百奈米,可大幅縮短電極間距,進而實現適合小型光模組的低驅動電壓 (低 Vpi, 半波電壓) 與超高頻寬。
異質整合架構克服成本與製造難題
TFLN 並非採用高成本且易碎的純鈮酸鋰晶圓,而是將 LN 薄膜鍵合 (Bonding) 於成熟的矽晶圓上。
其結構由下至上分別為:矽基板 (Si)、絕緣層 (SiO2)、薄膜鈮酸鋰 (LN) 以及金屬電極。
高度相容現有 CMOS 量產製程
基於底層的標準矽基板,此種異質整合晶圓可直接導入現有晶圓代工廠的 CMOS 產線,利用標準微影設備進行精密波導結構的蝕刻,具備大規模量產的可行性
OFC 2026 最新消息:

source: Hyperlight
Hyperlight 與 UMC 合作克服量產
UMC 的 6 吋線已進入量產(端到端良率達 90%,年產能達 100 萬片 KGD),且 8 吋線已處於先導試產最後階段。這解決了 TFLN 過去最大的量產瓶頸。
1.6T 已經有產品
Eoptolink 展示了結合 Broadcom Taurus DSP 的 1.6T DR4 模組;
Jabil 則完成了 1.6T LRO(半線性模組)的測試,實測功耗僅 11.5W。
3.2T 底層技術已就緒,生態系正推進中
供應鏈已實測「單通道 425 Gbps」的直連驅動效能。由於 3.2T 的架構基礎正是 8x400G(即 8 條 425 Gbps 通道),這代表 TFLN 平台的物理與技術層面已經 ready。
單波 425G 的標準將於 2026 年底確立,隨後 3.2T 模組將準備大量佈署(2028)
TFLN Power Comsuption Performance
TFLN 功耗表現數據與機制摘要:
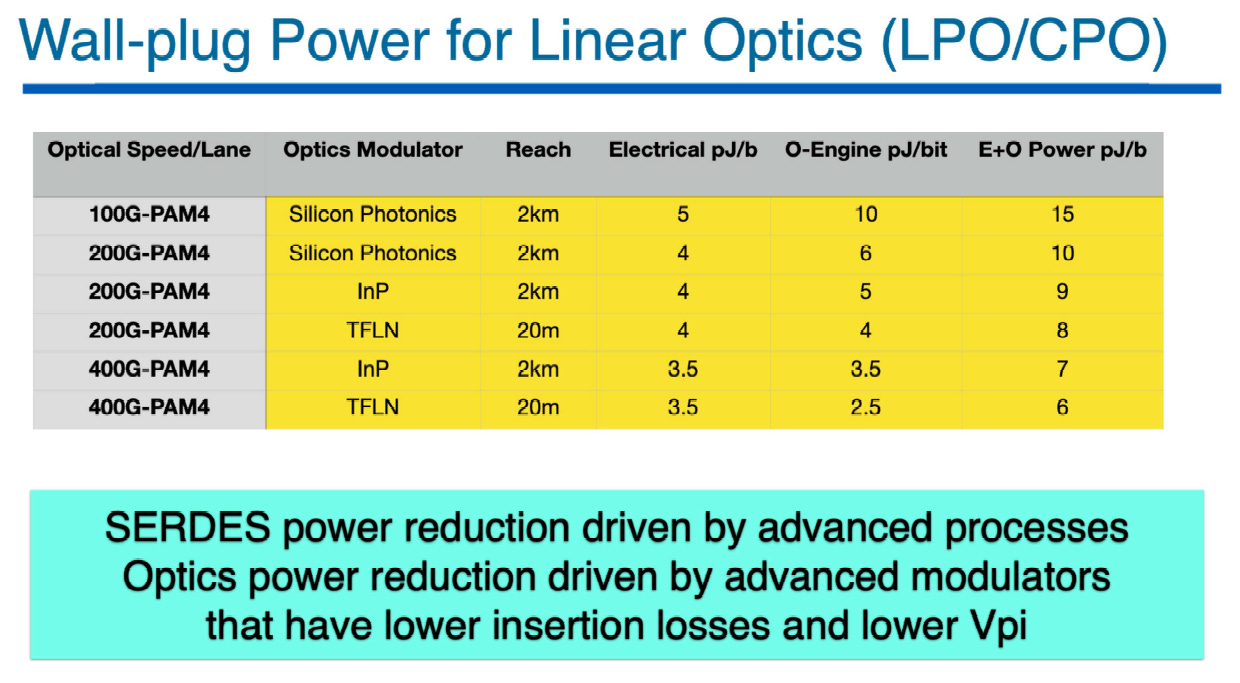
source: ISSCC26 F2_1
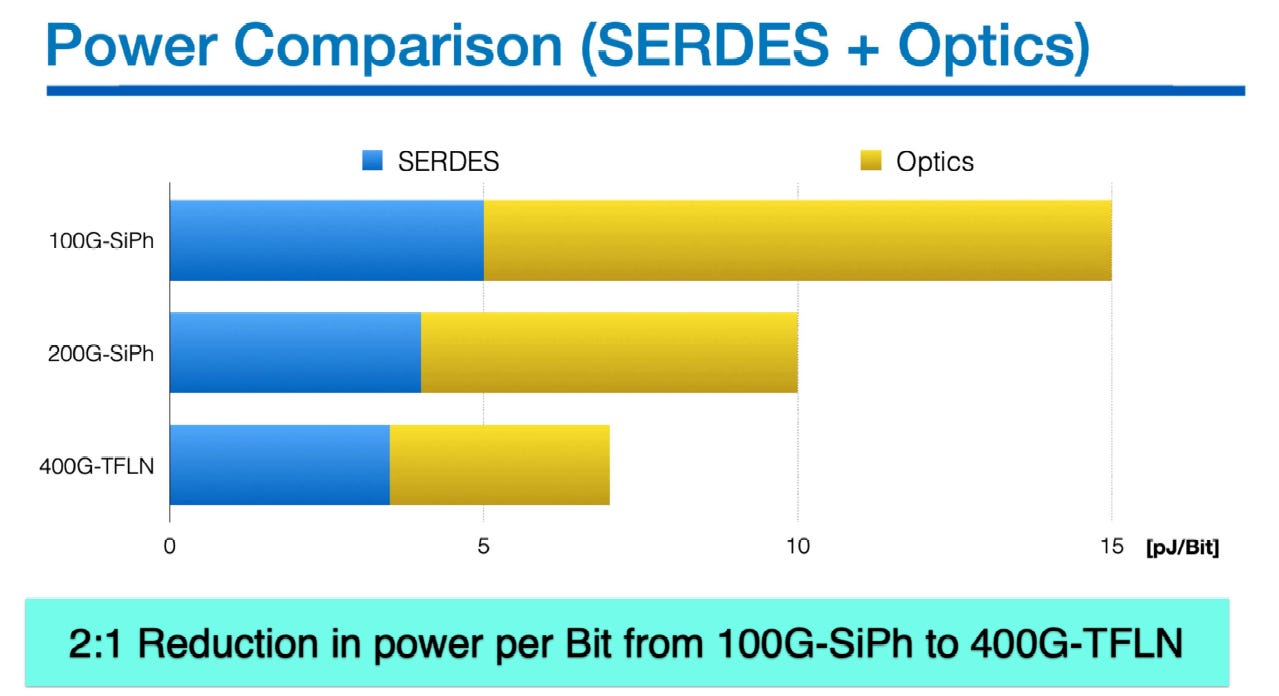
跨世代功耗減半 (2:1 Reduction)
從 100G-SiPh(總功耗 15 pJ/bit)升級至 400G-TFLN(總功耗約 6 pJ/bit),在單通道頻寬提升 4 倍的條件下,每位元功耗 (Power per Bit) 降低了超過 50%
同級規格功耗最低
200G 世代: TFLN 光學引擎功耗為 4 pJ/b,低於同級的 SiPh (6 pJ/b) 與 InP (5 pJ/b),整體模組功耗為 8 pJ/b。
400G 世代: TFLN 光學引擎功耗降至 2.5 pJ/b,整體模組功耗為全場最低的 6 pJ/b
source: ISSCC26 F2_1
TFLN低功耗的兩大物理機制
低驅動電壓 (Lower Vpi): 調變器可由 DSP 直接驅動 (Direct Drive),免除外部驅動晶片 (Driver IC) 的配置與功耗。
Direct Drive實踐前提,在於 DSP 供應商與 TFLN 元件廠必須進行深度的協同設計 (Co-design),以確保輸出電壓與調變靈敏度能完美匹配。
低插入損耗 (Lower insertion losses): 降低光訊號傳輸與調變時的衰減,進而減少所需的前端雷射發光功率。
2.2. Modulation: PAM4 or PAM6?
在 400G 單通道時代,為什麼業界最終選擇 PAM4 調變,而不是看似能降低高頻傳輸壓力的 PAM6。這本質上是一場「銅線與光學」的妥協與拉扯:

source: ISSCC26 F2_1
為什麼光學端「非 PAM4 不可」?
維持良好的光學訊號雜訊比 (OSNR): 在光通訊中,PAM4 是目前唯一可行且訊號品質達標的直接調變 (IM/DD) 選擇。
物理代價: 為了跑 400G-PAM4,實體層通道頻寬被迫拉高到極限的 106 GHz。傳統矽光子 (SiPh) 的頻寬耗盡,必須交棒給 TFLN 等新材料;且傳統 PCB 走線撐不住,必須換上 CPC(Co-Package Copper) 飛線等新型連接器。

source: ISSCC26 F2_1
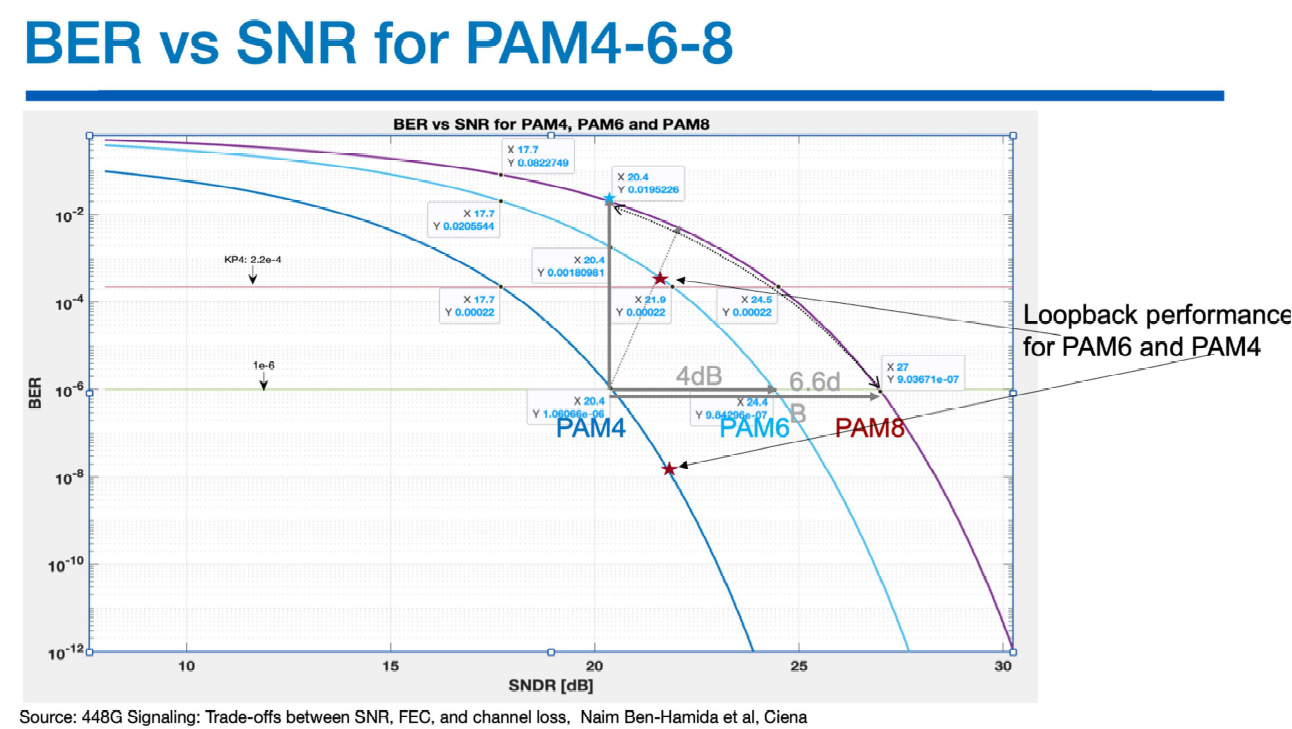
PAM6 的誘惑與致命陷阱
銅線的誘惑: 若改用 PAM6 調變,極限頻率 (Nyquist) 可以從 106.25 GHz 降到 85 GHz。這對銅線 (晶片到前面板的這段路) 非常友善,能大幅降低訊號衰減 (IL)。
光學的災難: 光學端非常不適合 PAM6。它會導致高達 4dB 的訊號衰減 (OSNR impact),迫使系統必須加入更多、更複雜的糾錯碼 (FEC) 來補救。
source: ISSCC26 F2_1
「變速箱 (Gearbox)」功耗
如果為了牽就主機板銅線而讓 Switch 晶片輸出 PAM6,但光模組又必須用 PAM4 才能把光打出去,那這兩者中間就必須加一顆 PAM6轉PAM4 的變速箱晶片 (Gearbox DSP)。就會額外暴增超過 25W (8 pJ/Bit) 的功耗。在散熱已經處於地獄級別的 AI 伺服器中,這種為了轉換訊號而產生的功耗浪費是絕對無法接受的。
2.3. Electrical Path
400G-PAM4 Interconnect:

source: ISSCC26 F2_1
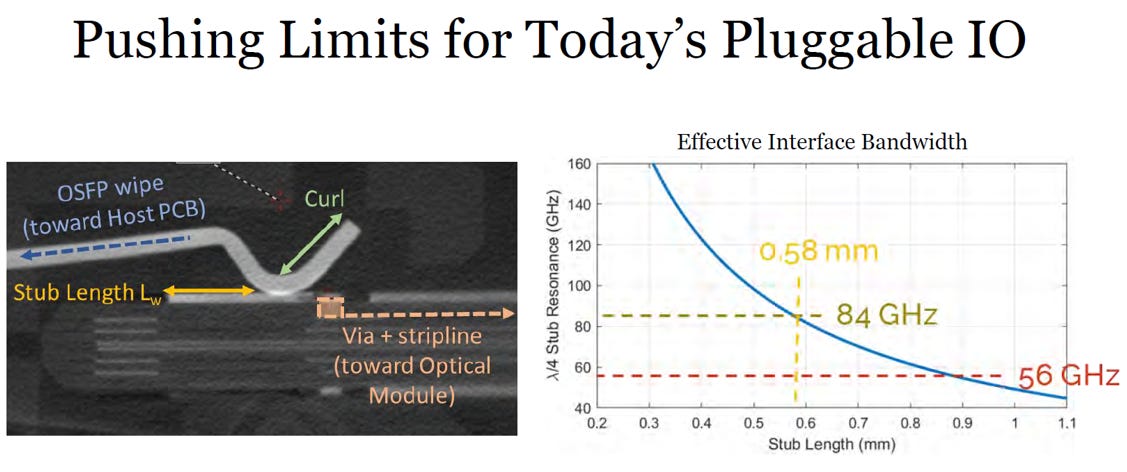
技術瓶頸:
傳統的 Paddle Card (金手指) 連接器設計,其訊號傳輸能力在 85 GHz 時會開始明顯衰減 (Roll off),加上 400G 高頻環境下的串擾 (Cross talk) 大幅增加,已無法滿足 106.5 GHz 的頻寬需求。
source: IEEE 802.3 NEA Ad hoc, Sam Kocsis, Amphenol
發展方向:
業界正在針對晶片端 (CPC)、中板 (Midplane) 與光模組開發全新的連接器。新型連接器必須具備完整的電磁屏蔽 (Full shielding) 設計,以消除共振與阻抗不連續的問題。
source: ISSCC26 F2_1
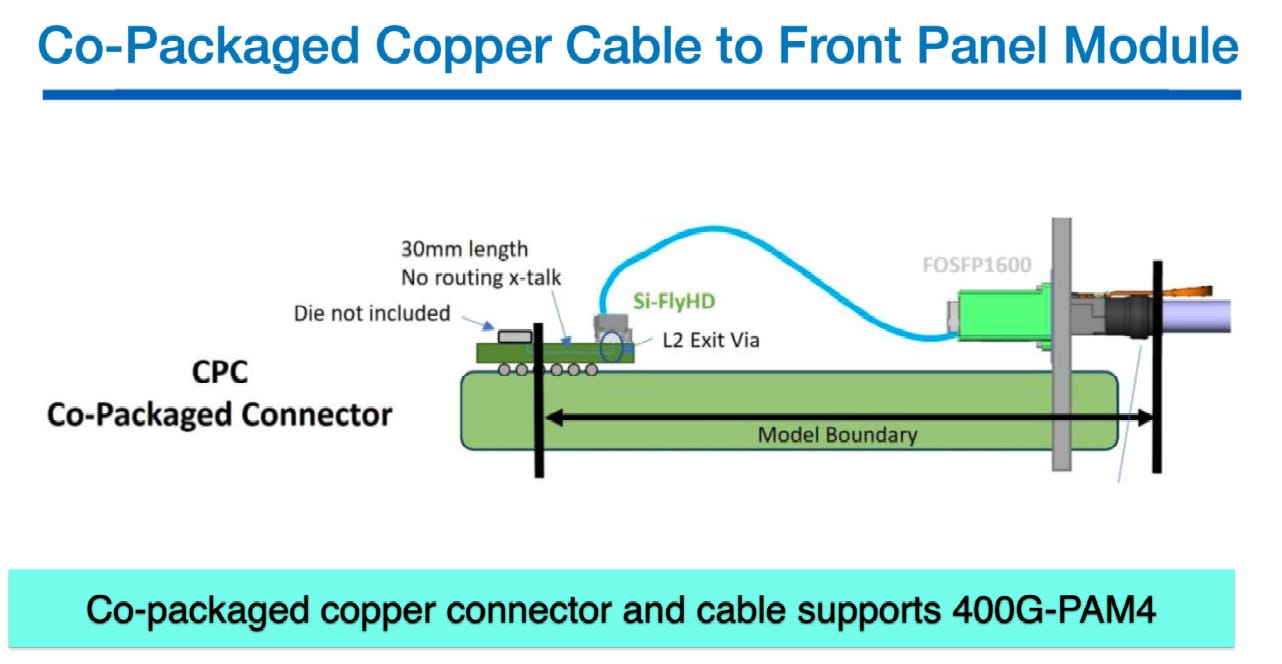
繞過 PCB 走線:
此圖展示了如何利用 Co-Packaged Copper (CPC) 架構來降低訊號損耗。將高速連接器 (如圖中的 Si-FlyHD) 配置在極度靠近 Switch 晶片的位置(CPC)。
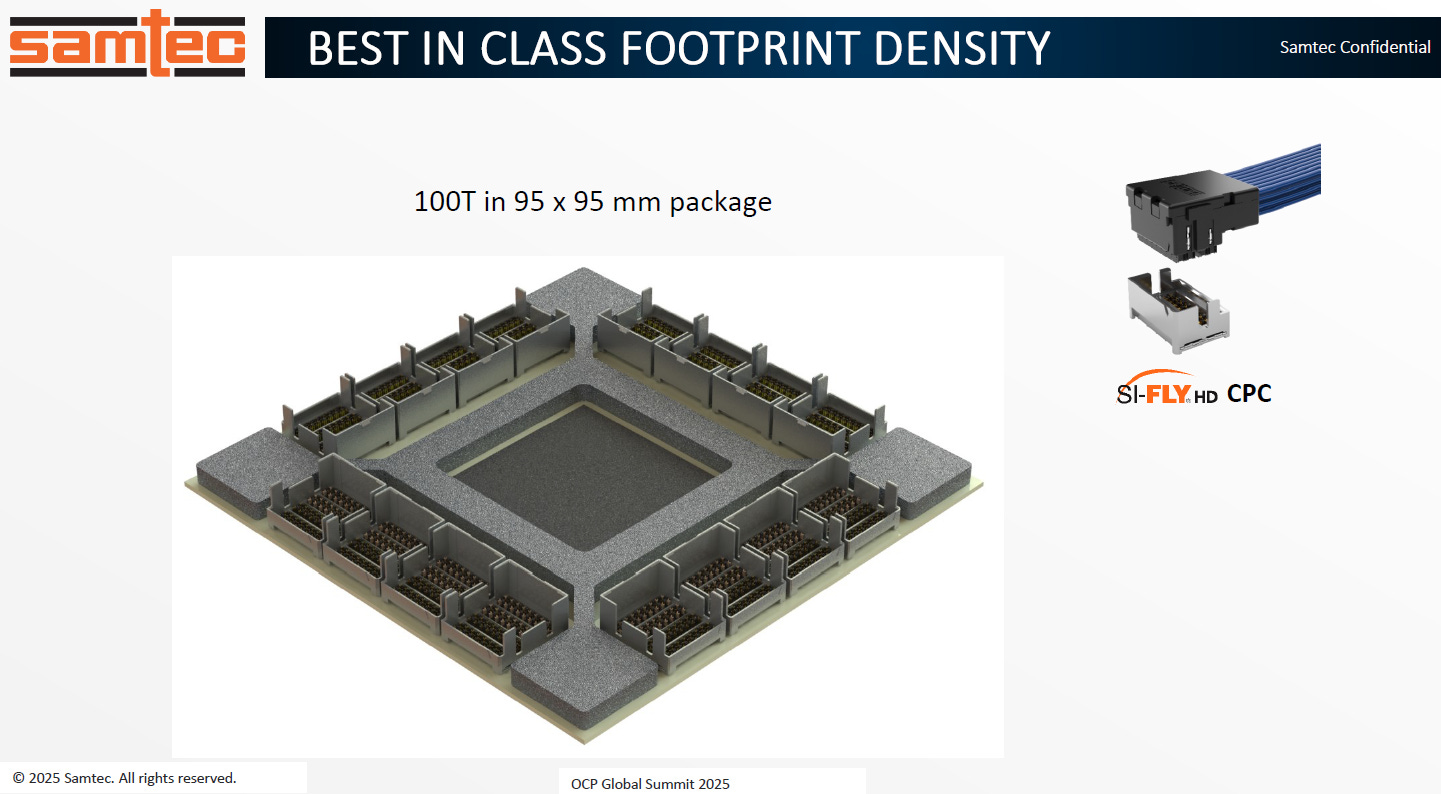
source: samtec
直接連結前面板:
400G-PAM4 訊號從晶片出來後,僅經過極短的載板走線 (標示為 30mm),即透過 CPC 轉換為雙軸電纜 (Twinax Cable),以實體飛線的方式直接連接至前面板的光模組,藉此有效維持 106.5 GHz 的訊號完整性。
2.4. 3.2T Optics Module
總結了 3.2T (8x400G-PAM4) 光模組在架構與材料上的規格與量產目標:

source: ISSCC26 F2_1
採用新型連接器
因應單通道 400G (106 GHz) 的高頻訊號完整性要求,傳統的 PCB 金手指插槽將被淘汰,必須轉換為新型的連接器
走向線性或半線性介面
為了嚴格控制 3.2T 模組的整體功耗,架構上將廣泛採用 Linear (全線性/LPO)、LRO (僅接收端線性) 或 TRO (僅發射端重定時) 等介面,以減少或免除 DSP 的使用
光學材料的交棒 (EML, InP or TFLN Optics)
在光學調變與發光元件上,將全面採用 EML、磷化銦 (InP) 或薄膜鈮酸鋰 (TFLN) 等具備超高頻響應特性的材料,以滿足 400G/lane 的需求
明確的量產時間表
產業界預期在新型連接器標準確立且生態系成熟後,3.2T 光模組將於 2028 年正式進入大規模量產階段
業界正在探索的另一種光學封裝架構:高通道數可插拔模組 (Higher Channel Count Pluggable Modules)

source: ISSCC26 F2_1
單一模組頻寬極大化:
方案將單一可插拔模組的通道數擴增至 64 個。在單通道 400G 的速率下,單一模組的總傳輸吞吐量可高達 25.6T(請參考: 6. 後記)。
64 組 TX 差分對 + 64 組 RX 差分對 = 128 組差分對
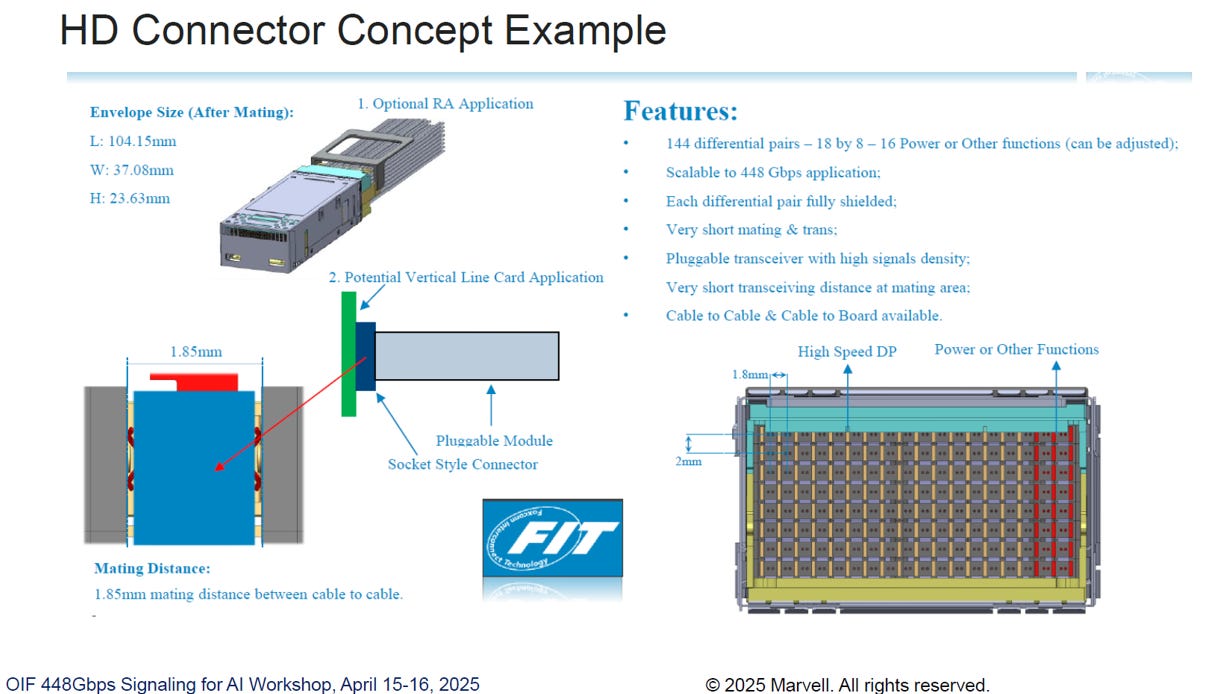
source: OIF
根據 FIT HD Connector 的規格表顯示,其設計容量為 144 組差分對
128 組 < 144 組,該連接器完全具備承載 64 個 400G 通道的能力
該 HD Connector 設計規格,確實能夠涵蓋並支援 25.6T 高通道數模組的硬體傳輸需求
縮短電氣通道與簡化系統配置:
針對次世代總頻寬達 204.8T 的交換器晶片,系統僅需配置 8 個此類高通道數模組即可滿足需求。這能大幅減少前面板的模組數量,並有效縮短系統內部的電氣走線距離
液冷散熱為必備條件:
由於將 25.6T 的傳輸能力集中於單一可插拔模組內會產生極高熱量,投影片底部標示,此架構的散熱挑戰必須透過液冷技術 (Liquid cooling) 來解決
需推動跨廠商標準化
此類高通道數規格目前尚未普及,若要大規模商用,必須仰賴跨廠商共同制定標準化協議。目前業界對此高密度插拔方案的興趣正逐漸增加。
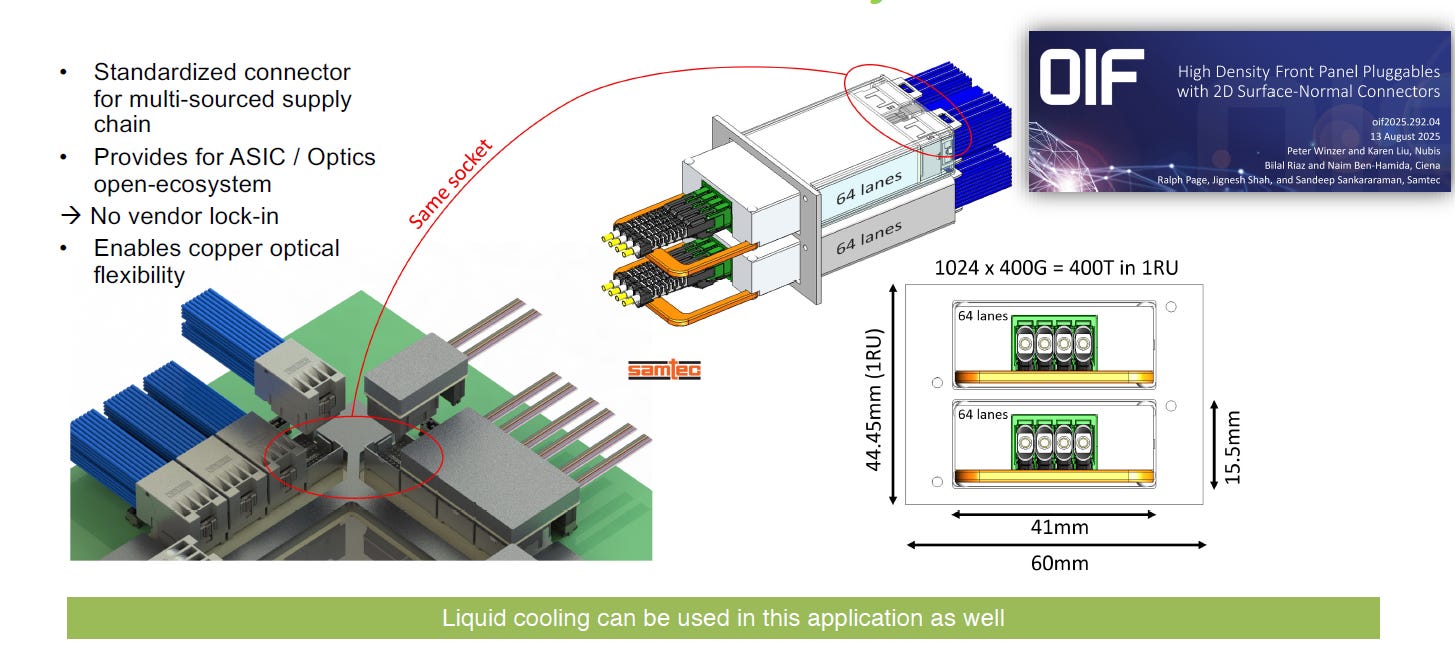
source: OFC 26
2.5. 400G Copper Interconnect
CPC支援單通道 400G-PAM4 (實體層 425G) 的純銅電氣通道 (Electrical channel) 模擬架構如下。若應用於 3.2T 銅線模組或連接方案,即是將此單通道架構擴展為 8 個通道 (8x400G) 進行平行傳輸。

source: ISSCC26 F2_1
業界大師級專家 Mike Peng Li 所發布的 425G-PAM4 實體層模擬結果:透過特定架構,銅線仍具備一定長度的傳輸能力(請參考 Mike Li介紹: EP28. Jitter )。

source: ISSCC26 F2_1
模擬基準與條件:
訊號標準:採用帶有 KP-FEC 糾錯碼的乙太網路標準 (425 Gbps)。
頻寬需求:對應 106.25 GHz 的 Nyquist 頻寬。
評估指標:以 COM (Channel Operating Margin,通道運行餘量) 作為衡量整體訊號完整性的單一量化指標。

source: ISSCC26 F2_1
測試模型建構:
建立了 15 組端到端 (E2E) 的傳輸通道模型,長度涵蓋 100mm 至 1500mm。
實體架構採用最新的 CPC (Co-Packaged Copper) 連接器,並搭配 31 AWG 規格的實體銅線電纜。
晶片與封裝參數同樣是由 224G 擴展而來
關鍵模擬結果 (Mike Li's Result):
模擬數據顯示,當要求 COM 值大於或等於 3 dB (即具備足夠的訊號餘量) 且插入損耗 (IL) 上限設定為 42 dB 時,此端到端 (E2E CPC-CPC) 傳輸通道的最大可行長度可達 1200 mm (1.2 公尺)。
只要捨棄傳統 PCB 走線,改用「CPC 連接器 + 31 AWG 實體雙軸電纜 (Twinax)」的架構,純銅傳輸依然足以應付單一機櫃內部 (Intra-rack) 伺服器與交換器之間的短距離互連需求。
純銅實體層高頻挑戰摘要:

source: ISSCC26 F2_1
訊號衰減與干擾: 集膚效應與介電損耗直接縮短有效傳輸距離;頻率相關的損耗差異會導致符號間干擾 (ISI);任何微小的阻抗不連續皆會引發反射干擾。
製造與機構極限: 極高頻環境對製造公差極度敏感,微小的幾何變異即會改變電氣特性;系統內外部的高頻串擾隨頻率急遽上升;具備全屏蔽設計的連接器已逼近微型化的實體空間極限。
系統級妥協: 若要突破上述物理限制,僅能依賴更高階的調變技術(如 PAM6 或 PAM8),但這將連帶增加 DSP 運算複雜度與系統整體功耗
3. Other Solutions
3.1. RF solution
介於「純銅電纜」與「光纖通訊」之間的另類實體層傳輸技術:中空波導管射頻傳輸 (RF over Hollow-core Waveguides)

source: ISSCC26 F2_1
核心傳輸機制
將數位電氣訊號轉換為毫米波 (mmWave) 或太赫茲 (Terahertz) 等級的射頻 (RF) 訊號。這些射頻訊號透過兩端的 SoC 晶片與天線,被發送進入內部為空氣的「塑膠波導管 (Plastic Waveguide)」中進行物理傳輸
對比純銅傳輸的優勢
消除物理損耗: 由於射頻訊號是在波導管內部的空氣中傳輸,因此避開了傳統銅線的集膚效應與介電損耗問題。
降低干擾與延長距離: 符號間干擾 (ISI) 大幅減少,使其有效傳輸距離可延伸至 10 到 20 公尺,涵蓋了純銅線難以觸及的範圍。
對比光學傳輸的優勢
免除光電轉換: 訊號從頭到尾皆維持在「電氣/射頻」領域,系統不需要配置雷射光源、光學調變器或光檢測器 (PD)。
降低製造成本與功耗: 省去了光學元件的材料成本與耗電,且波導管的對接不需要光纖那種微米等級 (Micrometer) 的精密對位封裝
實作規格與擴展性 (以 Point2 e-Tube 為例)
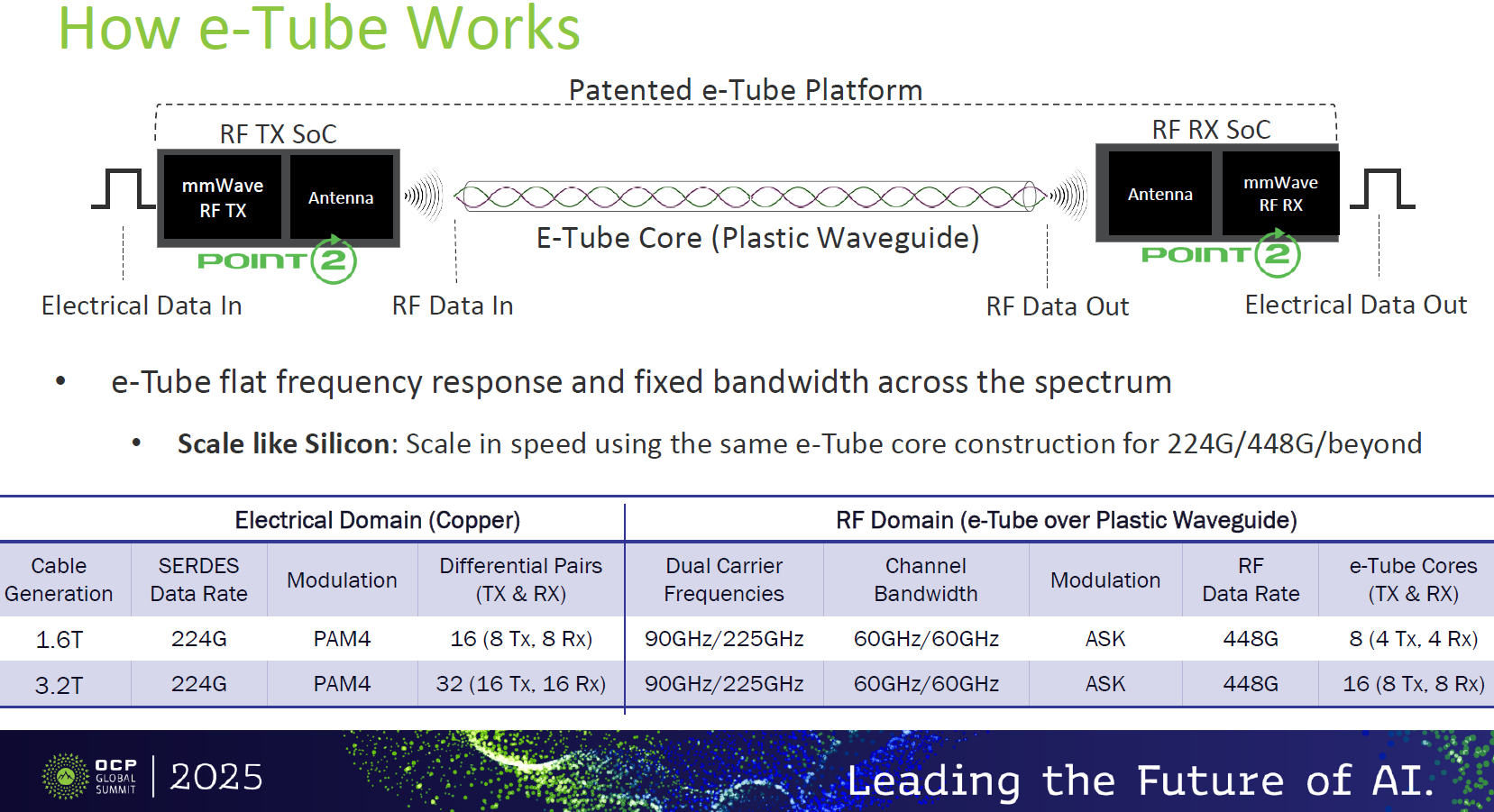
source: Point2
平坦的頻率響應: 該波導管具備固定的頻寬特性,有利於未來傳輸速率的擴展 (Scale like Silicon)。
通道簡化: 在 1.6T (224G 世代) 的應用中,傳統銅線需要 16 組差分對 (8 Tx, 8 Rx);而 e-Tube 透過雙載波頻率 (90GHz/225GHz) 與 ASK 調變,將 RF 資料率提升至 448G,因此僅需 8 條波導管 (4 Tx, 4 Rx) 即可完成同等吞吐量
產業界將這種射頻波導管技術定位為資料中心 「Scale-Up (向上擴展)」 架構中,針對 10 至 20 公尺跨機櫃連線的一種折衷解決方案。它試圖在純銅的距離限制與光學元件的高昂成本之間,提供另一個具備商用潛力的選項(請參考:EP22. Interconnect Media )。
3.2. CPO(Co-Packaged Optics)

source: ISSCC26 F2_1
400 Gbps/Lane 世代:CPO 面臨的材料與製程矛盾
優勢仍在(極短的電氣通道): CPO將光學引擎與 Switch/GPU 封裝在一起,只需約 50mm 的極短走線,可將插入損耗 (IL) 壓低在 17 dB 左右。
物理極限卡關: 主流 CPO 所依賴的矽光子 (SiPh) 材料,其頻寬已無法支撐 400G-PAM4。
製程生態系未就緒: 雖然理論上可以將 CPO 內部的材料換成 InP 或 TFLN 來突破頻寬限制,但目前這些新材料的製程 (Flow) 尚未準備好進入複雜的 CPO 量產體系
結論: CPO 短期內將停留在單通道 200 Gbps 的速度更長一段時間。 這代表 CPO 在單通道提速的競賽中,暫時落後於可插拔模組 (Pluggables) 陣營

source: ISSCC26 F2_1
Slow and Wide Optics ("Beyond CPO"):
架構轉型: CPO 將走向Slow & Wide 路線。例如 50G-NRZ 的平行介面,減少驅動高頻訊號所需的複雜補償電路,大幅削減電氣層耗能。
元件需求: 需要極高密度的微環調變器 (Micro-Ring-Modulators) 以及外部高密度雷射陣列 (Comb-lasers) 來支撐DWDM。
製程挑戰:
目前矽光子 CPO 依賴極其複雜的異質鍵合 (Hybrid bonding) 先進封裝製程。
光纖耦合單元 (FAUs) 的良率至今仍無法達到 100%。
在極度昂貴的 GPU 或高階 Switch 晶片封裝過程中,產業界無法承擔任何因為光學元件 (FAU) 良率瑕疵而導致整顆昂貴晶片報廢的風險。
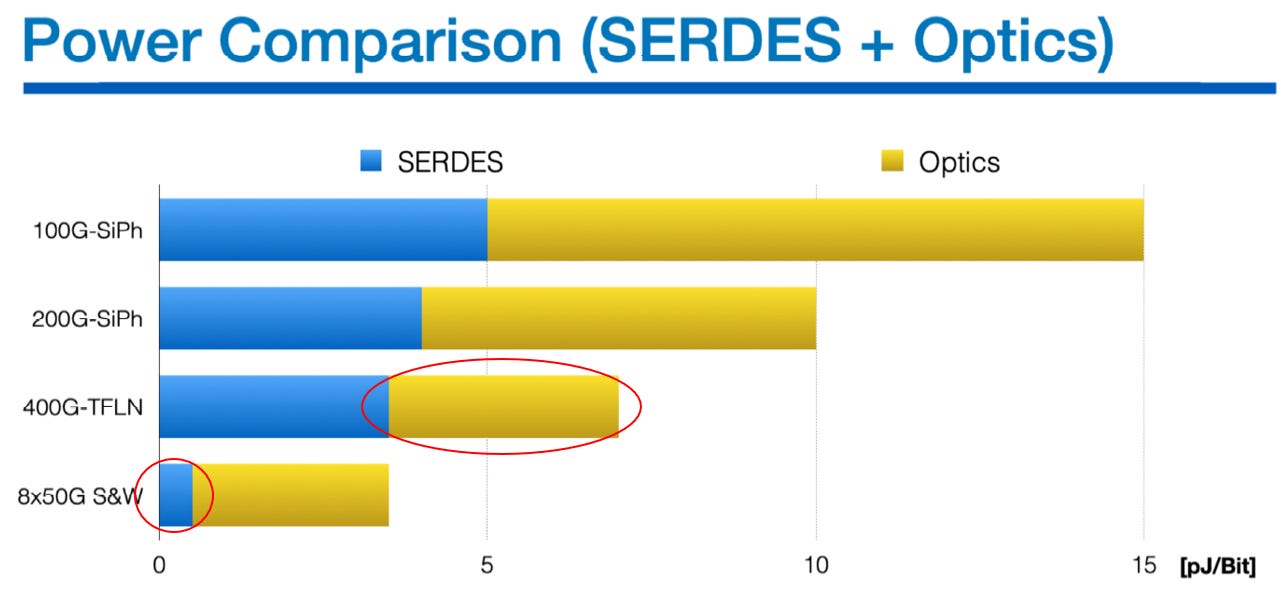
source: ISSCC26 F2_1
400G-TFLN (Fast&Narrow) 功耗特徵:
SerDes 功耗較高: 為維持 400G PAM4 訊號完整性,DSP 必須全速運作。
光學功耗極低: TFLN 材料具備低半波電壓 (Vpi),允許 DSP 直接驅動 (Direct Drive),省去高耗電的外部驅動晶片 (Driver IC)。
8x50G S&W (Slow&Wide) 功耗特徵:
SerDes 功耗極低: 降頻至 50G NRZ,免除複雜的 DSP 與 FEC 運算。
光學功耗佔比高: 需平行擴增多組光學通道以維持總頻寬,將挑戰轉移至先進封裝良率。
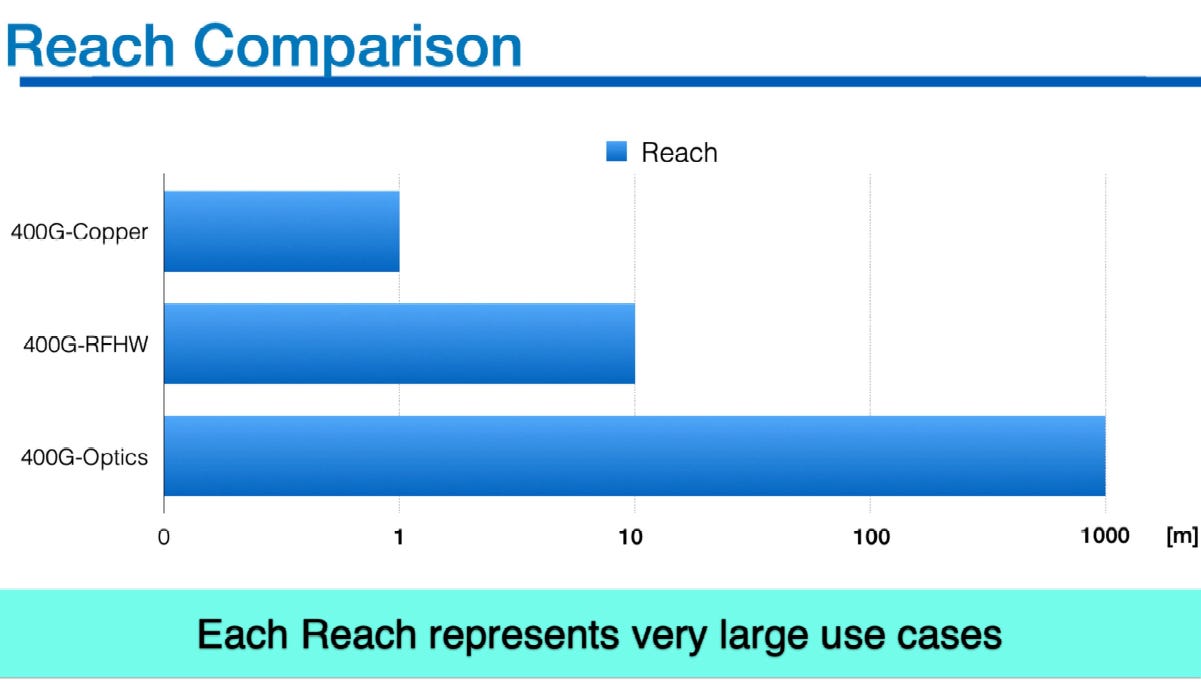
4. 傳輸技術比較
四種主要400G傳輸技術的比較(請參考:EP22. Interconnect Media ):

source: ISSCC26 F2_1
純銅傳輸 (400G-Copper)
傳輸距離: 最短,極限約為 1.2 公尺。
技術現況: 具備挑戰性但具可行性 (Challenging but doable)。
技術條件: 需仰賴高規格的 45 dB LR SERDES 以及 31 AWG 雙軸銅線 (Twin-ax copper)。
應用場景: 侷限於單一機櫃內部 (Intra-rack) 的極短距離互連
射頻中空波導管 (400G-RFHW)
傳輸距離: 涵蓋 10 至 20 公尺的中等距離。
技術現況: 研發中 (In development)。
技術優勢: 可達到跨機櫃的傳輸距離,且無需光學轉換元件,也免除了微米級的精密對位封裝。
應用場景: 針對資料中心內部的 Scale-Up 擴展需求
高頻單通道光學 (400G-Optics per lane)
傳輸距離: 最長,可達 1000 公尺 (1 公里) 以上。
技術現況: 基礎建設已相對完備 (Well established)。
技術條件: 必須採用具備超高頻寬的調變器材料,如 InP (磷化銦) 或 TFLN (薄膜鈮酸鋰)。
應用場景: 大規模資料中心網路 (Scale-out) 的長距離資料傳輸
降頻多通道光學 (Slow & Wide Optics)
技術現況: 研發中 (In development)。
核心挑戰: 這是一項先進封裝挑戰 (Advanced packaging challenge)。它需要極高良率的矽級別整合 (Silicon level integration),將多波長 DWDM 光學元件與晶片進行共同封裝
source: ISSCC26 F2_1

source: ISSCC26 F2_1
市場時程: 400G-PAM4 預計於 2028 年成為主流。
純銅線 (Copper): 傳輸極限約 1 公尺,適用於機箱或機櫃內部的短距連線。
射頻波導管 (RF): 傳輸距離 10 至 20 公尺,對應 Scale-up 擴展架構。
單通道光學 (Optics): 架構風險低,目前的產業焦點是哪種調變器技術能率先實現大規模量產。
降頻多通道光學 (Slow-and-Wide): 尚在研發中,高度依賴矽級整合,且與其他 400G 介面不相容。
終極結論: 單通道 400G 極可能是資料中心通訊發展的最終物理階段
5. 結論
綜合上述技術發展,單通道 400G (400G/lane) 極有可能是資料中心通訊演進在物理極限下的最終階段 。從 Andy Bechtolsheim 的務實觀點來看,未來的 400G-PAM4 (3.2T)世代將不會出現單一技術壟斷的局面,而是依據物理傳輸距離形成精細的市場分工 。在機櫃內部 1.2 公尺的短距互連,搭配 CPC 連接器的純銅架構依然具備工程可行性 ;面對 10 至 20 公尺的 Scale-Up 需求,射頻中空波導管 (RFHW) 展現了無須光電轉換的創新潛力 ;而在長距離的 Scale-Out 網路中,採用 InP 或 TFLN 等高頻寬材料的可插拔光模組,因具備成熟的量產產線與較低的架構風險,將繼續穩居市場主流 。
相對而言,CPO 陣營的 Slow & Wide 方案雖然在總體功耗上具備優勢,但必須先跨越極度艱鉅的先進封裝與光纖對位良率挑戰 。在迎來 2028 年的 3.2T 大規模佈署之前,底層材料生態系與製造良率的成熟度,將成為決定各項技術商業勝負的關鍵 。
6. 後記
2026 年 3 月的OFC(光纖通訊展覽會)上,由 Arista Networks 主導發起 XPO(eXtra-dense Pluggable Optics)MSA (Andy Bechtolsheim 是該協定的核心推動者), TeraHop也展示了XPO(請參考: Introducing XPO: Pluggable Optics for AI Networking; Inside AI Optical Scaling: Keysight and TeraHop at OFC)。

source: Arista
XPO MSA 技術與產業架構總結
發展背景與核心定位
隨著 AI 基礎設施在 Scale-up(如 NVLink)與 Scale-out(如乙太網路、InfiniBand)的頻寬需求呈指數級增長,單一光模組的功耗與散熱已逼近傳統風冷的物理極限。業界目前在「延續可插拔光學模組(Pluggable Optics)」與「轉向共同封裝光學(CPO / NPO)」之間存在路線博弈。
由 Arista 主導的 XPO MSA,其核心定位是將可插拔模組的生命週期與效能推向極致。透過導入液冷技術,XPO 試圖在解決極端功耗問題的同時,保留資料中心營運商高度重視的熱插拔維護彈性與供應鏈多樣性,避免過早受限於 CPO 架構帶來的良率與維修成本挑戰。
關鍵硬體與技術規格
XPO 在設計上大幅超越了現有的 QSFP 或 OSFP 標準,專為次世代超大頻寬與高密度互連量身打造:

source: Arista
超高通道密度:採用 64 路高速電訊號通道,若以每通道 200 Gbps(採用 224G SerDes 技術)計算,單一模組可提供高達 12.8 Tbps 的吞吐量( 2.4. 的舉例是400Gbps SerDes/25.6Tbps total)。
前面板極限密度:在標準 1U OCP 機架空間內,總吞吐量可達 204.8 Tbps,相當於現有 1600G OSFP 密度的 4 倍,大幅節省交換器機架空間。
內建液冷架構:模組設計直接整合液冷冷板(Liquid Cold Plate),將單一模組的解熱能力上限拉高至 400W。這為高功耗的相干光學(Coherent Optics)或高密度矽光子(SiPh)引擎提供了充足的熱預算(Thermal Budget)。
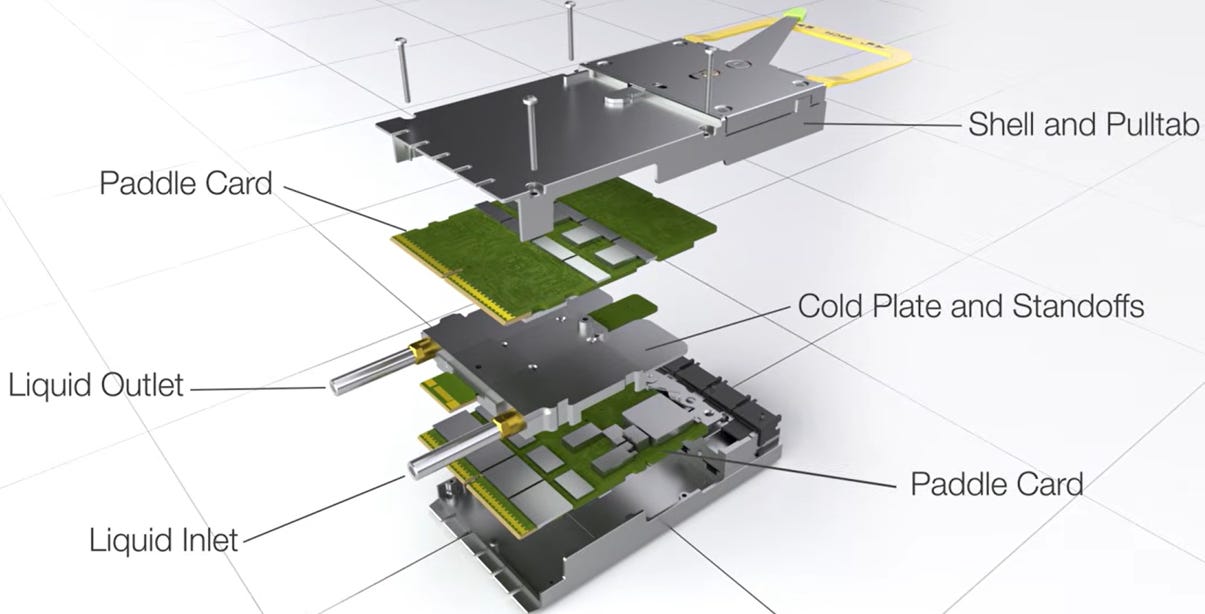
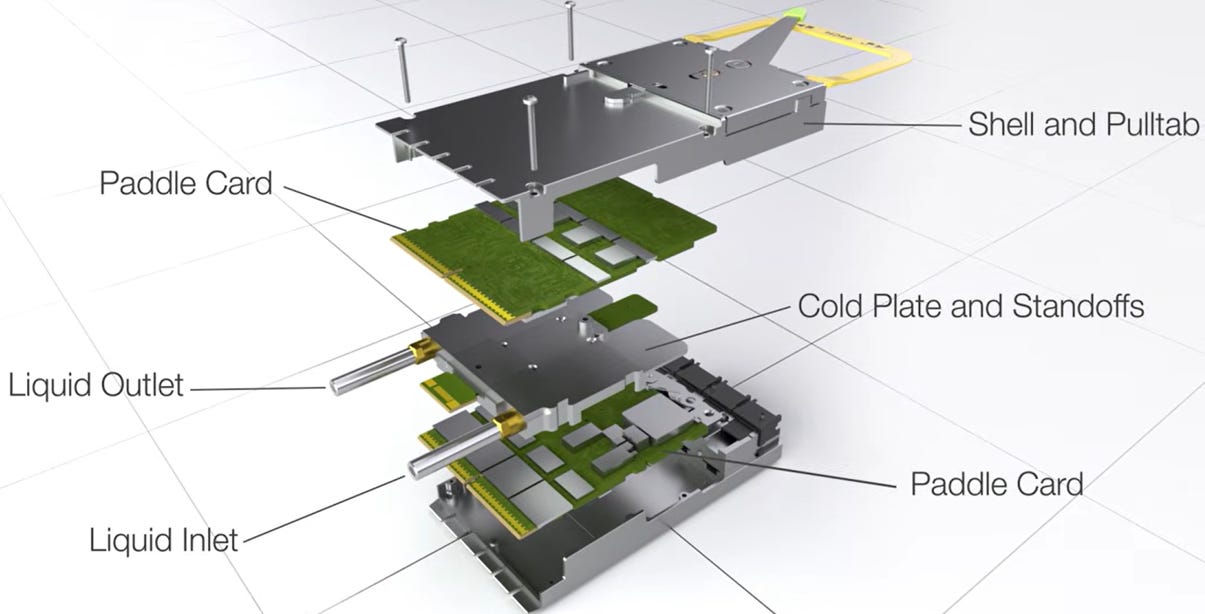
source: Arista
訊號架構與光學相容性
為了確保新標準能迅速融入現有網路架構,XPO 在介面與傳輸協定上保持高度彈性:
DSP 晶片架構支援:支援線性驅動(Linear Drive / LPO)、半重定時(Half-retimed / CPO-like)以及全重定時(Fully-retimed,內建完整 DSP)的介面設計,讓系統廠能根據功耗與訊號完整性需求進行取捨。
光學標準相容:涵蓋短距到長距的應用場景,相容標準包含 DR、FR、LR、SR,以及針對資料中心互連(DCI)的 ZR/ZR+ 相干光纖規格(這是CPO辦不到的)。
產業生態系與戰略影響
推動者與聯盟成員:該 MSA 於 2026 年 OFC 展會亮相,由 Arista 共同創辦人 Andy Bechtolsheim 領軍推動。成立初期即獲得超過 45 家產業鏈關鍵廠商支持,包含超大型雲端服務商(如 Microsoft)、光學元件與矽光子晶片大廠(如 Marvell、Lightmatter),以及眾多連接器與模組製造商。
市場戰略意義:XPO 提供了一條清晰的過渡路徑。對於大型資料中心而言,它降低了全面轉換至 CPO 架構的急迫性風險,讓基礎設施能繼續沿用模組化的維護邏輯來部署 1.6T、3.2T 甚至更高速的 AI 網路互連方案。
XPO 藉由CPC 低損耗電氣路徑架構,以及TFLN 高階光學材料的相容性,透過液冷技術解除了散熱問題,成功在「可插拔」的彈性基礎上,達成「按需配置(Pay-as-you-grow)」的靈活性。讓雲端服務商能以最高的硬體重複利用率來建置 AI 網路,這正是目前統一規格的 CPO 架構,無法提供的核心價值。
[Reference]
ISSCC2026_Forums_F2_1 Data Centre Interconnect 400G, 800G and Terabit pluggable Optics