EP36. 解析 NVIDIA 次世代光學引擎

在 AI 算力爆發的今天,晶片間 (Scale-up) 互連的「功耗之壁」已成為最大系統瓶頸。為了將傳輸能效壓縮至 5 pJ/bit 以下以取代短距銅纜,光學互連技術正加速從插拔式邁向共封裝 (CPO),讓光學引擎在物理空間上極致逼近運算核心。
面對此挑戰,NVIDIA 在 ISSCC 2026 提出了極具突破性的解法。他們採用「慢而寬 (Slow and Wide)」策略,捨棄了耗電的數位訊號處理器 (DSP) 與時脈資料恢復電路 (CDR),轉而以極具巧思的「類比電路設計 (Analog Design)」完美解決時脈轉發 (Forwarded Clock) 架構下的雜訊問題。本文將深入拆解這顆次世代光學引擎的內部細節,NVIDIA 如何成功達成總功耗僅 2.59 pJ/bit 的設計。分享個人觀點,歡迎討論。
1. Background
1.1. 光學互連技術演進
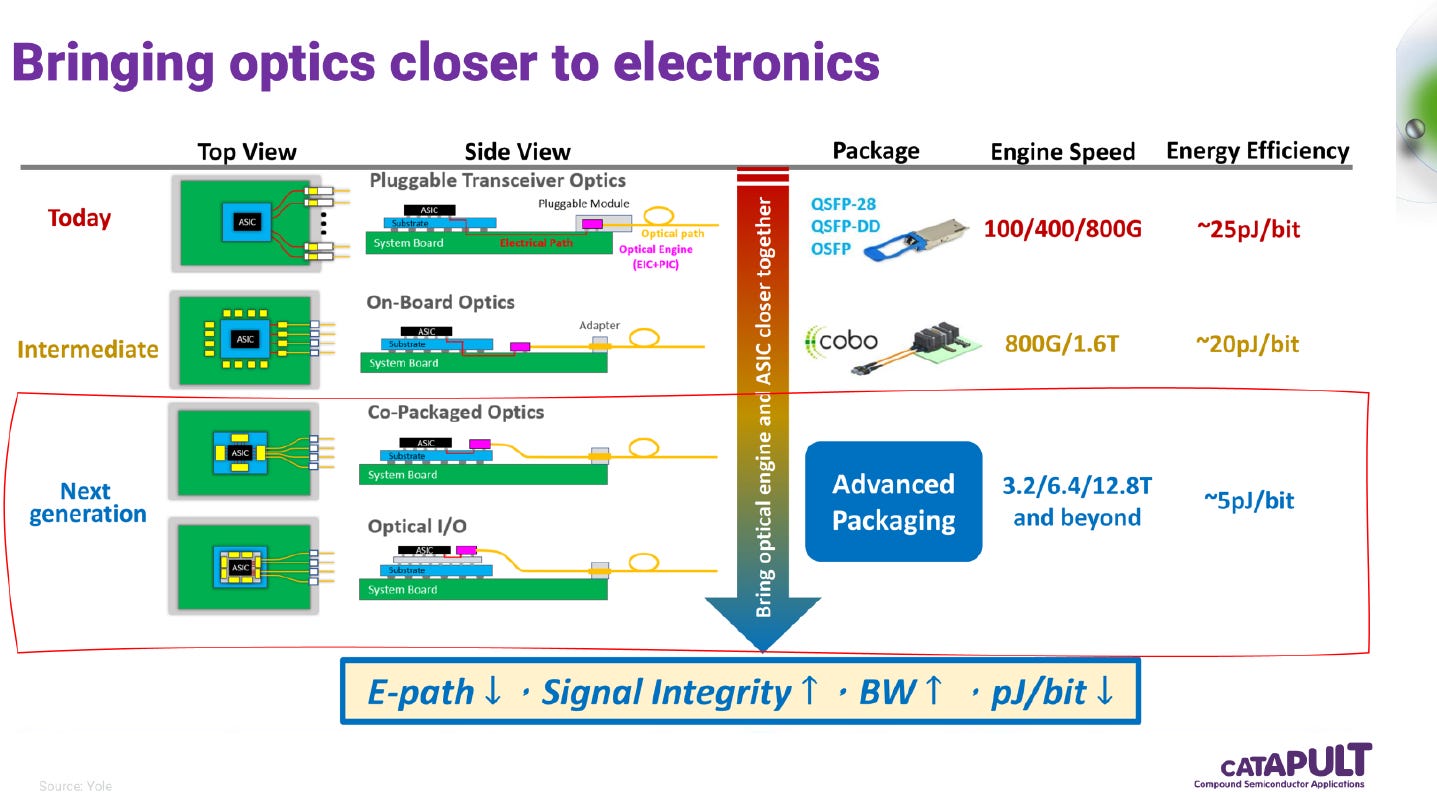
光學互連技術(Optical Interconnects)正處於「從插拔到共封裝」的歷史轉折點。演進不僅是「距離」的拉近,更是功耗(pJ/bit)與整合複雜度的演進。
source: CSA Catapult
source: Broadcom
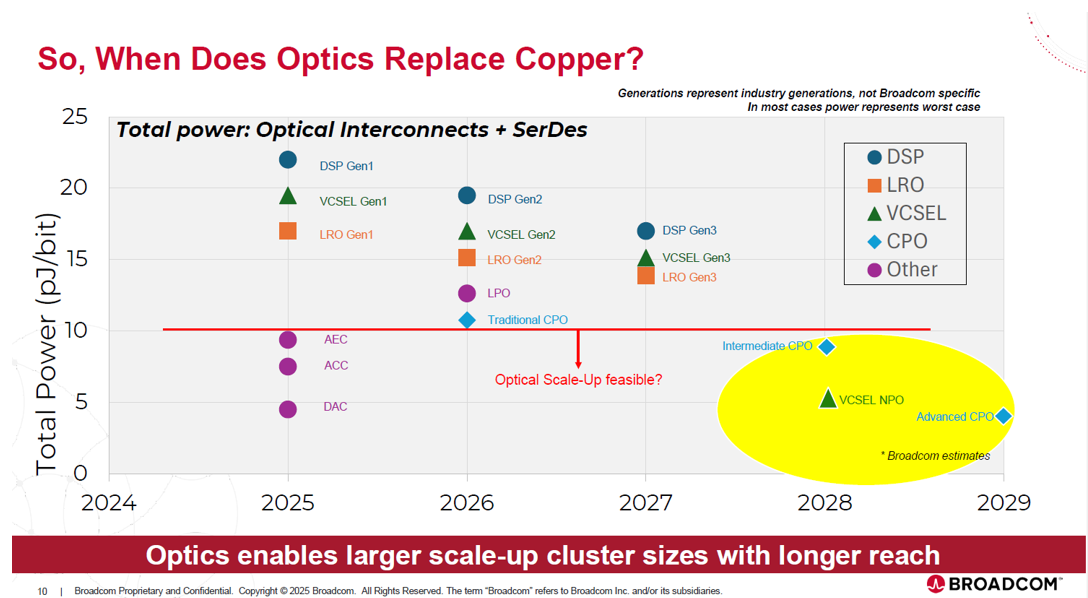
光學互連技術的演進,核心是為了解決 AI 晶片間(Scale-up)高速傳輸的功耗瓶頸。最終目標是讓光學傳輸的能效取代銅纜(低於 5 pJ/bit),從而實現無縫的超大規模運算叢集。
整個演進路線,本質上就是光學引擎(O/E)在物理空間上不斷向運算核心(XPU)逼近的過程,可簡述為三個階段:
現狀(插拔式 Pluggable): 光模組位於機殼面板,與晶片間透過長達十幾公分的 PCB 銅線連接。能效最差(約 20 到 25 pJ/bit),無法滿足未來高密度 AI 機櫃的需求。
過渡期(2026 到 2027 年,傳統 CPO): 以 Broadcom 的 TH6 平台為例,將光引擎與晶片整合在同一個「封裝基板(Substrate)」上。電路走線縮短至公分(10 mm)級,能效降至 10 到 15 pJ/bit,進步顯著但仍未跨越銅纜的低功耗門檻。
終局(2029 年,Advanced CPO 或 OIO(Optical I/O)): 這是真正的次世代架構。光引擎與晶片會被共同封裝在同一個「中介層(Interposer)」上。透過 2.5D/3D 先進封裝技術,晶片到電路晶粒(XPU to EIC)的距離被極致壓縮到公釐(mm)級。這使得能效正式突破 5 pJ/bit 以下,具備全面取代短距銅纜的優勢。
總結來說:網通定義的「Advanced CPO」與半導體定義的「Optical I/O」在硬體架構上將會殊途同歸。透過先進封裝,光學引擎(O/E)會實質變成一顆超低功耗、緊貼著運算核心的通訊 I/O Chiplet。
1.2. Fast&Narrow vs. Slow&Wide
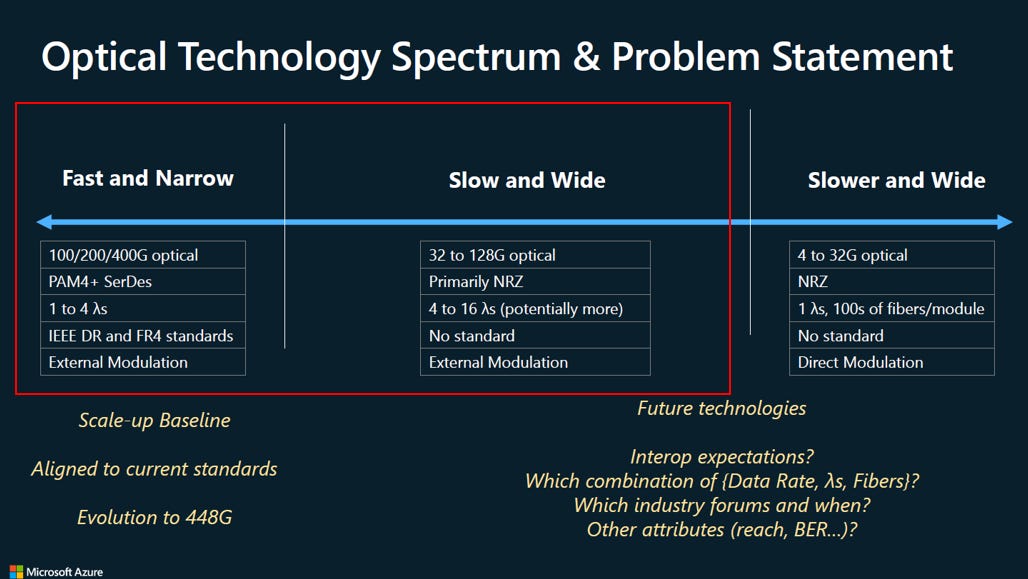
目前光學互連架構在面對 AI 龐大頻寬需求時,兩條截然不同的技術哲學:「拉高單通道極速」或是「增加平行通道數量」:
source: Microsoft
Fast and Narrow (快而窄 - 現有主流):
追求極致的單通道極速 (100/200/400G),使用少量的波長 (1 到 4 λs)。優勢是擁有成熟的 IEEE 產業標準,是目前的發展基準,但代價是必須依賴極其耗電且複雜的調變技術 (PAM4+ SerDes)和DSP:
source: Broadcom
Slow/Slower and Wide (慢而寬 - 未來潛力):
降低單通道速度 (降至 128G 甚至 32G 以下),改用簡單且省電的 NRZ 調變,藉由大幅增加平行的波長 (4 到 16+ λs) 或是數百根光纖來達成高總頻寬。
核心困境 (Problem Statement):
「慢而寬」架構因為省去了複雜的訊號補償 (DSP),能大幅降低功耗與延遲,是超大規模資料中心 (如微軟) 非常渴望的未來方向。然而,它目前面臨**「完全缺乏產業標準 (No standard)」**的致命傷。
1.3. Nvidia Spectrum 6 CPO — Fast&Narrow
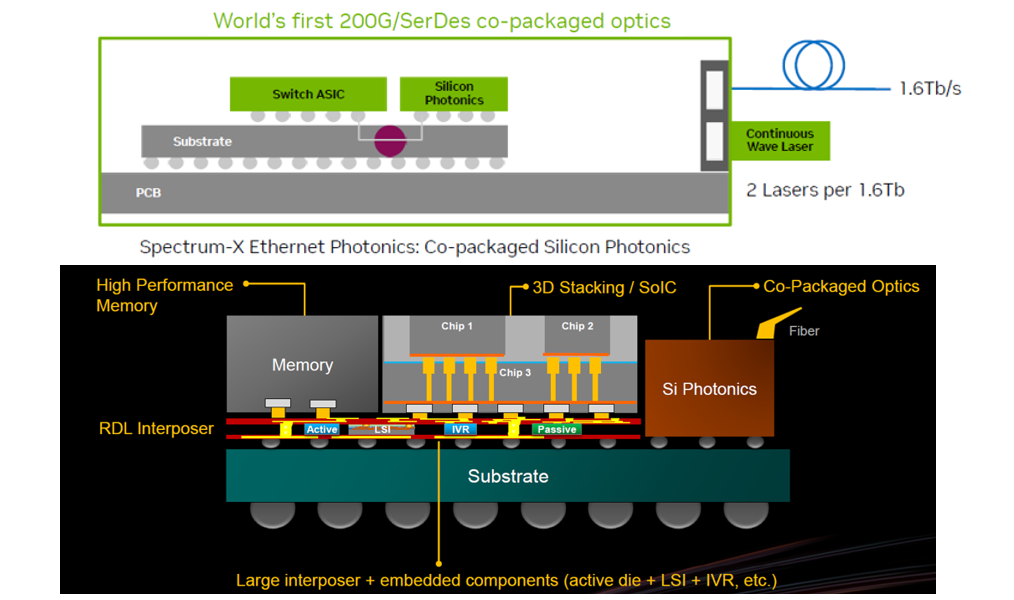
NVIDIA 針對單通道 200G 世代(應用於 Spectrum-6 等級乙太網路交換機)所推出的 CPO 光電架構:
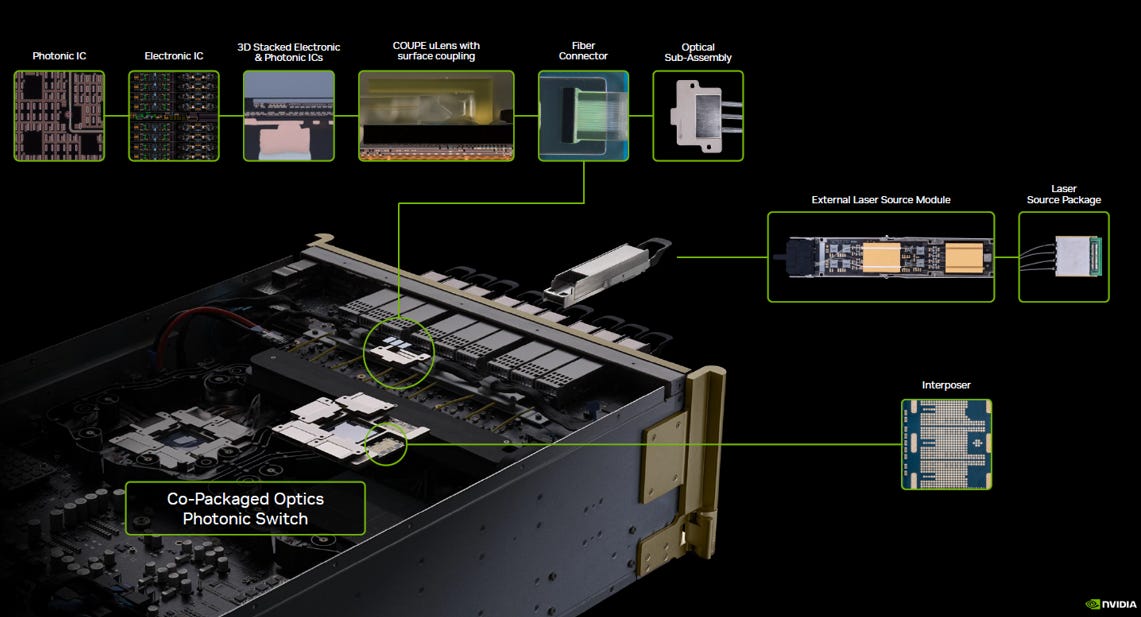
source: Nvidia
source: Nvidia, TSMC
NVIDIA Spectrum CPO 架構的核心,是利用TSMC的 2.5D/3D 先進封裝來突破單通道 200G(Fast&Narrow) 世代的功耗與訊號瓶頸。
封裝尺度的終極壓縮 (從 cm 到 mm,再到 μm)
捨棄 cm 級走線:淘汰傳統插拔式模組長達十多公分 (cm) 的耗電 PCB 銅線
進入 mm 級 (2.5D 整合):將交換機 ASIC 與矽光子引擎整合在同一個封裝基板(Substrate)上,將兩者間的高速電訊號路徑大幅縮短至小於10公釐 (mm) 級
深入 μm 級 (3D 堆疊):在光引擎內部,透過 TSMC COUPE 技術將電路晶粒 (EIC) 直接垂直堆疊於光路晶粒 (PIC) 之上,將驅動光調變器的實體路徑進一步壓縮至極致的微米 (μm) 級
光源外置設計 (ELS, External Laser Source)
為避免交換機 ASIC 運作時的高溫大幅折損雷射壽命,NVIDIA 將連續波雷射 (CW Laser) 從光引擎中抽出,改為配置在散熱條件良好的機殼前面板插槽上。
捨棄了昂貴且難以加工的保偏光纖(PMF),改以廉價的單模光纖 (SMF) 將光源送入 CPO 模組內。
為了克服單模光纖的偏振飄移,NVIDIA 在矽光晶片上整合了主動偏振控制電路來進行動態補償。這種設計大幅降低了外部硬體的組裝複雜度與量產成本。
內嵌式供電網路 (Embedded PDN) based on CoWoS-L
為了應對高密度封裝下的供電完整性 (PI) 挑戰,該架構在中介層中直接內嵌了整合型電壓調節器 (IVR) 等主動元件。
這種設計能就近為極度耗電的 200G SerDes 與光引擎,提供純淨且具備快速瞬態響應的大電流電源
這套架構示範了如何利用極致的 2.5D/3D CPO 異質整合技術,卸除 ASIC 驅動長距電訊號的負擔,為 AI 叢集在 Scale-out 網路的持續擴張打下低功耗的硬體基礎。
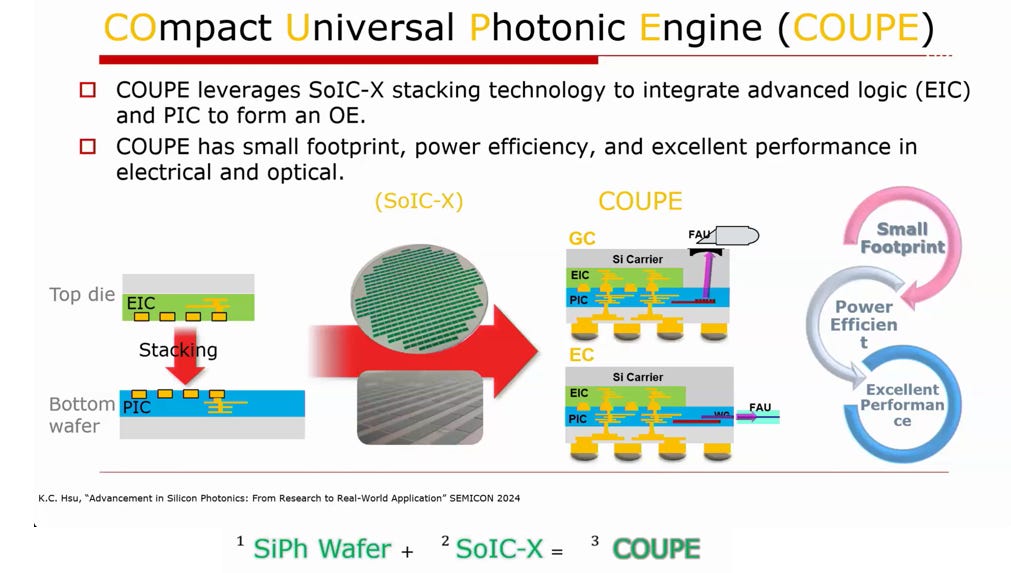
1.4. TSMC COUPE
COUPE (COmpact Universal Photonic Engine) 是台積電專為突破光學互連頻寬與功耗瓶頸所打造的先進封裝平台。核心為:SiPh Wafer + SoIC-X = COUPE。透過將先進邏輯電路與矽光子晶片進行 3D 堆疊,COUPE 成為實現單通道 200Gbps CPO 與未來OIO 的關鍵基礎。
source: TSMC
核心架構:基於 SoIC-X 的 3D 堆疊
COUPE 捨棄了傳統的 2.5D 平面佈線,採用台積電自家的 SoIC-X (Hybrid Bonding, 混合鍵合)技術進行垂直整合。
極致的 E-path 壓縮:這種 3D 堆疊將驅動器 (Driver) 到光調變器之間的電訊號路徑,從公釐 (mm) 級壓縮到了微米 (μm) 級,大幅降低了寄生電容與訊號延遲,是實現超高能效 (Power Efficient) 的物理前提。
EIC over PIC 設計:
熱力學最佳化:EIC (熱源) 在上,直觸散熱器
光學穩定性:PIC 在下,遠離火爐,避免熱光效應干擾波長
機構解耦:PIC 在下,提供穩固基座讓光纖 (FAU) 輕易對接
製程與成本最佳化:利用 65nm PIC 的廉價面積與強韌結構來承載 TSV,完美避開在 7nm EIC 上打孔的高昂成本與良率風險
光纖耦合突破:挑戰 0.3dB 的極限損耗
COUPE 平台同時支援了邊緣耦合 (EC) 與表面耦合 (GC) 兩種光纖對接方式。其中最具突破性的是其 GC (Grating Coupler) 方案:
傳統上,表面耦合雖然易於進行晶圓級的大規模自動化測試與封裝,但向下的光學漏失極大(損耗通常大於 1.5dB)。
COUPE 透過在 CMOS 後段製程中精準整合底部金屬反射鏡 (Bottom Metal Mirror, BMM),將向下漏失的光能量反射回上方;再配合微透鏡 (uLens) 進行模場整形,精準打入 FAU 中。
這項設計讓易於量產的表面耦合(GC),也能達到 ~0.3dB 媲美邊緣耦合(EC)的極低光學損耗(Ref. IEDM 2024 TSMC)。
總結:COUPE 帶來的三大綜效
小尺寸 (Small Footprint):大幅縮小光引擎體積,滿足高密度交換機前面板或 XPU 邊緣的空間限制。
高能效 (Power Efficient):消除長距電路走線的損耗,朝向 < 5 pJ/bit 的終極目標邁進
卓越的光電性能 (Excellent Performance):確保了 200G 世代極高頻寬下的訊號完整性與系統可靠度
2. Nvidia New Optics Engine
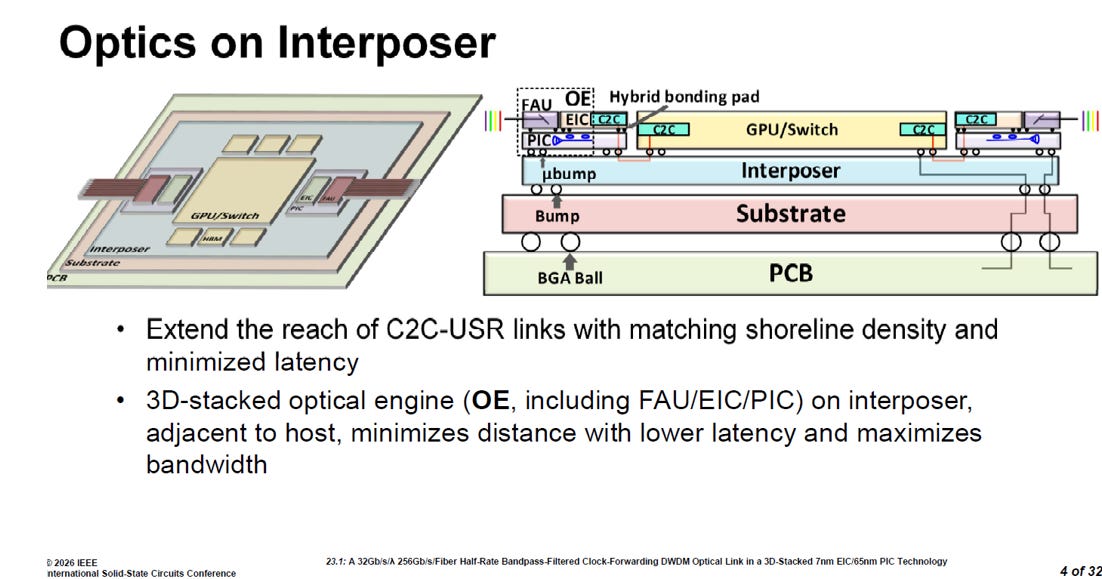
2.1. Optics on Interposer
NVIDIA 提出的「中介層上的光學互連 (Optics on Interposer)」架構,展示了 XPU Scale-up 網路的終極型態。該設計將 3D 堆疊的光學引擎 (OE) 直接與 GPU/Switch 相鄰封裝於同一個中介層上,藉由極致縮短物理距離來達成最低延遲與最大頻寬。
source: ISSCC26 23.1
系統級互連:走向公釐級 (mm) 的 SerDes-lite 架構
OIF C2C-USR 鏈路:在中介層極短的走線距離下,GPU 與光引擎之間捨棄了傳統耗電的長距 SerDes,改為採用 C2C (Chip-to-Chip) 的 USR (Ultra Short Reach) 介面。
卸除沉重 DSP:這種被稱為「SerDes-lite」的輕量化介面,,大幅省去了複雜的數位訊號處理 (DSP) 電路,將驅動功耗極致壓縮。
匹配海岸線密度:此設計能夠完美匹配 GPU 邊緣的 I/O 海岸線密度 (shoreline density),在有限的晶片邊緣空間內榨出最大的資料吞吐量。
晶粒級封裝:7nm EIC 堆疊 65nm PIC 的異質 3D 整合
微米級 (μm) 光電堆疊:光引擎 (OE) 內部採用了 EIC over PIC 的 3D 結構,包含了 FAU、EIC 與 PIC。EIC 與 PIC 之間透過混合鍵合墊 (Hybrid bonding pad) 直接垂直相連,達成微米級的無縫整合。
完美發揮製程紅利:採用了「3D-Stacked 7nm EIC / 65nm PIC」技術。這項精準的切割,讓需要極高運算密度的電子電路享受 7nm 先進製程的效能;同時利用 65nm 成熟製程的 PIC 作為強韌且廉價的基底,不僅降低了整體面積成本,也讓穿透底層的 TSV (矽穿孔) 製造變得更加容易且安全。
2.2. Slow&Wide with FC(Forwarding Clock)
如何將「慢而寬 (Slow and Wide)」策略與「時脈轉發 (Forwarded Clock, FC)」架構結合,打造出真正極低功耗的 SerDes-lite 接收端 (RX)。
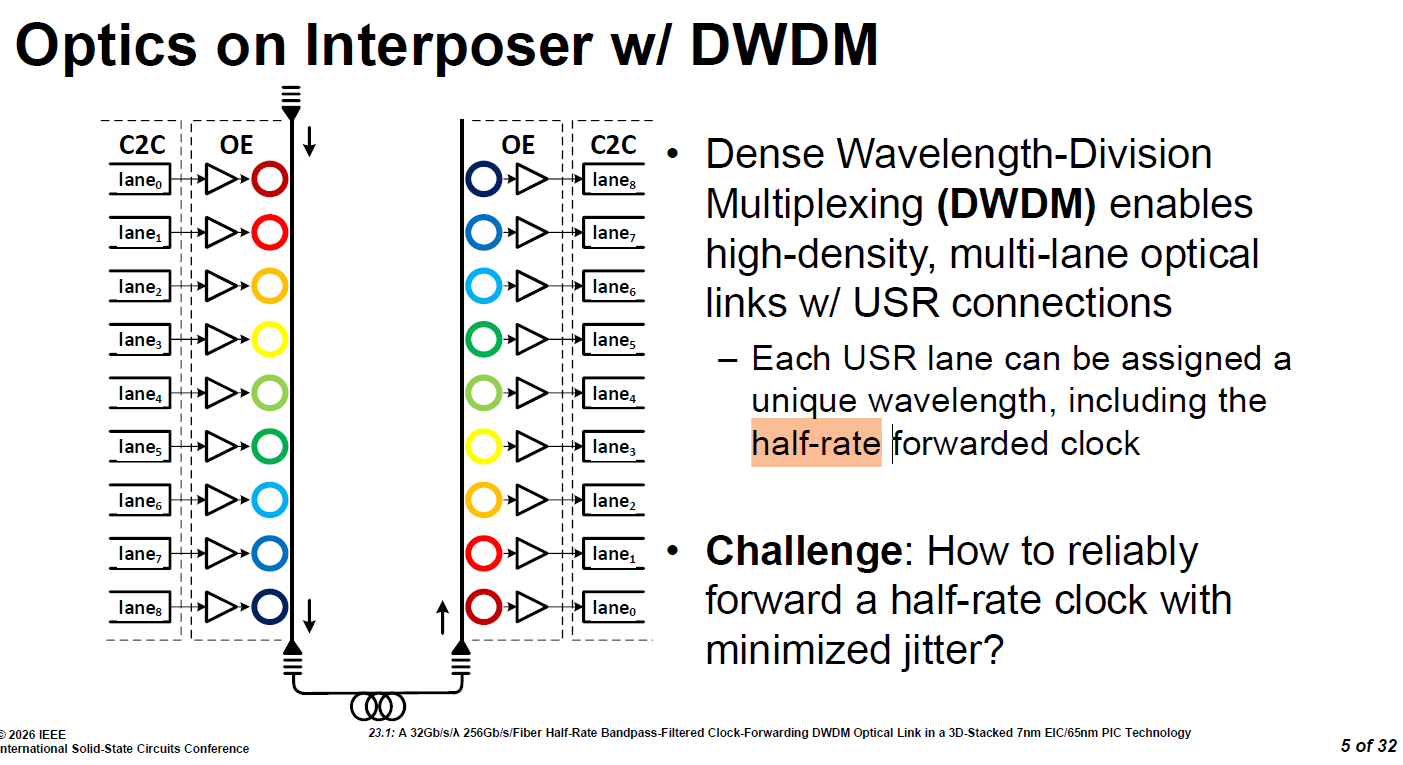
source: ISSCC26 23.1
極簡化的接收端設計 (Simplify RX design):
傳統接收端最耗電的元件是時脈與資料恢復電路 (CDR)。改用時脈轉發(FC)架構,直接將時脈訊號與資料平行傳送,讓接收端只需對齊現成時脈,免除複雜的時脈抽取運算,大幅降低功耗與延遲。
專屬時脈通道的 DWDM 實踐:
在多波長分波多工 (DWDM) 架構中,系統將資料分派給多個波長(32Gbps/λ),並特別獨立出一個專屬波長(例如 圖中
lane_8)來傳輸「半速率轉發時脈 (half-rate Forwarded Clock(FC)), 16Ghz」。
這是一套以「Slow&Wide with FC」換取「降低電路複雜度」的策略。透過轉發時脈,NVIDIA 成功將光學 I/O 的接收端精簡為 SerDes-lite 形態,這對於能效目標低於 5 pJ/bit 的 AI 規模化(Scale-up)網路至關重要。
矽基微環調變器(MRM)
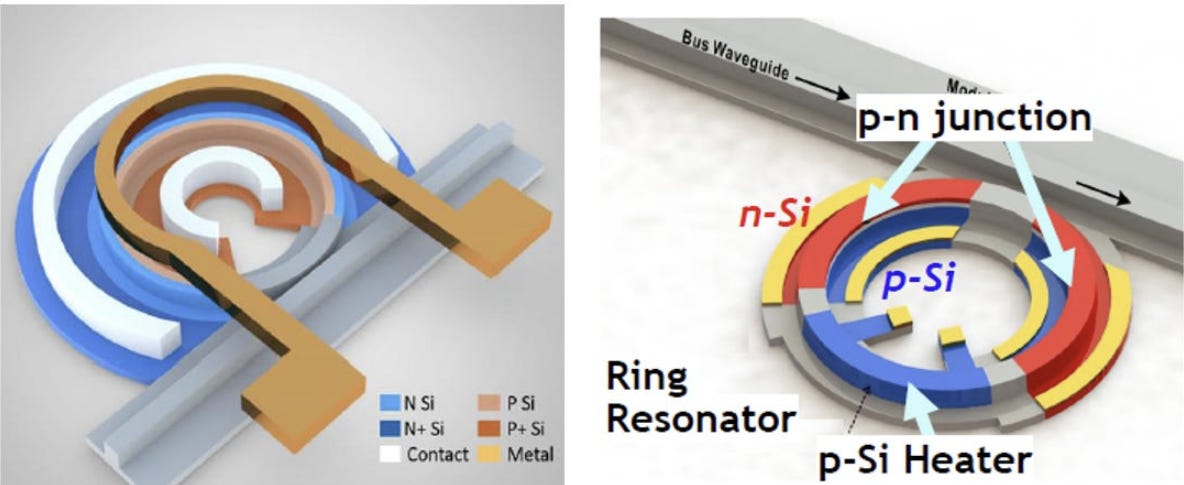
source: Intel
實現「DWDM」與「慢而寬」架構的核心光學元件:
優點:極致能效與高密度
超小尺寸 (μm 級):相較於長達公釐級的傳統 MZM 調變器,MRM 的直徑僅約數微米,能大幅提升晶片邊緣(Shoreline)的 I/O 密度。
極低功耗:屬於共振型元件,僅需極小電壓擺幅即可驅動,是達成低於 5 pJ/bit 能效目標的關鍵。
天然支援 DWDM:具備波長選擇性,多個微環串聯在同一條波導上即可實現多波長並行傳輸,無需額外的多工器空間
缺點:環境敏感與製程挑戰
極度熱敏感:共振波長會隨溫度劇烈飄移,必須配置複雜的熱調諧(Thermal Tuning)電路來維持穩定。
製程容差極小:對物理尺寸極度敏感,幾奈米的加工誤差就會導致波長偏移,對台積電等代工廠的製程均勻性要求極高。
頻寬限制:由於是共振結構,較適合「慢而寬」的 32G/64G 速率,在單通道 200G 以上的高速調變下線性度控制較難。
MRM 是為了 OIO (光學 I/O) 量身打造的技術,它以犧牲熱穩定性為代價,換取了 AI 晶片最需要的「超小面積」與「超低功耗」。
2.3. FC(Forwarding Clock) issues
2.3.1. Jitter
比較三種不同時脈架構在抖動(Jitter)處理上的優劣。說明為何 NVIDIA在 OIO 架構中選擇「帶通濾波時脈轉發(FC w/ BPF)」架構:
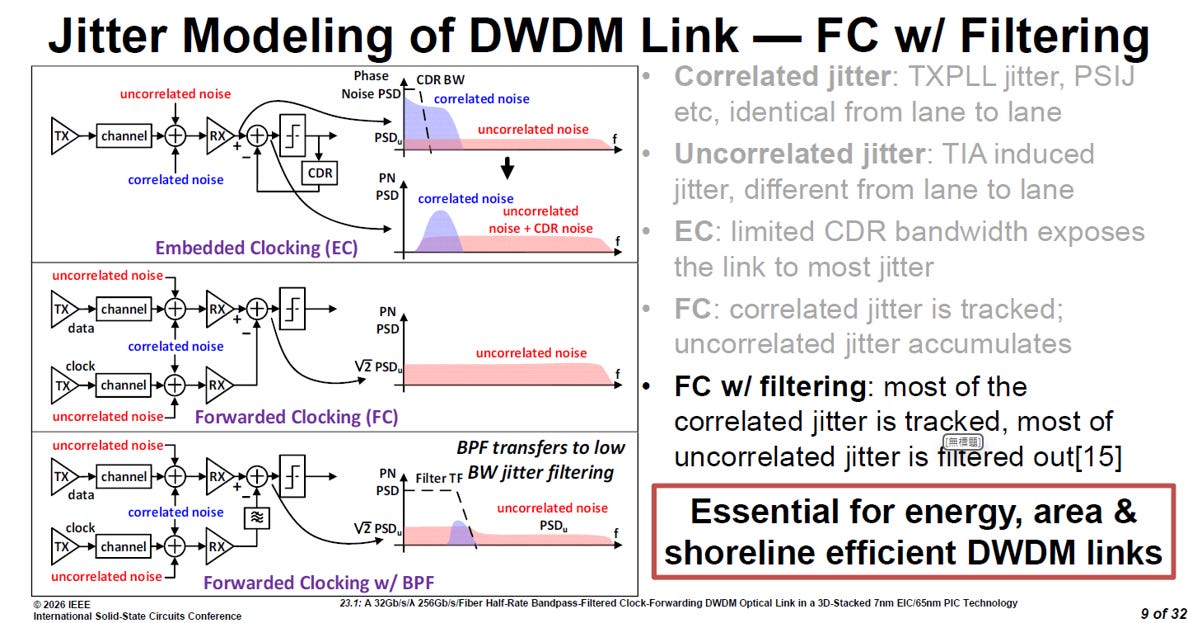
source: ISSCC26 23.1
內嵌時脈 (Embedded Clocking, EC)
這是傳統長距傳輸最常用的方式,將時脈訊號隱藏在資料流中
抖動問題:由於受限於時脈資料恢復電路(CDR)的頻寬(BW),鏈路會暴露在大部分的抖動中。
雜訊表現:從圖中的相位雜訊功率譜密度(PN PSD)可以看出,大部分的相關雜訊(correlated noise)與不相關雜訊(uncorrelated noise)都會疊加,並產生額外的 CDR 雜訊。這導致接收端需要更複雜、耗電的電路來還原訊號。
時脈轉發 (Forwarded Clocking, FC)
直接將時脈作為一個獨立通道與資料平行發送
優勢:相關抖動(correlated jitter,如 TX PLL 抖動)會被追蹤(tracked)並在接收端相互抵消。
致命傷:雖然相關雜訊抵消了,但不相關抖動(uncorrelated jitter,如 TIA 感應抖動)會不斷累積。這導致高頻的不相關雜訊(圖中紅色陰影區域)依然存在,影響資料採樣的精準度。
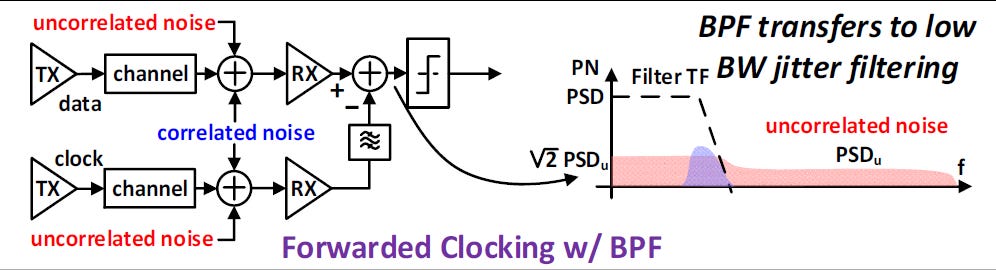
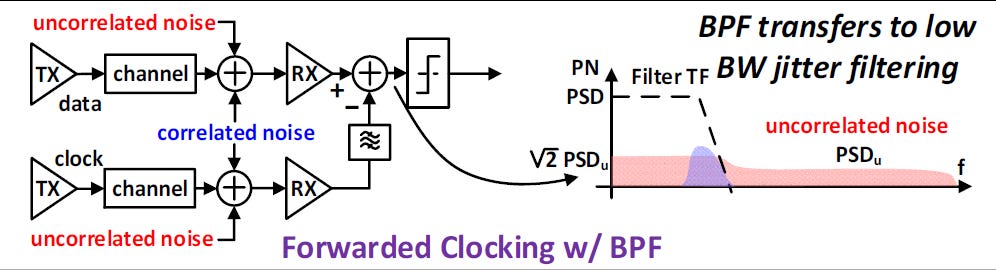
帶通濾波時脈轉發 (FC w/ Bandpass Filtering, BPF)
這是 NVIDIA 為了達成超低功耗與高能效 DWDM 鏈路所採用的核心技術
運作機制:在時脈接收路徑上增加一個帶通濾波器(BPF)。
抖動處理效果:
相關抖動(Correlated Jitter):依然維持 FC 的優點,大部分會被追蹤並抵消。
不相關抖動(Uncorrelated Jitter):因為純 FC 架構會讓不相關抖動 (Uncor不斷累積。利用BPF 透過低頻寬的抖動濾波特性,能將絕大部分的不相關抖動濾除。
最終表現:從圖中可見,PN PSD 僅剩下一小部分的相關雜訊,不相關雜訊幾乎被清空
總結:
FC w/ filtering 是實現「能源、面積與海岸線效率(energy, area & shoreline efficient)」之 DWDM 鏈路的必要條件:
省去 CDR:節省大量電力與晶片面積。
降低延遲:無需複雜的數位補償邏輯。
支持 DWDM:讓「慢而寬」的策略在物理層面上變得可行且穩定。
2.3.2. 長距離傳輸
在長距離傳輸(大於 50 公尺的 Scale-out 跨區或電信網路)的嚴苛物理環境中,強調「輕量省電」的 FC 架構會全面潰敗,必須交由「重裝甲」的 EC 架構來硬扛。
對抗靜態偏移 (長距色散 Skew)
FC 的死穴:時脈與資料波長因光纖色散產生的速度差,在長距離下會被無限放大,時間差直接超出輕量級 PI (相位內插器) 的補償極限。
EC 的必勝解:時脈直接編碼隱藏在各自的資料流中,天然免疫不同波長間的色散差。

對抗動態偏移 (環境溫差 Skew)
FC 的死穴:長距離光纖跨越機房產生的溫差與應力,會讓相位發生隨機且劇烈的跳動。拔除 CDR 的 FC 無法即時追蹤,只能盲目抓錯資料。
EC 的必勝解:依靠耗電但無比強大的 CDR (時脈與資料恢復) 電路,動態且即時地鎖定資料相位,完美無視外在環境的干擾。
對抗雜訊累積 (不相關 Jitter)
FC 的死穴:長途衰減與光放大器引入的海量雜訊,早已超出 BPF (帶通濾波) 能清掃的極限,導致訊號眼圖完全閉合。
EC 的必勝解:搭配極高功耗的 DSP (數位訊號處理器),用複雜的數學等化演算法暴力重建訊號,把糊成一團的眼圖強行撐開以供判讀。
在長距離應用,EC 是用「極高的運算功耗 (CDR + DSP)」來解決上述問題;而 FC 為了追求極致省電和延遲,拔除了這些重裝備,因此只能應用在短距離(Inter-Rack Scale-up)的機櫃間互連。
3. Design details
3.1. Architecture
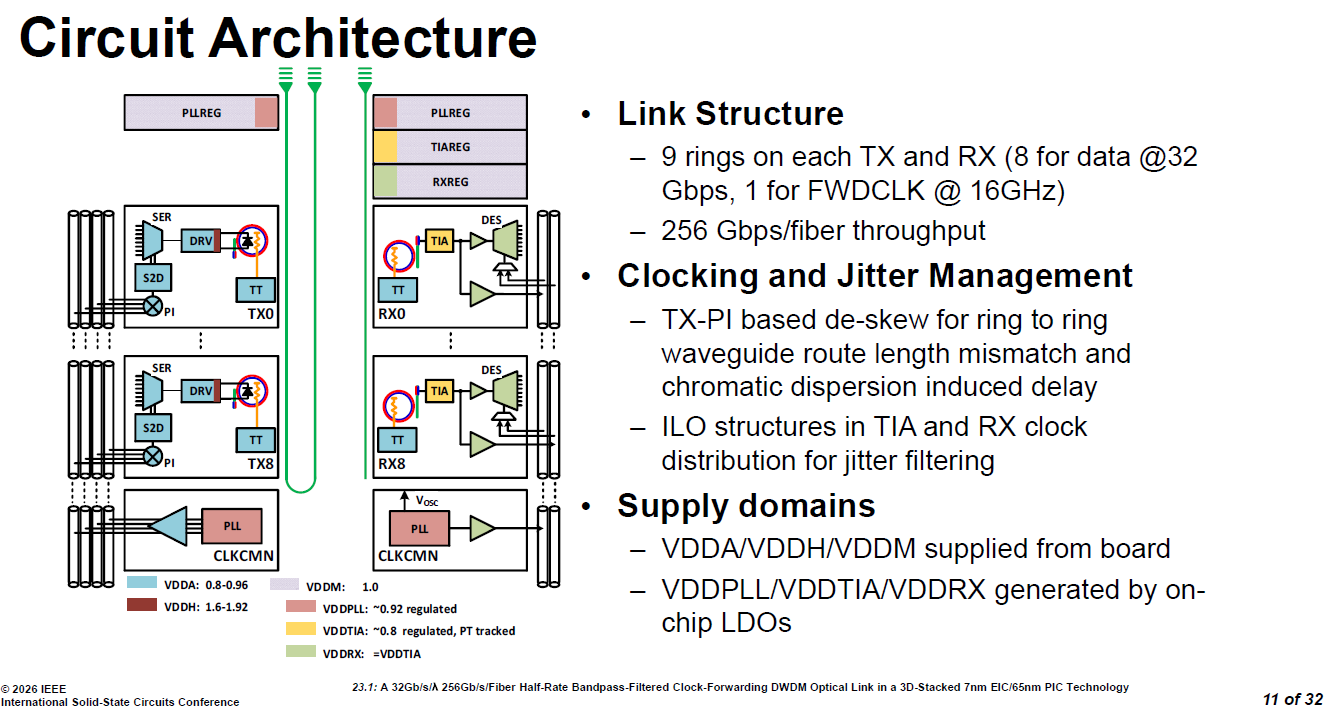
source: ISSCC26 23.1
鏈路結構 (Link Structure):實踐 DWDM 與轉發時脈
9 環陣列配置:在傳送端 (TX) 與接收端 (RX) 各配置了 9 個相同的微環電路。
資料與時脈分工:其中 8 個微環負責資料傳輸,每個通道運行在較低的 32 Gbps 速率;剩下的 1 個微環,則專屬用來傳輸 16GHz 的半速率轉發時脈 (FWDCLK)。
總頻寬:透過這種多波長平行設計,單根光纖即可達成 256 Gbps(=8x32Gbps) 的總吞吐量。
時脈與抖動管理: Skew and Jitter
TX-PI 預先補償 (對抗色散 Skew):選擇在傳送端 (TX) 的電路中加入 PI (相位內插器) 來進行去偏移 (de-skew)。它不僅用來對齊微環之間波導路徑長度不匹配的問題,更是用來預先抵消光纖中「色散 (chromatic dispersion)」所造成的延遲。利用輕量級的 PI 來解決同光纖內微小的靜態時間差。
ILO 結構濾波 (對抗 Jitter):先前提到的「帶通濾波器 (BPF)」,在電路層級上是透過在 TIA (轉阻放大器) 與 RX 時脈分佈電路中,建構 ILO (注入鎖定振盪器, Injection-Locked Oscillator) 來實現抖動濾波 (jitter filtering)。
供電域管理 (Supply domains):確保類比訊號乾淨
基礎電壓 (VDDA, VDDH, VDDM) 直接由外部電路板 (board) 供應
針對雜訊極度敏感的核心類比模組,包含鎖相迴路 (VDDPLL)、轉阻放大器 (VDDTIA) 與接收器 (VDDRX),則由晶片內建的 LDO (低壓差線性穩壓器) 獨立生成乾淨的電源
這個電路架構圖說明,如何利用 TX 端的相位內插器 (PI) 與 RX 端的注入鎖定振盪器 (ILO),解決了 DWDM 光學鏈路中的色散與雜訊,將先前推演的理論完美落地。
3.2. TX circuit
整個 TX 設計的核心目標,就是以極低的功耗,提供足夠且乾淨的電壓來驅動極度敏感的微環調變器 (MRM)。
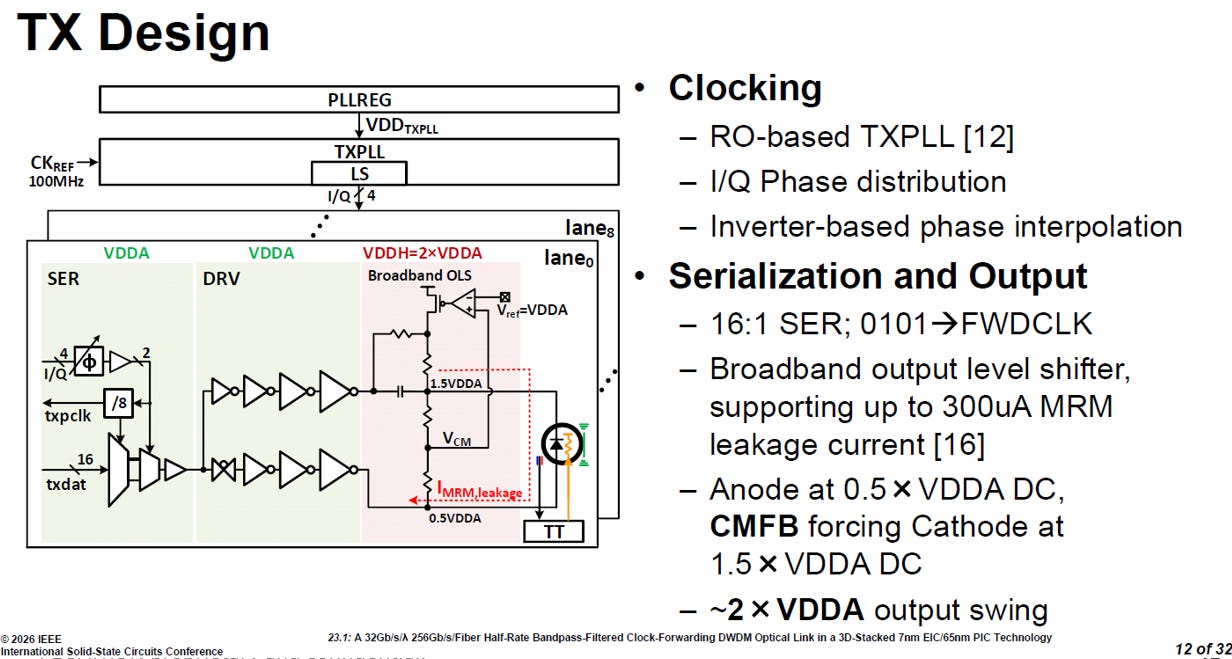
source: ISSCC26 23.1
TX 基礎架構:時脈與序列化
精準時脈控制:採用基於環形振盪器 (RO-based) 的 TX 鎖相迴路 (PLL),並搭配基於反相器 (Inverter-based) 的相位內插器 (PI) 來進行相位微調與去偏移 (de-skew)。
資料與時脈生成:序列化器 (Serializer) 採用 16:1 的架構,不僅負責將平行資料轉為串列,更直接將 0101 的規律訊號轉換為系統所需的轉發時脈 (FWDCLK)。
核心驅動引擎:寬頻 OLS (Output Level Shifter)
矽基微環調變器 (MRM) 需要較大的電壓擺幅,才能穩定改變光訊號狀態。為了在低電壓的 CMOS 製程中榨出高電壓,NVIDIA 設計了這款獨特的 OLS:
電壓倍增魔法:透過共模回授 (CMFB) 技術,系統將 MRM 的陽極設定在 0.5 倍的 VDDA 直流電壓,同時強制將陰極推升至 1.5 倍的 VDDA。這一拉一推,成功為 MRM 創造出將近 2 倍 VDDA 的極大輸出電壓擺幅,完美解決了低電壓 CMOS 製程難以驅動光學元件的痛點
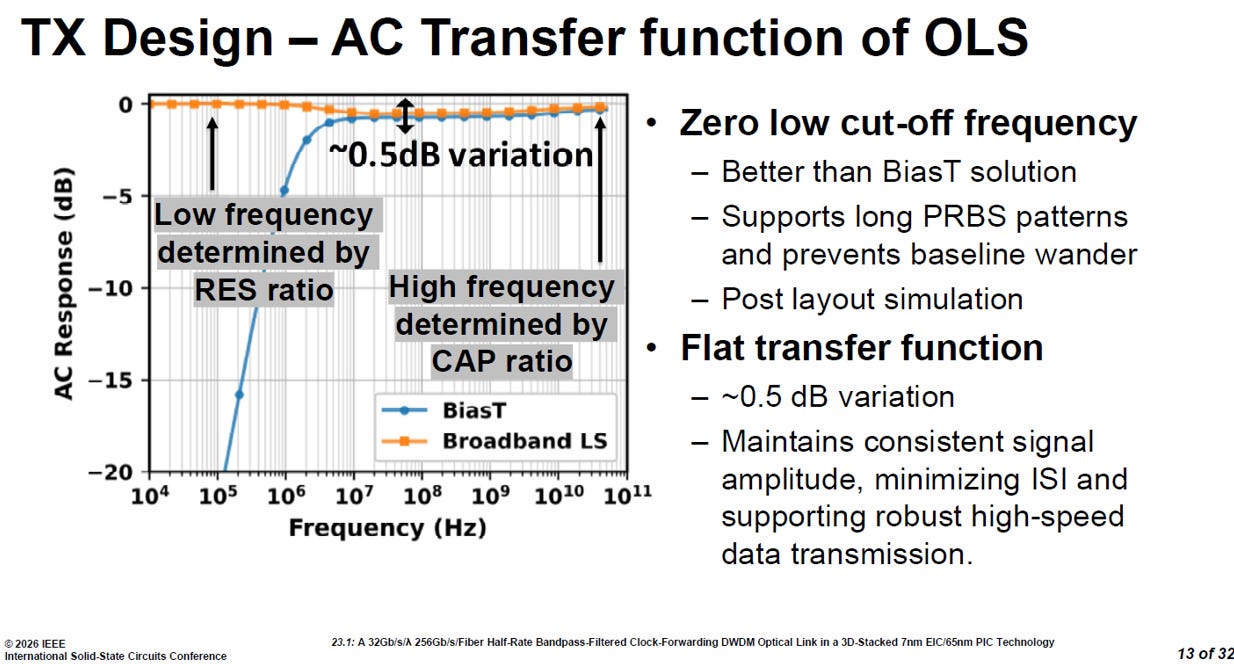
source: ISSCC26 23.1
OLS 的 AC 轉移函數優勢
從轉移函數比較圖 可以看出,這款寬頻 OLS (橘線) 相比於傳統的 BiasT 電路 (藍線),具備兩大決定性的訊號品質優勢:
零低頻截止點 (Zero low cut-off frequency):
傳統 BiasT 電路在低頻區域會出現嚴重的訊號衰減。
寬頻 OLS 的頻率響應則能一路平坦延伸至極低頻 (其低頻響應由電阻 (RES) 比例決定,高頻由電容 (CAP) 比例決定)。
這項特性完美防止了長串連續 0 或連續 1 造成的「基線飄移 (baseline wander)」,使其能完美支援極長的 PRBS 測試圖形。
極致平坦的轉移函數 (Flat transfer function):
在整個廣闊的工作頻段內,訊號變異被嚴格控制在僅約 0.5 dB 左右。
這種極致的平坦度確保了訊號振幅的高度一致性,從而大幅最小化了符元間干擾 (ISI),是維持高速資料穩健傳輸的絕對關鍵。
寬頻OLS 利用巧妙的電壓分配與極度平坦的頻率響應,完美解決了驅動矽基微環調變器(MRM)時最怕的「電壓擺幅不足」與「低頻訊號失真」兩大痛點。
3.3. RX Circuit
3.3.1. 電源設計
接收端的 TIA (轉阻放大器) 需要將極度微弱的光電流轉換為電壓,這是一個對雜訊極度敏感的元件。
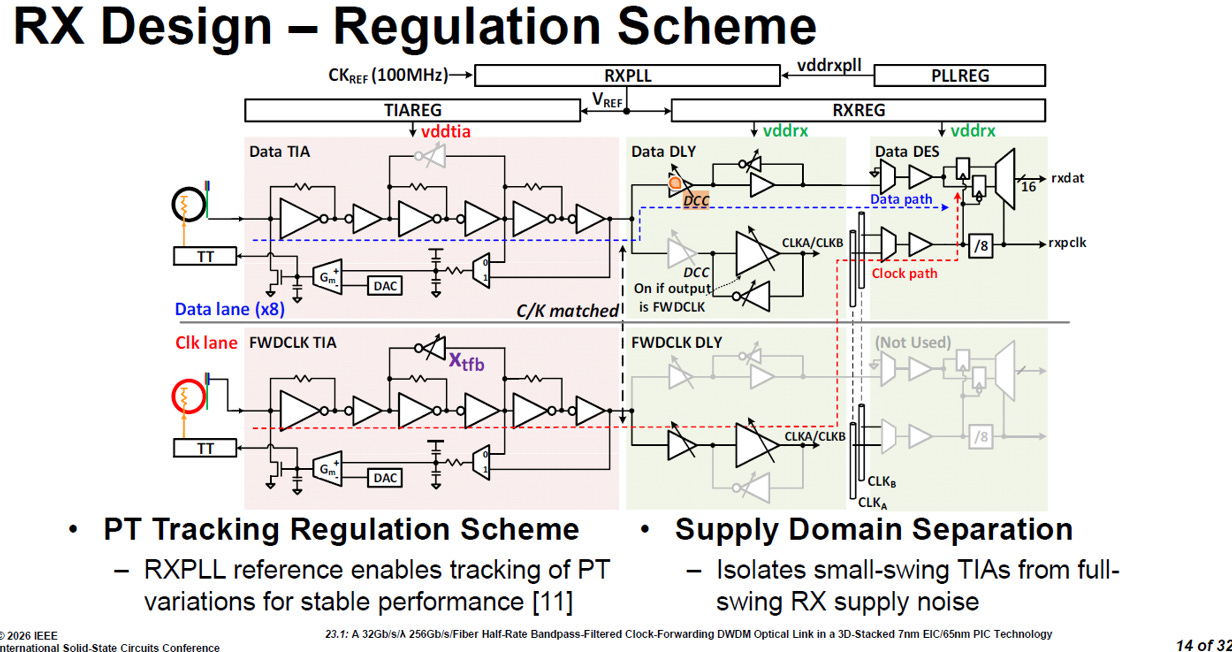
source: ISSCC26 23.1
PT 追蹤穩壓機制 (PT Tracking Regulation Scheme)
抗環境干擾:這裡的 “PT” 指的是製程 (Process) 與溫度 (Temperature)。光學晶片在運作時會面臨劇烈的熱波動與先天的製程微小差異。
動態補償:系統巧妙地利用 RXPLL (接收端鎖相迴路) 提供的參考電壓,讓 TIA 的穩壓器 (TIAREG) 能夠動態追蹤並補償這些 PT 變異。這確保了 TIA 在各種極端環境下,依然能維持非常穩定的放大效能。
供電域實體隔離 (Supply Domain Separation)
阻絕自家雜訊:在晶片內部,後段的解序列器 (DES) 等數位電路在高速運作時,會產生劇烈的「全擺幅 (full-swing)」電源雜訊。如果電源連在一起,這些雜訊會瞬間淹沒 TIA 正在處理的微弱訊號。
分區供電:從圖中可以清楚看到,最前端敏感的 TIA 區塊是由
TIAREG提供專屬的vddtia電源;而後段的數位電路則是由RXREG提供vddrx電源。這種實體層級的電源隔離,完美阻止了後端數位雜訊倒灌回前端類比電路。
3.3.2. TIA (轉阻放大器,Transimpedance Amplifier)
TIA 的工作就是將光電二極體 (PD) 接收的微弱光電流,精準且快速地轉換為後端電路能判讀的電壓訊號:
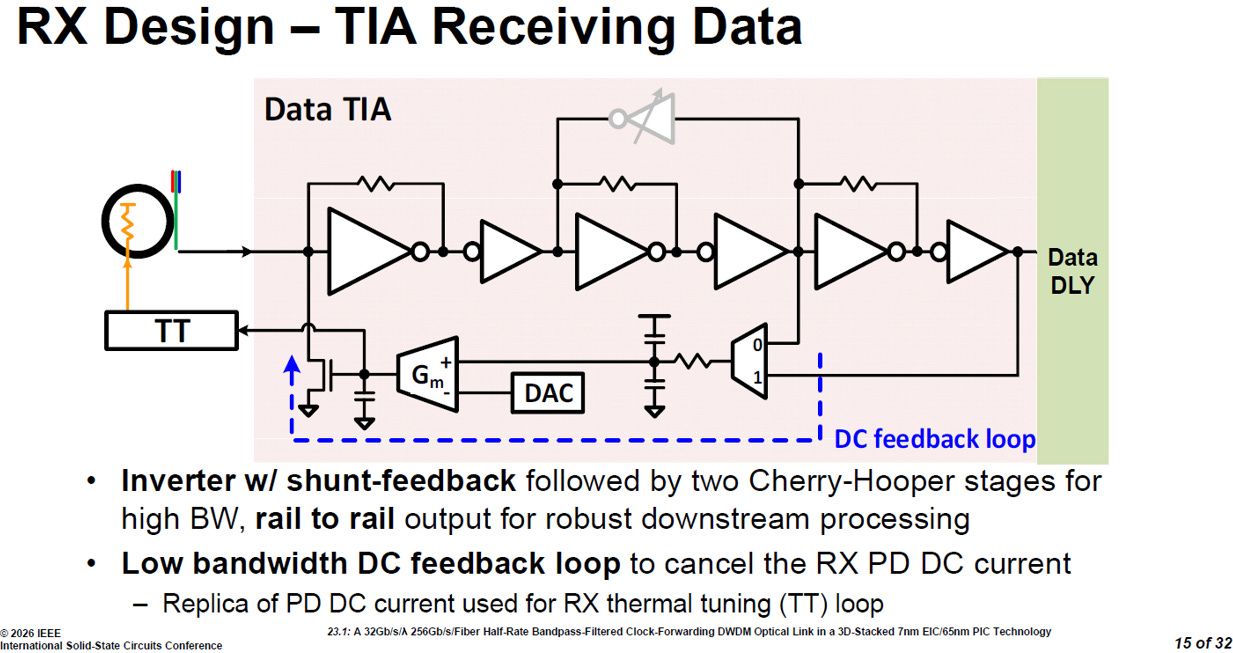
source: ISSCC26 23.1
主放大路徑:追求高頻寬與軌對軌輸出
核心架構:輸入端採用了「附帶並聯回授的反相器 (Inverter w/ shunt-feedback)」。
Cherry-Hooper 放大級:緊接著反相器之後,串聯了兩級的 Cherry-Hooper 放大電路。這是一種在寬頻放大器設計中非常經典的架構。
設計目的:這種組合是為了極高的頻寬 (high BW),並將原本微弱的訊號一路放大到能觸及電源上下限的「軌對軌 (rail to rail)」電壓輸出。這確保了交給後端數位電路處理的訊號具有極強的抗干擾能力與強健性 (robust downstream processing)。
直流回授迴路 (DC feedback loop):
在圖表的下方,有一條虛線標示的低頻寬直流回授路徑。這條迴路不處理高速資料,而是專門用來處理直流 (DC) 偏壓:
抵消直流電流:它的首要任務,是抵消掉接收端光電二極體 (RX PD) 運作時持續產生的直流電流 (DC current),避免這些無用的直流分量讓後端的放大器發生飽和現象。
連動熱調諧 (TT) 系統:這個回授迴路在抵消電流的同時,會精準複製出一份 PD 直流電流的複本 (Replica of PD DC current)。這個複本訊號會被直接傳送給左側的熱調諧迴路 (Thermal Tuning, TT)。TT能利用這個直流電流的大小,來間接感知微環的共振狀態,進而精準控制微環的溫度。
3.3.3. ILO(Injection Locking Oscillator)
不需要外加一個龐大耗電的帶通濾波器,而是直接在 TIA 內部加上一條回授(Xtfb),把放大器變成了 ILO。這讓接收端在訊號進門的第一關,就以極低的硬體代價把時脈雜訊給洗乾淨了,是達成超低延遲與低功耗的關鍵。
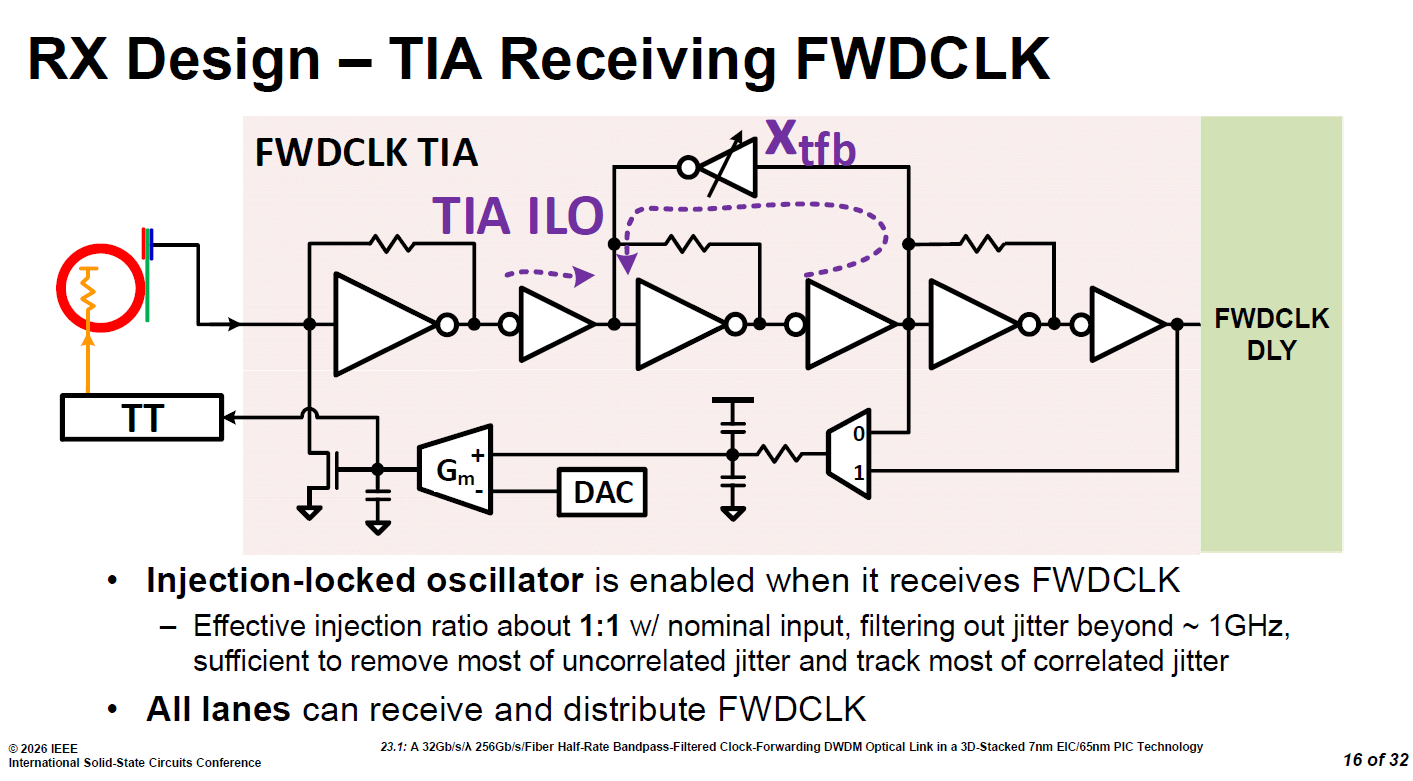
source: ISSCC26 23.1
O: Oscillator (振盪器) —— 核心引擎
三個反相器的迴路:從電路圖中紫色的
TIA ILO虛線路徑可以看到,利用了主路徑上的三個反相器 (inverters),並搭配上方一個帶有Xtfb標示可調變的反相器,建立正回授路徑,首尾相連形成了一個封閉迴路。Xtfb 的動態微調:系統能微調它的驅動強度來改變延遲時間,以克服晶片生產的製程變異或溫度變化,確保 ILO 始終能精準地在 16GHz 附近產生自然振盪。
I: Injection (注入) —— 外部帶有雜訊的時脈 (External Noisy FC)
引入 FWDCLK:這裡的 Injection,指的就是將光電轉換後、從外部傳進來的轉發時脈 (FWDCLK)「注入」到這個內部振盪器迴路中。
充滿雜訊的輸入:如同之前在 Jitter 模型探討過的,這個經歷了光學鏈路傳輸的外部 FC 訊號,雖然需要的基準頻率,但也夾帶了大量累積的「不相關抖動 (uncorrelated jitter)」雜訊。
L: Locking (鎖定) —— 濾波與淨化的魔法 (BPF 的真面目)
強制同步:當外部強勢且帶有雜訊的 FC 訊號注入後,內部的振盪器會被強制「鎖定 (Locked)」,跟著外部注入的主頻率一起震盪。
濾除高頻雜訊:ILO 在鎖定狀態下,天生具有一個針對相位雜訊的低通濾波特性。根據投影片說明,這個 ILO 濾除了大約 1GHz 以上的高頻抖動雜訊。
完美淨化:因為高頻的雜訊被擋在門外,它成功移除了絕大部分的「不相關抖動 (uncorrelated jitter)」,同時保留了主頻率與低頻的「相關抖動 (correlated jitter)」以供後續追蹤抵消。這完美實現了先前看到的乾淨相位雜訊頻譜。
source: ISSCC26 23.1
3.3.4. 延遲 (DLY) 設計
利用傳送端 (TX) 的相位內插器 (PI) 來預先補償光纖「外部」的色散 Skew。而這RX DLY Stage 則是為了搞定晶片「內部」電路走線與緩衝器所產生的時間差。
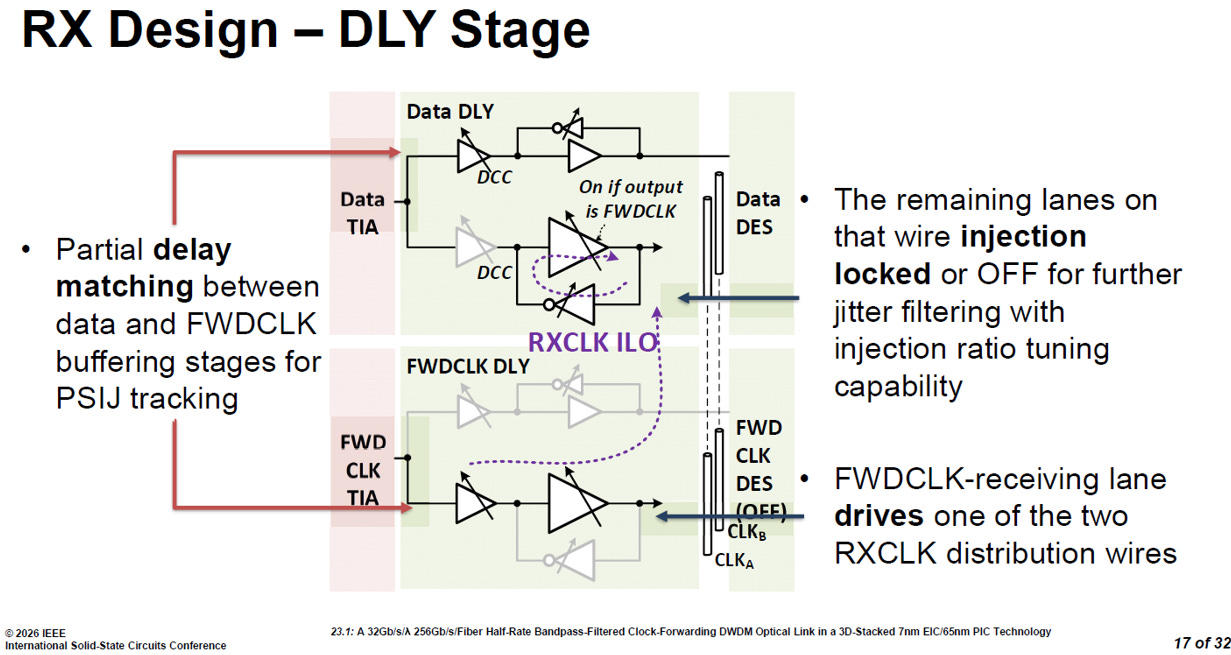
source: ISSCC26 23.1
內部精準 De-skew (抗電源雜訊):
透過在資料 (Data) 與轉發時脈 (FWDCLK) 的緩衝器之間進行「局部延遲匹配 (Partial delay matching)」,確保兩條路徑的內部延遲完全一致。這能讓時脈與資料完美踩在同一個電源波動上,進而有效追蹤並抵消「電源感應抖動 (PSIJ)」。
第二道 Jitter 濾波防線 (RXCLK ILO):
除了 TIA 內部的第一層濾波,系統在資料通道的延遲階段又佈署了「注入鎖定 (injection locked)」機制。它具備「注入比例微調 (injection ratio tuning)」能力,
乾淨的時脈分配網路:
專責接收 FWDCLK 的通道在把時脈洗乾淨後,會負責驅動兩條 RXCLK 分配線 (distribution wires) 的其中一條,將穩定的時脈訊號分發給全體資料通道使用。
如果在 TX 端對抗光纖色散是「宏觀的 De-skew」,那麼 RX DLY 階段的延遲匹配就是「微觀的 De-skew」。它補齊了晶片內部走線造成的時差,並用第二層 ILO 把抖動壓制到最低,確保最後交給數位電路的訊號絕對純淨。
3.3.5. Clock Distribution
接收端 (RX) 晶片內部極具彈性且低雜訊的時脈分配網路 (CLK Distribution):
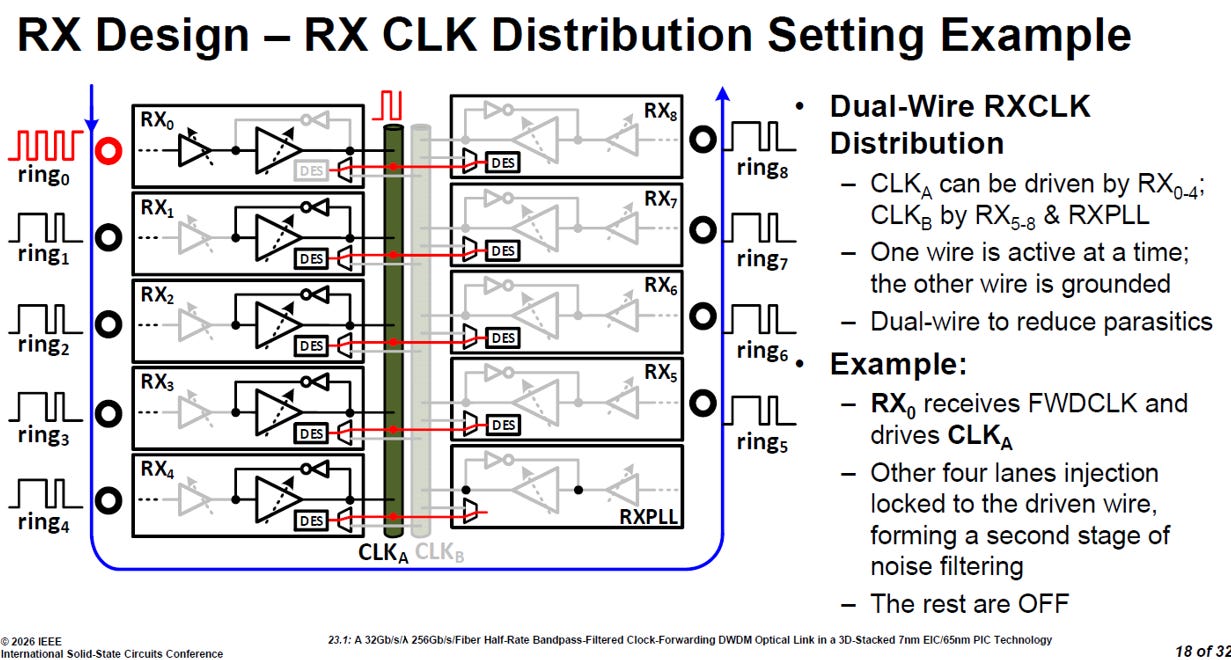
source: ISSCC26 23.1
雙線降低寄生功耗 (Dual-Wire 架構):系統配置了 CLKA 與 CLKB 兩條時脈幹線,但在同一時間「只有一條會啟動,另一條則直接接地」。這種單線輪替的設計大幅減少了晶片內長走線帶來的寄生電容效應,有效降低了驅動器的功耗負擔。
打破固定的極高彈性:時脈接收不再綁死於特定通道。任何一個通道(如圖中範例的 RX0)都能負責接收外部的光學轉發時脈 (FWDCLK),並在內部洗乾淨後化身為驅動器,將時脈訊號灌入啟動的幹線中。這為系統提供了極強的容錯與動態配置能力。
全局網狀的第二級濾波:當主通道(如 RX0)驅動幹線時,掛在同一條幹線上的其他通道(如 RX1 到 RX4)會對這條線進行「注入鎖定 (injection locked)」。這等於讓所有資料通道共同參與了時脈淨化,形成堅不可摧的「第二級雜訊濾波 (second stage of noise filtering)」防護網。
3.3.6. DES(解序列器)
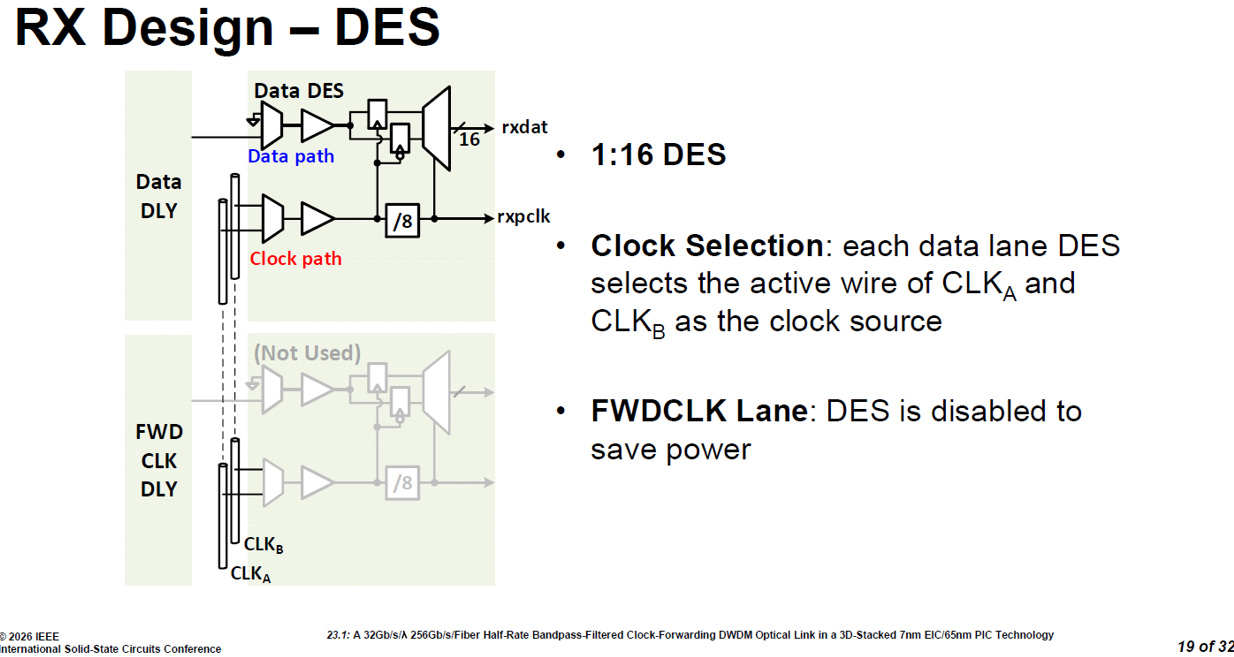
source: ISSCC26 23.1
1:16 降速展開 (1:16 DES):資料通道 (Data path) 的 DES 負責將前端傳來的高速串列訊號,轉換並平行展開成 16 條資料線 (rxdat),以符合後端 GPU 或交換機晶片能消化的數位處理格式。
靈活的時脈選擇 (Clock Selection):在解碼過程中,每個資料通道的 DES 都可以自由從兩條時脈幹線 (CLKA 與 CLKB) 中,精準選擇「當下處於啟動狀態 (active wire)」的那一條作為自己的時脈來源。
精準的關閉省電 (FWDCLK Lane Disabled):對於那個被指派去專門接收轉發時脈 (FWDCLK) 的通道,因為它本質上沒有資料需要解碼,系統會直接將其 DES 區塊徹底停用 (圖中標示為 Not Used)。這項直接了當的設計能為晶片省下可觀的功耗 (save power)。
3.4. Thermal Tuning Circuit
光學微環 (Micro-ring) 系統中不可或缺的**「熱調諧迴路 (Thermal Tuning Loop)」**設計。微環對溫度極度敏感,必須依靠這套精密的閉環控制系統來穩定波長。
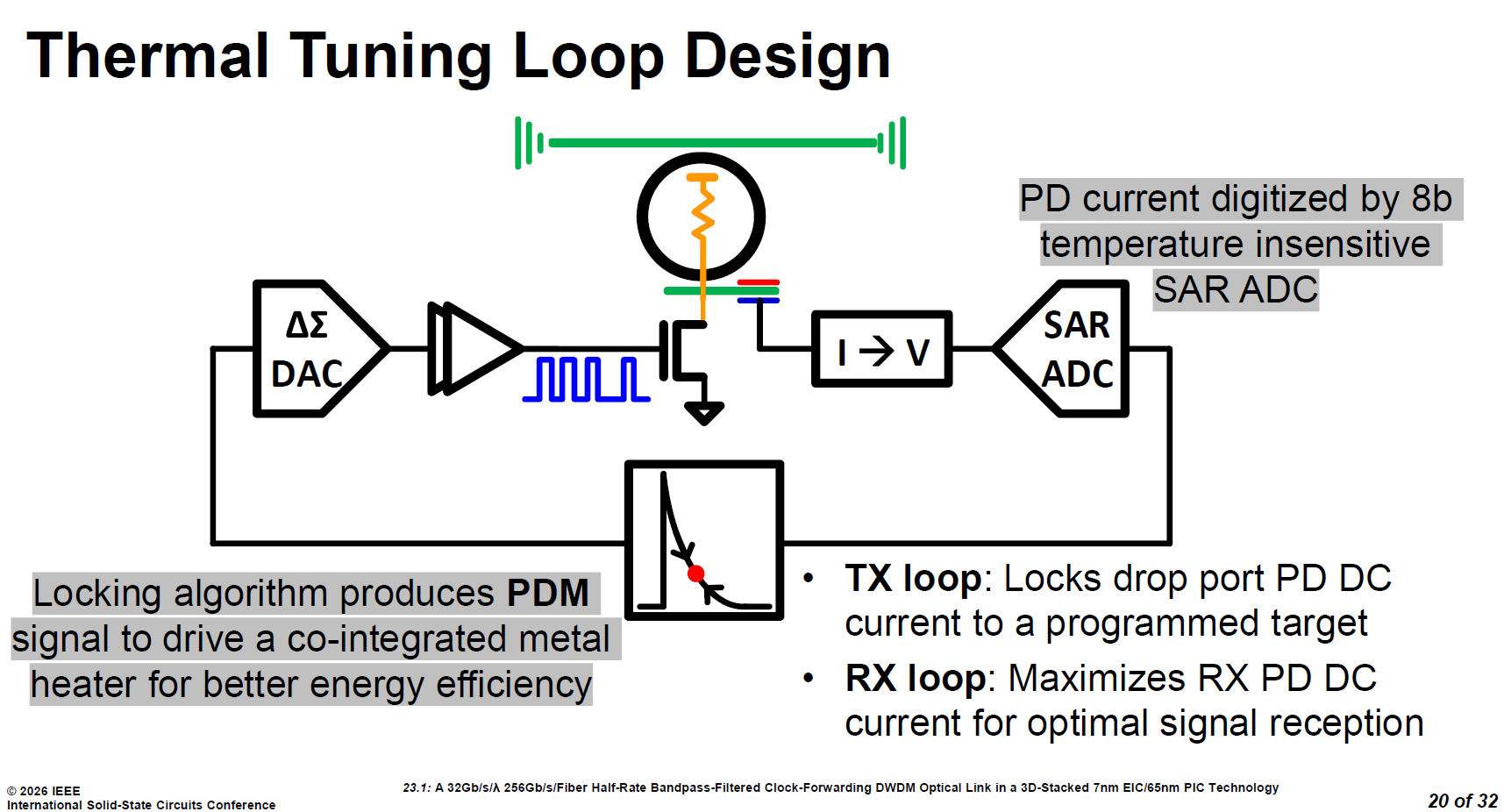
source: ISSCC26 23.1
精準且抗溫的感測 (SAR ADC):
利用「對溫度不敏感」的 8-bit SAR ADC,將光電二極體 (PD) 的直流電流精準轉換為數位訊號,確保感測源頭不會因為晶片發熱而失準。
高能效加熱控制 (PDM 驅動):
鎖定演算法計算出偏差後,會輸出 PDM (脈衝密度調變) 訊號來驅動微環旁的金屬加熱器。這種控制方式能大幅提升熱調諧的整體能源效率。
TX/RX 差異化策略:
雖然硬體架構相同,但在傳送端 (TX) 的任務是將電流「精準鎖定在預設目標值」以穩定雷射波長;而在接收端 (RX) 則是「最大化收訊電流」,以確保微環處於最佳共振接收狀態。
4. Results
4.1. Die Photos
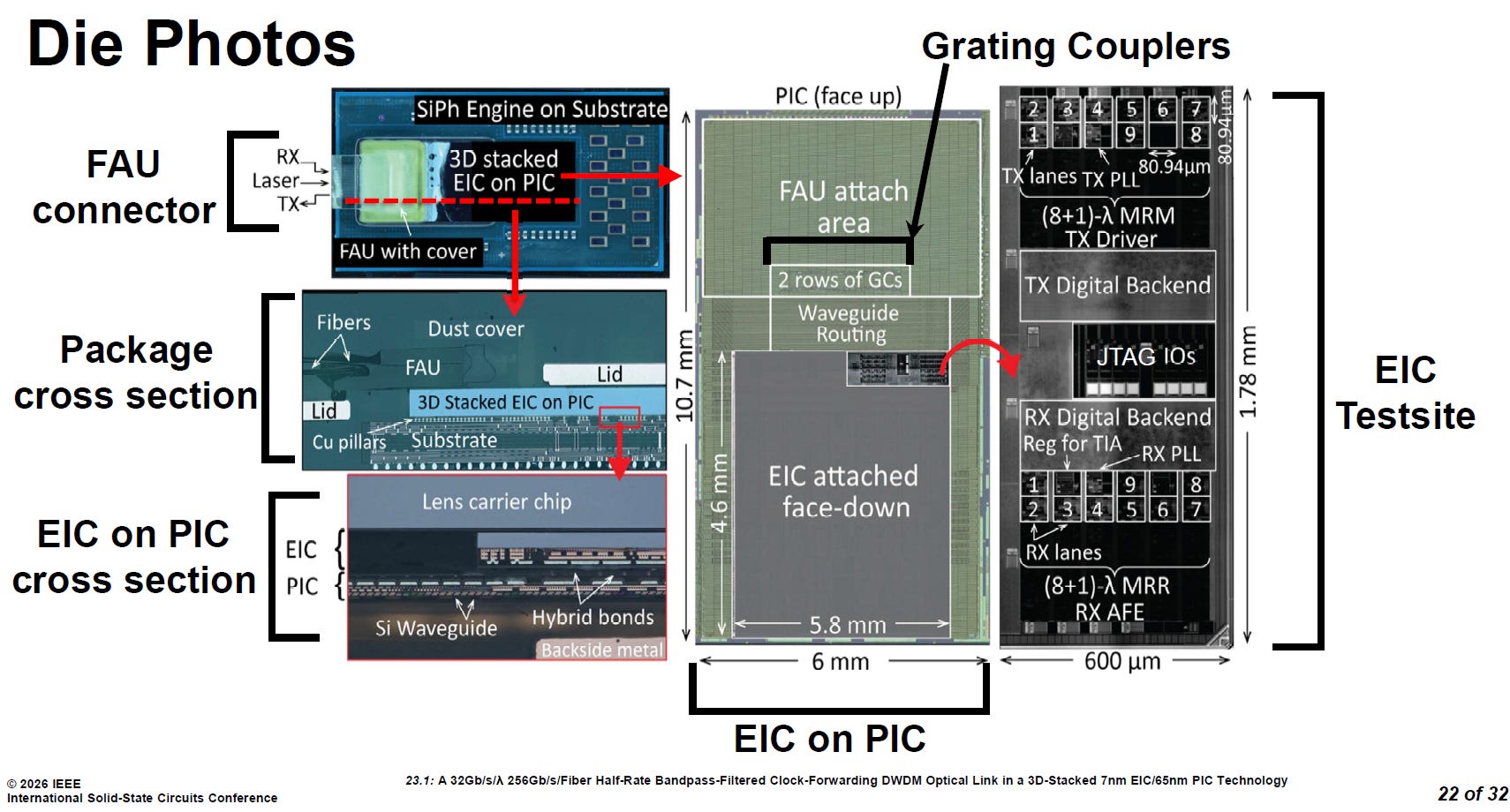
source: ISSCC26 23.1
3D 混合鍵合 (EIC over PIC):
從左下角的剖面圖可以看出,這套系統採用了 EIC 面朝下 (face-down) 直接覆蓋疊加在 PIC 面朝上 (face up) 的架構。兩者之間透過超高密度的「混合鍵合 (Hybrid bonds)」技術連接。這種設計將電子驅動器與光學微環之間的實體走線縮短到微米等級,是達成極低寄生電容與超低功耗的物理基礎。
高密度光纖介面 (FAU 與 GCs):
在中間的 PIC 俯視圖中,上方保留了大面積的光纖陣列單元連接區 (FAU attach area)。外部的光纖透過這個 FAU,對準下方的兩排光柵耦合器 (Grating Couplers, GCs),將光訊號(包含外部引入的雷射光源與收發資料)垂直耦合進出光子晶片。
9 通道對稱式 EIC 佈局:
最右側的 EIC 測試晶片 (EIC Testsite) 佈局圖,呼應了前面探討的電路架構。TX 傳送端(上半部)與 RX 接收端(下半部)呈現對稱設計,且各自都明確標示了 1 到 9 號通道(代表 8 條資料 + 1 條時脈)。這些包含 PLL、TX Driver、RX AFE 在內的複雜類比電路,被極度微縮在僅 1.78mm x 600µm 的超小面積內。
透過高密度的「EIC over PIC」3D 混合鍵合封裝技術,NVIDIA 成功將複雜的 9 波長 DWDM 驅動電路與矽光子微環完美濃縮,打造出這顆極致輕巧且具備極短實體走線的 OIO 光學引擎。
4.2. Performance 亮點
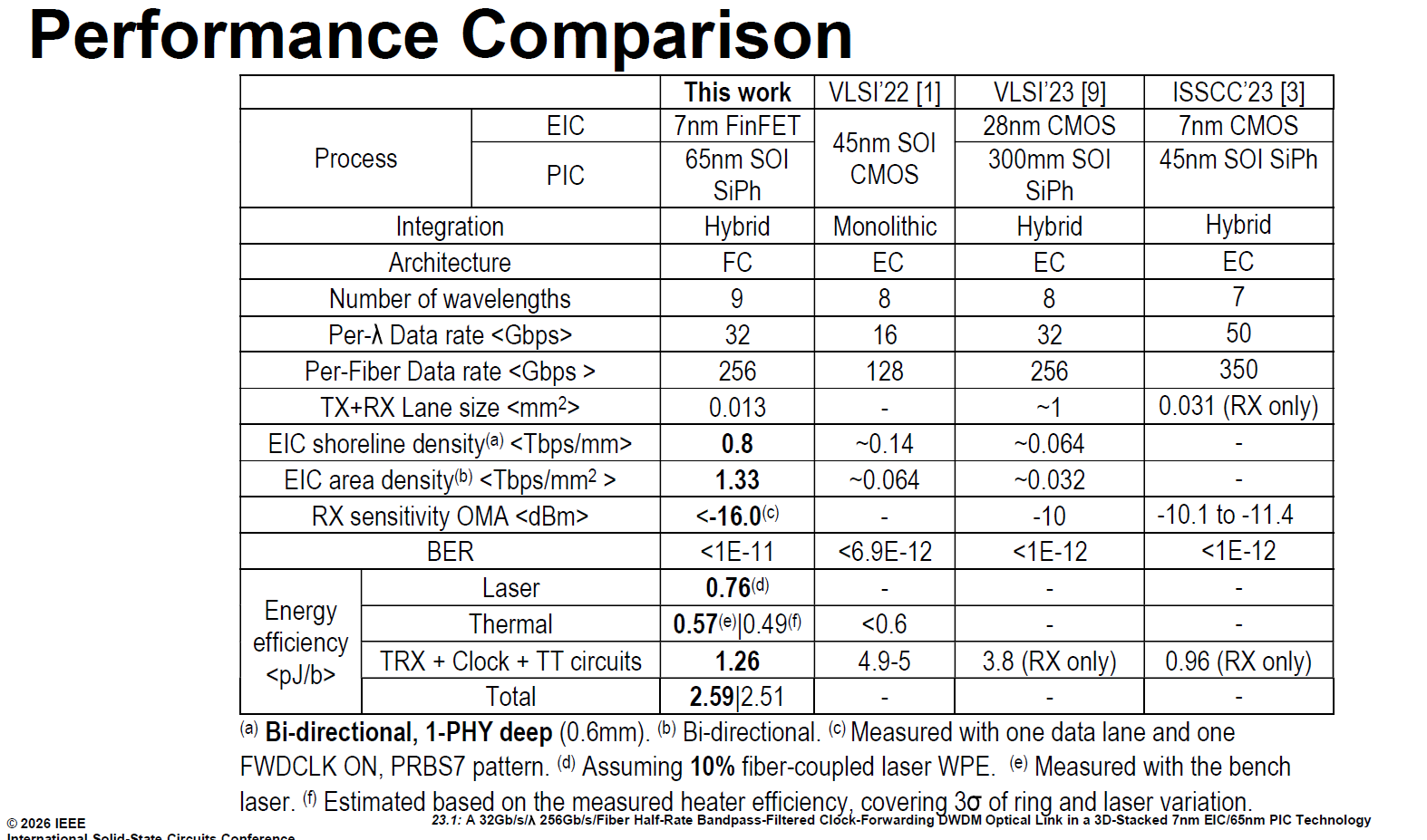
source: ISSCC26 23.1
亮點一:FC 架構的能效大勝利(總功耗僅 2.59 pJ/b)
這是整張表最具破壞力的數據。對比 2022/2023 年採用 EC (內嵌時脈) 架構的前代作品(光是 TRX 收發電路就高達 4.9 pJ/b),NVIDIA 捨棄 CDR 改用 FC (時脈轉發) 架構後,將收發器、時脈與熱調諧電路 (TRX + Clock + TT circuits) 的功耗硬生生壓到了僅 1.26 pJ/b。
即使加上外部雷射 (Laser, 0.76 pJ/b) 與微環熱控制 (Thermal, 0.57 pJ/b),整體總功耗也僅有 2.59 pJ/b。這完美達成了 AI 機櫃間 (Inter-Rack) 互連設定的「小於 5 pJ/b」嚴苛目標。
亮點二:輾壓級的頻寬密度(Tbps/mm 與 Tbps/mm2)
拔除龐大耗電的 CDR 與 DSP,加上「7nm EIC 面朝下堆疊 65nm PIC」的 3D 異質整合,帶來了驚人的空間微縮效果。
它的海岸線頻寬密度 (Shoreline density) 達到 0.8 Tbps/mm,面積頻寬密度 (Area density) 更高達 1.33 Tbps/mm2。對比前幾年的技術(落在 0.032 到 0.14 之間),這足足提升了一個數量級!這確保了在 GPU 邊緣極其稀缺的物理空間內,能夠塞入海量 I/O 頻寬。
亮點三:極致的接收靈敏度(<-16.0 dBm)
RX 接收靈敏度達到了驚人的 <-16.0 dBm OMA,遠遠優於對手 -10 dBm 的水準。
這證明了我們前面深究的「TIA 穩壓隔離設計」以及「雙重 ILO 注入鎖定濾波防線」在實戰中發揮了巨大作用。即便光訊號在 DWDM 光纖中大幅衰減或受到雜訊干擾,接收端依然能在極微弱的光功率下,乾淨地還原訊號(達成 <1E-11 的超低誤碼率 BER)。
宣告了 OIO 已經具備取代高階 GPU 叢集間銅纜的真實戰力:用最小的面積、最低的功耗和延遲,榨出極大的頻寬與跨機櫃的傳輸能力。
5. 結論
NVIDIA 在 ISSCC 2026 展示的這款 9 波長 DWDM 光學引擎,無疑為 AI 規模化網路 (Scale-up) 指明了一條極具潛力的道路。面對單通道速率極限與功耗牆的雙重夾擊,NVIDIA 證明了「慢而寬 (Slow and Wide)」搭配「時脈轉發 (Forwarding Clock)」並非只是理論上的美好願景,而是能在嚴苛尺寸限制下落地的實戰技術 。
這套架構最精彩之處,在於其捨棄了現代晶片設計中過度依賴「數位暴力 (DSP 補償)」的慣性,重新擁抱了精妙的類比電路設計 。無論是傳送端利用寬頻 OLS 榨出高電壓擺幅 ,還是接收端巧妙運用 ILO 形成雙重雜訊濾波防線 ,亦或是與台積電 COUPE 技術深度結合的 3D 異質封裝 (EIC over PIC) ,每一個環節都在為了「極致的微縮」與「每一分 pJ/bit 的壓榨」而服務 。
最終交出的成績單:高達 1.33 Tbps/mm2 的面積頻寬密度 、小於 -16.0 dBm 的卓越接收靈敏度 ,以及僅 2.59 pJ/bit 的整體功耗 。這不僅宣告了 SerDes-lite 架構的成功 ,更正式預告了 Advanced CPO (或稱 Optical I/O) 已經準備好跨越功耗門檻,在不久的將來全面接管高階 GPU 叢集間的短距互連任務 。
[Reference]
ISSCC26 23.1: A 32Gb/s/λ/Fiber Half-Rate Bandpass-Filtered Clock-Forwarding DWDM Optical Link in a 3D-Stacked 7nm EIC/65nm PIC Technology