EP34. DRAM Technologies Update

隨著生成式 AI 與大型語言模型 (LLM) 的爆發式成長,硬體效能的瓶頸已經從「處理器的算力」轉移到了「記憶體的存取速度」上 。為了滿足未來 AI 運算對高頻寬與高密度的極端需求,DRAM 技術正經歷一場從底層物理結構到後段封裝設計的全面革命 。分享個人觀點,歡迎討論。
1. Background
1.1. AI 推論面臨的記憶體牆
AI 推論(尤其是生成式 AI 與大型語言模型 LLM)對記憶體的需求極度渴望,這正是目前 AI 硬體架構面臨的最大瓶頸,業界常稱為「記憶體牆 (Memory Wall)」(參考: EP18. Memory Wall)
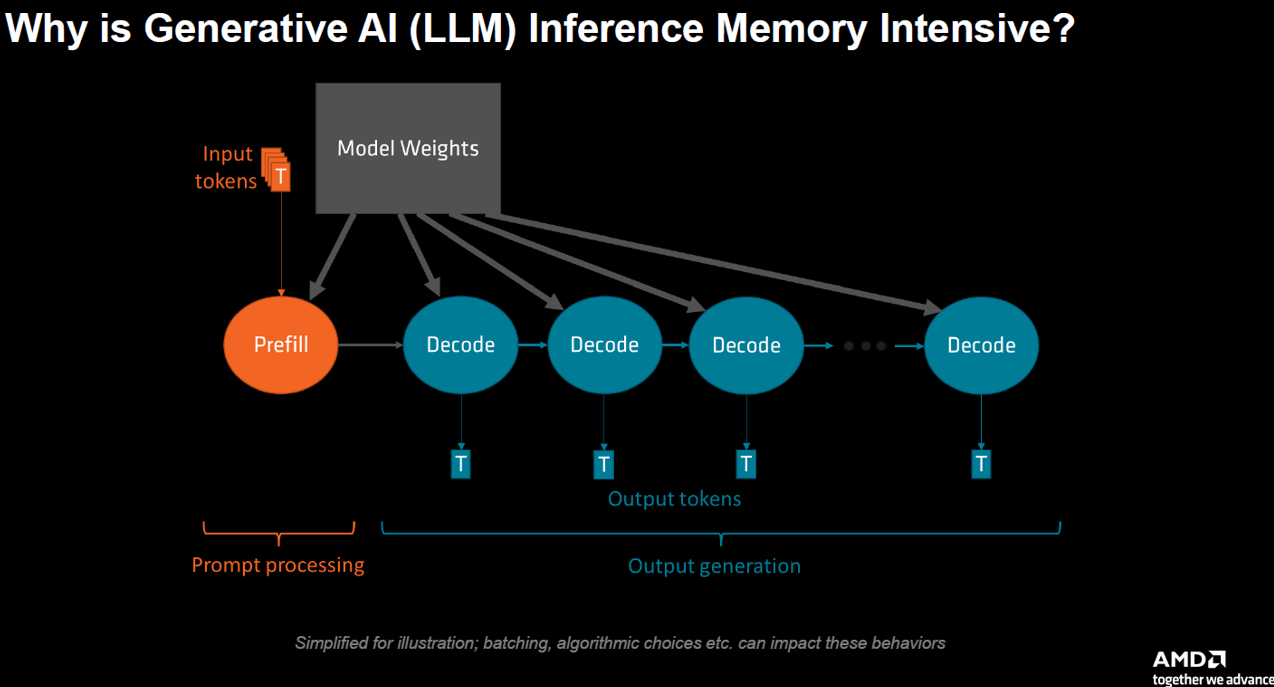
Source: IEDM25 SC2-1
為什麼 AI 推論超耗記憶體?
LLM 在生成文字(Decode 階段)時,每產生一個字,都必須把整套龐大的模型權重從記憶體搬運到運算核心一次。
這導致算力常常在「等」資料傳輸,系統的效能瓶頸在於記憶體頻寬(搬運資料的速度),而不是處理器的算力。
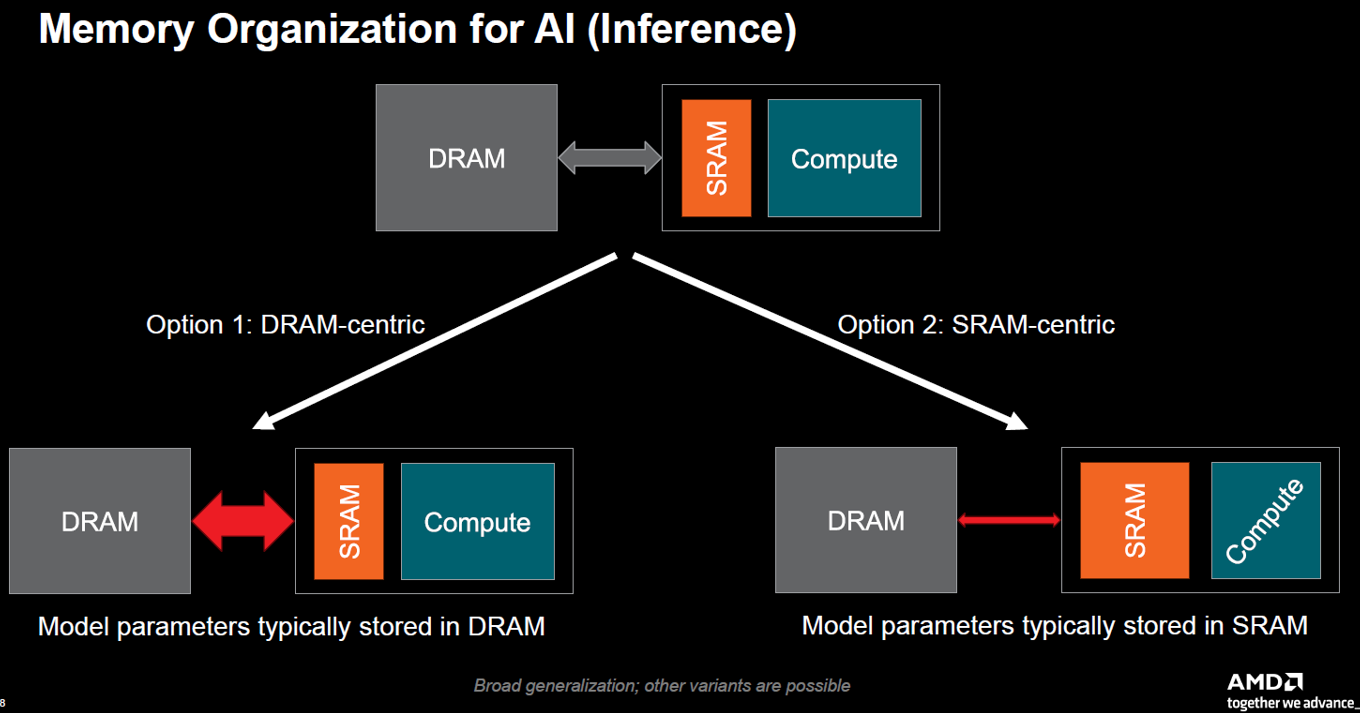
Source: IEDM25 SC2-1
兩種硬體記憶體架構選項:
以 DRAM 為中心(目前主流): 因為模型太大,只能放在外部的 DRAM 裡。為了解決傳輸瓶頸,必須建立極寬的資料通道(圖中的粗紅箭頭),這也是為何現在高階 AI 晶片都必須依賴 HBM 與先進封裝技術。
以 SRAM 為中心(例如: Groq LPU): 將模型直接存在晶片內部的 SRAM 裡。因為緊鄰運算核心,速度極快且不需依賴外部大頻寬(細紅箭頭),但缺點是晶片面積會變得非常大且成本極高。
源自於 Von Neumann 架構:
AI 推論的記憶體瓶頸源自於馮紐曼架構中「運算」與「儲存」物理分離的根本設計。
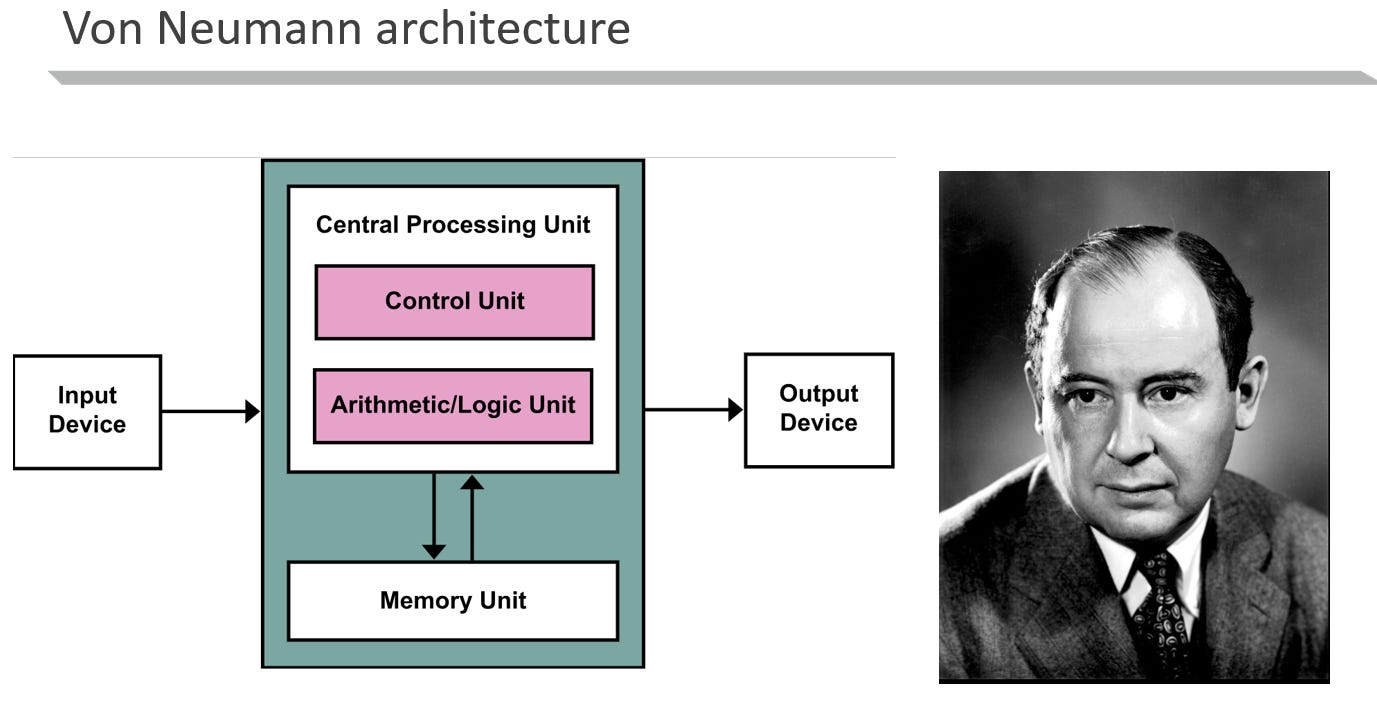
記憶體牆:
AI 晶片的算力極高,但推論時必須不斷透過有限的資料通道,從外部記憶體搬運龐大的模型參數過來運算。因為傳輸頻寬跟不上運算速度,導致高昂的算力經常在「空轉等資料」。
三大硬體解法:
拓寬通道: 既然無法避免分離,就利用先進封裝與高頻寬記憶體(HBM)盡可能把傳輸通道變寬。
記憶體池化: 當單晶片容量耗盡,就透過極低延遲的 Scale-up 網路(例如 NVLink 架構或 OCS 光交換網路)將多顆晶片的記憶體串聯共享。
改變架構: 捨棄外部 DRAM,將模型直接存在晶片內建的海量 SRAM 中(如 Groq LPU),徹底消除外部搬移的延遲
Memory 種類:
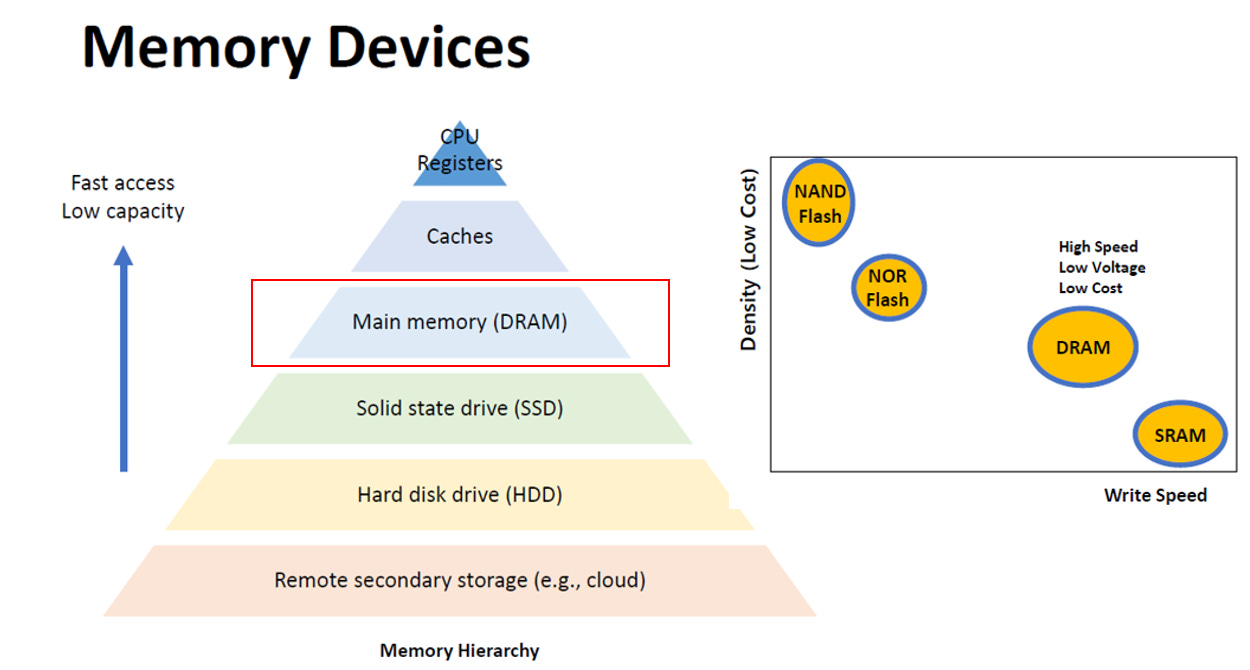
Source: IEDM25 SC2-3
記憶體階層(金字塔圖):效能與容量的權衡
頂層(CPU 暫存器 / 快取):存取速度最快,但儲存容量最小、成本最高。
中層(主記憶體 / DRAM):速度與容量表現適中,負責在極速的運算區與緩慢的儲存區之間擔任橋樑。
底層(SSD / 硬碟 / 雲端):存取速度最慢,但能提供最大的儲存容量且單位成本最低。
元件物理特性(座標圖):寫入速度 vs. 密度與成本
SRAM:擁有極高的寫入速度,但儲存密度最低(最佔晶片空間,6T)、成本也最高。
DRAM:速度稍慢於 SRAM,但在儲存密度(1T1C)與成本上取得了較好的平衡。
Flash (NAND / NOR):寫入速度最慢,卻能提供最高的儲存密度與最低的單位成本
與 AI 推論的關係:
底層 (NAND Flash / SSD) - AI 模型的「冷資料庫」: 擁有最高的儲存密度與最低成本。專門用來存放尚未啟動的龐大模型檔案。因為存取速度太慢,絕不會在這裡進行推論運算。
中層 (DRAM / 主記憶體) - AI 推論的「主戰場與瓶頸」: 在容量與速度間取得平衡。運作中的模型權重與生成的上下文記憶 (KV Cache) 都塞在這裡。由於頻寬經常卡死生成速度,高階 AI 晶片會將這層的 DRAM 升級為 HBM (高頻寬記憶體) 以拓寬通道。
頂層 (SRAM) - AI 運算的「極速彈藥庫」: 擁有極高的寫入速度,但容量極小。它緊貼在 AI 運算核心旁,負責零延遲地餵給資料。特定加速器 (如 Groq) 甚至極端地全用 SRAM 來追求物理極限的推論速度。
1.2. DRAM Basics
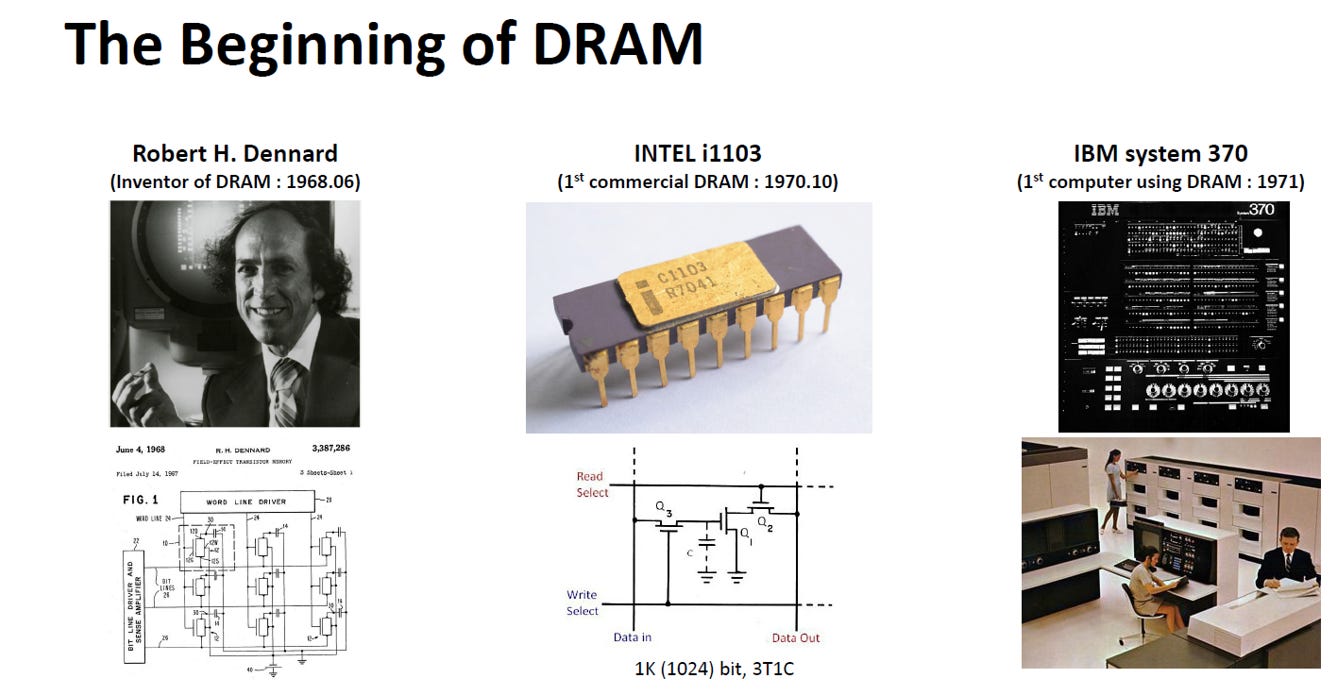
DRAM 的起源與早期發展
Source: IEDM25 SC2-3
1968 年:DRAM 的誕生
DRAM 是由 Robert H. Dennard 於 1968 年 6 月所發明(1T1C)。
1970 年:首款商業化晶片問世
Intel 在 1970 年 10 月推出了全球第一款商業化的 DRAM 晶片,型號為「INTEL i1103」。
當時這顆晶片的容量僅有 1K (1024) bit,底層電路設計採用的是「3T1C」架構(由三個電晶體與一個電容組成)。
1971 年:首次導入電腦系統
第一台實際採用 DRAM 作為記憶體的電腦系統是「IBM system 370」,於 1971 年正式登場。
關於 Intel 首款商用 DRAM 採用 3T1C 而非 1T1C 的原因:
1T1C 當時技術難以駕馭: 雖然 1T1C 最節省空間,但在 1970 年代的製程下,它釋放的電荷訊號實在太微弱了,而且讀取時會把電放光(破壞性讀取),當時的電路很難穩定控制。
3T1C 是「用面積換良率」的務實妥協: Intel i1103 選擇 3T1C,是因為多出來的電晶體可以直接「放大訊號」並做到「讀取時不破壞資料」。雖然佔空間,但大幅降低了出錯率,確保了晶片能順利商業化量產。
客戶需求的推波助瀾: 當時的電腦製造商 Honeywell 帶著內部構思好的 3T 設計找上 Intel 尋求代工與優化,這也直接決定了首款商用 DRAM 的架構走向。
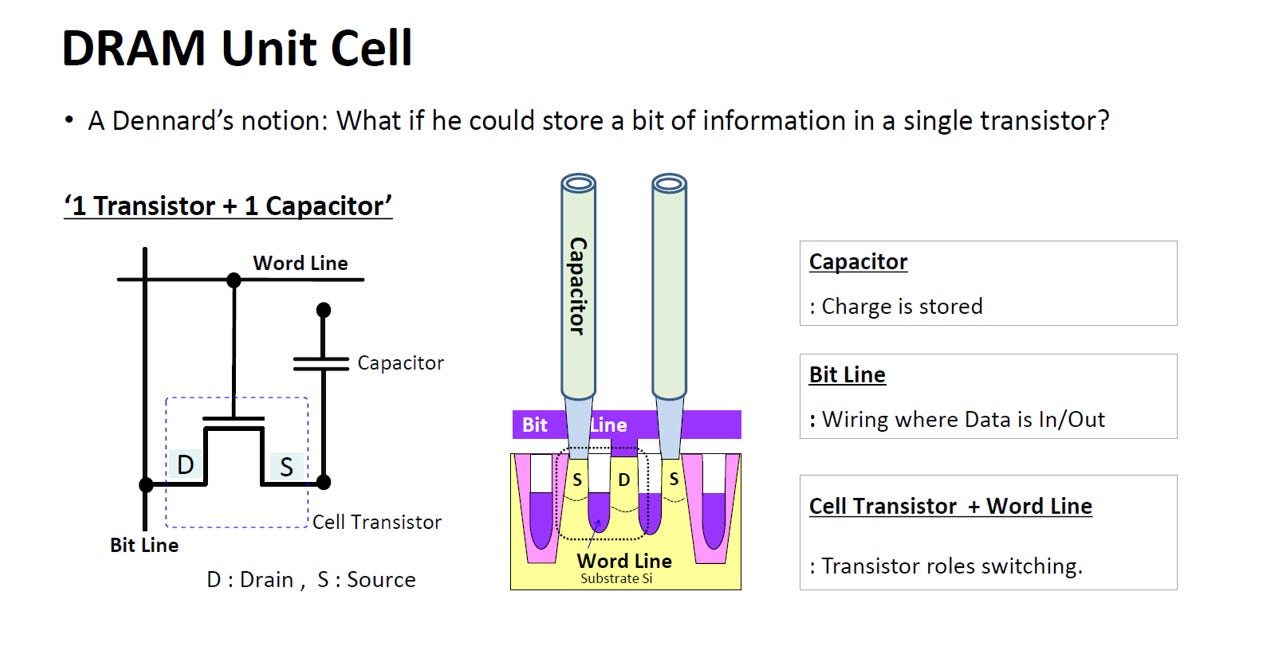
1T1C(單一電晶體 + 單一電容)架構
Source: IEDM25 SC2-3
電容 (Capacitor) = 儲存槽:負責儲存電荷。裡面有電或沒電的狀態,就代表著數位資料的「1」或「0」。
電晶體與字元線 (Transistor & Word Line) = 控制閥:字元線負責通電,讓電晶體發揮開關的作用,決定是否允許外部去讀取或寫入電容裡的電荷。
位元線 (Bit Line) = 傳輸通道:資料實際進出的實體佈線。寫入時透過它把電荷灌進去,讀取時透過它把電荷導出來判斷是 1 還是 0。
Common Drain: 為了極致壓縮晶片面積,兩個相鄰的 DRAM 記憶單元會背靠背共用同一個位元線(BL)接點(資料通道),並透過各自專屬的字元線(WL)(開關)來維持獨立運作。
1T1C 架構就是透過一個開關(電晶體)來控制一個微小電池(電容)的充放電,藉此記錄資料。由於電容天生會漏電,所以系統必須不斷「動態」地去重新充電(Refresh)才能維持記憶。
2. DRAM 空間爭奪戰:從 2D 走向 3D
2.1. Roadmap
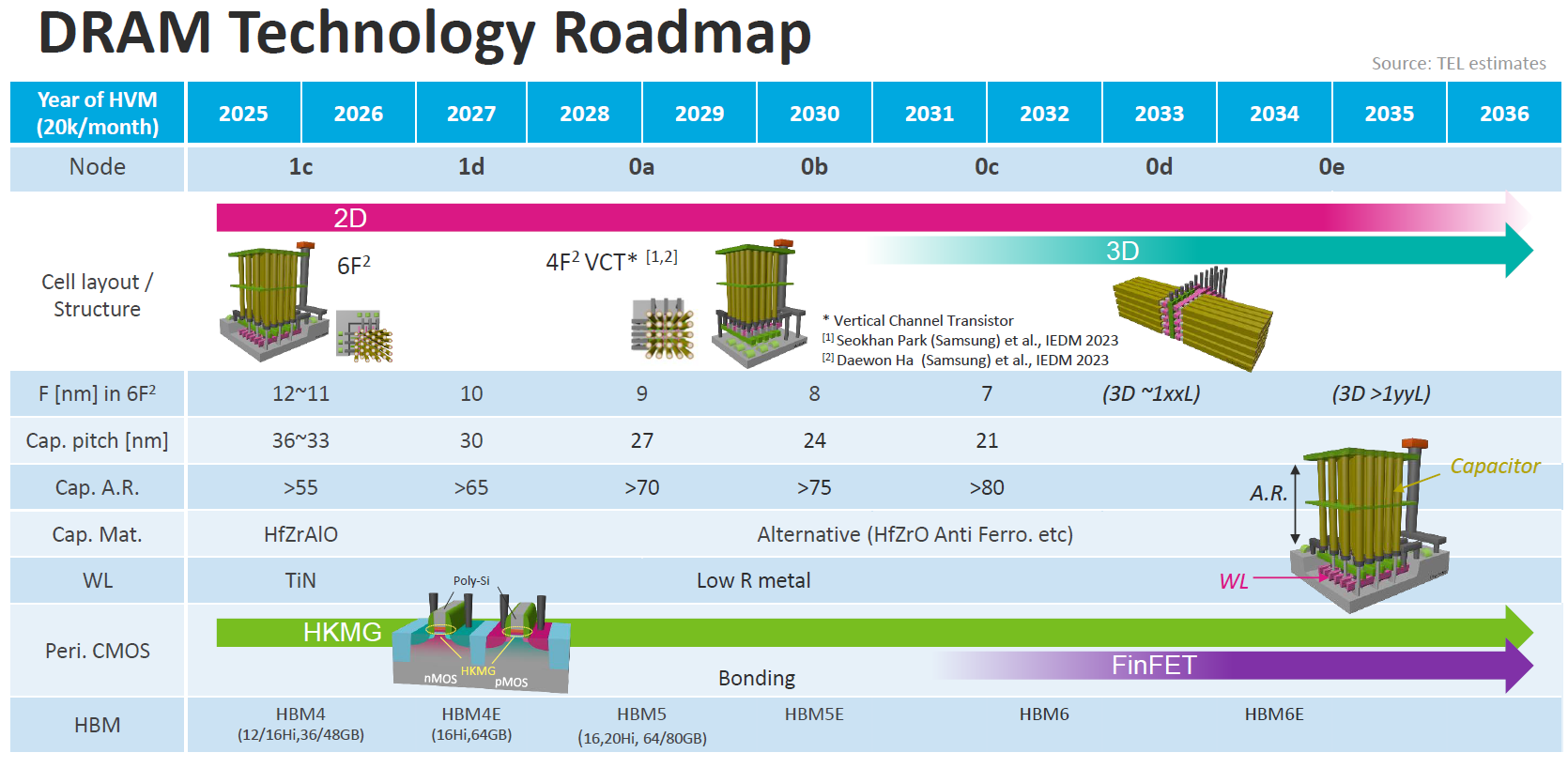
Source: IEDM25 SC2-5
四個核心發展趨勢:
架構的立體化革命 (從 2D 到 3D): 這是最重要的結構變革。
DRAM 的基礎單元將從現今主流的 2D 平面佈局 (6F2 面積) 發生跳躍式的改變。預計在 2028 年左右 (0a 節點),業界將導入 4F2 VCT (垂直通道電晶體) 技術,將電晶體「直立起來」以進一步壓縮面積。到了 2031 年之後,更將正式跨入真正的 3D DRAM 時代
電容深寬比的極限挑戰:
為了在不斷微縮的面積中維持足夠的電容量(避免漏電導致資料遺失),電容必須往上蓋得越來越高。圖表顯示,電容的深寬比 (Cap. A.R.) 將從 2025 年的大於 55,一路狂飆到 2031 年的大於 80。與此同時,電容材料也必須從現有的 HfZrAlO 轉換為更先進的鐵電等替代材料。
周邊電路與導線的全面升級:
負責傳遞控制訊號的字元線 (WL) 未來將導入低阻值金屬 (Low R metal) 以減少延遲。而負責控制的周邊電路 (Peri. CMOS) 也將從傳統的 HKMG,逐步採用晶圓鍵合技術 (Bonding) 來隱藏至陣列下方,未來甚至會升級為 FinFET 架構來強化運作效能。
驅動 AI 算力的 HBM 世代交替:
藍圖最下方的發展軌跡,直接對應了 AI 推論對超大頻寬的渴望。隨著底層 DRAM 製程節點的推進,高頻寬記憶體將從 2025 年的 HBM4 (12/16層堆疊),一路演化至 HBM4E、HBM5,甚至 2030 年代之後的 HBM6 與 HBM6E,藉由不斷增加的堆疊層高與單晶片容量,來打破「記憶體牆」的束縛。
兩條核心雙主線:
Cell Evolution = 前段製程革命:
專注於「晶片內部」的微縮。透過引進新設備 (如 EUV,ALD)、新材料以及改變物理結構 (從平躺的 6F2 演進到直立的 4F2 垂直通道電晶體),在單一片矽晶圓上把基礎記憶單元越塞越密,追求極致的儲存密度。
HBM = 後段先進封裝革命:
專注於「晶片外部」的整合。當單一晶片的容量與頻寬遇到物理天花板時,利用矽穿孔 (TSV) 與先進鍵合技術 (Bonding: TCB/HB),將多層 DRAM 裸片像蓋大樓一樣立體堆疊起來 (如一路演進到 HBM5、HBM6),藉此用「空間換取通道」,提供 AI 運算亟需的超大頻寬(參考: EP8: HBM technologies)
DRAM 與邏輯製程的發展對照表:
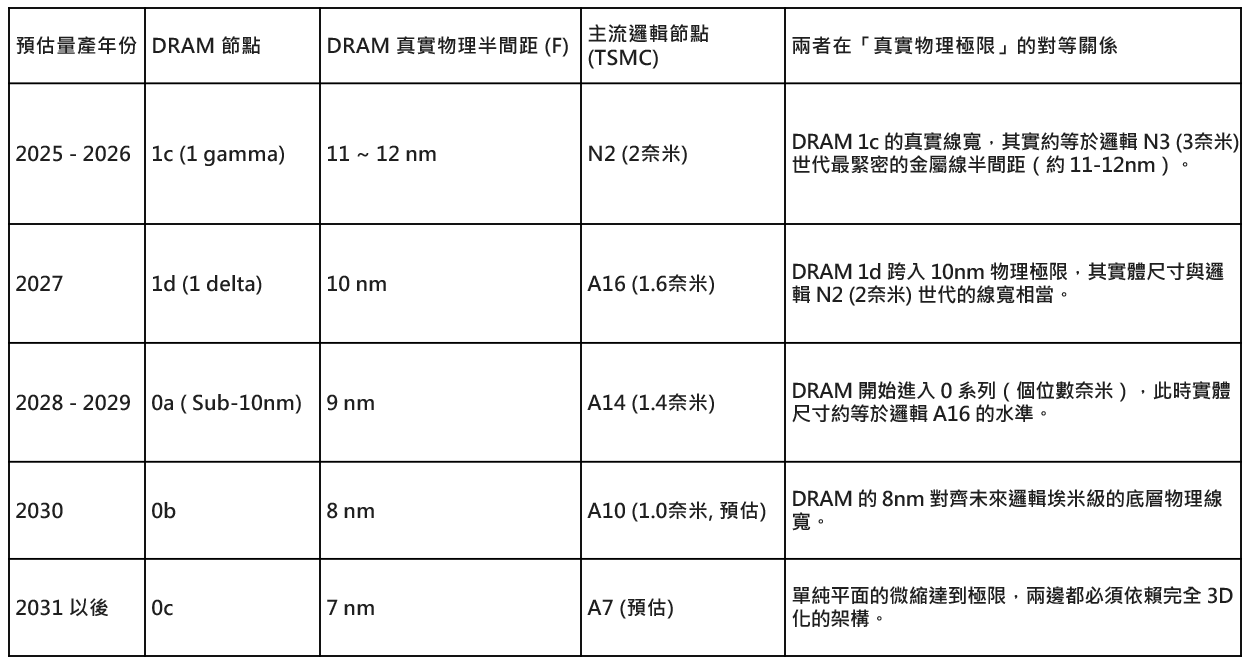
邏輯節點的命名純粹是行銷數字,DRAM 節點則相對誠實地反映了物理尺寸:
邏輯節點(Logic): 台積電的 N3 (3奈米) 或 N2 (2奈米),晶片上早已沒有任何一個物理特徵真的是 3 奈米或 2 奈米。它的命名代表的是「效能演進的世代」。
DRAM 節點: 根據您提供的發展藍圖,DRAM 的命名(如 1c, 1d, 0a)通常緊密對應著陣列的物理半間距(Half-pitch, 簡稱 F)。
為什麼 DRAM 看起來總是「落後」邏輯製程好幾個世代?
邏輯運算只需「當下」的開關: 邏輯製程的電晶體只負責把電流切換(0 與 1),只要材料不漏電,結構可以極致縮小(例如 N2 導入 GAA 環繞閘極結構)。
DRAM 必須「長期」鎖住電荷: 正如我們前文討論的 1T1C 架構,DRAM 不只要縮小電晶體,還必須帶一個實體電容 (Capacitor) 來儲存電荷。晶片面積縮小了,但如果電容容量跟著變小,資料就會消失。
電容是微縮的最大絆腳石: 為了在極小的面積裡維持電容體積,DRAM 廠只能把電容越蓋越高。圖中顯示,到 0c 世代,電容的深寬比 (Cap. A.R.) 會飆破 80。這就像在地震帶上蓋 101 大樓一樣困難,導致 DRAM 的微縮進度遠比邏輯代工慢得多。
2.2. Cell Layout Evolution
DRAM 記憶單元(Unit Cell)如何透過佈局改良來壓榨空間,達到容量極大化的目標:
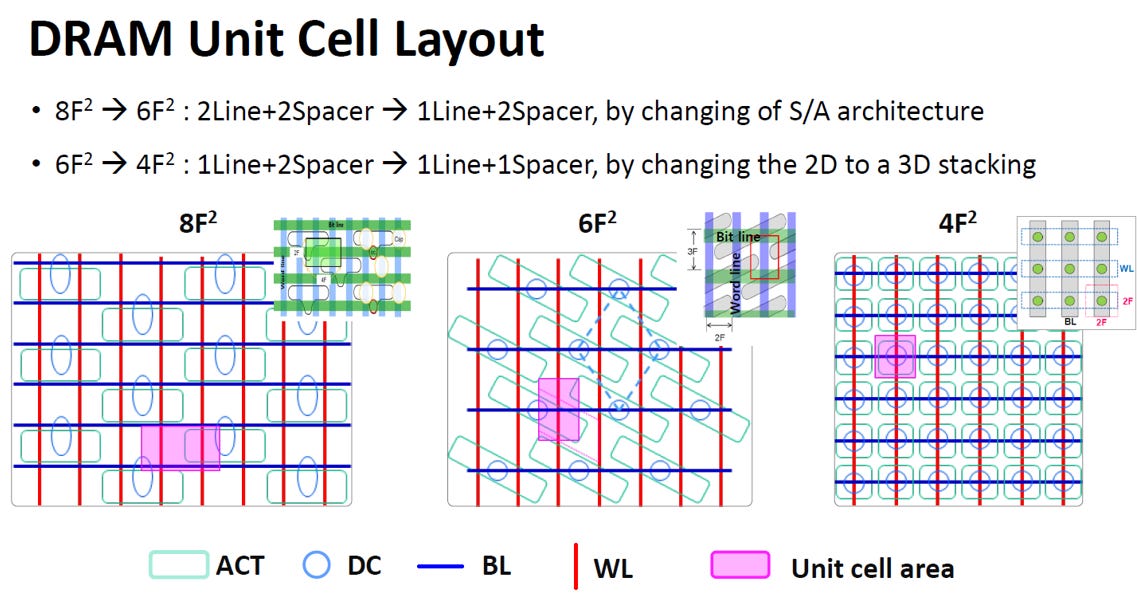
Source: IEDM24 SC1-3
F 的意義(最小特徵尺寸):F 代表該製程技術下能做出的最細線寬。8F²、6F²、4F² 則是指「單個記憶單元」所佔用的實體面積大小。
8F²(傳統網格):最原始的方正佈局,線寬與間距比例較鬆散(2Line + 2Spacer, Line = Spacer = F),單元面積最大(8F² = 4Fx2F)。
6F²(傾斜佈局):目前的主流技術。將主動區(ACT)傾斜擺放,像擠沙丁魚一樣交錯堆疊,成功將比例壓縮至 1Line + 2Spacer(1F+2F = 3F),在不改變線寬的前提下騰出更多空間。
4F²(立體堆疊):未來的終極目標。佈局回歸最簡約的十字交會,並達到物理極限的 1Line + 1Spacer。這必須將平鋪的電晶體改為**垂直立體結構(3D Stacking)**才能達成。
DRAM 透過從「平躺方正」演進到「傾斜交錯」,最後走向「垂直立體」,在同樣的面積裡塞進更多記憶單元。
2.3. 2D DRAM (6F²)
目前主流的 2D DRAM (6F²) 架構是記憶體產業在成本與容量之間取得最佳平衡的產物,其核心特點在於透過幾何設計的變革,在相同製程下比早期架構多切出約 33% 的晶粒
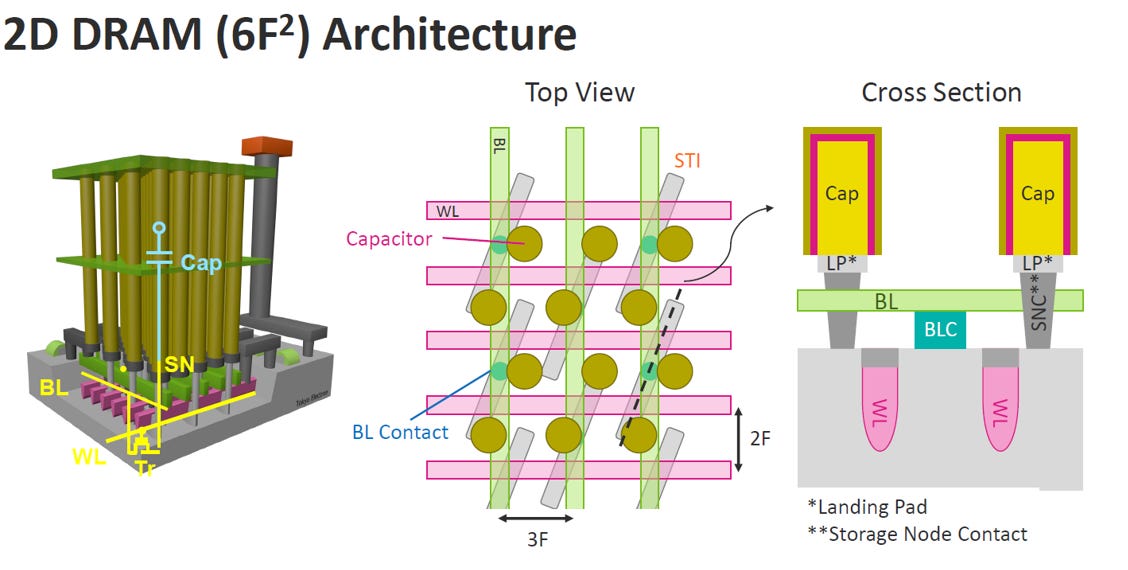
Source: IEDM25 SC2-3
空間利用:傾斜的主動區設計
傾斜佈局:不同於水平排列,6F² 將主動區(Active Area/STI)設計為傾斜角度橫跨字元線。
壓縮比例:這種傾斜方式允許單元像擠沙丁魚一樣交錯堆疊,將單元長度從傳統的 4F 壓縮至 3F。
面積公式:單元長度 3F 乘以寬度 2F,得出物理面積為 6F²。
立體結構:高深寬比電容
柱狀電容 (Capacitor):電容結構如同高塔般矗立在頂層,負責儲存電荷。
物理極限:隨著面積縮小,為了維持電容量,電容必須蓋得越來越高。目前 1c/1d 節點的電容深寬比(A.R.)已超過 55 到 65。
連接機制:電容透過落地墊(Landing Pad, LP)與儲存節點接點(SNC)向下連接至電晶體。
底層開關:埋入式字元線
Buried Word Line (WL):字元線被埋入矽基板的溝槽中,作為電晶體的閘極開關。
效能優勢:這種埋入式結構能有效改善短通道效應並減少漏電,是達成高密度儲存的關鍵製程。
與 8F² 的差異
8F²:採用方正網格(2Line + 2Spacer),結構較鬆散,單元面積較大。
6F²:藉由「改變感測放大器架構」與「傾斜主動區」,將比例優化至 1Line + 2Spacer,大幅提升儲存密度
2.4. 3D DRAM
2.4.1. 4F² VCT(Vertical Channel Transistor)
4F²垂直通道電晶體 (VCT) 是 DRAM 架構為了突破平面微縮極限,所演化出的革命性「立體化」設計。
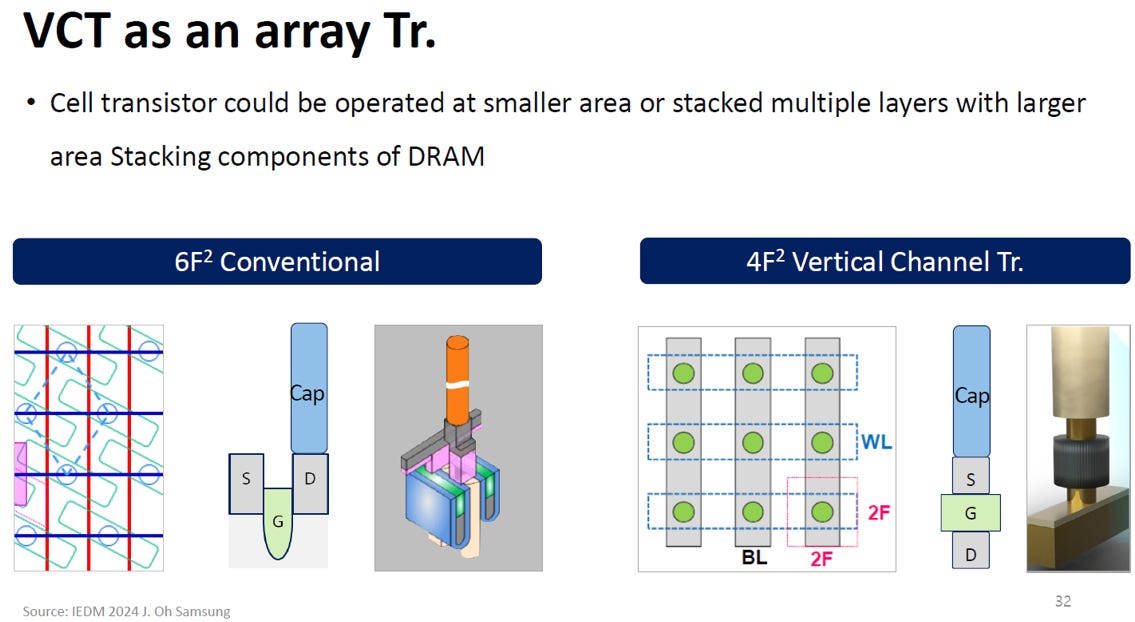
Source: IEDM25 SC2-3
從圖表中的左右對比,可以清楚拆解這項技術的核心特徵與影響:
核心結構:把電晶體「拔地而起」
傳統 6F² 架構:在左側的示意圖中,儘管閘極 (G) 採用了埋入式設計,但電晶體的源極 (S) 與汲極 (D) 依然是平躺在矽晶圓表面上的。電子通道的運作基本上仍在水平面上。
4F² VCT 架構:右側的 VCT 徹底改變了空間的利用方式。它將汲極 (D)、閘極 (G) 與源極 (S) 像蓋大樓一樣由下往上垂直堆疊,並將電容 (Cap) 直接蓋在最頂端。電流的流動方向從水平變成了完全的上下垂直。
佈局革命:極簡的完美網格
因為電晶體變成了直立的柱狀體,DRAM 陣列的平面佈局不再需要像 6F² 那樣採用複雜的「傾斜主動區」來硬擠空間。
觀察圖中的俯視佈局,字元線 (WL) 與位元線 (BL) 回歸了最單純的十字垂直交叉。每一個交會點就是一個直立的記憶單元,完美將單元長寬壓縮至 2F x 2F,達成 4F² 的物理理論極限面積。
戰略意義:叩關 3D DRAM 時代
圖表頂部特別點出,VCT 架構不僅能在更小的面積內運作,更具備「堆疊多層 (stacked multiple layers)」的潛力。
透過將基礎元件垂直化,記憶單元變成了一個個獨立的微型高塔,這為未來跳脫單層矽晶圓限制、將多層 DRAM 陣列層層往上疊加的「真 3D DRAM」技術打下了基礎
2.4.2. VS-DRAM(Vertical Stack DRAM)
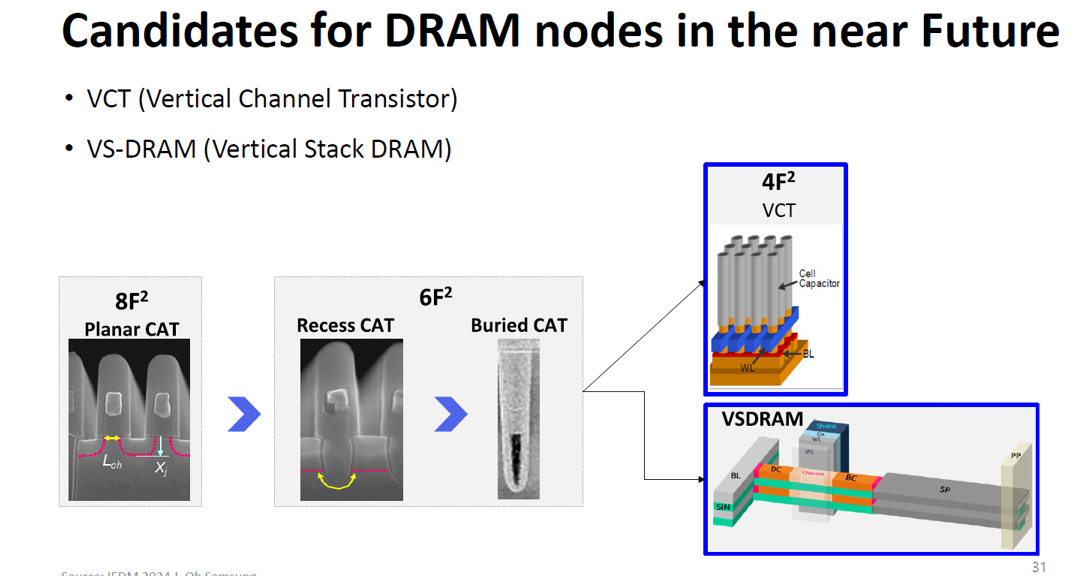
Source: IEDM25 SC2-3
2D 時代的空間魔術 (8F2 到 6F2)
8F2 平面閘極 (Planar CAT):早期的電晶體完全平躺在矽基板表面。因為通道(Channel)在表面佔據了較大面積,很快就遇到了微縮瓶頸。
6F2 凹槽/埋入式閘極 (Recess / Buried CAT):這正是目前業界的主流。為了解決平面空間不足,工程師開始「往下挖溝」,把電晶體的控制通道與字元線埋進矽基板深處。這讓 DRAM 得以一路順利微縮到現今的 10 奈米等級
2D 極限的過渡期 (4F2 VCT)
4F2 垂直通道電晶體 (VCT):當「往下挖」也擠不出空間時,解法就是把整個電晶體「直立起來」。讓電流由下往上垂直流動,電容則頂在最上方。這是單層矽晶圓(2D 平面)所能達成的終極物理極限面積。
終極型態:VS-DRAM (Vertical Stack DRAM / 3D DRAM)
如果說 4F2 VCT 是在原本的一樓平房裡「把所有家具立起來放」以節省空間,那麼 VS-DRAM 就是直接放棄平房,開始蓋「多樓層公寓」。根據藍圖,這是預計在 2031 年之後全面接棒的真 3D DRAM 技術。
架構徹底翻轉 (Horizontal Cell, Vertical Stack):
請仔細對比圖中的 4F2 VCT 與 VSDRAM。VCT 是一個個直立向上的柱子。
VSDRAM 則是把位元線 (BL)、通道 (Channel) 以及電容 (SP, Storage Poly / Storage Plate),全部改成**「水平橫躺」**的方式,做成一層超薄的平面結構。
向 3D NAND 借鏡的堆疊魔法:
VSDRAM 不再執著於把單一個元件做得更小,而是將上述那種「橫躺的記憶單元」,一層一層地往上垂直堆疊 (Vertical Stack)。
這意味著,未來 DRAM 容量的提升,不再完全受限於 EUV 光刻機的解析度極限,而是取決於半導體廠能穩穩地「往上疊幾層樓」。
化解電容的「高塔危機」:
在傳統 2D 或 VCT 架構中,為了維持電量,電容必須往上蓋得超級細長。
但在 VSDRAM 的架構中,電容變成了橫向發展(圖中標示為 SP 的長條結構)。這巧妙地避開了製造超高深寬比柱狀電容的極端物理與蝕刻難題。
這種橫向設計帶來了巨大的製造優勢:半導體廠再也不用痛苦地去挑戰極端深寬比的「深洞蝕刻」了。工程師只需像做三明治一樣,用平面沉積的方式一層一層把 SP(Storage Poly) 與 PP(Plate Poly) 平鋪上去,就能輕鬆擴展電容面積,並實現完美的 3D 垂直堆疊。
DRAM 的演進史,就是一場從「平躺 (8F2)」、到「挖溝 (6F2)」、到「站立 (4F2 VCT)」,最後走向「蓋摩天大樓 (VS-DRAM)」的極致空間爭奪戰。
3. 先進微影與電容製造挑戰
3.1. Lithography
EUV(極紫外光)微影技術在量產先進製程時,所面臨的物理挑戰,以及業界為了解決這個痛點所導入的方案:
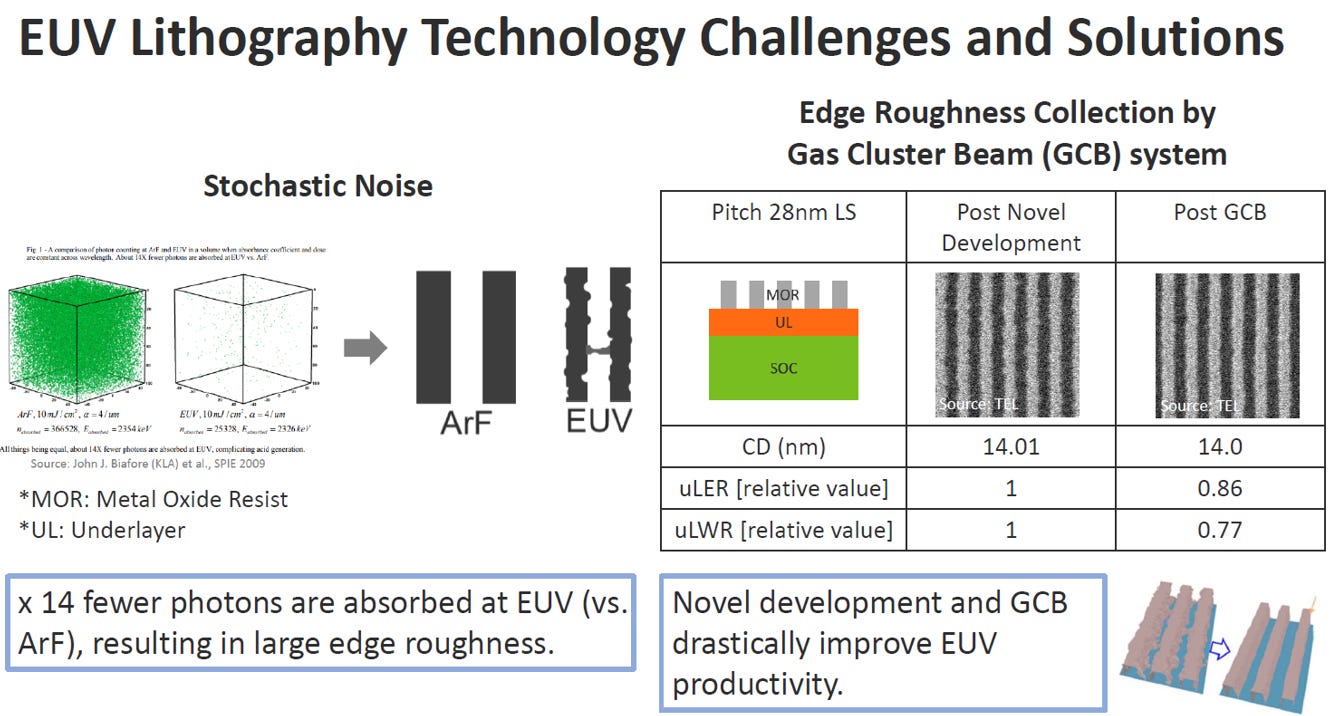
Source: IEDM25 SC2-5
挑戰:隨機雜訊 (Stochastic Noise) 導致邊緣粗糙
光子數量不足:EUV 的波長極短、單一光子能量極高。圖中指出,在相等的條件下,光阻劑吸收到的 EUV 光子數量,足足比傳統的 ArF 浸潤式機台少了 14 倍。
打點不均勻:因為可用來曝光的光子數量太少,打在晶圓上的分佈就像下毛毛雨一樣,產生嚴重的「隨機雜訊」。
線條崎嶇 (Large Edge Roughness):從圖表中間的黑白對比圖可以看到,傳統 ArF 印出來的線條邊緣非常平整,但 EUV 印出來的線條卻像狗啃的一樣,邊緣非常粗糙崎嶇。這種粗糙度在極端微縮的製程中,會輕易導致線路斷裂或相鄰線路短路
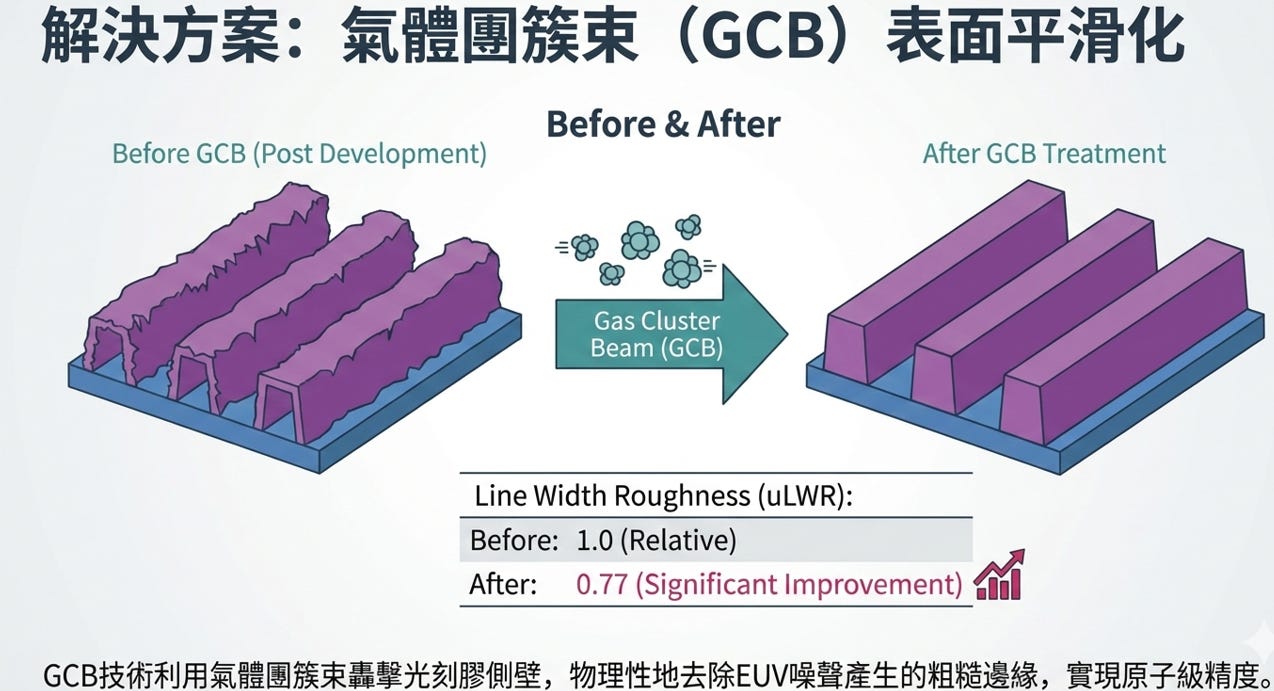
解決方案:氣體叢集離子束 (GCB) 系統修整
導入新設備修補:為了解決這個問題,提出了一種後段修整技術:利用 GCB (Gas Cluster Beam, 氣體叢集離子束) 系統來進行邊緣粗糙度的收集與修平。
削平邊緣的魔法:在一般的顯影後(Post Novel Development),線條邊緣依然粗糙。但經過 GCB 的處理後(Post GCB),設備能精準地把突出的邊緣「削平」或「撫平」。
數據實證:經過 GCB 處理,線寬(CD)依然完美維持在 14.0 nm,但相對的邊緣粗糙度指標 uLER(線邊緣粗糙度)與 uLWR(線寬粗糙度)分別顯著下降到了 0.86 與 0.77,線條變得平滑許多。
EUV 雖然解析度極高,但因為「光子太少」帶來了嚴重的隨機雜訊與邊緣粗糙問題。業界目前的解法是透過新型顯影技術搭配 GCB 設備進行後段的「物理拋光」,藉此大幅提升 EUV 的生產力與良率。
3.2. 高深寬比電容的三大難關
用來儲存電荷「高深寬比柱狀電容 (Capacitor)」的三大關鍵製程與物理挑戰:
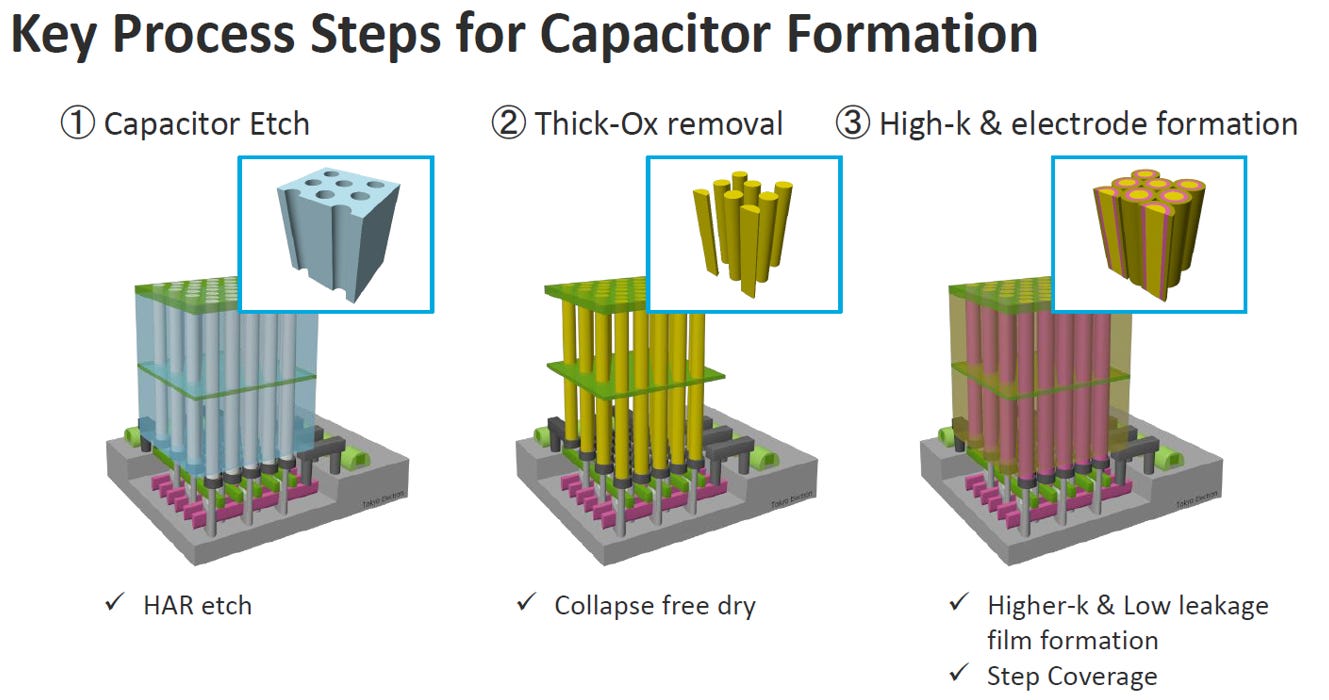
Source: IEDM25 SC2-5
蝕刻孔洞 (Capacitor Etch)
利用 HAR (高深寬比) 蝕刻技術,往下精準挖出極度深且狹窄的圓柱形孔洞,挑戰在於必須維持筆直不偏斜。
移除模具 (Thick-Ox removal)
洗掉周圍的厚氧化層模具,留下細長的柱狀結構森林。此階段必須採用無倒塌乾燥 (Collapse free dry) 技術,避免液體的表面張力將脆弱的柱體拉扯傾倒或互相沾黏
沉積材料 (High-k & electrode formation)
在極狹窄的微觀柱體間隙中均勻鍍上電極與薄膜。挑戰在於達成完美的階梯覆蓋率 (Step Coverage),並且必須導入高介電常數 (Higher-k) 且低漏電的材料,以確保極小體積內能鎖住足夠電荷
DRAM 電容的成形,就是一場連續克服「極限深孔蝕刻」、「防護細微高塔倒塌」以及「極窄縫隙完美鍍膜」的微觀工程挑戰。
3.2.1. Capacitor Etch (蝕刻孔洞)
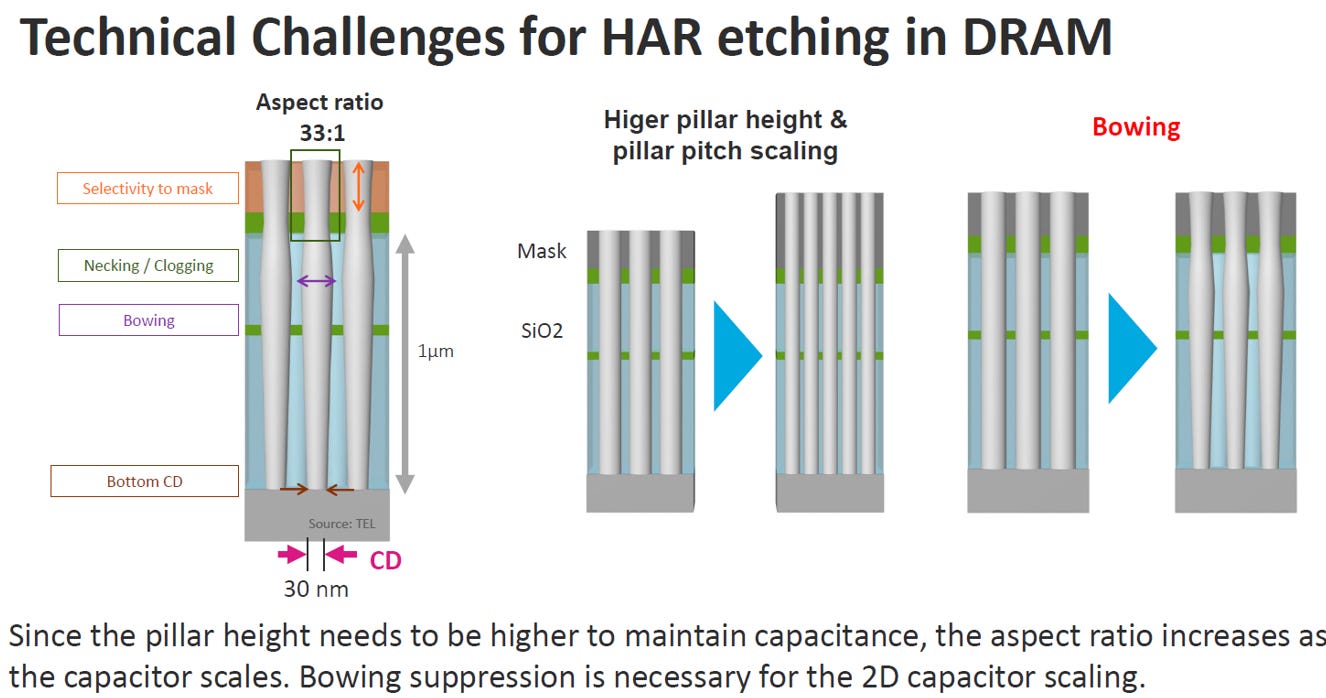
Source: IEDM25 SC2-5
面臨的挑戰:Bowing (弓形 / 膨肚效應)
隨著 DRAM 容量提升,電容孔必須挖得極深。
極端深寬比 (Aspect Ratio):圖中展示了一個深達 1 微米 (1um) 但底部線寬 (CD) 僅有 30 奈米的孔洞,深寬比高達 33:1。
多重蝕刻缺陷:在這種極端條件下往下挖,會遇到光罩選擇比 (Selectivity to mask)、頂部頸縮/阻塞 (Necking / Clogging)、以及底部尺寸控制 (Bottom CD) 等一連串問題。
最致命的 Bowing 效應:圖表右側特別強調了「Bowing」現象。在長時間的電漿蝕刻過程中,孔洞中段的側壁會因為受到側向侵蝕而膨脹變寬,形狀變得像弓或大肚子一樣。隨著記憶體單元微縮、電容排列越來越密集,這種「膨肚」會導致相鄰的電容互相接觸而發生短路。因此,抑制 Bowing 是 2D 電容持續微縮的必要條件。
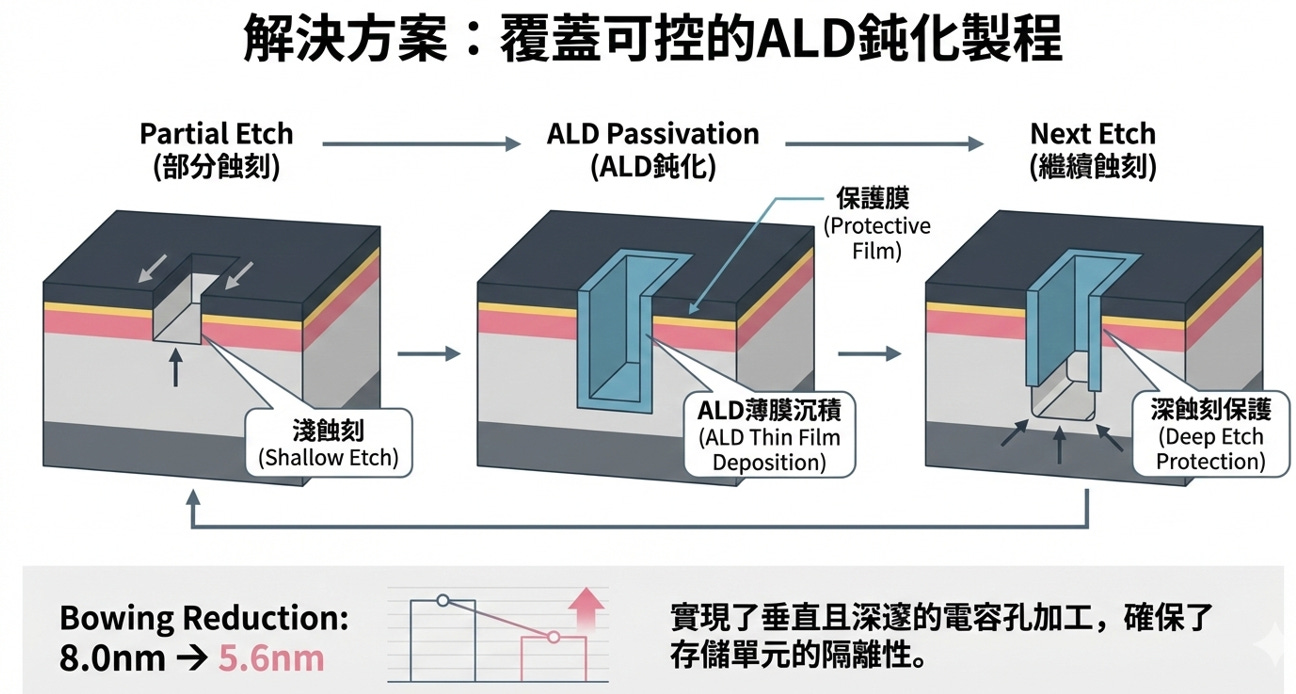
解決方案:可控的 ALD(原子層沉積) 鈍化製程
為了解決中段側壁被過度蝕刻的問題,第二張圖表展示了一種巧妙的「邊挖邊保護」循環策略:
步驟一:部分蝕刻 (Partial Etch):先往下挖出一個較淺的孔洞 (Shallow Etch)。
步驟二:ALD 鈍化 (ALD Passivation):暫停蝕刻,利用 ALD 薄膜沉積技術,在剛剛挖好的孔洞側壁與底部,均勻覆蓋一層極薄的「保護膜 (Protective Film)」。
步驟三:繼續蝕刻 (Next Etch):再次啟動蝕刻。此時垂直向下的離子束會輕易打破底部的保護膜並繼續往下挖,但「側壁」因為有 ALD 薄膜的深蝕刻保護,就不會被電漿產生側向侵蝕。
循環加工:系統會不斷重複這三個步驟 (部分蝕刻 ➔ ALD 鈍化 ➔ 繼續蝕刻),直到達到目標的完美深度。
透過這種 ALD 鈍化保護技術,圖表左下角的數據顯示,Bowing 的膨脹程度成功從 8.0nm 大幅縮小到 5.6nm。這實現了垂直且深邃的電容孔加工,確保了記憶儲存單元之間的隔離性,完美避開了短路危機。
3.2.2. Thick Oxide Removal(移除模具)
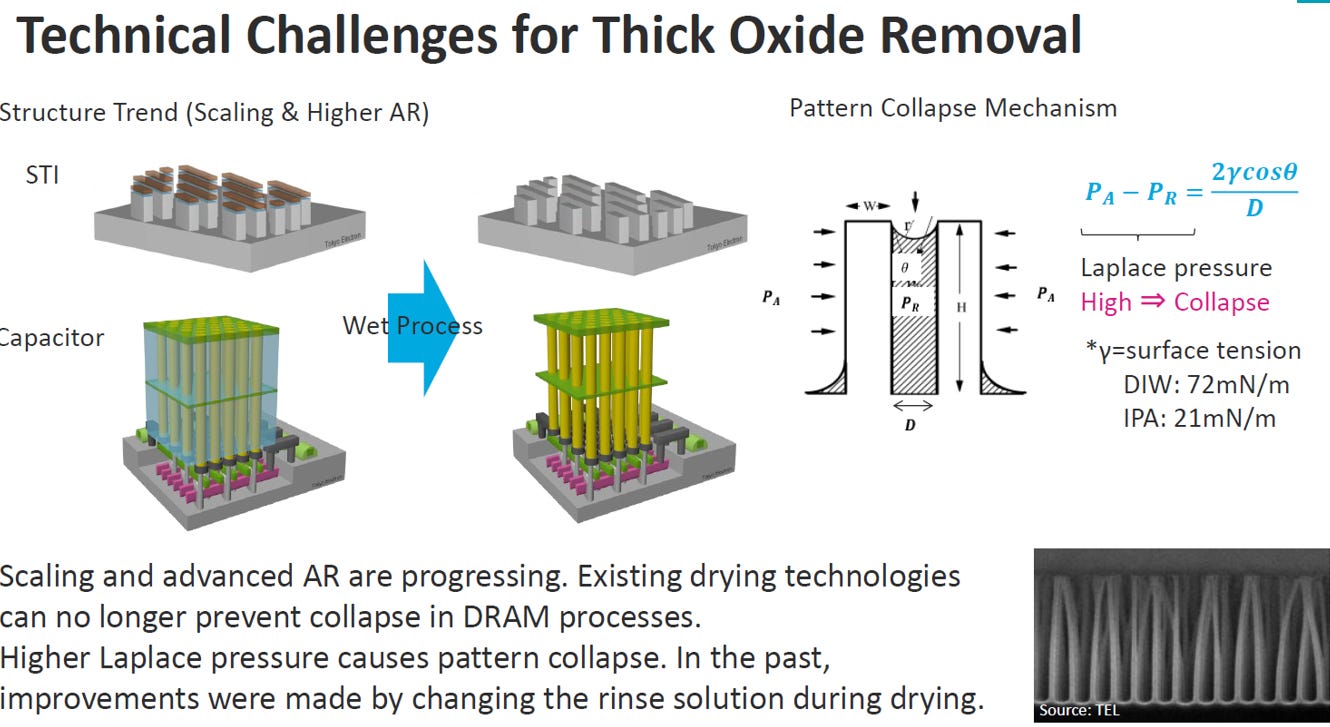
Source: IEDM25 SC2-5
致命挑戰:表面張力導致的「圖案倒塌 (Pattern Collapse)」
問題情境: 當費盡千辛萬苦挖好深孔並建立起電容柱體的雛形後,必須使用濕式製程 (Wet Process) 用液體洗掉周圍作為模具的厚氧化層。
物理元凶: 真正的危機發生在「乾燥 (Dry)」的瞬間。圖表右側的物理機制顯示,當清洗液體(如去離子水 DIW 或異丙醇 IPA)在柱子之間蒸發時,會產生表面張力 (Surface Tension)。
拉普拉斯壓力 (Laplace Pressure): 這個表面張力會在微觀尺度下產生強大的「拉普拉斯壓力」,就像一雙無形的大手,無情地把周圍極度細長、脆弱的電容柱體拉扯在一起。從右下角的電子顯微鏡照片可以看到,柱子就像被風吹倒的蘆葦一樣,發生嚴重的沾黏與倒塌,這會導致整顆記憶體晶片報銷。
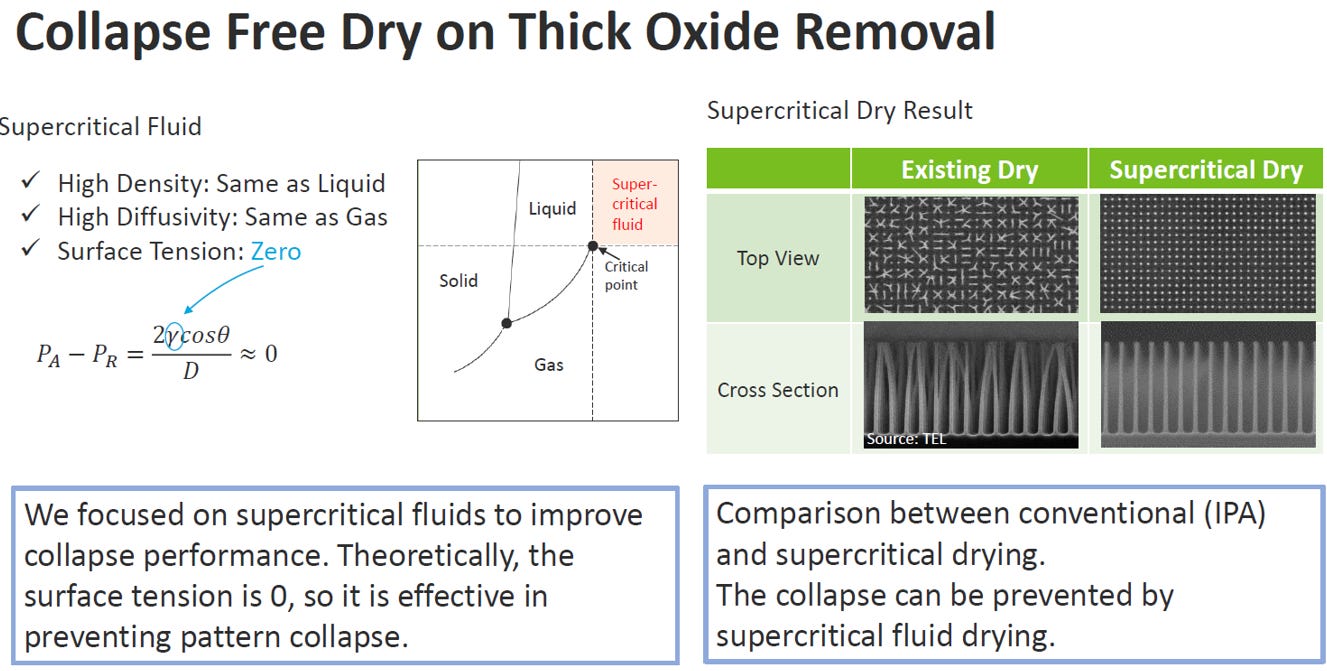
Source: IEDM25 SC2-5
完美解法:超臨界流體乾燥 (Supercritical Dry)
為了解決這個連 IPA 酒精都無法克服的倒塌難題,半導體業界導入了**「超臨界流體 (Supercritical Fluid)」**來進行乾燥。這與食品工業中使用超臨界二氧化碳來「萃取低咖啡因咖啡豆」是完全相同的物理魔法。
咖啡萃取的奧妙: 在咖啡工業中,超臨界流體擁有「氣體的穿透力」可以鑽進堅硬的咖啡豆內部,同時又擁有「液體的溶解力」可以把咖啡因帶出來。
在 DRAM 製程中的應用:
根據圖表說明,超臨界流體同時具備了高密度(如同液體)與高擴散性(如同氣體)的特性。
最關鍵的必殺技:表面張力為零 (Surface Tension: Zero)。因為超臨界流體沒有傳統液體的表面張力,所以前面提到的拉普拉斯壓力就會直接降為零。
最終成效: 既然沒有了拉扯的力量,流體在乾燥退場時就能做到真正的「揮一揮衣袖,不帶走一片雲彩」。從圖表右側的對比圖可以清楚看到,使用超臨界乾燥後,每一個細長的高深寬比電容柱都能完美地直立著,徹底解決了倒塌危機。
3.2.3. High K and Electrode formation

Source: IEDM25 SC2-5
這張圖表總結了 DRAM 電容在最後鍍膜階段,為了解決「越薄越會漏電」的物理難題所採用的創新技術:
核心挑戰: 為了增加儲電量,必須降低「電容等效厚度 (CET)」,但材料(如 ZrOx)變薄通常會導致漏電電流暴增,造成記憶體資料遺失。
創新解法: 在傳統的「底端電極 + High-k 材料 (ZrOx) + 頂端電極」的三明治結構中,額外插入一層極度輕薄(僅 0.7 奈米 / 7A)的 XO(eXtra Oxide) 夾層。
突破成效: 實驗數據證實,這層奈米級的 XO 夾層發揮了關鍵的阻絕作用,成功讓電容在降低 CET 厚度的同時,完全不增加漏電(無漏電懲罰)。
透過多加一層 0.7 奈米的 XO 薄膜,成功讓電容的絕緣外衣變得更薄、儲電效率更高,且完美阻絕了漏電危機。
4. 結論
DRAM 技術的發展已進入「空間爭奪戰」的終極階段 。從 2D 佈局的優化到 4F2 VCT 的垂直化,再到未來 VS-DRAM 的多層堆疊,每一步都在試圖突破馮紐曼架構的物理限制 。
關鍵結論如下:
3D 化是唯一出路:當平面微縮 (Scaling) 遭遇電容高塔倒塌與蝕刻極限時,走向 3D 堆疊是維持容量增長的必然選擇 。
製程與材料並進:除了 EUV 技術的精密化,新材料 (如高介電材料與 XO 夾層) 與特殊乾燥製程 (超臨界乾燥) 已成為維持良率的關鍵技術門檻 。
HBM 扮演短中期救星:在底層 DRAM 結構徹底轉型前,透過 HBM 先進封裝增加通道頻寬,仍是目前解決 AI 記憶體牆的主流方案。
谢谢解释的这么详细的长文。
No where on the internet there is a single piece of information on DRAM process that is this Dense and frost free. Tagging @Vikram Sekar @Irrational Analysis for more reach.