EP32. 資料中心光模組發展趨勢

隨著 AI 算力競賽進入白熱化,光通訊產業正站在 1.6T 世代的關鍵路口。上週有幸參與一場光通訊專家的深度會議,會中不僅剖析了從 800G 跨越至 1.6T 的技術路徑,更揭示了地緣政治如何從『晶片』延伸至『光學材料』的潛在危機。我將這些第一手的產業洞察整理如下,希望能為各位帶來新的啟發,歡迎交流討論。
1. Background
1.1. 市場預估
去年初這位專家預估,2025資料中心800G光模塊需求為2000萬隻,與實際出貨量相當接近。
他在會議上預估今年和明年高速光模塊的出貨量:
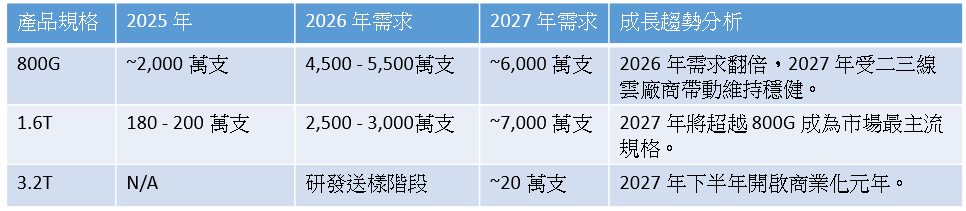
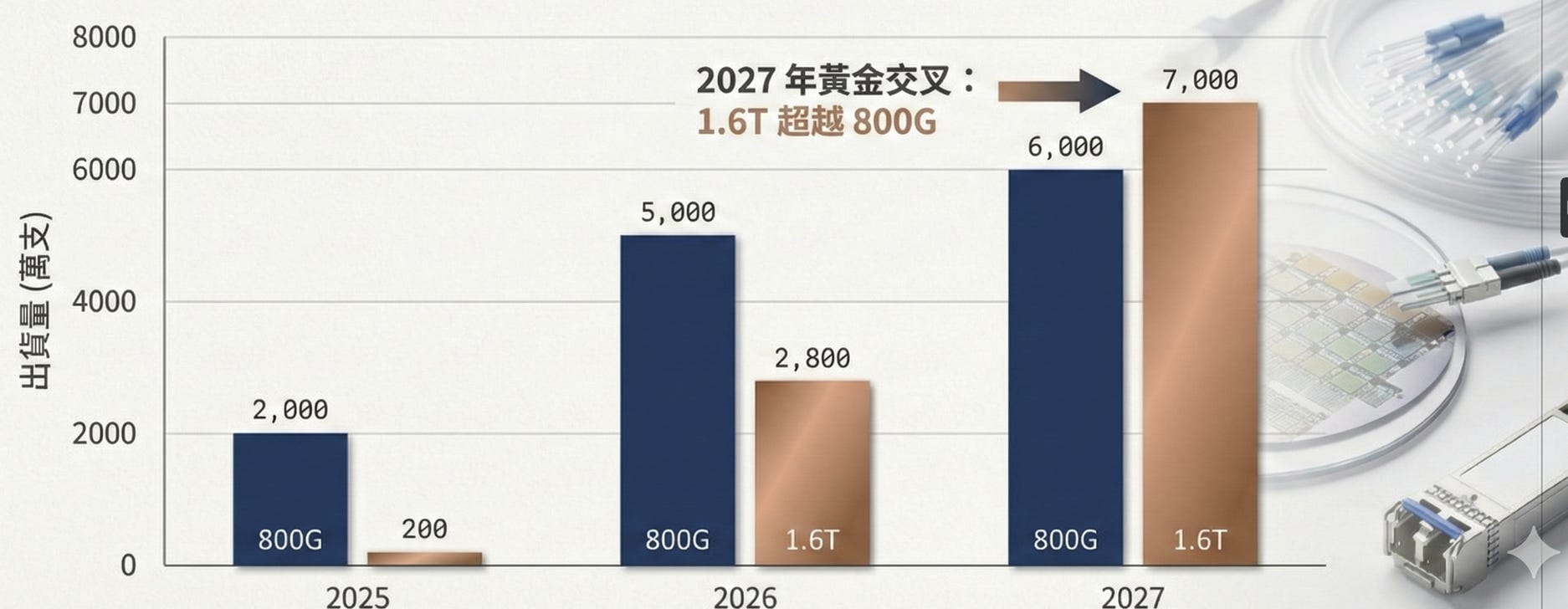
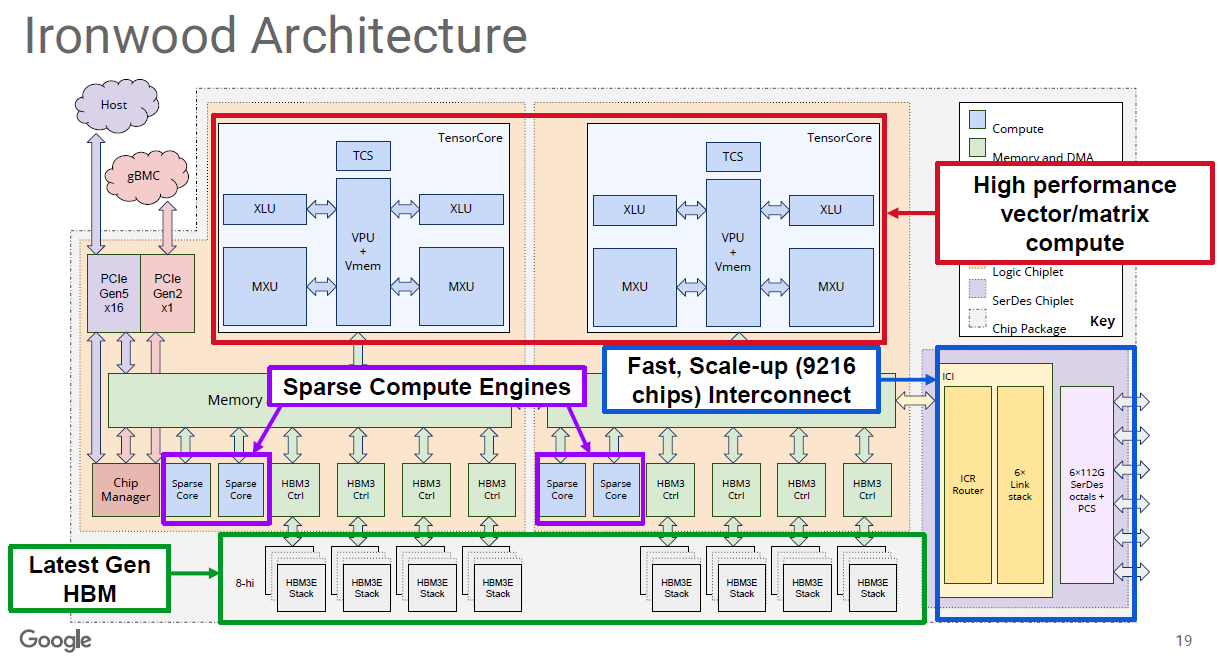
隨著 NVIDIA GB300 或Vera Rubin架構的大規模落地與Google TPU V7 的配套需求,1.6T 光模組正迎來爆發式增長,並與 800G 共同構成當前算力網絡的雙支柱(參考EP31. Vera Rubin AI network簡介;EP26. Google Ironwood)。
Google 是 1.6T 最激進的推動者,預計 2027 年單一客戶需求即達 3,000 萬支。NVIDIA 的 GB300 套件與 OpenAI (預計 2027年獨立採購 1,000 萬支 1.6T) 亦是核心增長引擎。
1.2. 1.6T 技術演進
由於Data Rate翻倍(200G/lane PAM4),許多元件必須升級,以支持這高速信號通訊。其中最重要的元件就是,模組使用的調變器(Modulators)(註1)。
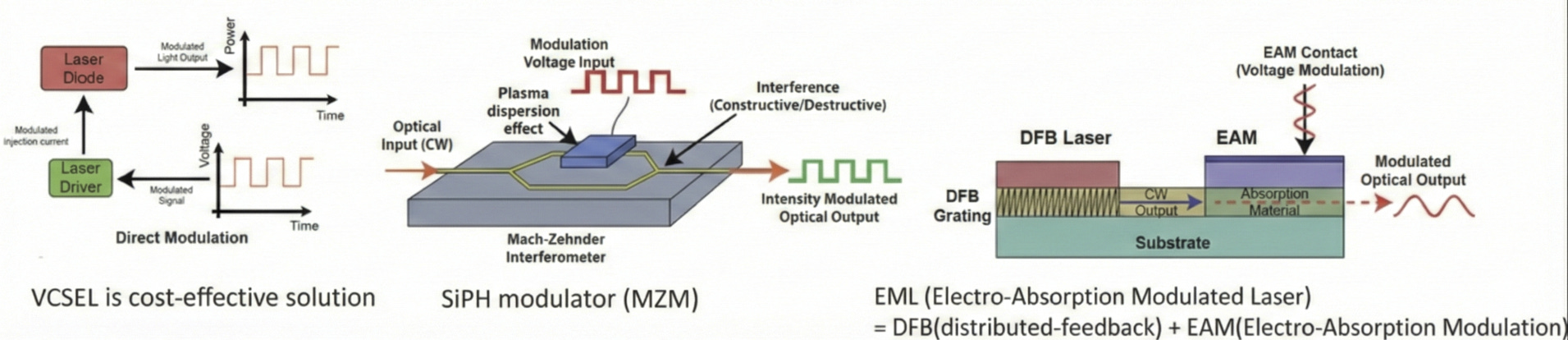
三種主流光調變技術的物理機制,決定光模組成本、功耗與傳輸距離的核心差異:
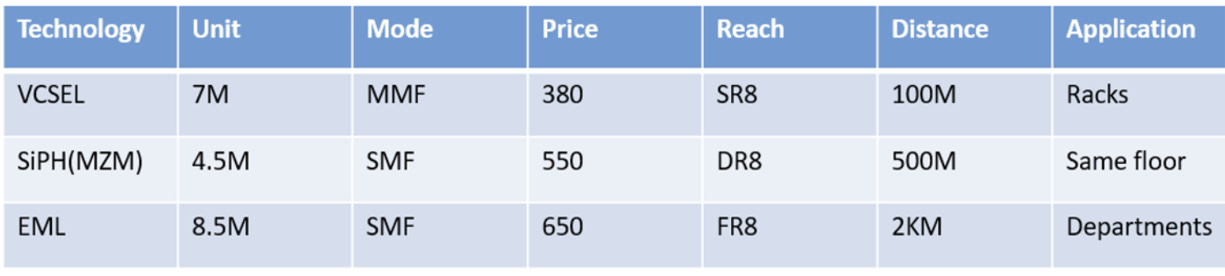
VCSEL (直接調變 Direct Modulation)
簡介: 採用「電流直接驅動」。利用 Driver 直接控制注入雷射的電流大小來產生亮暗訊號(如左圖)。結構最簡單、成本最低,是目前的短距(< 100m)霸主(參考EP9: Light sources)。
200G 可行性: 極低 (面臨物理障礙)。
瓶頸: GaAs 材料的頻寬限制使得 VCSEL 很難突破 50GHz 以上的頻寬(200G PAM4 需要約 56GHz Nyquist 頻寬)。
結論: 雖然有研發多接面 (Multi-junction) 技術,但在 200G 世代,VCSEL 因為頻寬不足與多模光纖色散問題而缺席,主要停留在 800G模組(100G/lane)(註2)。
SiPh MZM (矽光子馬赫-曾德爾調變器)
簡介: 採用「干涉原理」。將光分為兩路,透過電壓改變矽波導折射率造成相位差,最後合波時產生干涉(如中圖),適合中距離。
200G/lane 可行性: 純矽方案可行
現狀: 透過優化行波電極 (Traveling Wave Electrode) 設計與摻雜製程,目前的純矽 (Pure Silicon) 調變器已具備支援 200G/lane (112 Gbaud) 的能力,是 1.6T DR 模組的高性價比選擇。
未來: 更高階的 TFLN (薄膜鈮酸鋰) 技術,因具備超高頻寬特性,則是被視為下一代3.2T模組( 400G/lane) 的關鍵技術路徑。
EML (電吸收調變雷射 Electro-Absorption Modulated Laser)
簡介: 採用「單晶片整合」。整合了 DFB 雷射(持續發光)與 EAM 吸光器(負責開關)。光訊號品質(Eye Diagram)最佳,適合長距離(註 3)。
200G 可行性: 最佳 (成熟首選)。
優勢: EAM 天生具備高頻寬與高消光比 (Extinction Ratio),非常適合對訊噪比敏感的 PAM4 訊號。
定位: 200G/lane 的主流方案,統治長距離 (FR/LR) 市場。
註 1: Modulators for CPO
共封裝光學 (CPO)Modulator(光調變器)的選擇(參考EP27. Marvell + Celestial AI = ?):
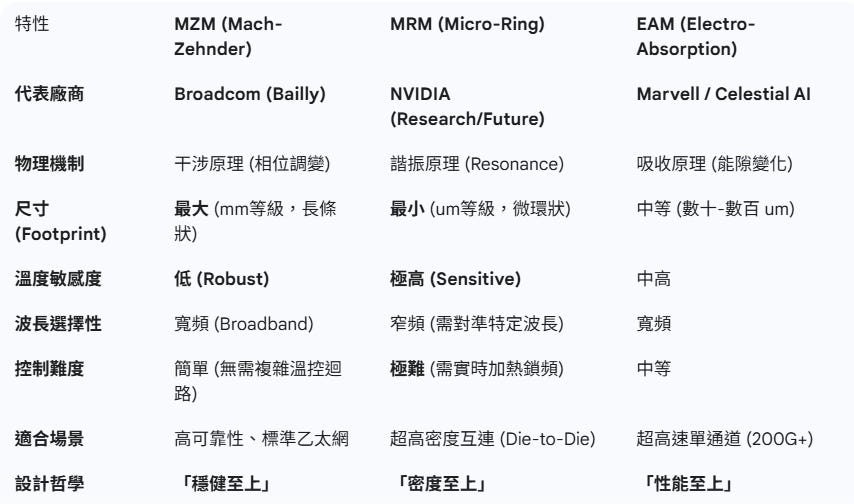
Nvidia Spectrum 6 CPO採用SiPH MRM(純矽),可支援200G PAM4的調變(參考 EP31. Vera Rubin AI network簡介 )
註 2: BRCM 200G VCESL
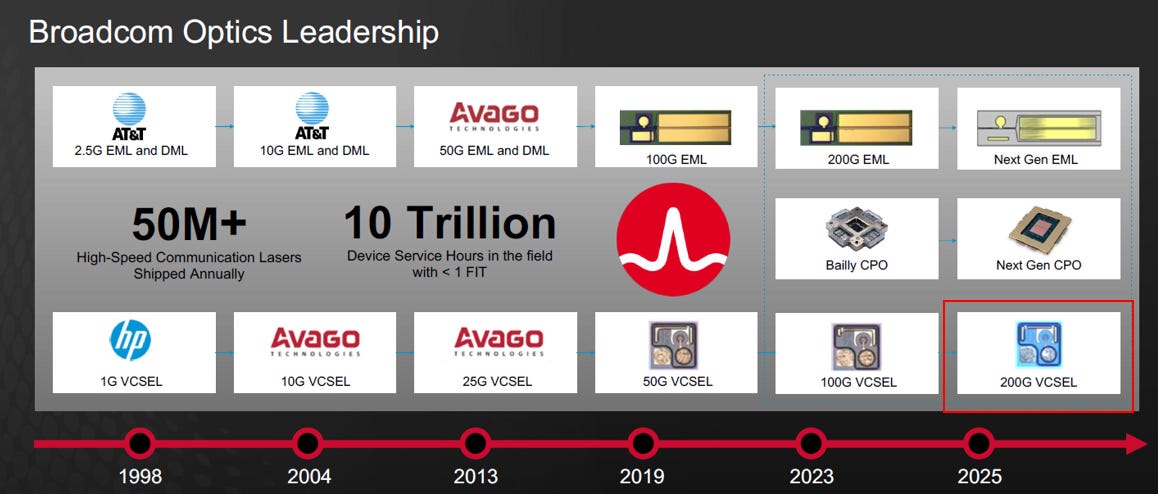
BRCM 作為 VCSEL 霸主,推動 200G VCSEL 是為了延續其在短距市場的高利潤與主導權。Roadmap明確列出了 200G VCSEL 就緒,但在主流的光通訊研討會(如 OFC、ECOC)或分析師的 1.6T 預測中,大家對 200G VCSEL 卻保持「謹慎沈默」或「存疑」,已經排除使用的可行性。
距離縮水,實用性低:
Broadcom 造出了晶片,但在 200G 高速下,多模光纖 (MMF) 的物理色散會導致傳輸距離從 100m 銳減至 30-50m。這對於需要大規模跨櫃互連的 1.6T AI 叢集來說,距離太短,不敷使用。
市場定位被夾殺:
短距 (<10m): 被更便宜的 DAC/AEC 銅纜 拿走。
中長距 (>10m): 必須由 SiPh 或 EML 接手。
結果: 200G VCSEL 卡在中間,失去了標準化大規模部署的戰略位置。
註 3. EML
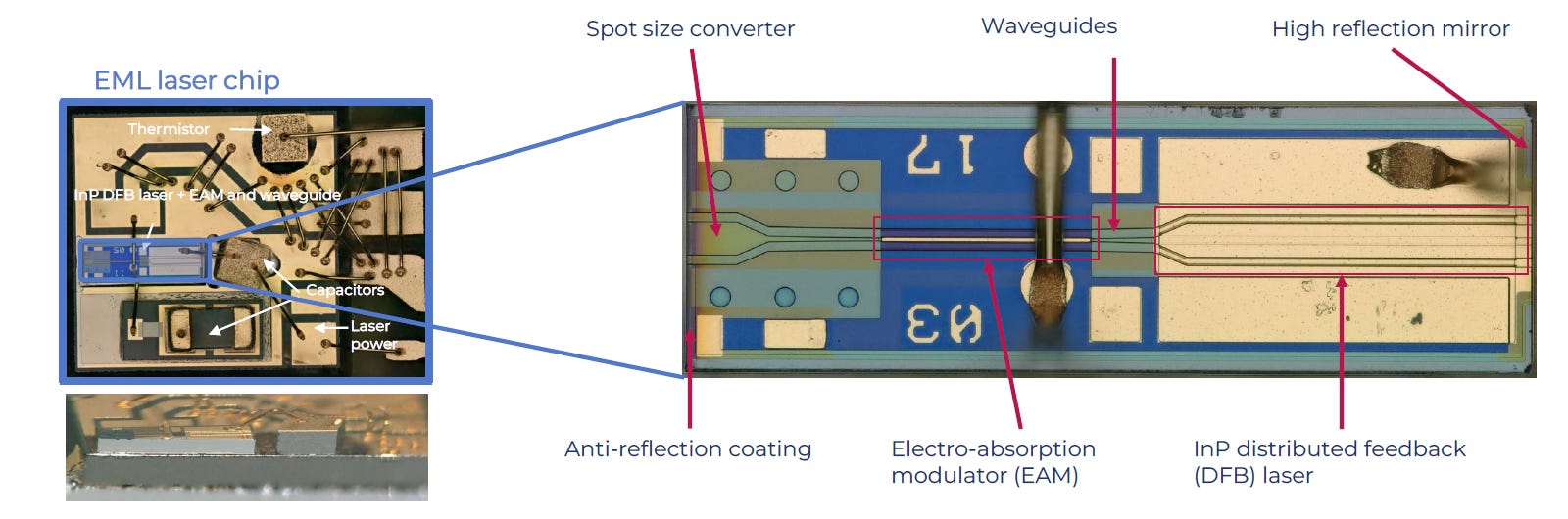
Source: Yole
EML = 燈泡 (DFB) + 快門 (EAM)
DFB (雷射): 負責恆亮(CW, Continuous Wave)。提供穩定、純淨的直流光。
EAM (調變): 負責切光。像百葉窗一樣高速開關,將光變成 0/1 訊號
核心價值:
抗干擾: 光源與開關分離,雷射波長不飄移 (無 Chirp),訊號更清晰。
高速率: 能穩定支援 單波 200G 的技術,是 800G / 1.6T AI 光模組 的心臟。
市場現況:四大寡占
製造門檻極高 (InP 製程),全球200G EML產能主要由以下四家壟斷:
Lumentum (美) - 市佔龍頭
Broadcom (美) - 晶片整合強
Mitsubishi (日) - 高可靠性
Sumitomo (日) - 材料技術深厚
2. SiPH 技術主導
2.1. 資料中心1.6T
針對 1.6T 資料中心 (DC) 應用,矽光子 (SiPh) 之所以能取代 EML 成為主導方案,可歸納為以下三個核心邏輯:
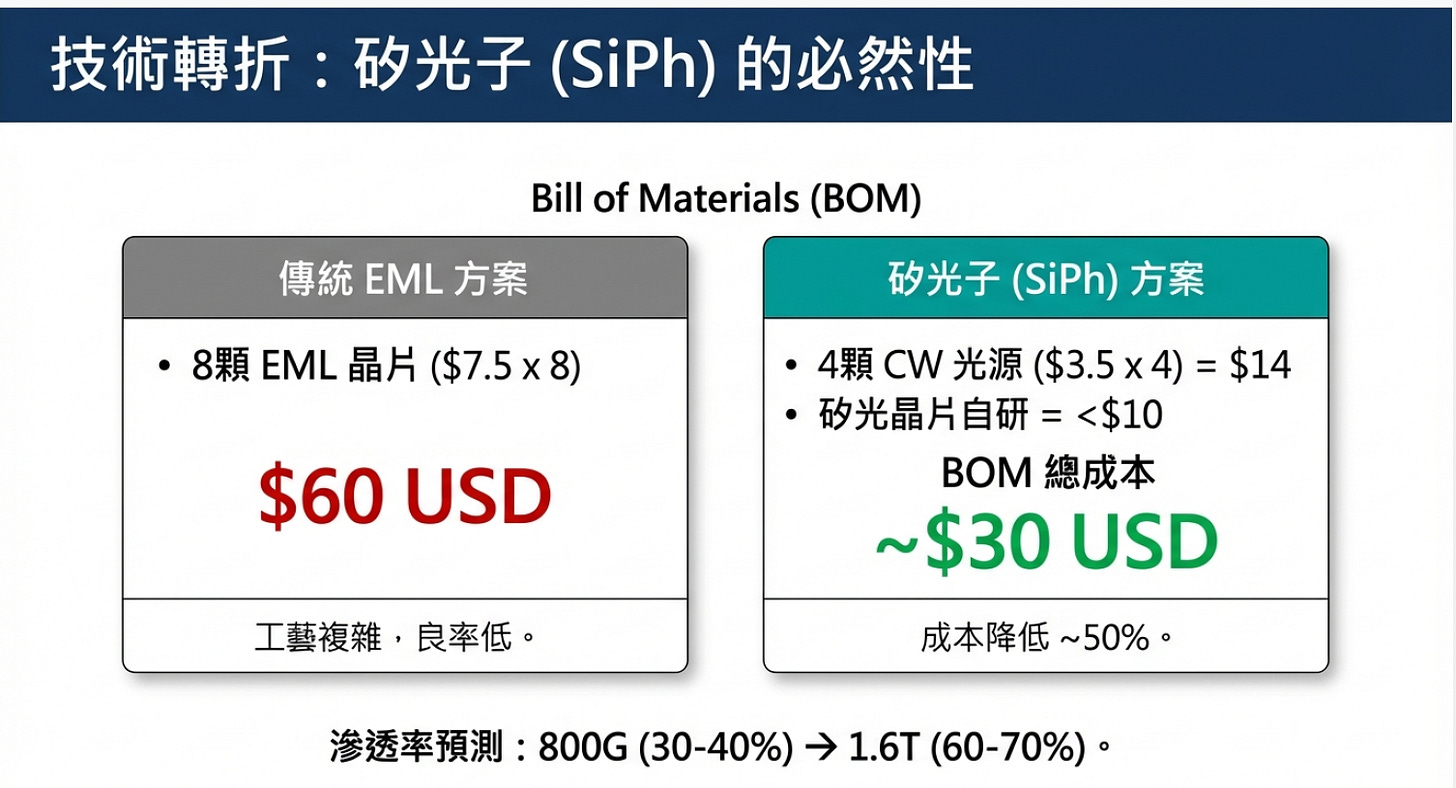
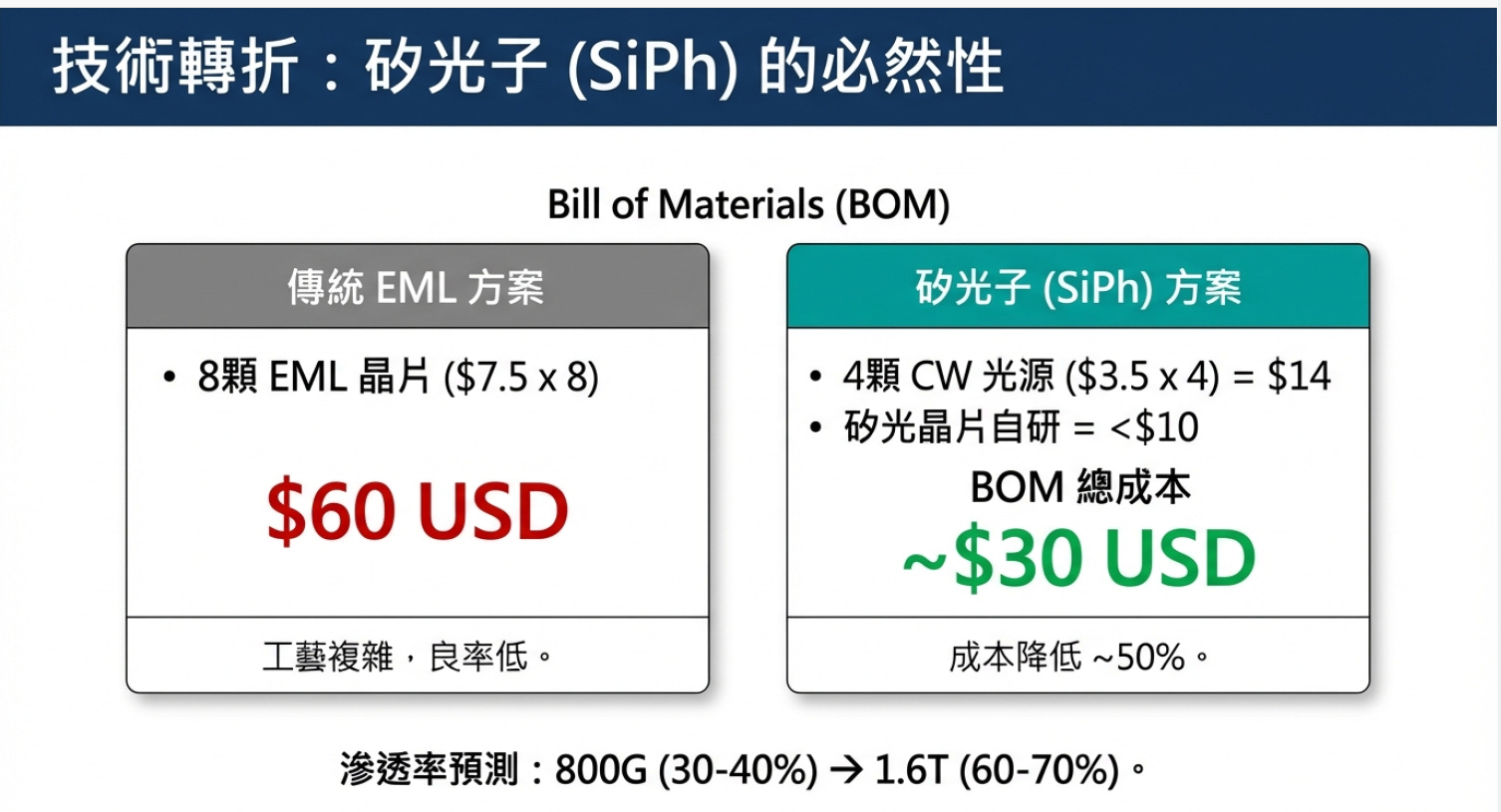
架構帶來的成本紅利 (BOM Cost)
EML (1:1 綁定): 傳統架構需「8 顆 EML 對應 8 個通道」,光學元件成本隨頻寬線性疊加,且 InP 材料昂貴。
SiPh (1:N 共享): 採「光電分離」,1 顆高功率 CW 光源可驅動 2 個通道 (1:2)。在 800G例子中,僅需 4 顆光源即可,大幅降低昂貴雷射的用量,BOM 成本較 EML 降低約 50%。
200G/lambda 的製造量產性 (Scalability)
供應商問題: 單通道 200G 的 EML 供應商稀缺 (僅 4 家),而有眾多CW laser(DFB)供應商,產能不是問題。

CMOS 規模效應: SiPh 的調變器 (Modulator) 使用成熟的 CMOS 製程,擴充通道數簡單,一致性高且產能無虞,解決 1.6T 大規模部署的供應鏈風險。

性能與場景的精準適配 (Performance/Cost Sweet Spot)
Campus 場景 (DR/DR+): 在 AI 叢集主流的傳輸距離(< 2KM)下,不需要 EML 的極致長距離性能
性價比勝出: 雖然 SiPh 物理性能 (光功率/消光比) 略遜於 EML,但透過 高功率 CW 光源 補償損耗,加上 DSP 強大的糾錯能力,其訊號品質已完全滿足此距離需求 (Good Enough)。Hyperscaler 選擇「夠用且便宜」的 SiPh 搭配多芯光纖 (MCF, 參考補充說明),而非昂貴的 EML。
在 1.6T 世代,SiPh 憑藉低成本架構與穩定的 CMOS 產能,擊敗了生產困難的 EML,成為 AI 資料中心短中距離互連 (Intra-DC) 的標準答案。
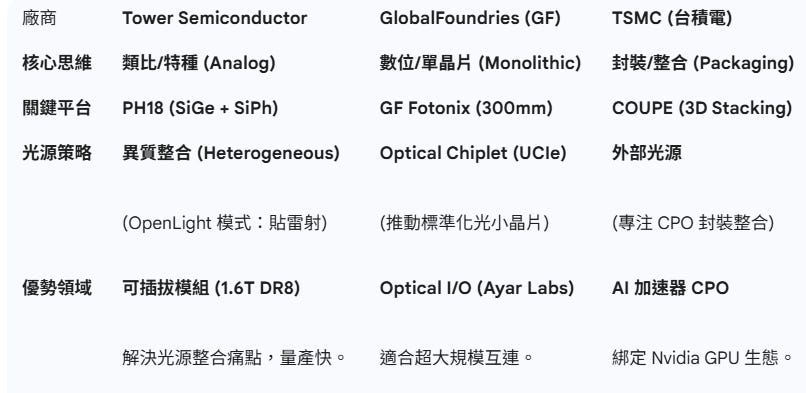
2.2. SiPH代工廠
專家有提到光模組SiPH PIC(Photonic IC)主要代工廠Tower,將要擴充 3倍產能,這是一個很強的市場信號: CPO 雖然是未來,但 Pluggable (可插拔) 才是現在的現金牛。
Tower Semiconductor (類比派):自帶雷射,拼量產
核心技術: 異質整合 (OpenLight提供技術),把雷射直接貼在晶片上 (On-chip Laser)。
戰略目標: 解決光模組廠「封裝雷射」的痛點,降低門檻。
主戰場: 1.6T 可插拔模組 (Pluggable),適合現在就要出貨的訂單
GlobalFoundries (數位派):單晶片,拼標準
核心技術: 矽光 + 邏輯電路單晶片化 (Monolithic),走 300mm 製程。
戰略目標: 推動光通訊變成標準化的「光小晶片」(Optical Chiplet/UCIe)。
主戰場: Optical I/O (如 Ayar Labs),適合超大規模運算互連(參考EP25. UCIe Over Optics)。
TSMC (封裝派):3D 堆疊,拼 AI 效能
核心技術: COUPE (3D 封裝),光電晶片垂直堆疊,雷射放外面 (ELS) 避熱。
戰略目標: 突破 AI 晶片的功耗牆與頻寬極限,深度綁定 Nvidia。
主戰場: CPO (共封裝光學),為下一代 AI GPU 服務
2.3. 需求來源:誰在買 1.6T?
儘管邊緣端 (NIC) 尚未準備好原生支援 1.6T(NIC受限於 PCIe 6.0),但 1.6T 模組需求依然強勁,主要來自兩大推力:
交換器互連 (Spine/Core Layer)
隨著交換器晶片升級至 51.2T 和 102.4T (如 BRCM Tomahawk 6, Nvidia Spectrum 6),前面板密度成為瓶頸
使用 1.6T 模組可將端口數減半 (64 ports),維持 1U/2U 尺寸,解決散熱與佈線密度問題
Breakout 應用
配置模式: 交換器端插 1.6T OSFP —> 光纖分接 —> 連接 2 張 800G NIC
戰略意義: 這是 2026 年需求量的主力。它允許資料中心在不升級 NIC (受限於 PCIe 6.0) 的情況下,先行部署 1.6T 交換網路架構。例如: Nvidia Spectrum 6 Switch 支援1.6T,而CX-9只支援800G
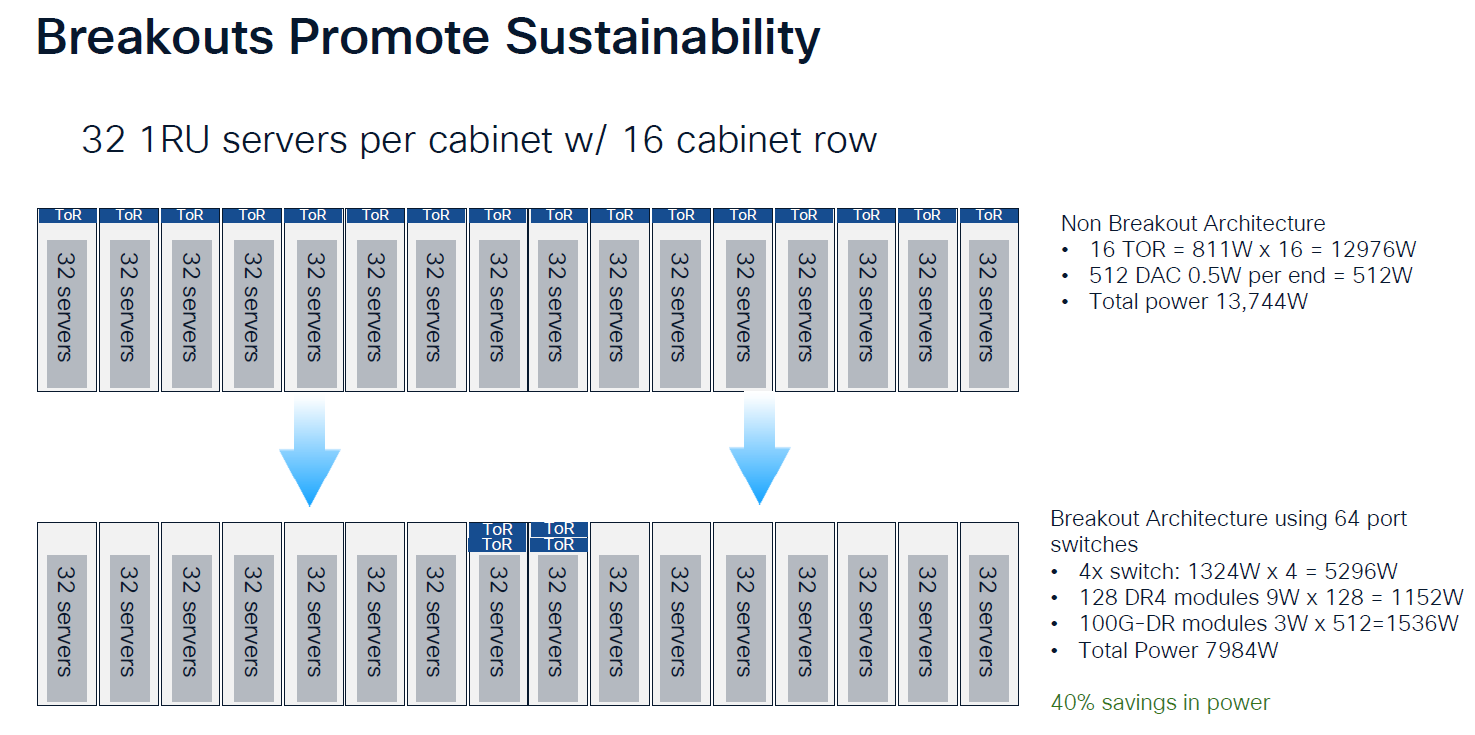
Source: Cisco
High Radix + Breakout 是用「光學模組成本與微幅功耗增加」,來換取「交換器設備大幅減少、網路延遲降低、以及整體系統能效提升」的最佳解方
Google TPU V7 1.6T的應用
專家預估 2027 年單一客戶需求量將達 3,000萬支 (30M),佔全球 1.6T 總需求 (70M) 的近一半。這因為Google TPU v7 (Ironwood) 採用的 OCS (光路交換) + Scale-up (ICI) 架構,使其成為全球 1.6T 光模組需求最激進的推手。為了達到極致的優化,Scale-Up 層級目前必須拋棄標準的 Ethernet(參考EP26. Google Ironwood)。
Source: Google
技術路線:
為了適配 OCS 的端口經濟學與 TPU 的電氣特性,Google 走了一條與 NVIDIA 截然不同的技術路線:
光學層: 必須採用 WDM (波分複用) + BiDi (單纖雙向),而非市面通用的 PSM (DR8),以節省 OCS 端口。
電氣層(猜測): 透過 on board Gearbox (變速機制) IC 解決 TPU 100G SerDes 與 1.6T (200G/lane) 模組之間的速率匹配問題。下一代TPU 應該會支援 200G SerDes。
市場時程:
2026 年為爬坡期,2027 年將迎來「黃金交叉」,1.6T 正式超越 800G 成為主流。
OCS (Optical Circuit Switch) 打破下列限制:
速率無關 (Speed Agnostic): OCS 的 MEMS 鏡片只反射光,不在乎速率。
升級策略: 當 TPU v7 想要上 1.6T 時,不需要更換中間的 OCS 交換機,只需要升級端點的光模組 (Transceiver) 與 Gearbox。這讓 Google 的部署速度遠快於依賴電子交換(EPS)升級的競爭對手。
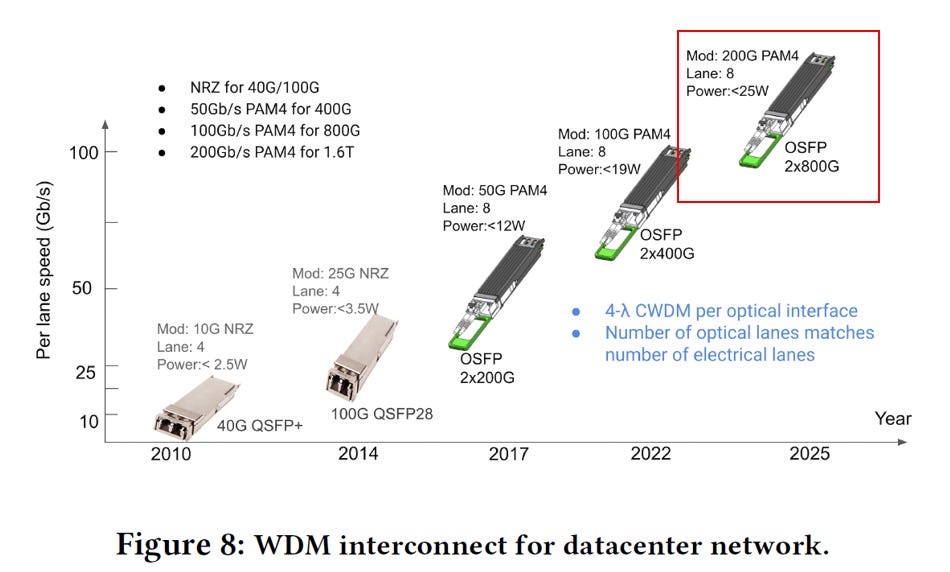
客製化模組:
Source: Google
Google 的 3000萬支需求並非市面上的標準品 (Generic DR8),而是高度客製化的產品:
挑戰: OCS 的端口 (MEMS 鏡片) 極度昂貴且稀缺。若使用標準 DR8 (8對光纖),連接一個 1.6T 節點會消耗 16 個端口,導致 OCS 規模無法擴展
解法: 強制採用 WDM (如 CWDM8) 結合 光環行器 (Circulator)
效果: 將 1.6T 的雙向流量塞進 1 根光纖 (或 2 根),僅佔用 1-2 個 OCS 端口。
供應鏈影響: 模組廠必須具備高精度的 WDM 封裝 與 Circulator 整合 能力。
Google TPU v7 的問世,確立了 “OCS + WDM + SiPH” 在 AI 超級運算領域的重要地位。
兩條平行的 1.6T 賽道:
通用賽道 (NVIDIA/Ethernet Scale-out): 追求低成本、標準化的 SiPH DR8 (PSM)模組
Google 賽道 (OCS Scale-up): 追求極致端口效率的 SiPH WDM + BiDi 模組。
3. 供應鏈風險
專家也提到由於地緣政治導致的材料管制,雖然下游需求強勁,但上游兩大核心原料——用於光隔離器的 稀土材料與用於雷射的 InP Substrate(襯底) ,正深陷中國出口管制的審批泥沼。特別是主力供應商 AXT (通美) 的出口受阻,已造成全球雷射晶片面臨『無米之炊』的斷鏈風險,這將是未來兩年最大的瓶頸。
稀土材料
3.1. Faraday Rotator
光隔離器 (Optical Isolator) 在光通訊模組中的地位,就如同電路中的「二極體」或水管中的「止逆閥」。對於高速光模組,光隔離器的目標:防止反射光(Back Reflection)回到雷射腔體。Isolator 的必要功能是「單向導通,斬斷回波」。它是維持高訊號品質 與保護昂貴雷射晶片。
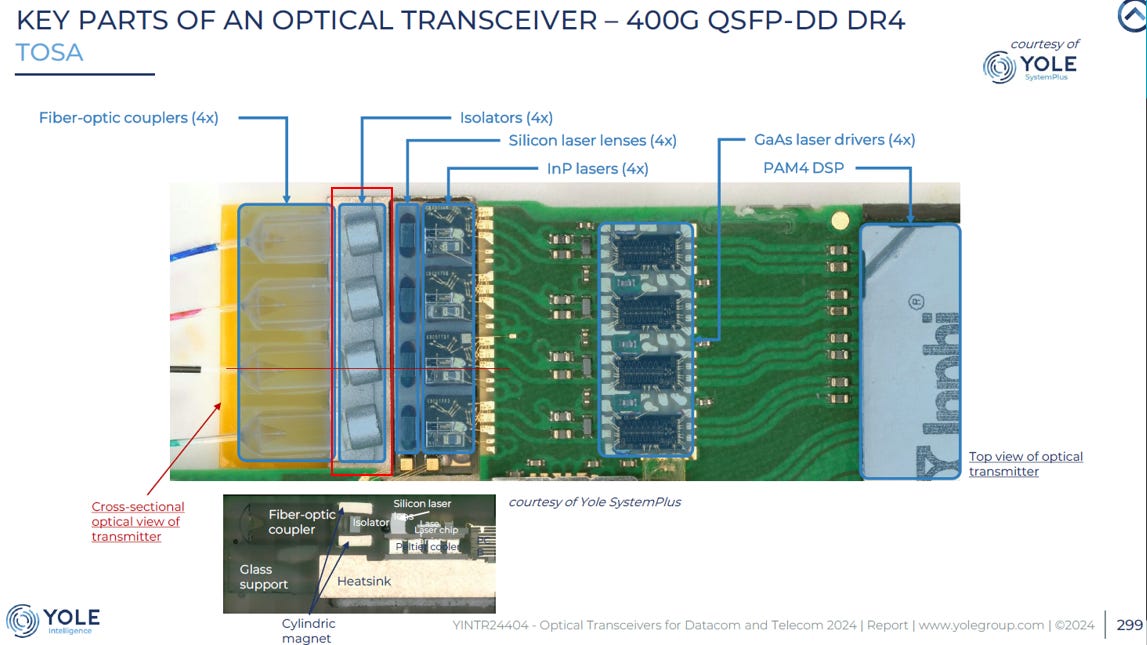
Isolator = 偏振片 A + [ Faraday Rotator ] + 偏振片 B

Source: Yole
正向傳輸 (Forward):通訊訊號 (Pass)
這就像是過三關,目標是讓光順利通過
Input Polarizer (0°): 光進入,被過濾成垂直偏振 (0度)。
Faraday Rotator (45°): 光通過 TGG (Terbium Gallium Garnet,鋱鎵石榴石)晶體。在外圍磁場的作用下,偏振方向被旋轉了 +45度。
Output Polarizer (45°): 出口的偏振片剛好安裝在 45度角。光線角度完全吻合,無損通過。
逆向傳輸 (Backward):反射雜訊 (Block)
利用隔離器磁光效應的「非互易性」(Non-reciprocity)
Output Polarizer (45°): 反射光從尾端進入,首先被濾成 45度。
Faraday Rotator (+45°): 關鍵就在這裡! 一般材質(如旋光糖水)逆向通過會把角度轉回去 (變回 0度)。但法拉第效應的特性是:無論光從哪個方向通過,它都只會往同一個方向旋轉。
所以,原本的 45度反射光,再被旋轉 +45度,變成了 90度。
Input Polarizer (0°): 此時反射光 (90度) 撞上了入口偏振片 (0度)。兩者正交 (Crossed),光線被完全阻擋/吸收。
對應供應鏈風險
Faraday Rotator = TGG Crystal (Terbium Gallium Garnet, 含稀土 Tb, 鋱) + Magnet (含稀土 Sm/Nd, 釤/釹): 這是心臟,負責旋轉光線。沒有稀土(磁光材料),就沒有法拉第旋轉,隔離器就失效了.
Polarizers: 通常是特殊的玻璃利用金屬奈米粒子拉伸或鍍膜製成,雖然對稀土依賴較低,但高品質的偏振片供應商同樣高度集中 (如日本)
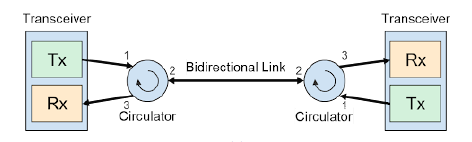
3.2. Circulator
在 Google TPU 的光互連架構(特別是結合 OCS 光路交換器)中,為了將光纖利用率翻倍,Circulator (光循環器) 是實現單光纖雙向傳輸 (BiDi) 的核心。
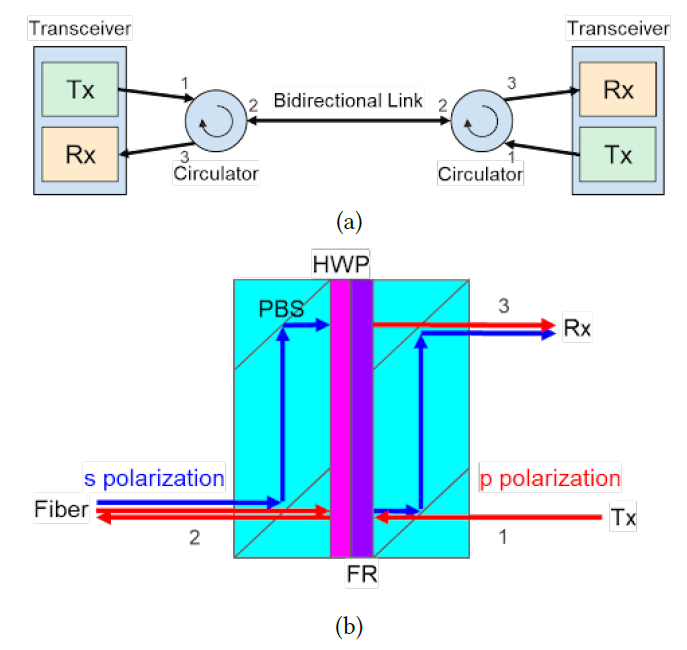
Source: Google
功能:光的「單行道圓環」
機制: 嚴格遵循 「1進2出 (發送),2進3出 (接收)」 的物理路徑。
價值: 實現 BiDi (單纖雙向) 傳輸,讓 TPU 叢集的光纖佈線數量直接減半,大幅降低 OCS (光路交換) 的複雜度。
核心成分:稀土是心臟
運作原理: 依賴 法拉第旋轉器(FR) 來控制光的轉向。
關鍵磁光材料:
轉向 (Rotator): 必用 TGG 晶體,核心是 鋱 (Tb, 重稀土)。
磁場 (Magnet): 必用 釤鈷/釹鐵硼磁鐵,含 釤 (Sm) 與 釹 (Nd)
Google 雖透過 BiDi 技術極大化了光纖效率,但其硬體底層完全依賴中國壟斷的 重稀土 (鋱)。若稀土斷供,Circulator 做不出來,TPU 的 BiDi 架構就會停擺。
InP substrate (磷化銦襯底)
3.3. InP (磷化銦) 襯底製造
極高耗能:用「時間」換晶體
製程極慢: 必須採用 VGF (垂直梯度凝固法),長出一根合格晶棒需耗時 2~3 週 (矽晶棒只需數天)。
持續燒錢: 高溫高壓爐必須 連續 20 天不間斷運轉,導致單片晶圓分攤的電力成本極高。
極低良率:物理特性的惡夢
長晶難 (怕亂): 磷在 1000°C 會瞬間氣化,需 30倍大氣壓 封裝抑制。且溫場稍不穩即產生 「孿晶 (Twinning)」,整根報廢。
加工難 (怕碎): InP 質地 「軟而脆」 (如餅乾),在切割、研磨、拋光過程中極易碎裂,機械損耗率遠高於矽。
極高門檻:環保與工安壁壘
劇毒易燃: 原料涉及 易燃紅磷 與 劇毒磷化氫 (PH3)。
擴產受限: 歐美日環保法規嚴苛,導致擴產審批極慢,產能難以在短期內複製。
中國製造的機會
InP 襯底的製造困難,形成了一道 「高能耗、高污染、高風險、長週期」 的天然屏障
歐美日選擇「棄守」這塊利潤微薄的陣地,而中國選擇將其視為「戰略物資」並利用體制優勢拿下
3.4. InP Platform 供應鏈
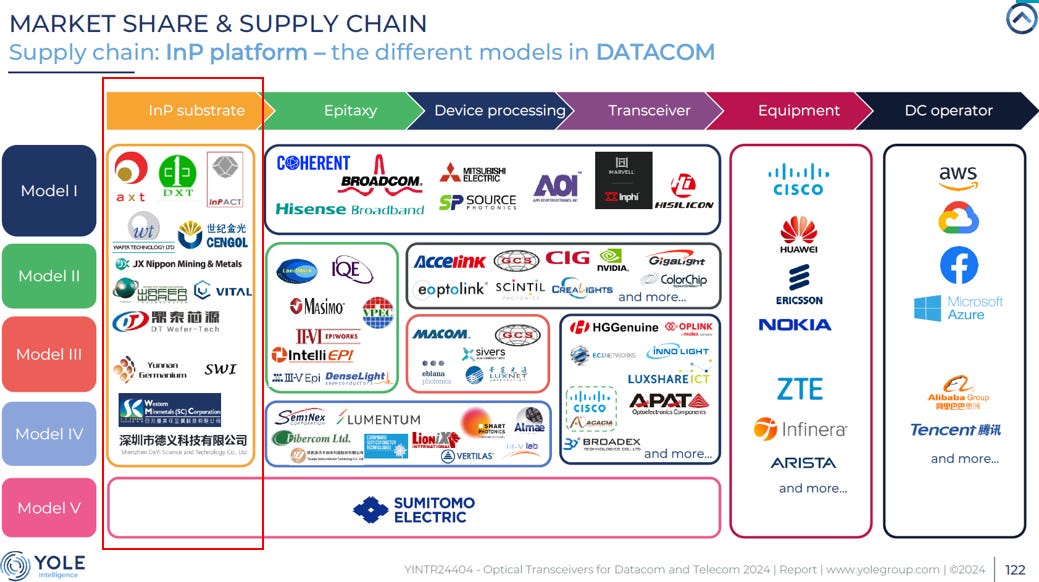
Source: Yole
InP Substrate 供應鏈地圖
安全區 (Non-China, High Volume):
Sumitomo Electric (SEI): 絕對龍頭,也是 Google 最放心的來源。但產能已被各大廠搶光,交期極長。
JX Nippon: 產能較小,專注於特定規格。
灰色區 (China Risk / High Volume):
AXT (Tongmei): 產能最大,性價比最高。但它是「北京製造」,是地緣政治風險的核心。AXT (母公司) 是在美國那斯達克掛牌的「空殼」總部,而 Tongmei (北京通美) 才是它在中國境內擁有所有工廠、技術與產能的「實體」靈魂。
Semicore (中科晶電): Yole 點名的中國新星。如果 AXT 出事,它會接收中國境內的訂單。
精品區 (Non-China, Low Volume):
InPACT (法)、Wafer Tech (英): 品質好但量少。如果是做「實驗室等級」或「利基型」的 1.6T 產品可以考慮,但無法支撐大規模 AI 部署。
Coherent (美): 主要是自用,外賣量取決於它自己的雷射生意好壞。
3.5. InP 襯底供應鏈危機
整理專家的敘述如下:
源頭斷供 (AXT/通美): 全球主要供應商 AXT (北京通美) 預警出口量驟降 30%。
政治干預: 原因並非「做不出來」,而是 中國商務部出口許可審批 變嚴、變慢,實質上形成了軟性出口管制。
全球缺料: 這導致海外雷射大廠 (Lumentum, Coherent) 拿不到晶圓,無法生產足夠的 EML 晶片 來滿足需求。
替代無門 (僵局): 日本供應商 (Sumitomo) 產能早已被搶光;中國本土其他廠商 (如中科晶電) 想出口也面臨同樣的審批紅燈,形成死結。
卡在 「中國發不出貨,海外拿不到貨」 的地緣政治僵局
4. 個人心得
本次會議後,歸納出三個值得關注的產業訊號:
1.6T 的急迫性與黃金交叉
市場對 1.6T 模組的需求比預期更為急迫。預計 2027 年將迎來關鍵的「黃金交叉」,屆時 1.6T 的出貨量將正式超越 800G,成為資料中心的新主流 。在此趨勢下,矽光子(SiPh)憑藉其在 1.6T 世代的成本優勢與大規模量產能力,將取代傳統方案(EML),確立其主導地位 。
CPO 還早,Pluggable 續命
從 CW Laser 的用料狀況與矽光子(SiPh)目前的發展來看,傳統的可插拔模組(Pluggable)生命週期比預期更長。SiPh 透過共享光源架構大幅降低了成本 ,足以應付 1.6T 世代的需求。CPO(共封裝光學)雖然是終極目標,但在 3.2T(單通道 400G,參考EP23. 448G SerDes)遭遇物理極限之前,大規模導入的必要性尚未浮現。眼下,是 SiPh Pluggable 的主場。
地緣政治:從晶片延伸至材料
光模組的兩大基石正成為新戰場:
稀土 (光隔離器心臟): 缺關鍵磁光材料 鋱 (Tb)、釔 (Y) 則無法製造法拉第旋光片。
InP 襯底 (雷射晶片地基): 產能集中於中國,受出口審批卡關。
一旦這兩類原料受阻,即便擁有先進 DSP 晶片,高階光模組產線(特別是 Google 高度依賴 BiDi 架構的 TPU 叢集 )恐將面臨斷鏈危機。
5. 補充說明
5.1. MCF (Multi-Core Fiber)
MCF (Multi-Core Fiber,多芯光纖),這被視為解決下一代 (800G/1.6T) 傳輸瓶頸的關鍵技術。
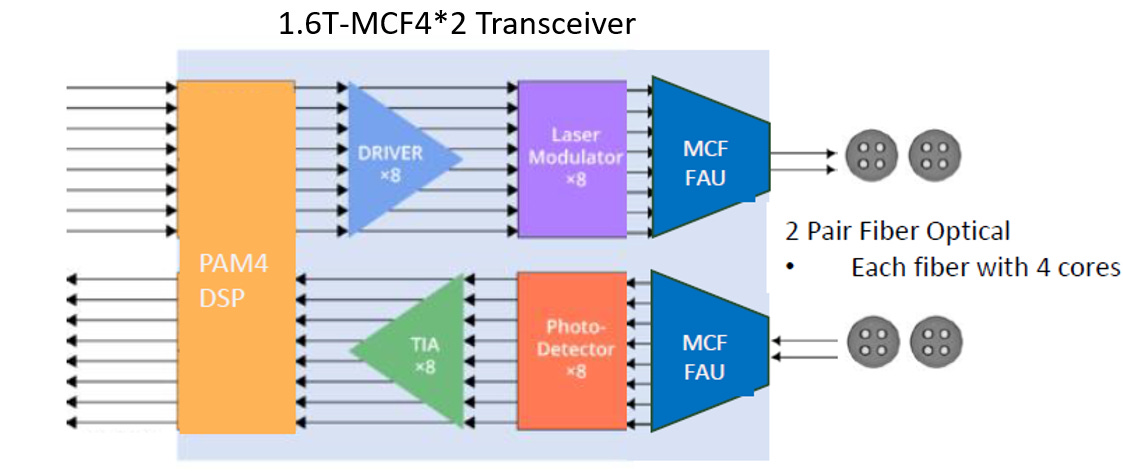

什麼是 MCF? (結構與定義)
傳統光纖 (SMF) 是一根光纖裡面只有一個「核心 (Core)」來導光。而 MCF 則是在標準的 125μm 包層 (Cladding) 直徑內,塞入了多個獨立的核心。
Weakly Coupled (弱耦合):投影片特別強調這是 “Weakly Coupled MCF”。意思是這 4 個核心之間的距離夠遠,彼此的 Crosstalk (串擾) 極低,可以視為 4 條獨立的通道。
兼容性 (Compatible):每一個核心的光學特性都跟傳統單模光纖 (SMF, G.652) 完全一樣。這意味著它不需要重新發明光的傳輸物理,只是改變了「封裝密度」。
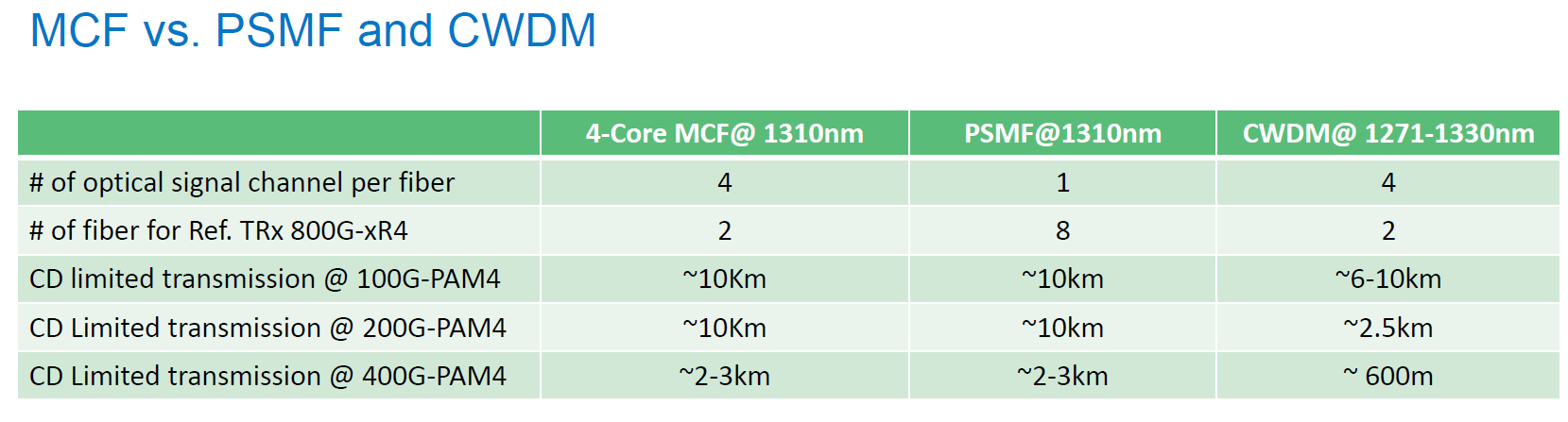
MCF 的兩大戰略優勢
從這張比較表 可以看出,MCF 完美結合了 PSMF 的性能 與 CWDM 的密度,是「魚與熊掌兼得」的方案。
A. 解決物理極限 (vs. CWDM)
這是 MCF 最強大的理由。CWDM 因為使用了 1271nm,在 200G/400G 速率下會撞上色散牆 (Dispersion Wall)。
CWDM:被迫使用不同波長,受限於色散,400G 只能傳 ~600m。
MCF:4 個核心全部都用性能最好的 1310nm(Zero Dispersion ,零色散)。因此,它的傳輸距離表現跟 PSMF 一樣強悍,在 400G 速率下仍能支撐 2-3km,遠勝 CWDM。
B. 解決空間擁擠 (vs. PSMF)
既然 1310nm 這麼好,為什麼不直接用 4 根獨立光纖 (PSMF)?因為太佔空間。
PSMF:要達成同樣頻寬,光纖數量是 MCF 的 4倍 (8根 vs. 2根)。這在 Data Center 內部會造成巨大的佈線災難 (Cable size, weight)。
MCF:密度提升 4 倍。它讓光纜維持輕量化,這對於高密度的 CPO (Co-Packaged Optics) 或 NPO 應用至關重要,因為晶片邊緣的空間 (Beachfront) 非常寶貴
總結:MCF 的定位
簡單來說,MCF 的出現是為了應對 “High Baud-rate” (高波特率) 時代的兩難局面:
想跑得遠 (抗色散),必須用 Single Wavelength (1310nm,Zero Dispersion (零色散))。
想塞得進機櫃 (高密度),必須減少光纖數。
5.2. BiDi(Bidirectional)
BiDi (Bidirectional) 技術在 AI 高速運算網路中的應用,特別是針對 Google TPU OCS 架構的解析。
核心價值與驅動力
隨著 AI 叢集規模擴大,頻寬需求邁向 12.8T 甚至更高,傳統的雙纖單向 (Duplex) 佈線面臨空間與成本的雙重挑戰。BiDi 技術的核心優勢在於:
資源利用率提升 100%:在單一光纖內實現同時雙向傳輸 。
顯著降低成本:被視為實現 High Radix (高基數) 網路的最低成本方案 。
簡化佈線複雜度:以 12.8T 光學引擎為例,所需單模光纖 (SMF) 從 128 根減半至 64 根 。
節省設備埠數:在光電路交換系統 (OCS) 中,能直接節省 50% 的埠數需求
BiDi 技術的兩大主流路徑
A. 波分複用型 (WDM BiDi) 利用不同波長來區隔 Tx 與 Rx 信號
Filter-based (傳統型):利用薄膜濾波器區分兩個寬波段 (如 1270nm 與 1310nm),技術成熟。光譜利用率較低,需要佔用兩段較寬的頻譜 。

Interleaved (交錯型):針對 SiPh (矽光子) 與 MRM (微環調製器) 優化的架構。例如 Lightmatter 方案,使用 200 GHz grid 的多波長雷射,將波長以奇偶數交錯方式分配給 Tx 與 Rx,適合提升晶片端頻寬密度 。波長管理較複雜,需精密的波長交錯控制 。
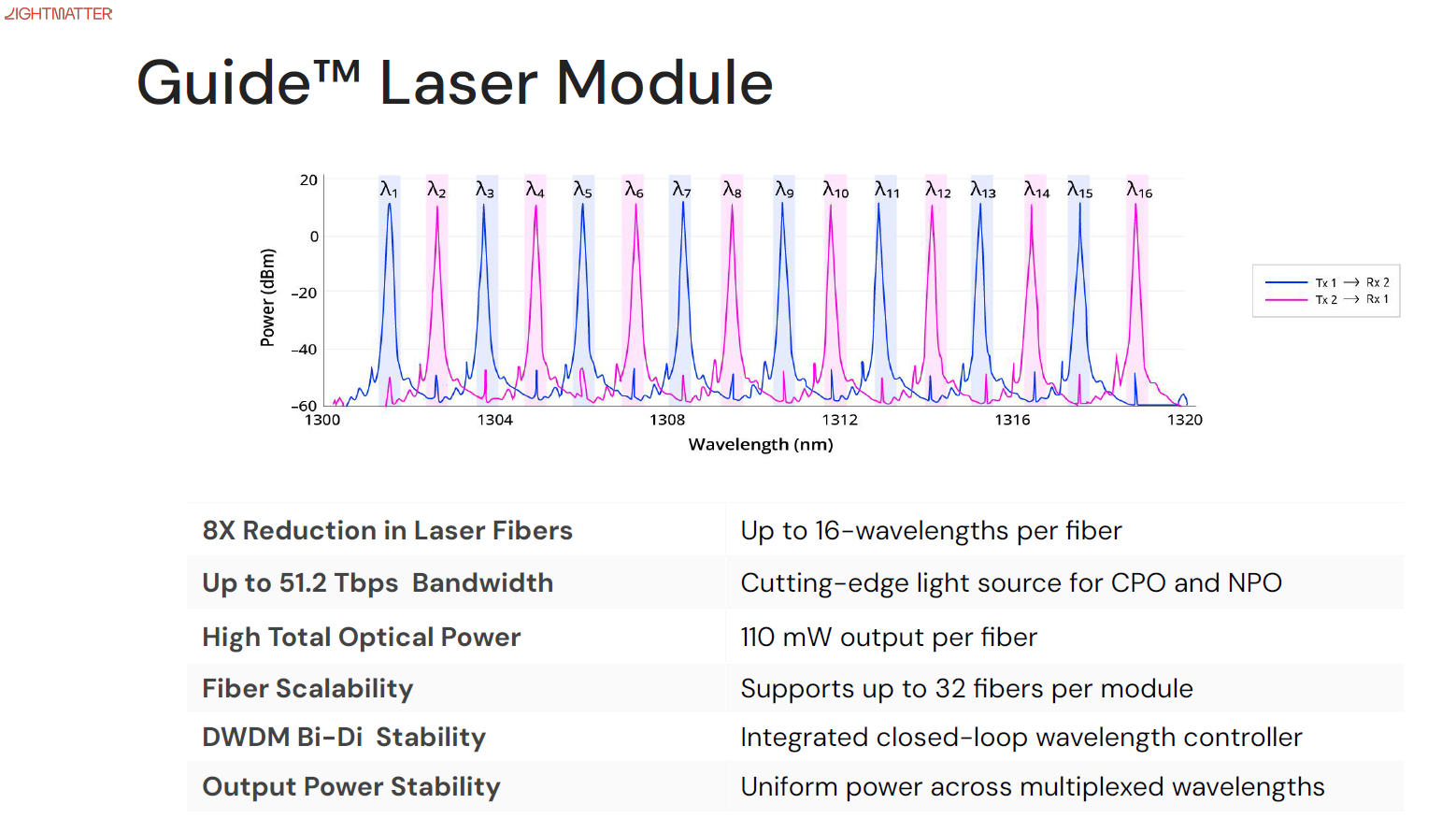
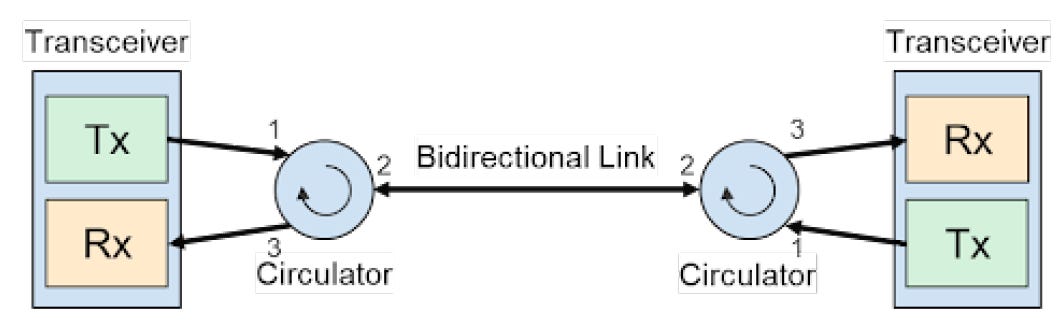
B. 環行器型 (Circulator BiDi) 主要應用於 Google TPU OCS 等場景
核心原理:利用「非互易性 (Non-reciprocity)」來分離光路,而非依賴波長 。
運作邏輯:Circulator 具有循環連接性 (Cyclic connectivity),信號由 Port 1 -> Port 2 (傳輸),Port 2 -> Port 3 (接收) 。
Google 光學架構核心摘要: 雙重技術疊加,極大化 OCS 效率
Google 為了在昂貴且埠數有限的 MEMS OCS 交換器上達成最大連接規模 (High Radix),採用了「BiDi + CWDM」的組合拳:
BiDi (雙向傳輸):將 Tx 與 Rx 整合至單一光纖,直接讓 OCS 埠數需求減半 (相較於 DR/PSM 模式) 。
CWDM (分波多工):在單一光纖內堆疊 4 個波長 (如 4x200G),解決頻寬擴展問題 。
環行器 (Circulator) 帶來的兩大優勢
Google 捨棄傳統 Filter-based WDM BiDi,改用 Circulator-based WDM BiDi ,帶來了兩個決定性的好處:
物理層優勢 (同波長雙向):利用「非互易性」與「偏振」分離信號,允許 Tx 與 Rx 使用 完全相同的波長 進行傳輸,不需佔用雙倍頻譜
運維層優勢 (消滅 A/B 模組):因為不依賴波長區隔方向,所以不需要成對的「Group A (發送波長X) / Group B (發送波長Y)」模組。所有模組皆為 單一料號 (Universal SKU),可任意互連,大幅簡化資料中心的庫存與佈線管理