EP31. Vera Rubin AI network簡介

2026 CES 的重頭戲無疑是黃教主的 Keynote。雖然 CES 傳統上是消費電子的主場,但 NVIDIA 這次發布的 Vera Rubin 平台,其意義遠超過單純的晶片升級 。不是單一晶片的算力提升,而是 NVIDIA 透過『極限協同設計 (Extreme Co-design)』,將六大關鍵晶片融合成了一台『單一 AI 超級電腦』。從 400G SerDes 的物理層突破,到大膽導入 CPO (共封裝光學) 解決銅纜極限 ,Rubin 平台正在重新定義 AI 基礎設施的遊戲規則。這一集,我們就來深入拆解這背後的技術佈局
六大關鍵晶片
NVIDIA 在 CES 推出的 Rubin 平台,核心理念是將六大關鍵晶片整合成「單一 AI 超級電腦(One AI Supercomputer)」,透過極限協同設計(Extreme Co-design)來突破摩爾定律的瓶頸。

Vera CPU:協作處理器,採用 88 個 Olympus 核心 (Arm 架構) 與 LPDDR5。
Rubin GPU:AI 運算核心,算力達 50 PFLOPS,搭載 HBM4 記憶體。
NVLink 6 Switch:400Gbps SerDes,機櫃互連晶片,頻寬 3,600 GB/s,支援 Single Hop 直連。
Spectrum-6 Switch:乙太網路交換晶片,總容量 102.4 Tb/s,採用 CPO (共封裝光學) 技術。
ConnectX-9:高速網卡 (SuperNIC),200Gbps SerDes,單埠頻寬達 800 Gb/s。
BlueField-4 DPU:資料處理單元,整合 64 核 Grace CPU 與 CX-9 網卡功能。
Rubin 平台的關鍵在於「整合」。從 NVLink 6 的 400G SerDes,到 Spectrum-6 大膽導入 CPO ,顯示出 NVIDIA 試圖在物理層面上解決銅纜傳輸的極限,和光互連技術推進。
AI Supercluster (超級叢集)
基於 Vera Rubin 平台 的 AI Supercluster (超級叢集) 實體部署架構,採用典型的「運算—網路—運算」佈局:

兩側:運算單元 (Compute)
配置: 左右各標示為 “8x NVL 72”,即左右各 8 個 NVL72 機櫃,共 16 櫃。
規模: 總計包含 1,152 顆 Rubin GPU (= 16 Racks x 72 GPUs)。
意義: 每個 NVL72 機櫃內部是透過 NVLink 6 銅纜直連(Scale Up)的單一大核心;機櫃之間則需要透過網路層擴展。
中間:網路核心 (Scale out Network)
配置: Spectrum-6 CPO 交換器機櫃。
技術關鍵: 這裡明確標示了 CPO (Co-Packaged Optics),證實 NVIDIA 在 Scale-out (水平擴展) 的乙太網路層,正式導入共封裝光學技術,用來連接兩側龐大的 NVL72 運算群,解決傳統可插拔光模組在這種高密度互連下的功耗與散熱瓶頸
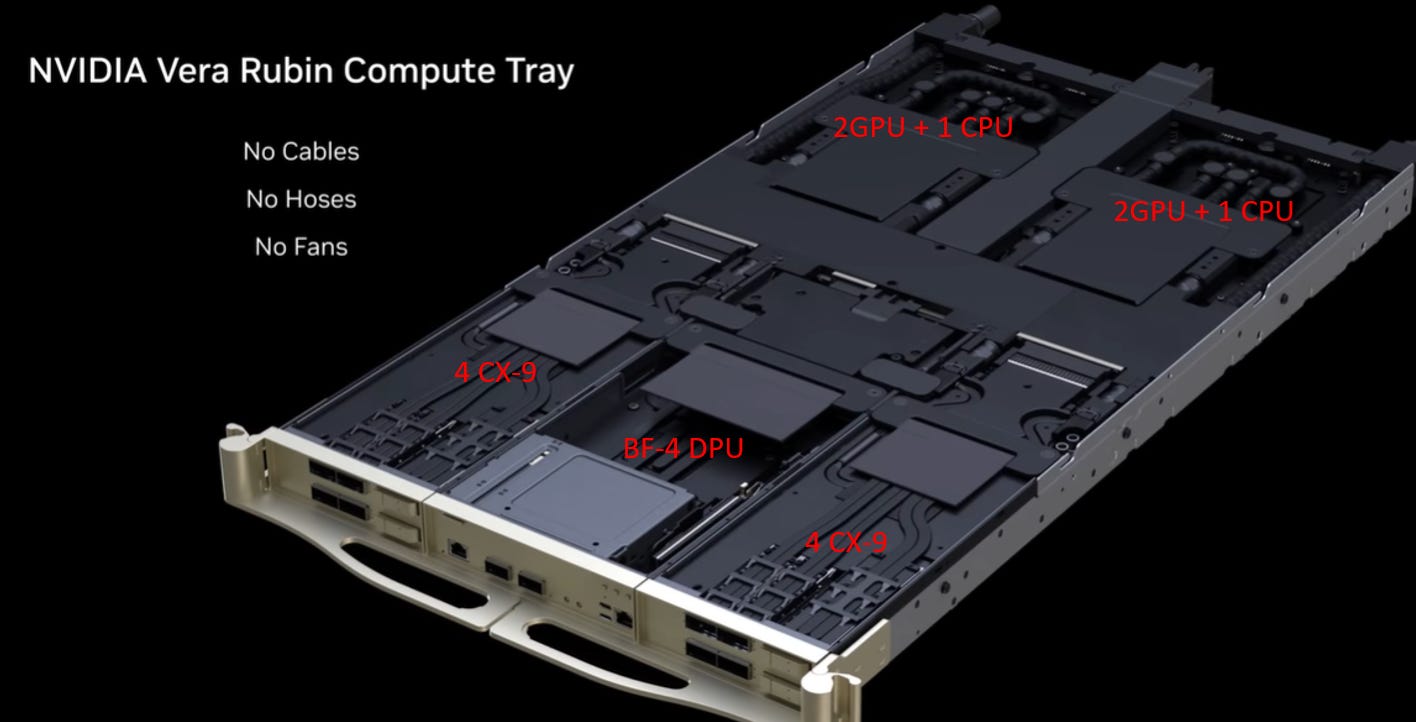
Compute Tray
Vera Rubin Compute Tray 的設計延續了 NVL72 的高密度理念,但在運算與網路頻寬上進行了顯著升級。

運算密度:雙 Superchip 配置
配置: 單個 Tray 包含 2 組「Vera Rubin Superchip」模組。
總核心數 (Per Tray): 2 顆 Vera CPU + 4 顆 Rubin GPU。
記憶體: 結合了 Rubin 的 HBM4 與 Vera 的 LPDDR5,形成統一記憶體架構。

Scale-Out 網路 (水平擴展):1.6Tbps Per GPU
硬體: 搭載 8 顆 ConnectX-9 (CX-9) SuperNIC。
拓撲配比: 採用 2:1 的配比,即每一顆 Rubin GPU 搭配 2 顆 CX-9。
頻寬: 每顆 CX-9 提供 800 Gb/s,因此每顆 GPU 擁有 1.6 Tbps 的專屬 Scale-out 頻寬。
技術細節: 這裡的底層採用了 200G PAM4 SerDes 技術。

Front-End 網路 (南北向/管理):
硬體: 中央配置 1 顆 BlueField-4 (BF-4) DPU。
功能: 負責儲存、安全卸載及管理流量,提供 800 Gb/s 頻寬(Shared with 2 CPUs or 4 GPUs),確保運算核心專注於 AI 工作負載。

機構設計:三無設計 (No Cables, No Hoses, No Fans)
Tray 內部完全無纜線、無水管、無風扇。
這意味著電源 (Busbar) 與液冷 (Manifold) 全部採用盲插 (Blind-mate) 設計,極大化了散熱效率並降低了維護時的人為故障風險。
Switch Tray
核心配置:單 Tray 四晶片 (4 ASICs)
佈局: 如圖 6 所示,每個 Tray 搭載 4 顆 NVLink 6 Switch 晶片。
驗證: 9 個 Trays × 4 顆 = 36 顆 Switch 晶片/機櫃,完美對應 72 顆 GPU 的互連需求。
晶片規模: 每顆 Switch 晶片擁有 1060 億個電晶體。

關鍵技術突破:400G SerDes
規格:圖中紅框明確標示採用 “400G SerDes”(參考 EP23. 448G SerDes)
意義: 相比於 Blackwell (NVLink 5 200G SerDes),Rubin 平台將 SerDes 速率翻倍至 400Gbps。這使得每條 Lane 的頻寬大幅提升,從而實現單顆 GPU 3.6 TB/s (= 36 x 400 x 2 /8)的總吞吐量。
互連架構:Scale-Up Fabric
功能: 提供機櫃內 GPU 的 All-to-All 全互連。
SHARP 技術: 支援 In-Network SHARP Collectives,這意味著 Switch 晶片本身具備運算能力,可直接在網路層處理集合通訊(如 All-Reduce),減少數據在 GPU 與 CPU 之間來回搬運的延遲(參考EP17. Scale-Up Ethernet(SUE)簡介)。
物理連接:高密度盲插 (HD Connector)
設計: 針對400G SerDes高速信號,使用 High Density (HD) connector(參考 EP23. 448G SerDes)
特點: 這種連接器專為 NVLink 6 的高頻信號設計,位於 Tray 的後方,用於直接與機櫃背板(Backplane)進行 盲插 (Blind-mate) 連接,完全摒棄了傳統纜線 (No Cables),以確保 400G 信號在銅背板上的完整性。

NVL72 機櫃「脊椎 (Spine)」

5,184 條 NVLink Spine (銅纜背板)
物理核心:貫穿整座機櫃的巨大銅質背板,負責連接所有的運算與交換托盤。
關鍵技術:採用 盲插 (Blind-mate) 設計,完全 無纜線 (No Cables),解決了傳統佈線的複雜與損耗問題。
戰略目的:利用銅導體實現機櫃內的極速互連,讓 72 顆 GPU 在物理上合體為 「單一巨大 GPU」。
這 5,184 條(= 72x36x2) 像微血管一樣密布在那個金色的盲插背板中,是讓 72 顆晶片融為一體的關鍵通道。
Rubin 頻寬翻倍,線數卻沒變? Rubin 的總頻寬 (3.6 TB/s) 是 Blackwell (1.8 TB/s) 的兩倍,但它透過升級 SerDes 速度 來維持相同的佈線密度
Ethernet CPO Switch
Spectrum-6 Ethernet Switch,它是 Rubin 平台負責 Scale-Out (水平擴展) 的核心交換器,用來將多個 NVL72 機櫃串連成超大型叢集。

關鍵技術:CPO (共封裝光學)
突破點: 這是 NVIDIA 首度公開展示的 Ethernet Co-Packaged Optics 交換器。
光引擎: 內部整合了 200G Silicon Photonics (矽光子) 引擎,直接封裝在 Switch ASIC 旁,解決了電訊號長距離傳輸的功耗與衰減問題。
性能怪獸:102.4 Tb/s 交換容量
晶片規模: 擁有驚人的 3,520 億 (352 Billion) 個電晶體。
總頻寬: 提供 102.4 Tb/s 的交換容量,是目前單晶片乙太網路交換器的頂峰( (和BRCM TH6 相當)。
連接規格:
物理層 (Physical): 配置 64 個 1.6 Tb/s 端口(每個端口包含 2 組 MPO-12 接頭,共 128 組光纖介面)。
邏輯層 (Logical): 透過 Breakout 模式提供 128 個 800 Gb/s 鏈路。

用途:
對接網卡: 每一路 800G 鏈路精準對應一張 ConnectX-9 (800G) 網卡(每個 Compute Tray 有 8 張 CX-9,剛好佔用 switch 的 4 個 1.6Tbps 端口)。
架構目的: 實現機櫃間 (Rack-to-Rack) 的 Scale-Out 水平擴展,建構超大規模 AI 叢集網路。
Spectrum 6是Quatum-X800(InfiniBand) CPO的改進版:

Quantum-X800 (Blackwell 世代)
總容量:28.8 Tb/s。
光引擎:16 顆 (每顆 O/E = 1.6 Tbps)。
策略:無冗餘 (全配)。
Spectrum-6 (Rubin 世代)
總容量:102.4 Tb/s。
光引擎:36 顆 (每顆 O/E = 3.2Tbps)。
策略:有冗餘 (32運作 + 4備用)。為了確保量產良率,允許封裝過程中有少量引擎失效而不影響整顆晶片出貨。
但是CES 最新展示的 Spectrum-6 CPO 確實已定案為 32 顆 O/E。這代表 NVIDIA 採取了 「Zero-Spare (零實體備用)」 的量產策略,展現了對矽光子封裝製程的強大自信。
網路頻寬分析
Scale Up Network: 記憶體互連 (Memory Fabric)
核心技術: NVLink 6, NV Switch
頻寬規格: 3.6 TB/s (Bidirectional per GPU, 2x36x400Gbps/8)
技術突破:
業界首度導入 400Gbps SerDes (推測PAM6 ),OIF 448G規格制訂要加油了(參考 EP23. 448G SerDes)!
相較於 Blackwell 世代 (1.8 TB/s),頻寬翻倍,旨在解決 MoE 模型巨大的 All-to-All 通訊需求。
支援 NVL72 架構下的 72 GPU 全互連單一記憶體空間
Scale Out Network: 運算互連 (Compute Fabric)
核心技術: ConnectX-9 (CX-9) SuperNIC / Spectrum-6 Switch
頻寬規格: 1.6 Tbps (Per GPU, by two CX-9)
SerDes 規格: 200Gbps PAM4
物理瓶頸分析 (PCIe 6.0 Limitation):
儘管網卡支援 1.6 Tbps (約 200 GB/s 單向),但受限於 Host 端的 PCIe 6.0 x16 匯流排速度 (約 1.024 Tbps單向)
此限制促使 NVIDIA 更傾向於推廣 Chip-to-Chip (C2C) 的 Superchip 設計以繞過 PCIe 瓶頸。
Front End Network: 管理與儲存互連 (Management Fabric)
核心技術: BlueField-4 (BF-4) DPU
頻寬規格: 800 Gbps
配置拓樸: 資源共享架構 (Shared Architecture)
1 DPU : 4 GPU (or 2 CPU)
透過 1:4 的配比,BF-4 集中處理 Compute Tray 內的南北向流量、儲存卸載 (Storage Offload) 與資安加密,釋放 GPU 算力
頻寬比例分析 (Bandwidth Proportionality)

架構法則 (Rule of Thumb)
Scale Up : Scale Out : Front End = 100 : 10 : 1
此比例 (72:8:1) 顯示了 AI 叢集設計的核心哲學:記憶體頻寬是絕對優先級,其次是跨節點頻寬,最後才是管理頻寬
光互連技術變革
Spectrum-6 交換器的推出,標誌著 CPO 技術從實驗室走向大規模量產的轉折點,將普及時間點從預測的 2027+ 提前至 2026。
光引擎架構 (Optical Engine Architecture)
為了在極高密度下維持散熱與訊號完整性,NVIDIA 採取了與傳統矽光子不同的激進路線(BRCM O/E用MZM,參考:EP27. Marvell + Celestial AI = ? 介紹MZM, EAM, MRM的差異; EP14. SiPH MRM介紹)
調變器 (Modulator): Microring Resonator (MRM)
特徵:200G PAM4 MRM(註1)
優勢: 尺寸極小,大幅提升頻寬密度
波長策略 (Wavelength Strategy): Single Lambda (PSM)
配置: 不使用 WDM (波分複用)(註2),每條光纖傳輸單一波長
效益:
Less IL (Insertion Loss): 不用 MRM具備的 MUX/DeMUX 特性,降低光路損耗,提升能效
Easy Temperature Control: 避免了 WDM 系統中需同時鎖定多個 MRM 波長的極端熱控難度
註1: TSMC MRM frequency Response:
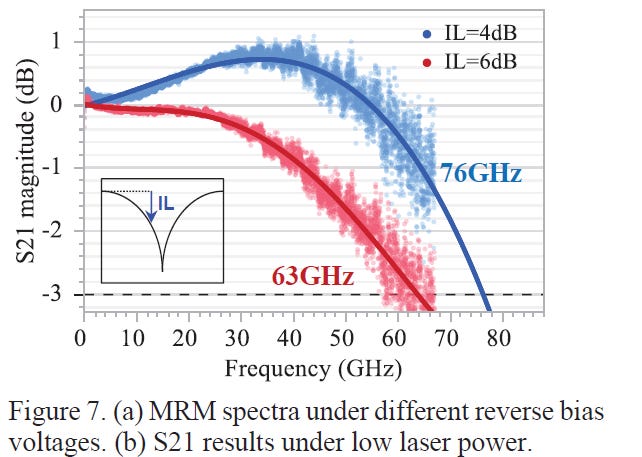
數據硬實力:圖中顯示該元件的 3dB 頻寬介於 63 GHz 至 76 GHz 之間。
物理門檻:要跑 200G PAM4 (100GBd),依據 Nyquist 定理僅需約 53-56 GHz 的頻寬。
結論:TSMC 的 MRM 頻寬顯著超標,證實其物理層技術已完全能夠駕馭 NVIDIA Spectrum-6 CPO 所需的 200G 傳輸速率
註2: TSMC特別強調MRM的WDM特性
個人心得
400G SerDes 提早到位
NVLink 6 採用的 400G SerDes 規格令人驚艷 。原本業界預期這還需要一段時間孵化,但 NVIDIA 為了達成單顆 GPU 3.6 TB/s 的吞吐量,激進地將 SerDes 速率翻倍 。這對 OIF 等標準制定組織來說是巨大的壓力,也意味著 PCB 材料、連接器(如 HD Connector)與訊號完整性技術必須同步跟上 。
CPO 正式邁入量產
Spectrum-6 交換器正式導入 CPO,標誌著這項技術不再是實驗室的產物,而是進入了「大量佈署」階段 。特別值得注意的是 NVIDIA 在量產策略上的自信——採用「32 顆 O/E 運作、零實體備用 (Zero-Spare)」的設計 。這顯示其對 TSMC COUPE 等先進封裝製程的良率已有極高把握,將 CPO 的普及時程從 2027 年提前至 2026 年 。
SiPH MRM 駕馭 200G PAM4
過去對微環調變器 (MRM) 的質疑在於其頻寬限制。但依據 TSMC 的測試數據,其 MRM 的 3dB 頻寬已達 63-76 GHz ,依據 Nyquist 定理,這完全足夠支撐 200G PAM4 (100GBd) 所需的 ~53 GHz 頻寬需求 。這證明了矽光子 MRM 在超高速訊號調變上的可行性。
Single MRM 勝過 WDM
雖然 WDM (波分複用) 在光譜效率上更佳,但在 Rubin 這一代,NVIDIA 選擇了 Parallel Single Mode fiber(PSM, e.g., DR4) 搭配 Single MRM 的路徑 。這是一個務實的工程取捨:放棄 WDM 可以避開 MUX/DeMUX 帶來的額外插損 (Insertion Loss) ,同時解決了多波長MRM 陣列極其困難的熱控制 (Temperature Control) 問題 。
補充資料
需要多少台Spectrum 6 CPO switch(SN6810-LD) ?

基礎參數確認
總需求頻寬: 1152 GPUs x 1.6 Tbps = 1843.2 Tbps
單台 Switch 容量 (SN6810-LD): 102.4 Tbps (Spectrum-6, 128x800G or 64x1.6T)
理論最少台數: 1843.2 / 102.4 ≈ 18 台
但這只有在「把所有 GPU 插在一台超級 Switch 上」才成立
為什麼實際數量遠多於 18?
為了連接 1152 顆 GPU 並達成 Non-blocking (無阻塞) 傳輸,標準架構會採用 Leaf-Spine (Fat-Tree) 拓樸。這意味著 Switch 必須將其頻寬「對半切」:一半接 GPU (Downlink),一半接上層 Switch (Uplink)
第一層:Leaf Switch (ToR)
連接限制: 一台 SN6810 雖然有 102.4T 頻寬 (約 64 個 1.6T Port),但為了無阻塞,它只能用 32 個 Port 接 GPU,另外 32 個 Port 必須保留給上行 (Uplink)
所需數量:
1152 GPU / 32 (Downlink Ports/Switch) = 36 台
第二層:Spine Switch (骨幹層)
連接需求: 這 36 台 Leaf Switch 的上行頻寬,需要由 Spine Switch 來承接交換。
總上行頻寬: 36 台 x 32 Ports x 1.6Tbps
所需數量:
(36 x 32) / 64 (Ports/Switch) = 18 台
總計數量 (Total Switch Count)
Leaf (36) + Spine (18) = 54 台
為了支撐 1152 顆 GPU 的 1.6T 全速運轉,實際部署的 SN6810-LD 數量大約在 54 台左右,這與圖中展示的視覺相符