EP29. PCIe 7.0 Update

最近看到介紹PCIe 7.0的文章,剛好手邊也有些資料,整理一下知識,分享個人心得,歡迎討論。
1. Background
1.1. PCIe發展
PCI 匯流排是PCIe前身,於 2000 年代初期,由於 3D 遊戲圖形卡、Gigabit 乙太網路與高清多媒體 的頻寬需求激增,導致採用「並列傳輸 (Parallel)」與「共享頻寬」的 PCI 匯流排,因物理上的時脈偏移 (Clock Skew) 難以同步,加上嚴重的串音干擾,最終撞上了頻率天花板 。
為了突破此物理極限,業界才轉向 SerDes (串列器) 技術,將架構徹底改為「點對點串列傳輸」的 PCIe,利用嵌入式時脈解決同步難題,這項為了應付當時多媒體吞吐量而做的底層革命,恰好提供了極佳的擴展性,才為二十年後海量數據的運算奠定了傳輸基石。

Source: Keysight
PCIe 的發展可以簡述為以下三個關鍵趨勢:
速度呈倍數增長:
從 2003 年 PCIe 1.0 的 2.5 GT/s 起步,每一代的速度大致翻倍,直到預計 2024-2027 年推出的 PCIe 7.0,速度將達到 128 GT/s。
技術迭代加速:
圖中指出代與代之間的更新間隔縮短了 1/3,特別是從 2017 年 (4.0) 到 2019 年 (5.0) 再到 2022 年 (6.0),顯示創新步伐正在加快
複雜度與編碼變革:
隨著速度提升,技術複雜度和測量挑戰也隨之增加。PCIe 6.0 和 7.0 的波形從原本單一的眼睛(NRZ 編碼)變成了三個堆疊的眼睛(PAM4 編碼),這是為了在高頻下維持頻寬成長所採用的新技術。
1.2. PCIe的規格文件
PCIe 三大核心規範文件的定位與用途,呈現從「理論設計」到「產品實作」再到「驗證」的流程:
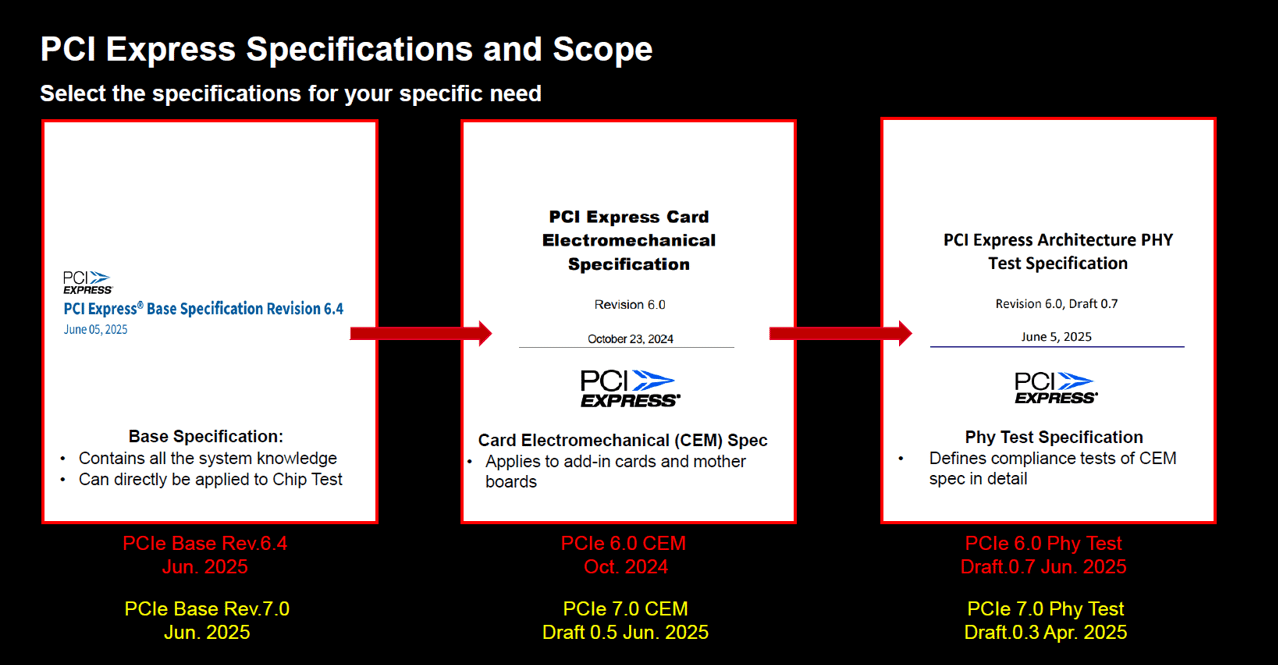
Base Specification (基礎規範):
定位: 技術核心與理論基礎。
用途: 包含完整的系統知識,直接應用於晶片 (Chip) 層級的設計與測試。
受眾: IC 設計與 IP 開發者。
CEM Specification (卡類機電規範):
定位: 產品實作標準。
用途: 定義機構尺寸、連接器與電力規範,適用於開發介面卡 (Add-in cards) 與主機板 (Motherboards)。
受眾: 系統廠、板廠硬體工程師。
PHY Test Specification (實體層測試規範):
定位: 驗收與認證標準。
用途: 詳細定義針對 CEM 規範的相容性測試 (Compliance Tests) 步驟與標準。
受眾: 測試工程師與認證實驗室。
先由 Base Spec 定義晶片怎麼做,再由 CEM Spec 定義板卡怎麼造,最後用 Test Spec 來驗證產品的合規性 (Compliance)。
目前PCIe 7.0 的晶片規範已經 ready(2025 Jun.),但系統硬體設計與測試驗證的標準還在「施工中」
1.3. PCIe架構
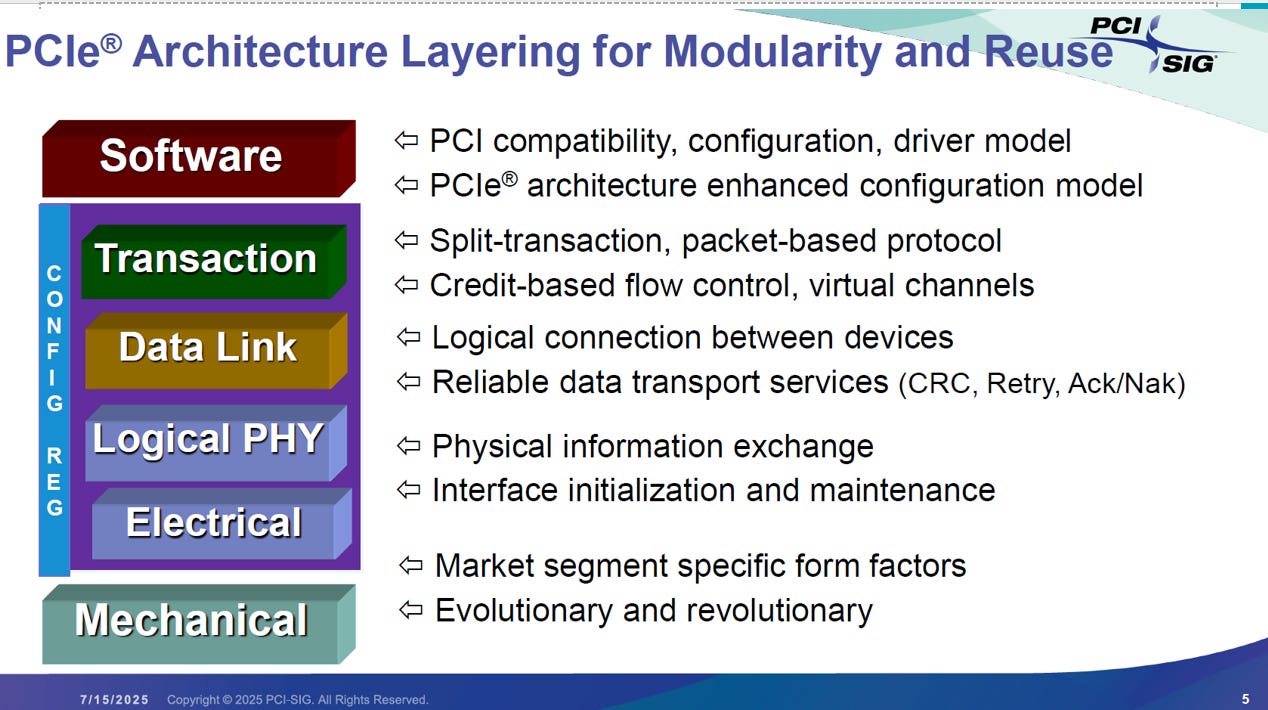
PCIe 採用類似網路 OSI 模型的分層架構 (Layering),其核心設計哲學是模組化,確保底層硬體升級(如速度翻倍)時,上層軟體完全不用修改。
軟體層 (Software)
向下相容: 維持與舊式 PCI匯流排 完全相同的驅動程式模型 (Driver Model) 與配置空間,讓作業系統無縫接軌。
交易層 (Transaction)
運籌帷幄: 負責建立封包 (TLP,Transaction Layer Packet)。採用 Split-transaction 機制(發送請求後不需原地等待回應)以及 Credit-based 流量控制(確認對方有空間才發送),大幅提升匯流排效率。
資料鏈結層 (Data Link)
數據保全: 負責確保點對點傳輸的可靠性。透過CRC 校驗、Ack/Nak 確認機制以及錯誤重傳 (Retry),保證資料正確。
實體層 (Physical - Logical & Electrical)
硬體實作: 負責底層訊號處理。包含邏輯子層(負責鏈路初始化與維護)以及電氣子層(處理實際的電壓與類比訊號交換)。
機構層 (Mechanical)
外觀形式: 定義插槽、板卡尺寸等物理規格。
1.4. PCIe 7.0 關鍵指標 (Key Metrics)
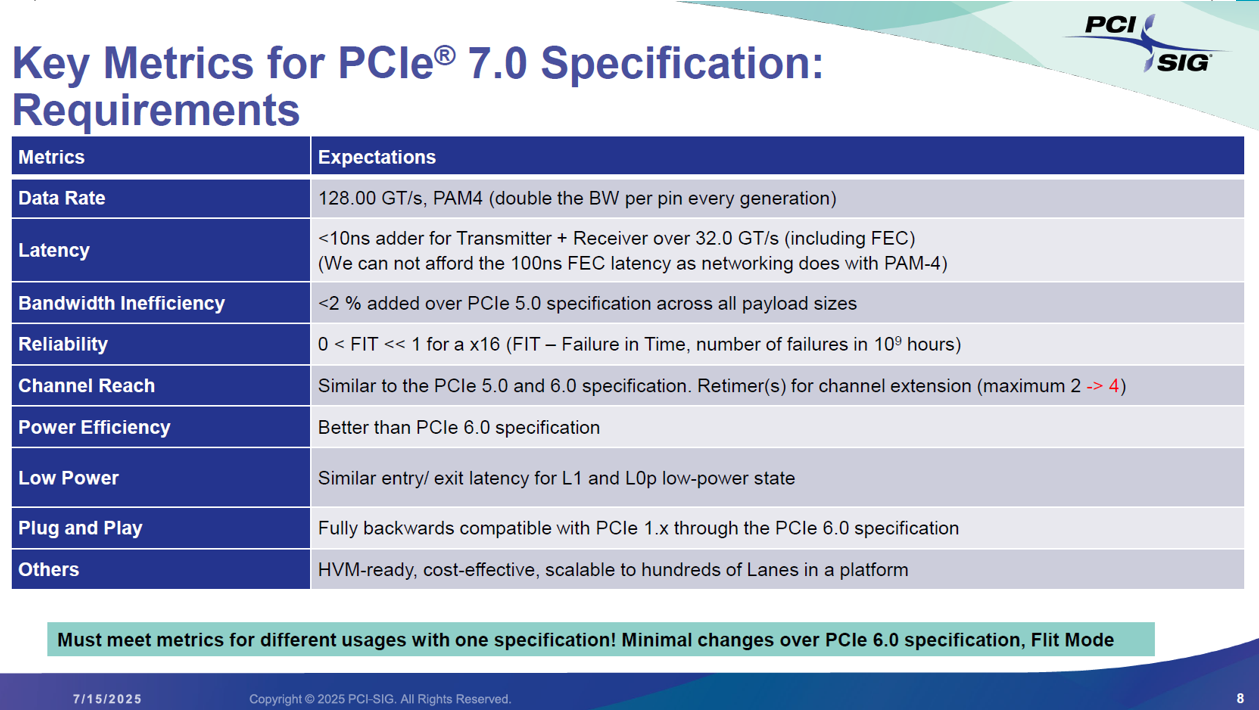
對於系統設計者來說,PCIe 7.0 的核心訊息是:「要在頻寬翻倍的同時,死守低延遲與高可靠度。」這與乙太網路 (Networking) 的發展路徑有顯著不同 。
速度與調變 (Data Rate)
128 GT/s (PAM4): 延續 PCIe 6.0 的 PAM4 調變技術,再次將每條通道的頻寬翻倍。
延遲 (Latency) —— 最艱鉅的挑戰
這點是 PCIe 7.0 與 800G 乙太網路最大的分水嶺:
拒絕高延遲 FEC:PCIe 無法負擔像網路通訊那樣高達 100ns 的 FEC (前向糾錯) 延遲 。
嚴苛指標: 即使加上了 FEC,發送端 + 接收端的延遲增量 (Adder) 必須控制在 <10ns (相較於 32 GT/s 的 PCIe 5.0)。這意味著必須使用極輕量級的 FEC 演算法。

傳輸距離與拓撲 (Channel Reach)
物理極限的妥協: 由於頻率太高,PCB 傳輸損耗極大,單靠板材已難以維持長距離傳輸。
Retimer 數量倍增: 為了延伸訊號距離,規範允許的 Retimer (重計時器) 串接數量上限從原本的 2 顆增加到了 4 顆 (maximum 2 -> 4)。這直接增加了系統設計的成本與複雜度。
效率與可靠度 (Efficiency & Reliability)
頻寬效率: 儘管引入了複雜的 PAM4 和 Flit 編碼,協議開銷 (Overhead) 造成的頻寬損失被限制在 <2% (相較於 PCIe 5.0)。
超高可靠度 (FIT): 要求 FIT (Failure In Time) << 1,即在 10 億小時內的故障數遠小於 1,這對伺服器等級的穩定性至關重要。
總結
PCIe 7.0 的目標是在維持 PCIe 6.0 架構的基礎上,透過更強的訊號處理與更多的 Retimer 輔助,將速度推向 128 GT/s,同時嚴格限制延遲以滿足 CPU/GPU 記憶體存取的需求。
1.5. FLIT (Flow Control Unit) 編碼模式
過去 PCIe (Gen 1-5) 的資料傳輸是「變動長度」的封包,但為了適應 PAM4 高誤碼率環境下必須使用的 FEC (前向糾錯),PCIe 6.0/7.0必須改用「固定長度」的容器來傳輸,這個容器就是 FLIT編碼模式。FLIT (Flow Control Unit) 主要位於 實體層 (Physical Layer) 的 邏輯子層 (Logical PHY)。

結構:256 Byte
為了配合 FEC 演算法運作,FLIT 採用固定的大小,其內部配置極為精實:
TLP (236 Bytes): 資料載荷區。不管是大封包還是小封包,統統裝進這裡,空間利用率極高。
DLP (6 Bytes): 鏈路管理區。負責傳遞 Ack/Nak 與流量控制 (Credits) 資訊。
CRC (8 Bytes): 偵測區。負責抓錯,保證能偵測到任何小於 8 Bytes 的數據損毀。
FEC (6 Bytes): 修復區。採用三路交錯設計,每組可修正 1 Byte 的錯誤。
目的:低延遲糾錯
簡單高效: 使用簡單的 FEC 編碼/解碼邏輯,目的是為了達到低延遲 (Low Latency) 並減少晶片面積。
固定模式: 一旦鏈路啟用 FLIT 模式,即使降速運作也會繼續使用此格式,不會切換回舊模式。
運作邏輯
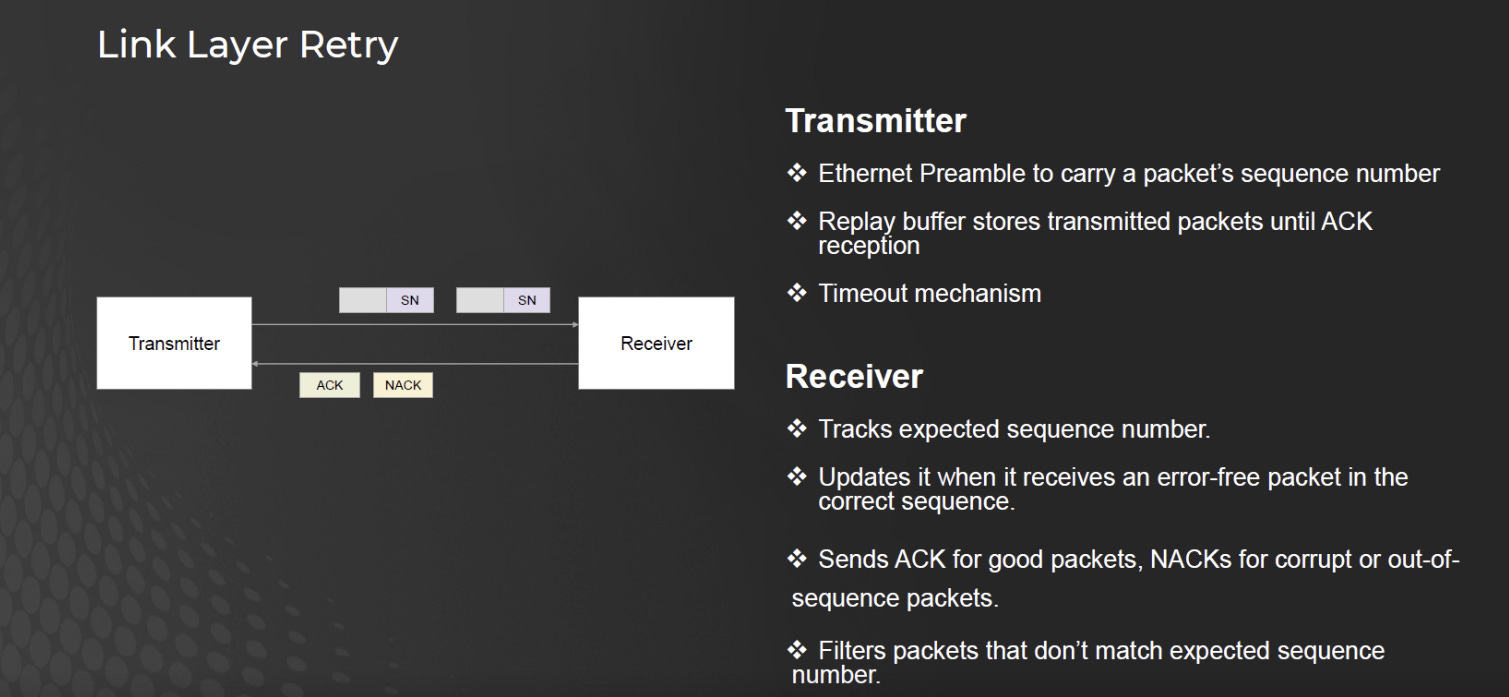
資料收到後,先由 FEC 修正,再由 CRC 偵測。如果 CRC 發現 FEC 修不好(或修壞了),則直接要求 Retry (重傳)。
將重傳機制 (Retry) 下沉至 PHY/Link Layer 是效率最高的做法。相比之下,Ethernet 若依賴上層軟體進行端對端重傳,將產生毫秒級的來回延遲,導致 GPU 因等待數據同步而閒置。
因此,UEC (Ultra Ethernet Consortium) 採用硬體級的 LLR (Link Level Retry) 機制,和PCIe 6.0/7.0類似,直接利用底層晶片進行重傳 ,避免整條傳輸路徑的頻寬浪費,滿足「無損」且低延遲的傳輸品質。
1.6. 挑戰
PCIe 7.0 面臨的挑戰是「在物理極限下,強行兼顧速度、延遲與成本」的三難局面。
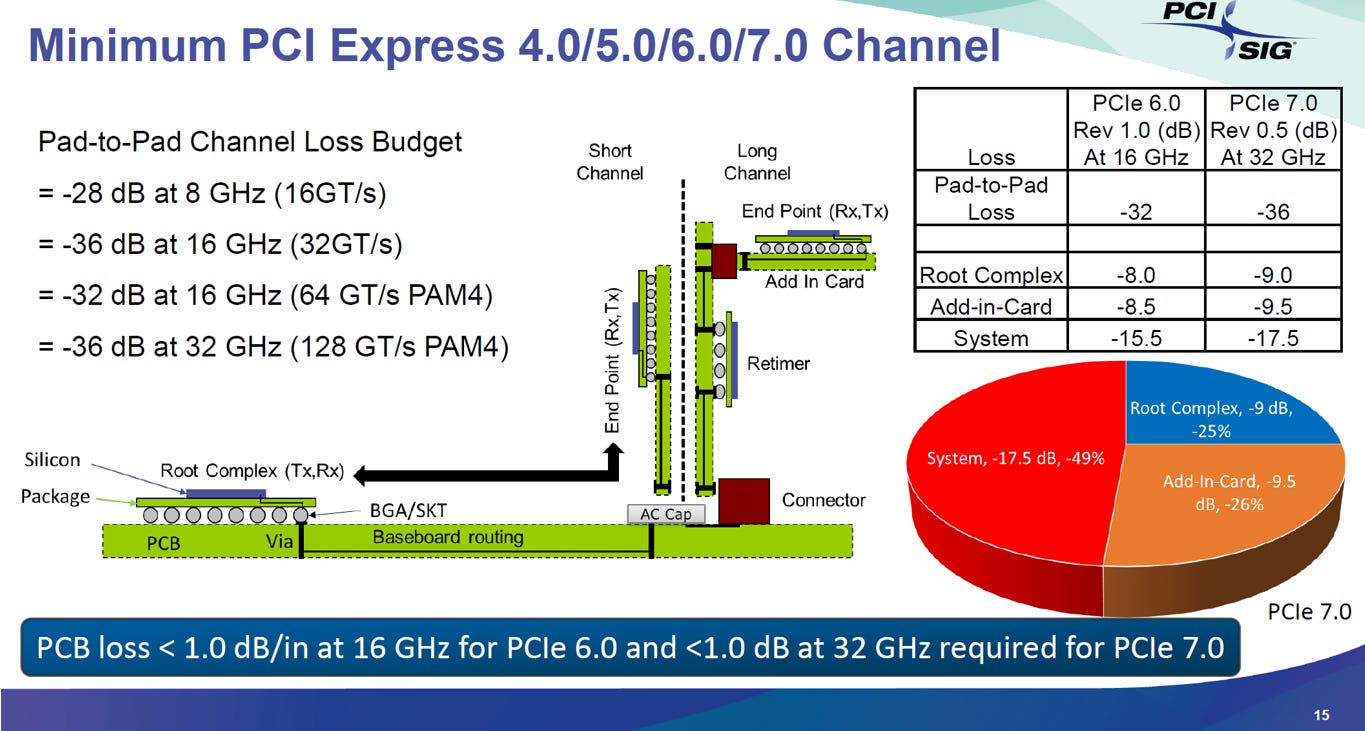
Channel Loss Budget
極致損耗: 128 GT/s 的奈奎斯特頻率高達 32 GHz,但端對端損耗預算僅給了 -36 dB。
昂貴代價: 為了達標,PCB 板材損耗被嚴格限制在 < 1.0 dB/in @ 32 GHz。這意味著必須全面捨棄常規材料,改用極昂貴的超低損耗 (Ultra-low loss) 板材(參考EP10. 3. CCL的介紹)。
延遲的要求(Latency Constraint)
既要糾錯又要快: PAM4 訊號脆弱必須依賴 FEC (前向糾錯),但 PCIe 無法像乙太網路那樣容忍 100ns 的延遲。
<10ns 要求: 規範強硬要求 FEC 加總延遲必須控制在 < 10ns,這對晶片邏輯設計是極限挑戰。
系統的Complexity
Retimer 暴增: 單靠銅線傳不遠,為了延伸距離,規範允許串接的 Retimer (重計時器) 上限翻倍至 4 顆。這直接導致系統功耗、散熱與 BOM 成本大幅上升。
2. TX Test Update
當 PCIe 從 Gen 5 (NRZ) 跨入PCIe 6/7 (PAM4) 時,TX(發送端)測試面臨的典範轉移。因為 PAM4 將電壓切成四份,導致眼高 (Eye Height) 劇縮,以前在 NRZ 時代可以被容忍的微小非線性失真,在 PAM4 眼高被壓縮至僅剩 <7mV 的情況下,都會變成致命傷。
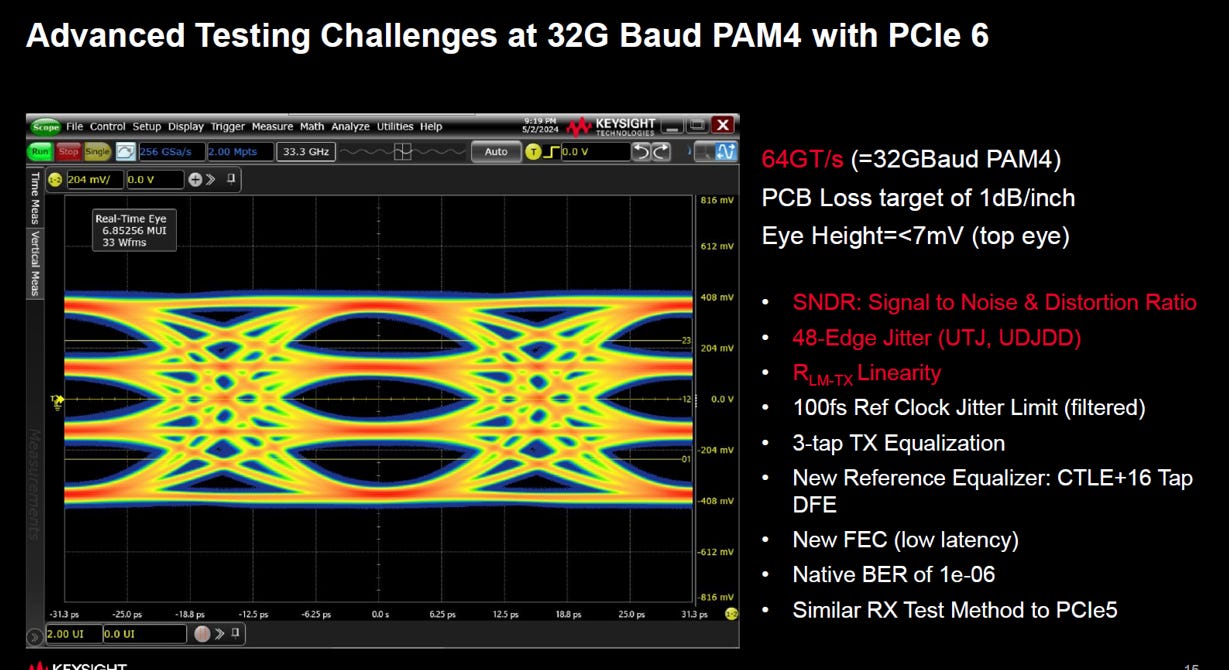
TX 測試新增的三大關鍵指標:
SNDR (Signal-to-Noise-and-Distortion Ratio)
定義: 訊號雜訊失真比。
目的: 這是衡量訊號「純淨度」的綜合指標。
原因: 以前 NRZ 時代只看 SNR (訊號雜訊比)。但在 PAM4,眼圖極小,必須把非線性失真 (Distortion) 與 串擾 (Crosstalk) 全部加進雜訊項一起計算。如果 SNDR 太低,代表波形太髒,接收端一定解不出來。
RLM (Ratio of Level Mismatch - Linearity)
定義: 電位準線性度 (Linearity)。
目的: 檢查 0, 1, 2, 3 四個電壓階梯是否「等高」。
原因: RLM 是衡量 PAM4 四個電位準(0, 1, 2, 3)間距是否均勻的關鍵指標。理想情況下,這三個眼睛的張開程度應一致。如果 TX 晶片的 DAC 線性度不好 (RLM 差),會導致中間的眼睛被擠壓或變形,大幅增加誤碼率。
48-Edge Jitter (UTJ, UDJDD)
定義: 涵蓋所有轉換組合的抖動測量。
目的: 捕捉 PAM4 所有可能的轉換路徑 (Slew Rate) 對時間抖動的影響。
原因: NRZ 只有單純的 0↔1 轉換。PAM4 有 12 種不同的轉換路徑 (如 0→1, 0→3, 2→1 等),每種斜率都不同。「48-Edge」方法能確保測量到最壞情況下的 不相關總抖動 (UTJ) (12種轉換類型 x 4次取樣 = 48 Edges)。
SNDR 與 RLM 決定了眼圖在垂直電壓軸的張開程度 (Eye Height),而 Jitter 則決定了水平時間軸的有效寬度 (Eye Width)。
2.1 SNDR (Signal-to-Noise-and-Distortion Ratio)

核心定義:SNDR 公式
SNDR 的物理意義是**「訊號強度」除以「雜訊與失真的總和」**。 根據圖片中的公式演進:
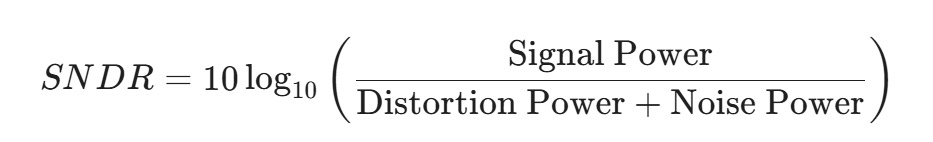
在最新的規範中 (ECN new SNDR equation),分子(訊號)的計算方式變得更嚴謹:
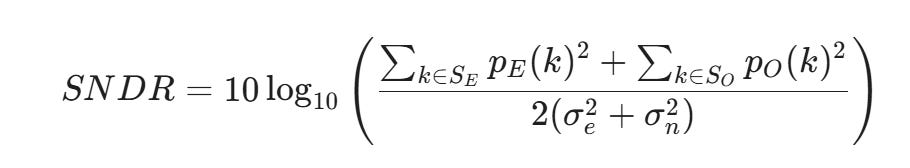
註: 測試規範必須拆分 Even/Odd 摘要如下:
架構機制 (DDR/Half-rate)為了降低電路頻率,TX 採用半速率時脈。
Rising Edge (正緣) 觸發: 輸出 Even bits ( pE )
Falling Edge (負緣) 觸發:輸出 Odd bits ( pO)
DCD(Duty Cycle Distortion)
正緣與負緣的物理電路路徑不同,極易產生 DCD (佔空比失真) 或 驅動振幅不一致,導致偶數與奇數的波形長得不一樣。
最新的規範
SNDR 公式強制將pE 與 pO分開計算,精準抓出這種因「DDR 觸發機制不匹配」所導致的訊號劣化。
三大組成要素詳解
這張圖解釋了公式中三個變數 σe、σn 與 Pulse Response 的來源:
A. 訊號 (Signal) - 從Pmax 進化為 Pulse Response
舊方法: 只看 Pmax(最大脈衝峰值)。
新方法: 使用 線性擬合脈衝響應 (Linear fit pulse response, p(k) 的平方和。
為什麼要改? 圖片指出,新方法考慮了偶數 (Even) 和奇數 (Odd) 符號的響應總和,對於高損耗通道 (Lossy channels) 來說,比單純看峰值Pmax 更具一致性與代表性。
B. 失真 (Distortion) - σe (Sigma-e)
定義: 這是指訊號偏離「理想線性波形」的程度。
測量方式: 它是利用上述的線性擬合脈衝響應,計算出測量到的波形與理想波形之間的誤差。這主要捕捉的是非線性 (Non-linearity) 和 ISI (符號間干擾)。
限制: 只在 Compliance Pattern (合規測試圖樣) 中的 PRBS (隨機碼) 區段進行計算。
C. 雜訊 (Noise) - σn (Sigma-n)
定義: 純粹的隨機雜訊。
測量方式: 測量特定的直流電平區段(Symbol #61),重複測量 250 次來計算變異數。
處理: 計算時會對每個電平取平均,並套用雜訊補償 (Noise compensation)。
為什麼 SNDR 這麼重要?
眼圖太小: 如前一張圖所述,PAM4 的眼高 < 7mV。
失真是殺手: 在 NRZ 時代,我們主要擔心隨機雜訊 (Noise)。但在 PAM4,因為有 4 個電位準,晶片的線性度 (Linearity) 只要稍差,或者通道反射造成 ISI,就會產生巨大的失真 (Distortion)。
總結: SNDR 是一個「照妖鏡」,它強迫 TX 設計者不僅要降低雜訊,還必須保證輸出的波形在數學上是非常線性的。
2.2 RLM(Ratio of Level Mismatch - Linearity)
RLM是衡量 PAM4 發送端 (TX) 「線性度 (Linearity)」 的關鍵指標:
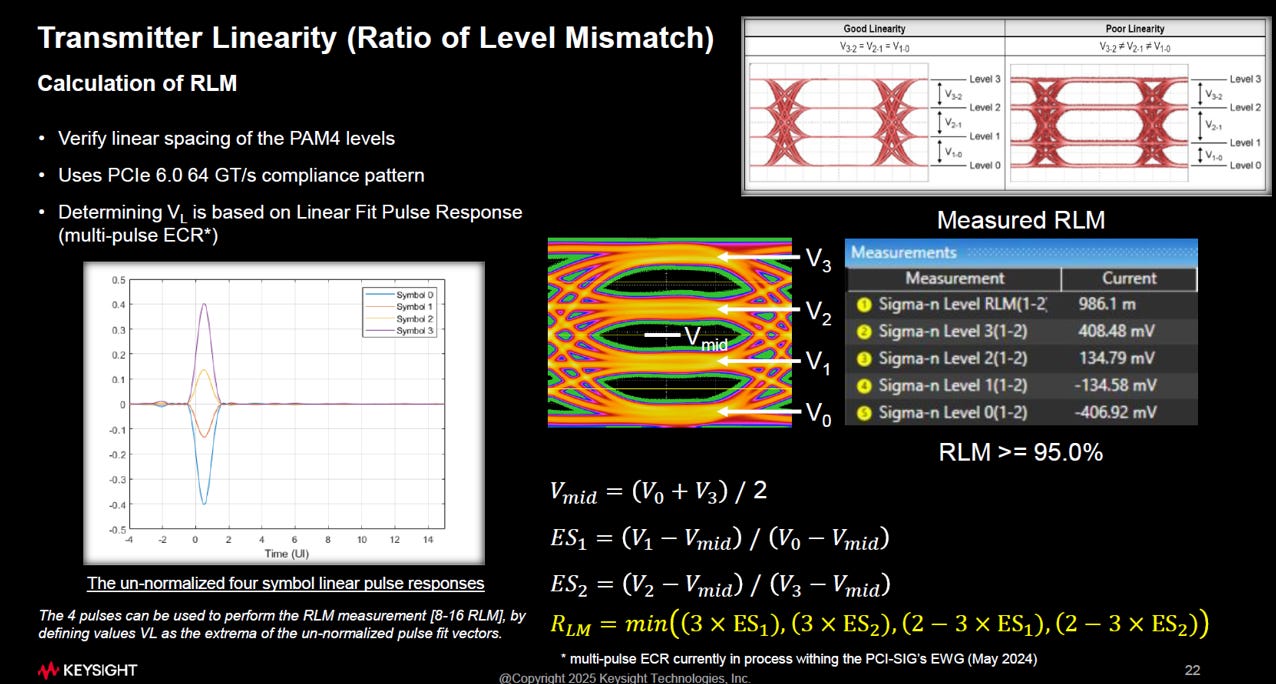
核心定義
RLM 檢查的是 PAM4 四個電壓階梯 (V0 V1 V2 V3) 的間距是否均勻。
理想狀況: 0→1、1→2、2→3 的電壓高度差應該要一模一樣(如圖右上角 “Good Linearity” 所示,三個眼睛一樣大)。
糟糕狀況: 如果發送晶片的 DAC 線性度不好,中間的階梯可能會被壓縮(如圖右上角 “Poor Linearity” 所示,中間的眼睛被壓扁,導致誤碼率暴增)。
測量與計算邏輯
RLM 的計算不再單純依靠示波器的直方圖,而是基於 Linear Fit Pulse Response (線性擬合脈衝響應) 來提取穩定的電壓位準。這和SNDR用的方法相同,計算步驟概念如下:
抓出四個電位: 確定 V0 V1 V2 V3 的電壓值。
找中心點: 計算總擺幅的中間值 Vmid = (V0 + V3)/2。
比對誤差: 計算實際的中間電位 (V0 ,V2) 與理想位置的偏差比例 (ES1, ES2)。
取最差值: 公式RLM = min(…) 會從所有可能的誤差組合中挑出**「最差的那個」**作為最終分數。
合規標準
RLM ≥ 95.0%: 這是 PCIe 6.0/7.0 的高標要求。這意味著 TX 輸出的四個電壓階梯,其均勻度必須達到 95% 以上的完美程度,幾乎不允許有忽大忽小的情況。
RLM 用來確保 PAM4 的「三個眼睛」張開得一樣大;如果 RLM 太低,代表某一兩個眼睛被擠壓,訊號品質就會崩潰。
2.3 48-Edge Jitter
這是一個針對 PAM4 多電平特性所設計的「地毯式」抖動分析:
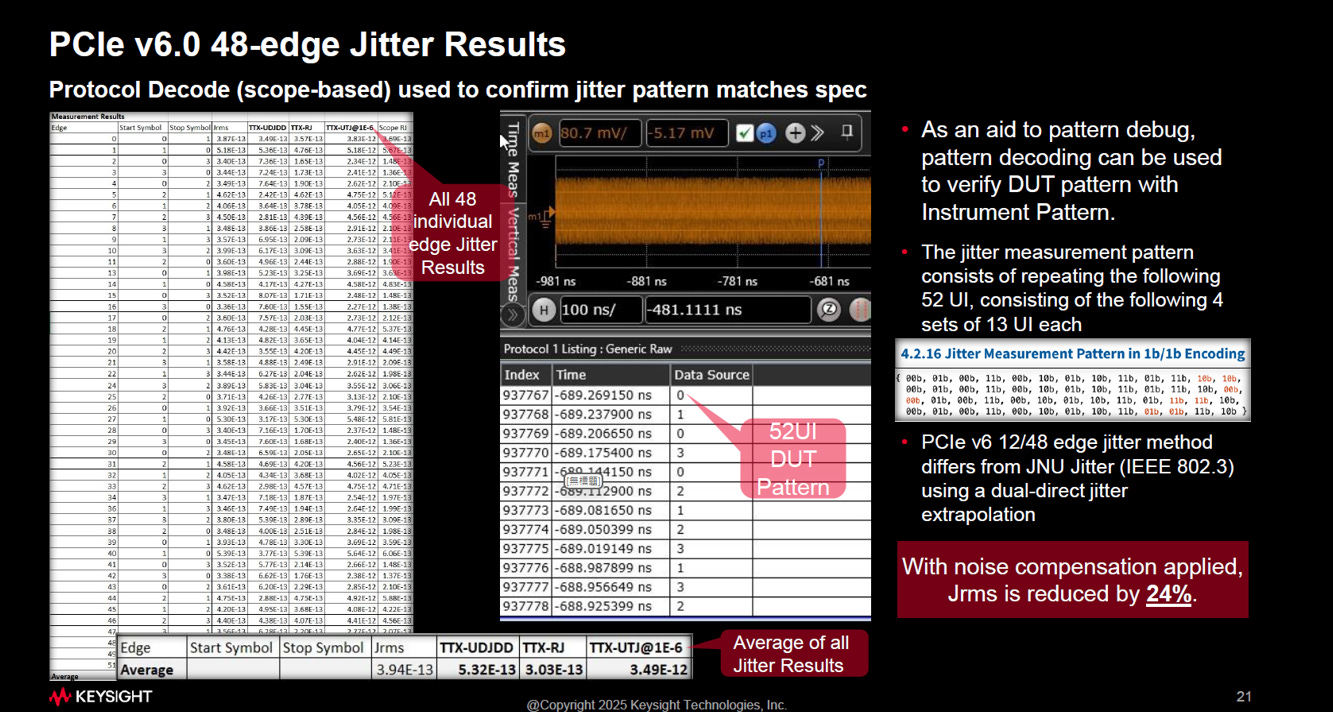
1. 為什麼是 “48-Edge”?
在過去的 NRZ (PCIe 5.0) 時代,訊號只有 0 和 1,轉場單純。但在 PAM4 架構下,電壓有 4 個階梯 (0, 1, 2, 3),這導致了12 種不同的轉換斜率 (Slew Rate),12種轉換類型 x 4次取樣 = 48 Edges。
多樣的轉場: 從 0->1 的速度,跟 0->3 的速度是不一樣的;上升緣 (Rising) 和下降緣 (Falling) 的特性也不同。
特定的測試圖樣: 規範定義了一個長度為 52 UI (Unit Interval) 的重複測試圖樣 (Pattern)。在這個 52 UI 的序列中,包含了4 次12 種不同的轉換,和4 次電位不變 (Self-transition)。
全面檢測: 48-Edge Jitter 的精神就是「不放過任何一種轉場可能性」,它會單獨測量這 48 個邊緣的抖動,確保所有類型的轉換都符合規範。
2. 測量流程與方法
根據投影片的左側表格與說明,測量步驟如下:
捕捉與解碼 (Capture & Decode):
示波器必須先鎖定訊號,利用 Protocol Decode 技術找到那個特定的 52 UI 重複圖樣,確認待測物 (DUT) 發出的圖樣無誤。
個別計算 (Individual Calculation):
系統會針對表格中列出的 Edge #0 到 Edge #47,逐一計算每個邊緣的抖動數據 (包含 UDJDD, RJ, UTJ)。
平均化 (Averaging):
最後的合規結果 (Compliance Result) 並不是看單一點,而是將這 48 個邊緣的結果取 平均值 (Average of all Jitter Results),得出最終的 TTX-UTJ (總抖動)。
3. 關鍵技術特徵
與乙太網路不同:
投影片特別註明,PCIe 採用的方法與 IEEE 802.3 (乙太網路) 的 JNU Jitter 不同。PCIe 使用的是 “Dual-direct jitter extrapolation” (雙向直接抖動外推法)。
雜訊補償 (Noise Compensation):
由於 PAM4 訊號太小,示波器本身的雜訊會嚴重干擾測量。測試規範允許扣除儀器底噪。圖中顯示,在套用雜訊補償後,測得的 RMS 抖動值 (Jrms) 大幅降低了 24%,這對通過測試至關重要。
48-Edge Jitter 是一套針對特定 52 UI 圖樣中所有 48 個關鍵轉換點進行獨立測量並取平均的嚴格測試,目的是為了在 PAM4 複雜的電壓切換環境下,精確抓出與轉換斜率相關的時序誤差(請參考EP28. Jitter)。
3. RX Update
3.1. ADC-based DSP
PCIe 7.0 在接收端 (RX) 架構上發生的典範轉移 (Paradigm Shift):從傳統的混合訊號處理轉向了基於 ADC/DSP 的數位處理。
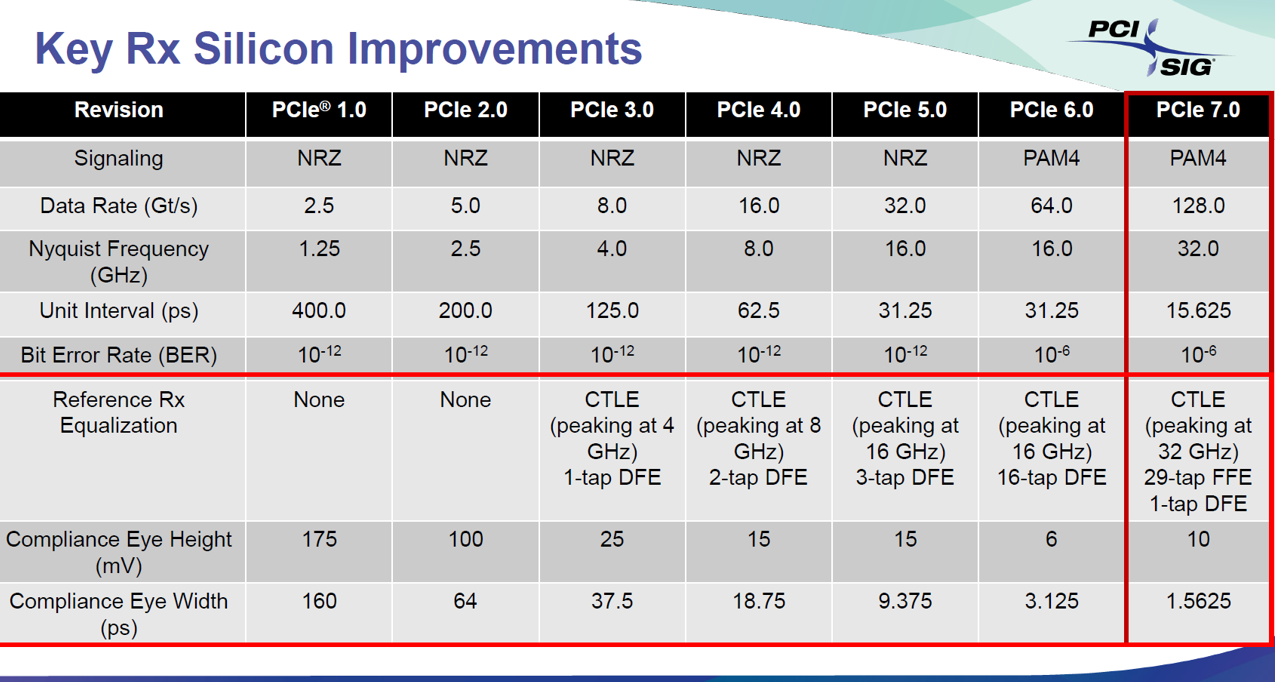
PCIe 6.0 及以前:Mixed-Mode (CTLE + Heavy DFE)
架構特徵: 主要依賴類比電路與混合訊號邏輯。
策略: 使用 CTLE 進行初步高頻補償,然後依賴高達 16-tap DFE (判決回授等化器) 來消除長距離的反射與 ISI (符號間干擾)。
瓶頸: DFE 的回授迴路有嚴格的時序限制 (Timing Closure),在類比域要做超過 16 個 tap 非常困難且耗電。
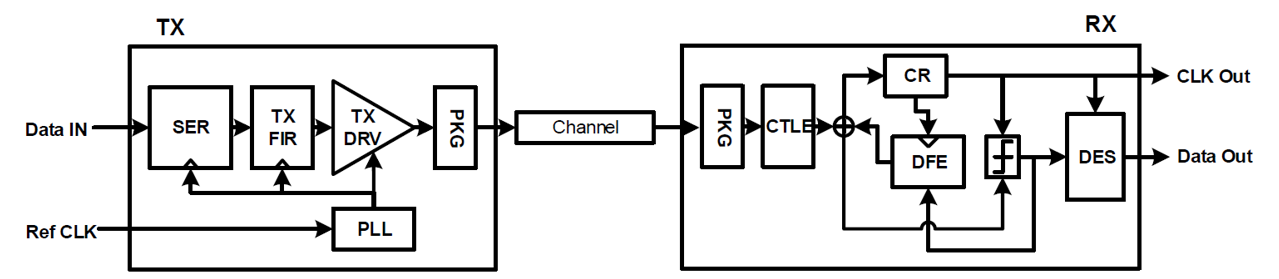
PCIe 7.0:ADC-based DSP (Heavy FFE + Light DFE)
架構特徵: 引入 ADC (類比數位轉換器),先將高速訊號數位化,再用 DSP 運算。
策略: 重點轉移至 29-tap FFE (前饋等化器)。
FFE 是純數位濾波器,能處理極複雜的通道響應。
因為 FFE 已經把大部分的 ISI (包含 Pre-cursor 和 Post-cursor) 處理掉了,DFE 被大幅削減至僅剩 1-tap,只負責處理最貼近的一個 bit 的干擾。
優勢: 數位化的 FFE 不受類比時序限制,能輕鬆實現長距離的等化 (29 taps),這是應對 128 GT/s 高損耗通道的唯一解法。

一句話總結: PCIe 7.0 放棄了「用大量 DFE 硬扛」的傳統類比做法,改用 ADC + 數位 FFE 的 DSP 架構來數學重建訊號,僅留 1-tap DFE 收尾。
理想模型 vs. 工程現實
PCIe 6.0 Reference Design (標準規範) 它只是定義互通性的行為模型 (Behavioral Model)。為了數學描述方便,它沿用了 Mixed-Mode (CTLE + DFE) 的語言,要求晶片達到某個及格線。
Implementation (廠商實作) 面對 PCIe 6.0(PAM4) 的高難度考題,純類比 (Mixed-Mode) 實作極難收斂。 Astera/Marvell/Broadcom 等廠商可能直接用 ADC + DSP (數位解法),以強大的算力來「模擬並超越」那個類比模型的標準。
3.2. 與Ethernet RX 比較
雖然 PCIe 7.0 終於跟隨 Ethernet 進入了 ADC/DSP 架構,但因為 「<10ns Latency」 這個緊箍咒,兩者在 DSP 內部的演算法選擇上產生了本質的分歧。
為什麼 PCIe 7.0 選擇 "Heavy FFE + 1-tap DFE"?
PCIe 必須避免 DFE 造成的 Burst Errors (突發錯誤),這正是 PCIe 7.0 架構設計的核心考量。
Ethernet 的做法 (Heavy DFE): Ethernet 有強大的 RS-FEC (如 RS(544,514)),所以不怕 DFE 判錯導致的 Burst Error (一錯錯一串) -> 所以敢用 Heavy DFE。
PCIe 的困境 (Lite FEC): PCIe 的 FEC 只有極短的糾錯能力 (為了低延遲)。一旦 DFE 第一個 bit 判錯,回授機制會導致後面一串 bit 全部錯(Error Propagation),這會直接穿透 Lite FEC,CRC 偵測而導致 Replay。
PCIe 7.0 的解法: 正如上一張圖 所示,PCIe 7.0 極端地強化 FFE (29 taps) 而將 DFE 砍到只剩 1 tap。
FFE 優勢: 前饋 (Feed-forward) 沒有回授迴路,不會產生 Burst Error。
1-tap DFE: 只處理最近的一個反射,將錯誤擴散風險降到最低。
關於 PCIe 8.0 (256 GT/s) 與 MLSD 的矛盾
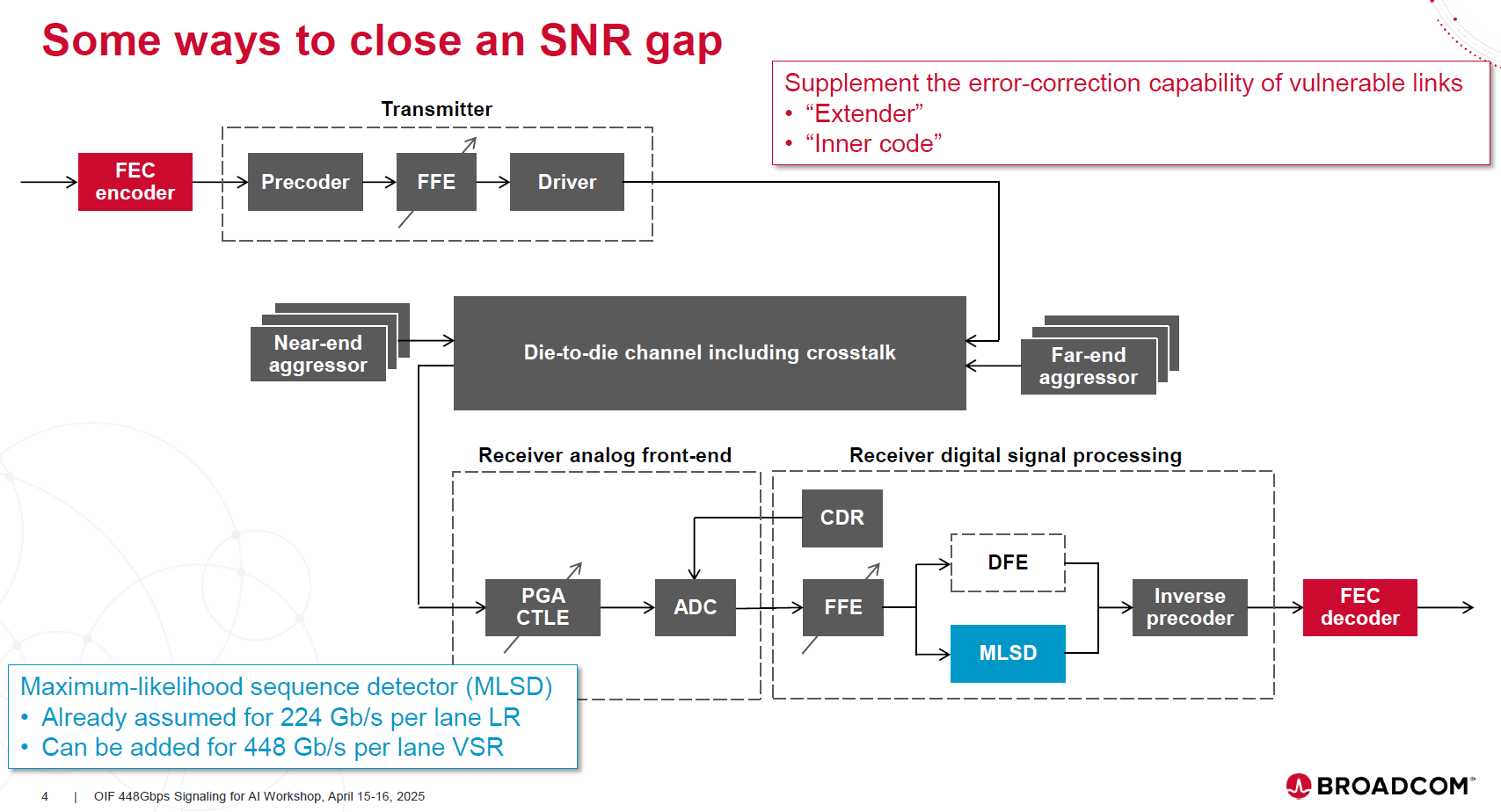
如上圖,Ethernet 200G/lane 導入 MLSD (Maximum Likelihood Sequence Detection) 是為了在極低 SNR 下救回訊號(請參考EP23. 448G SerDes),但這對 PCIe 8.0 來說是一個巨大的難題:
MLSD 的本質是「延遲換取準確度」: MLSD (如 Viterbi 演算法) 必須觀察「一整串序列 (Sequence)」後,算出機率最大的路徑來決定現在是 0 還是 1。這意味著必須 Buffer 足夠的資料量才能做決定,這天生就與 PCIe 的 低延遲 (Low Latency) 要求互斥。
PCIe 8.0 可能的處理方式: 目前業界推測 PCIe 8.0 很難直接照搬 Ethernet 的完整 MLSD。較可能的方向是:
Reflection Cancellation (反射消除): 在 DSP 內部做更複雜的數位消除,而不是依賴序列偵測。
Trellis Coded Modulation (TCM) 的變體: 結合調變與編碼,但必須是極低延遲的簡化版。
銅線退場 (The End of Copper): 256 GT/s 下,銅線距離可能縮短到 < 10公分。或許 PCIe 8.0 不會為了救銅線而導入高延遲的 MLSD,而是直接規範 CPO (Co-Packaged Optics) 或光學互連為長距離標準,銅線僅限於封裝內或極短距連接。
結論:
PCIe 8.0 不太可能全盤接收 Ethernet 的 MLSD。它更有可能繼續在 FFE/Reflection Cancellation 上榨取極限,或者乾脆兩手一攤,透過物理層介質的改變 (光學化) 來解決 SNR 問題,以保住它最重要的資產——超低延遲。
4. AI Applications
4.1 UIO (Unordered I/O)
UIO (Unordered I/O) 技術是 PCIe 7.0 從「單一樹狀架構」跨越到 「Fabric (網狀織物) 架構」 的關鍵轉捩點,目的是為了解決 AI 叢集在機櫃級 (Rack Level) 互連的頻寬阻塞問題。
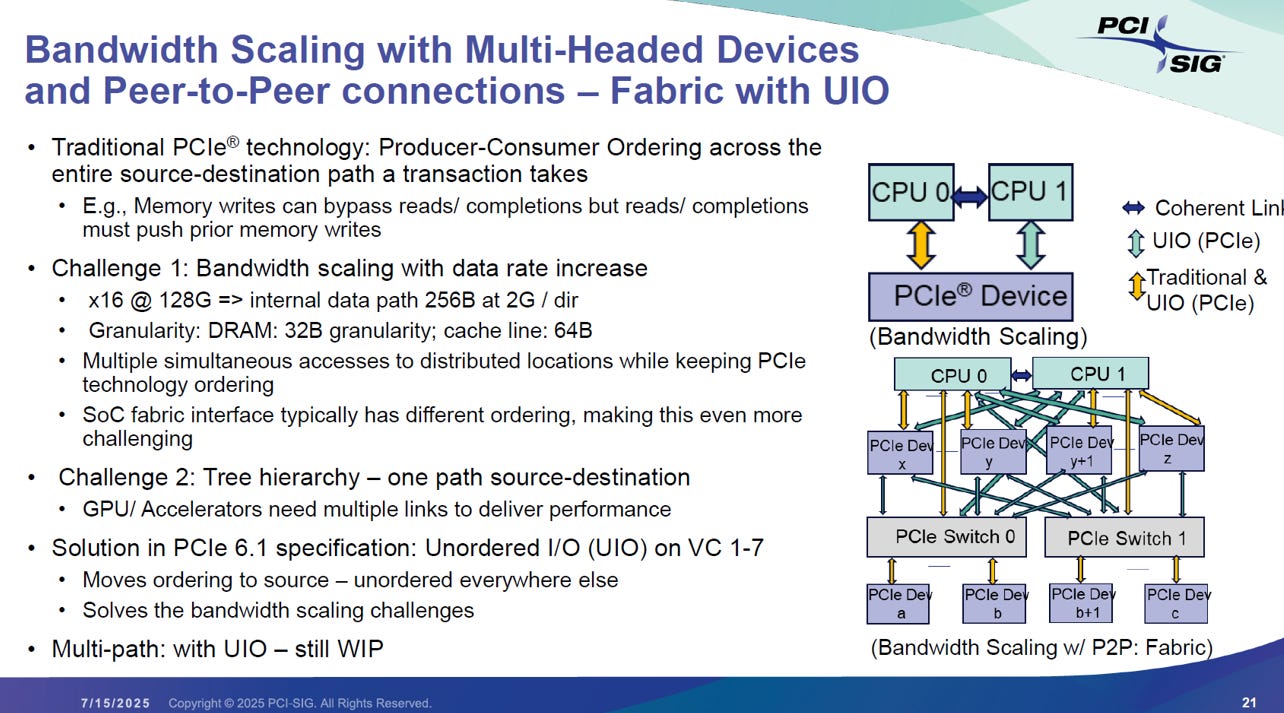
目的:解除頻寬阻塞 (Head-of-Line Blocking)
痛點: 傳統 PCIe 嚴格遵守排序,導致前方的慢速封包會卡住後方無關的高速資料。在 128GT/s 的超高頻寬下,這種排序會嚴重拖累效率。
解法: UIO 允許在 VC 1-7 (虛擬通道) 上傳輸不需嚴格排序的資料,讓後方的封包可以「超車」,填滿介面頻寬。
機制:責任回歸源頭 (Source-Based Ordering)
改變: 不再要求沿途所有的 Switch 維護順序。
新制: 排序責任全權交給 發送端 (Source) 自己控管,中間的 Switch 與路徑視為「無序 (Unordered)」,只負責極速轉發,不再進行複雜的相依性檢查。
應用:實現 PCIe Fabric
突破: UIO 打破了單一路徑 (Tree Hierarchy) 的限制,支援 多重路徑 (Multi-path) 與 多頭裝置 (Multi-headed Devices)。
意義: 這讓 PCIe 具備了類似乙太網交換機的能力,能構建出機櫃級 (Rack-level) 的 Peer-to-Peer 互連網路,是 AI Scale-up架構的基礎。
4.2. Optical PCIe
Optical PCIe (光學 PCIe) 是 PCIe 能夠突破銅線物理極限,實現 「機櫃級互連 (Rack-Level Reach)」 的關鍵技術。
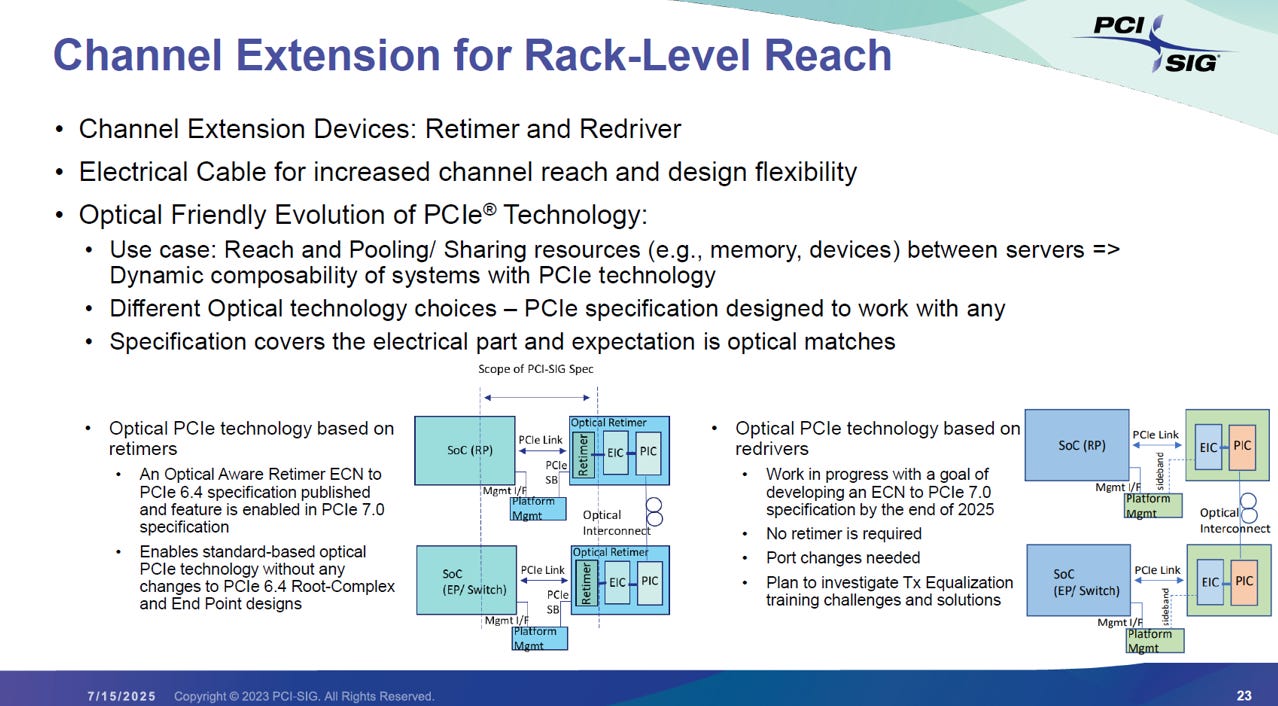
核心目的:突破距離與實現池化
距離延伸: 隨著 PCIe 7.0 速度變快,銅線傳輸距離急劇縮短。Optical PCIe 的首要任務是將傳輸距離拉長,覆蓋整個機櫃。
資源池化 (Pooling): 它的戰略目標是實現伺服器之間的資源共享(如記憶體、加速器),讓多台機器能動態組合成一個系統 (Dynamic composability)。
兩種主要實作架構
PCI-SIG 定義了兩種光學互連的實現路徑,以適應不同的功耗與成本需求:
A. 基於 Retimer 的光學 PCIe (目前的主流標準)
機制: 使用 “Optical Aware Retimer”。在電氣層面上,Root Complex (CPU) 覺得它只是連到了一顆普通的 Retimer,但這顆 Retimer 背後其實連著光纖模組 (EIC/PIC)。
優勢: 完全相容。不需要修改現有的 CPU 或 Switch 設計 (No changes to RC/EP),隨插即用。
進度: 相關功能已在 PCIe 6.4 ECN 發布,並正式納入 PCIe 7.0 規範。
B. 基於 Redriver 的光學 PCIe (未來的 Linear Drive/LPO)
機制: 移除昂貴且耗電的 Retimer (DSP),改用 Redriver 直接驅動光訊號。這類似於乙太網中的 LPO (Linear Pluggable Optics) 概念。
挑戰: 因為移除了 Retimer 的重整功能,訊號品質更難控制,需要修改 Port 的設計,並且面臨 TX 等化訓練 (Equalization training) 的挑戰。
進度: 目前仍在開發中 (WIP),目標是在 2025 年底 完成針對 PCIe 7.0 的 ECN。
4.3. 戰略目標
PCI-SIG 將 AI Scale-up (單機/機櫃內擴充) 與 Scale-out (跨機櫃網路) 列為 PCIe 7.0 的關鍵戰略目標:
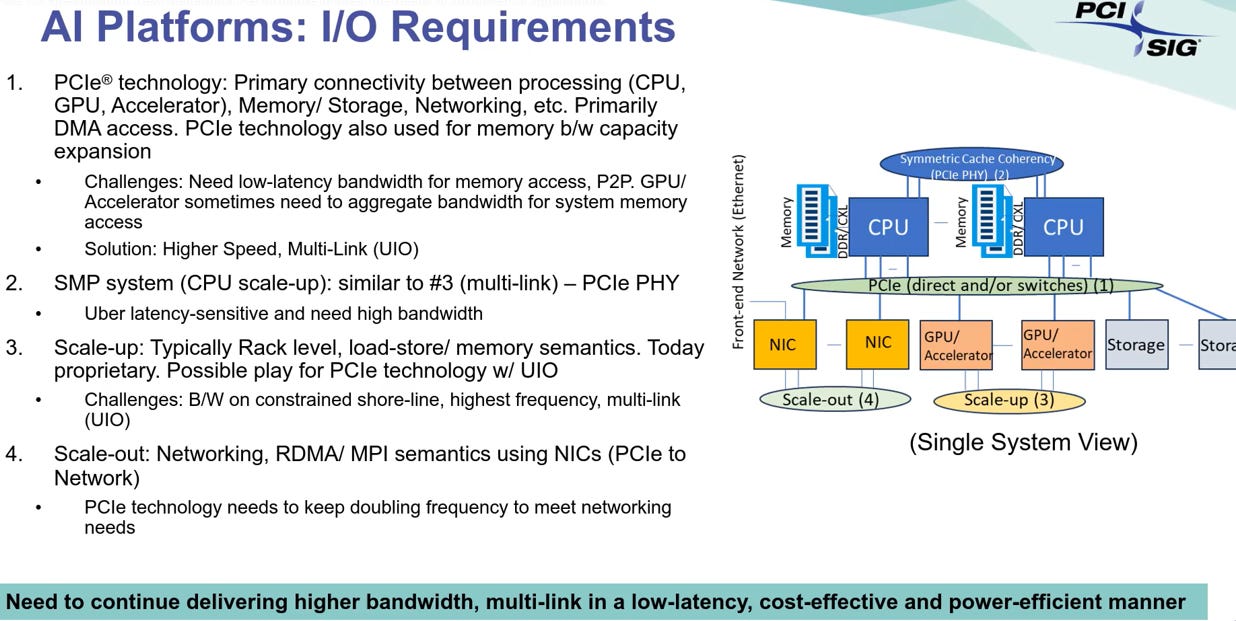
Scale-up (機櫃內互連):挑戰 NVLink 的壟斷
機會點:UIO 與 CXL 圖中提到 Scale-up 目前多為 “Proprietary” (指 Nvidia NVLink 或 AMD Infinity Fabric),但 PCIe 7.0 透過 UIO (Universal I/O) 概念,試圖以標準化介面切入。
Load/Store 語意: PCIe/CXL 本生就支援 CPU/GPU 共享記憶體的 Load-Store 語意,這是 AI 訓練中參數交換的剛需。
頻寬達標: PCIe 7.0 x16 雙向頻寬達 512 GB/s,雖仍低於 NVLink (900 GB/s - 1.8 TB/s),但已具備作為次級或推論 (Inference) 叢集互連的資格。
挑戰: Nvidia 沒有誘因開放 NVLink。PCIe 7.0 在 Scale-up 的真正機會在於 非 Nvidia 陣營 (如 AMD, Intel) 透過 CXL 3.x 進行記憶體池化 (Memory Pooling) 與 GPU 互連。
Scale-out (跨節點網路):餵飽 800G/1.6T 網卡
機會點:作為 “Feeder” (供輸者) 圖中明確指出 “PCIe technology needs to keep doubling frequency to meet networking needs”。
1:1 對應關係: 網卡 (NIC) 的速度由乙太網決定 (800G/1.6T),但資料必須從 GPU/CPU 經由 PCIe 傳給網卡。
頻寬匹配: 一張 800G 網卡 需要 PCIe 6.0 x16 或 PCIe 7.0 x8 才能跑滿。若未來走向 1.6T Ethernet,則非 PCIe 7.0 x16 不可。PCIe 7.0 是實現次世代 Scale-out 網路的絕對前提。
隱藏的關鍵機會:Optical PCIe (光學化)
圖中 Scale-up 提到 “Constrained shore-line” (板邊空間受限) 與 “Highest frequency” 的物理限制。 PCIe 7.0 銅線傳不遠 (Retimer 數量暴增),這將迫使 PCIe 直接 「光學化」 (Optical PCIe / CPO)。一旦 PCIe 能透過光纖傳輸數十公尺,它就有機會直接跳過乙太網,成為機櫃間 (Rack-to-Rack) 的互連標準,這才是 PCIe 最大的潛在變革。
總結:
PCIe 7.0 在 Scale-out 是「剛需」(為了餵飽 1.6T 網卡);在 Scale-up 則是「備胎」(透過 CXL 服務非 Nvidia 陣營),而光學互連是它突破機箱限制、統一 AI 傳輸介面的唯一機會。