EP27. Marvell + Celestial AI = ?

前幾天看到Marvell併購Celestial AI的新聞。LightMatter, Celestial AI和AyarLabs為三家受矚目的矽光子新創公司,EP25. 才介紹AyarLabs和LightMatter,Celestial AI卻冒出大新聞。整理一下資料分享個人觀點,歡迎討論。
1. Background
1.1. 矽光子新創公司
第一次注意到Celestial AI,是在Yole的報告。在業界公認的「黃金標準」比較表中,有顯示這三家矽光子新創公司:
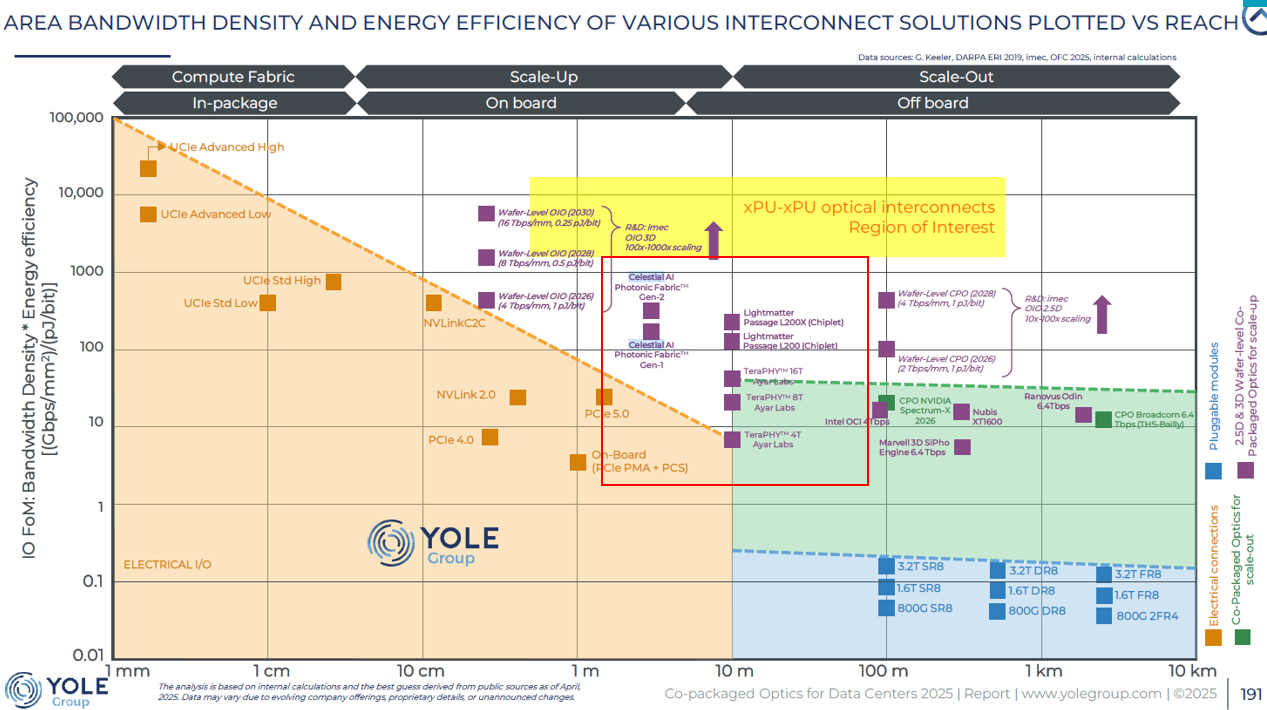
Source: Yole
這三家新創代表了矽光子技術的三種不同「整合維度」,簡單總結如下:
Ayar Labs (側邊鋪路 - I/O 專家)
定位:Side-car (小晶片)
做法:做成一顆獨立的光通訊晶片,放在 GPU/CPU 旁邊。
特點:技術最成熟,生態系最廣(Broadcom/NVIDIA/Intel),專注解決「晶片對外」的頻寬瓶頸,但受限於晶片邊緣(Shoreline/Beachfront)長度。
Celestial AI (垂直蓋樓 - 密度之王)
定位:3D Stacking (垂直堆疊), In-die。
做法:把光引擎直接堆疊在運算晶片或記憶體上下方。
特點:Yole 圖表上打破了面積限制,實現了最高的頻寬密度和能效,直接挑戰「記憶體牆 (Memory Wall)」。
Lightmatter (地基基建 - 平台專家)
定位:Interposer (中介層), Wafer-scale
做法:做成一片晶圓級的超大光學載板,把所有晶片(XPU, HBM)都放在上面。
特點:取代傳統 PCB/載板,像是一張「光學主機板」。適合大規模叢集互連,解決複雜佈線問題。
Ayar Labs 幫晶片裝寬頻(旁邊);Celestial AI 幫晶片加樓層(疊合);Lightmatter 幫晶片換地基(下面)。
註:Lightmatter Passage M1000 為Optical Interposer(圖上沒顯示); L200為CPO module。
估值總覽 (2025 Q4)

Ayar Labs 賣的是管線 (零件);Celestial AI 賣的是擴建方案 (記憶體解構);Lightmatter 賣的是新地基 (全新運算架構)。解決的問題層級越高,估值越高。
1.2. CPO solutions
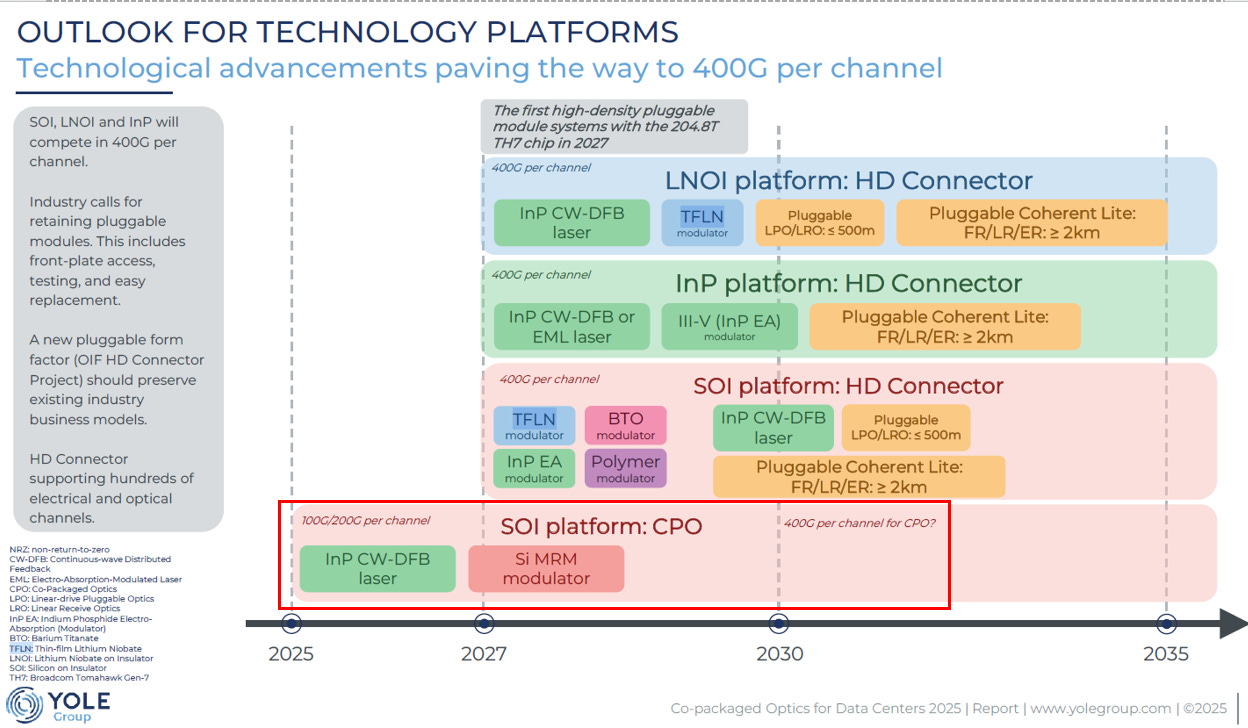
Source: Yole
這張由Yole整理的圖表資訊豐富。上半部是針對pluggable module(使用新的HD connector,參考EP23. 448 SerDes),下半部是針對這次討論的CPO。
光源策略 (Laser Source):大局已定
主流:ELS (外部雷射源)。除了 Intel 堅持將雷射做在晶片上 (Hybrid bonding),其餘主流玩家Broadcom, Nvidia, Celestial(Marvell now), AyarLabs, Lightmatter皆採用 ELS(External Laser Source),目的是將熱源與昂貴的邏輯晶片分離。
調變器戰場 (Modulator):
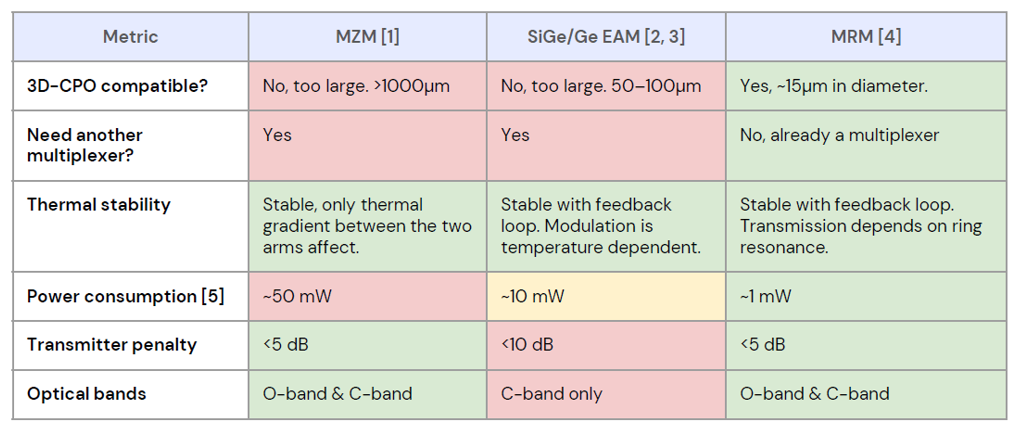
本來和Yole的看法一樣,以為是MRM(Micron Ring Modulator主導(參考EP14. SiPH MRM),但依最近讀的資料,可能會演變成三種路線的博弈:
密度派:MRM(Micro-Ring Modulator)
代表廠商:Nvidia, Intel, Lightmatter, Ayarlabs
特點:理論密度最高(微米級),適合極致微縮。
挑戰:對溫度極度敏感(熱漂移問題),控制複雜度高。
穩健派:MZM(Mach-Zehnder Modulator)
代表廠商:Broadcom
特點:技術最成熟,對溫度不敏感,可靠性最高。
代價:元件尺寸大(毫米級),難以實現極致密度。
定位:交換機 (Switch) 端 CPO 的霸主。
平衡派:GeSi EAM(Electro-Absorption Modulator)
代表廠商:Marvell(Celestial AI)
特點:體積比 MZM 小(50微米),熱穩定性比 MRM 好(不需極端溫控)。
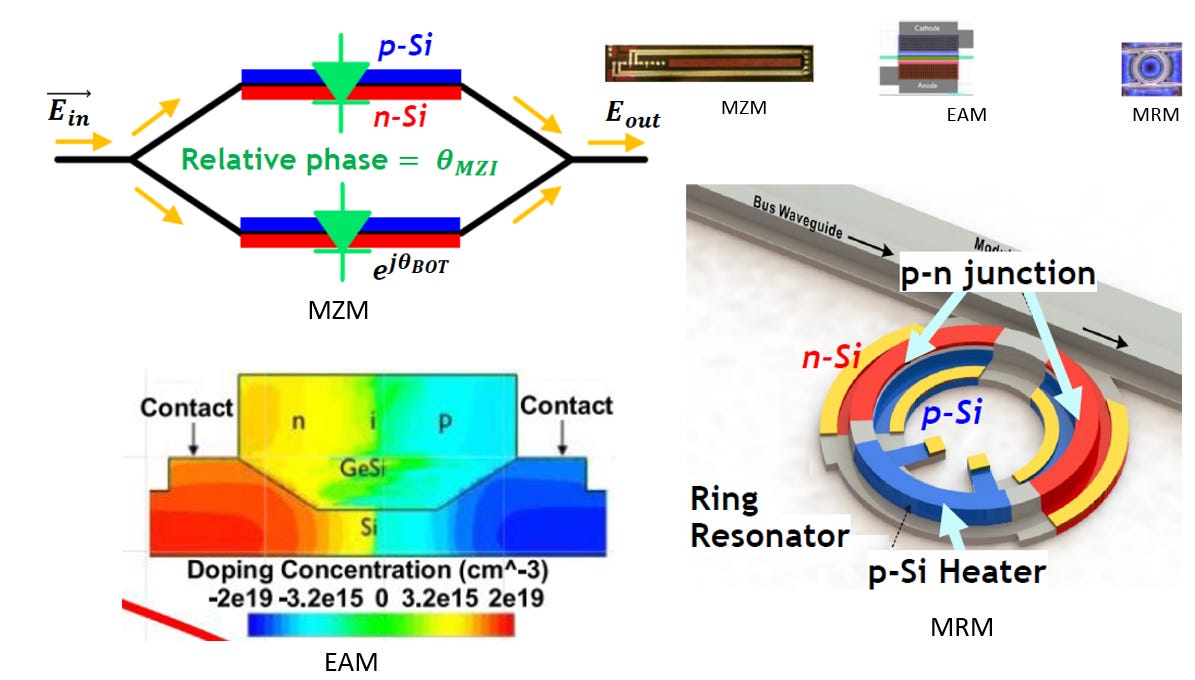
Source: Intel, Lightmatter
2. Modulator
2.1. MRM(Micro-Ring Modulator)
架構和工作原理
微環調變器 (MRM) 的核心運作機制,可以簡述為「一個對波長極度挑剔的高速光學開關」:
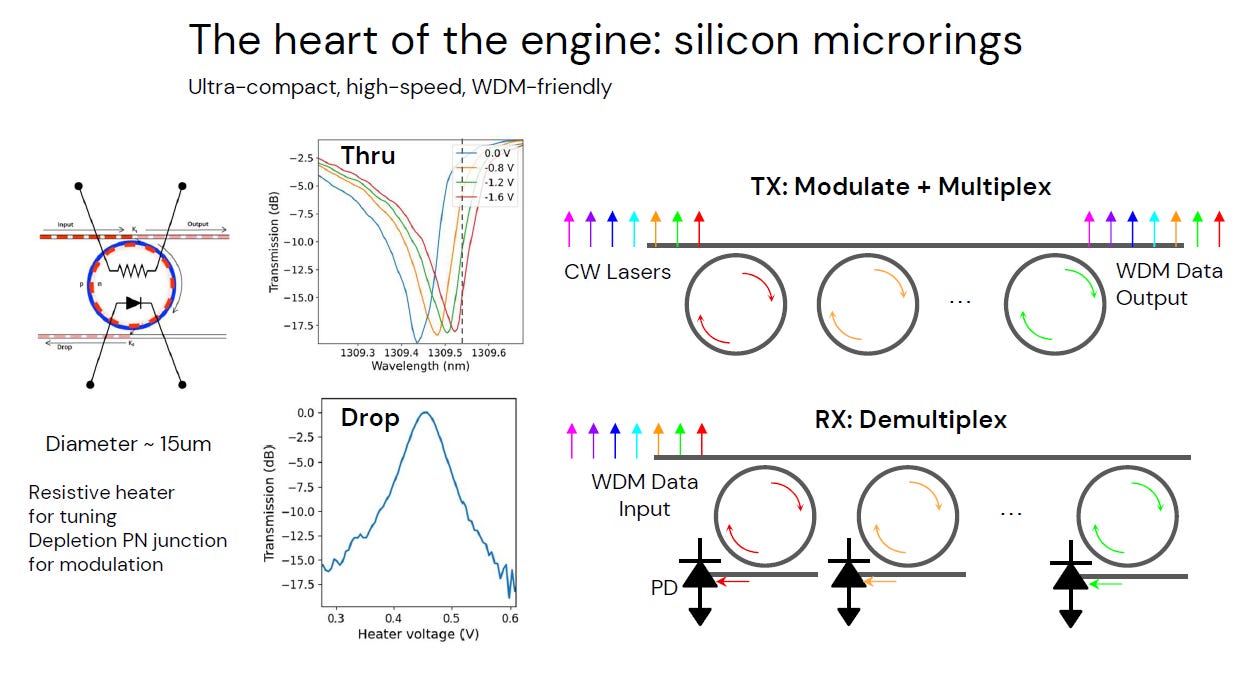
Source: LightMatter
光學共振(Resonance): MRM 是一個直徑僅約 15µm 的矽圓環。當光的波長與圓環周長匹配時,光會發生「共振」,從直線路徑「跳」進圓環裡打轉(被濾掉),導致輸出端訊號變弱(代表 “0”)。
電壓調變 (Modulation): 利用 PN Junction 施加電壓改變矽的折射率,強制讓共振波長偏移(Shift)。原本該被圓環吸走的光,因為共振點跑掉了,變成直接通過,輸出端訊號變強(代表 “1”)。
多波長並行 (WDM): 圖右展示了 MRM 最大的優勢。因為它體積極小,可以在同一條光波導上串聯多個微環,每個環只負責處理一種顏色(波長)的光。這讓單條光纖能像彩虹一樣同時傳輸多路數據,實現極致的頻寬密度。
代價 (The Heater): 圖中特別標示了 Resistive heater (電阻加熱器)。因為矽對溫度非常敏感,必須用加熱器隨時微調,確保圓環的共振點不會亂飄,這也是 MRM 控制最困難的地方
MRM (微環調變器) 的材料
主流霸主:純矽 (Silicon, Si)
特性:CMOS 相容性是最大王牌,能在 12 吋晶圓廠低成本量產。
致命傷:熱穩定性差。矽的折射率隨溫度變化劇烈,必須依賴耗電的加熱器 (Heater) 隨時鎖定波長,這也是 Si-MRM 難以攻克「超高密度堆疊」散熱牆的主因。
明日之星:薄膜鈮酸鋰 (TFLN)
代表:HyperLight 等新創。
特性:速度極快 (>100GHz) 且訊號純淨 (無 Chirp)。它是目前物理特性最完美的材料,比矽更穩定。
挑戰:加工困難。鈮酸鋰很難蝕刻,且難以像矽一樣進行大規模單晶片整合 (Monolithic),成本較高。
異質整合:III-V 族化合物 (InP/GaAs)
代表:部分高效能利基應用。
特性:效率高。利用量子效應 (QCSE) 進行調變,電壓低且響應快。
挑戰:鍵合工藝 (Bonding) 昂貴。必須把 III-V 材料「貼」到矽晶圓上,良率與量產性不如純矽。
目前的 CPO 戰場中,Si-MRM 因成本優勢仍是主流,但其「熱控制惡夢」正是促使 Celestial AI 轉向 GeSi EAM(較穩定),以及業界開始研發 TFLN(更高速)的根本原因。
2.2. MZM(Mach-Zehnder Modulator)
架構和工作原理
馬赫-曾德爾調變器 (MZM) 的核心機制,可簡述為「利用光的干涉效應來控制明暗的開關」:
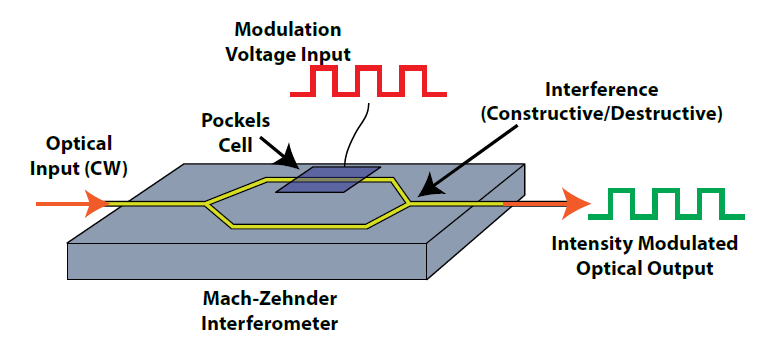
Source: Reference
分流 (Split): 將一道連續光 (CW) 一分為二,分別送入兩條平行的光波導手臂。此時兩束光的相位是同步的。
變速 (Phase Shift): 在其中一條(或兩條)手臂上施加電壓。電壓會改變材料的折射率,導致光在該手臂中行進速度變慢,產生「相位延遲」(慢半拍)。
干涉 (Interference): 兩束光在出口處重新匯合。
亮 (1):若兩束光相位依然同步(波峰對波峰),訊號疊加增強。
暗 (0):若電壓控制得當,使其中一束光剛好慢了半個波長(波峰對波谷),兩者會互相抵消,訊號消失。
MZM (馬赫-曾德爾調變器) 的材料
現役霸主:純矽 (Silicon, Si)
代表:Broadcom (目前 CPO 產品), Intel。
特性:成本無敵。完全相容 CMOS 製程,能在 12 吋晶圓廠大規模製造。
瓶頸:物理極限已到。利用載子擴散效應(Plasma disperion Effect)調變,速度慢且光損耗大,在單通道 200G 以上顯得力不從心。
明日之星:薄膜鈮酸鋰 (TFLN)
代表:HyperLight (新創), Lumentum (轉型)。
特性:物理性質完美。利用普克爾斯效應 (Pockels,圖中所示),反應極快 (>100GHz)、訊號純淨無損耗,且比矽穩定。
挑戰:加工困難。材料太硬難蝕刻,目前正處於從實驗室走向晶圓廠量產的關鍵過渡期。
傳統貴族:磷化銦 (InP)
代表:Infinera(Nokia),Lumentum,Coherent。
特性:效率極高。原生就能發光(Laser)與調變,電壓驅動效率優於矽。
挑戰:貴且難整合。晶圓尺寸小、成本高,難以像矽一樣跟邏輯晶片大規模整合。
2.3. EAM(Electro-Absorption Modulator)
架構和工作原理
電吸收調變器 (EAM) 的運作機制,可以簡述為一個高速開關的 「光學百葉窗」:
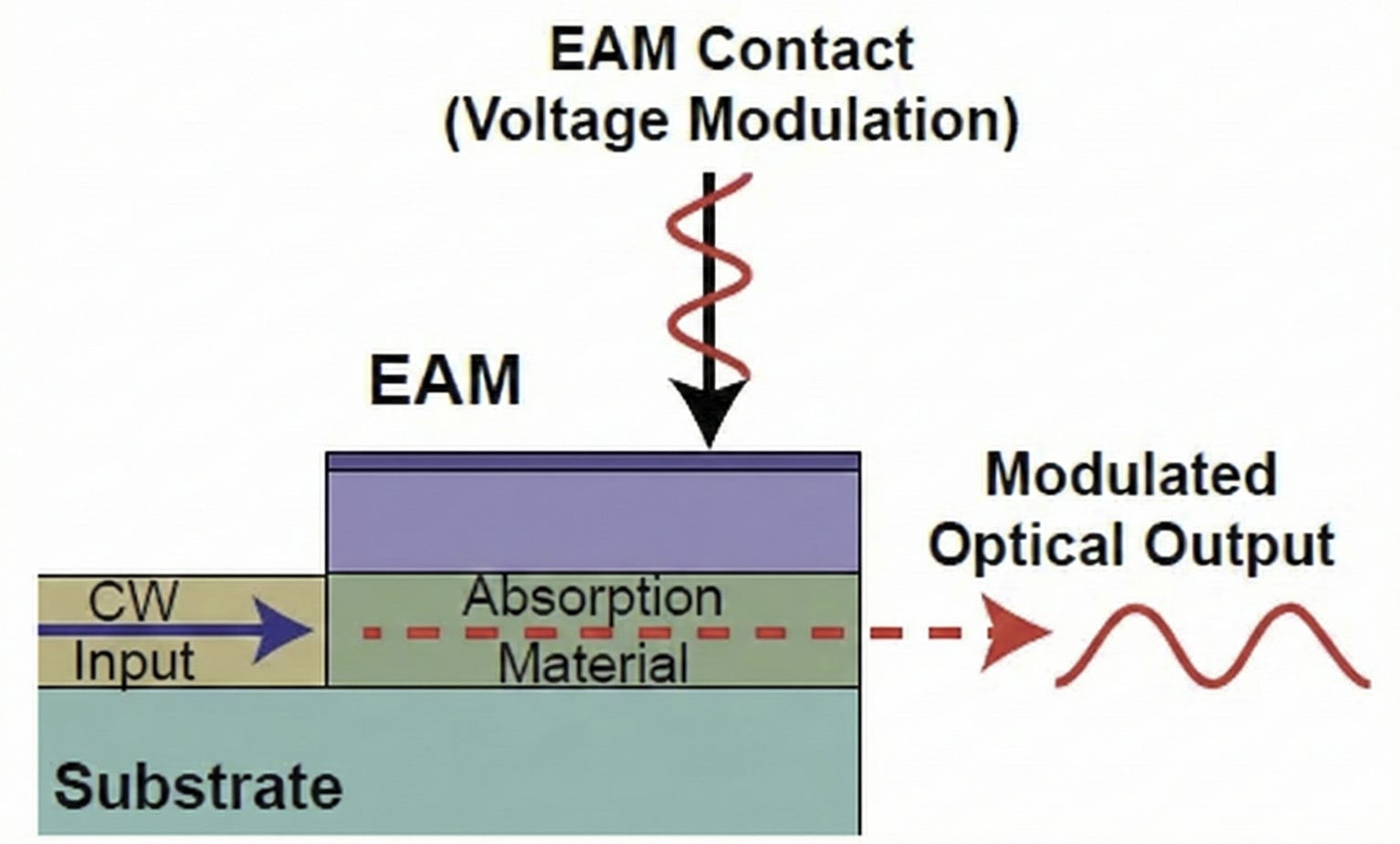
Source: Reference
結構 (Structure): 它不像 MZM 那樣有長長的手臂,而是一個垂直堆疊的「三明治」結構。中間夾著一層 吸收材料 (Absorption Material)。
運作 (Operation): 利用 法蘭茲-凱爾迪什效應 (Franz-Keldysh Effect) 來控制材料「透不透光」:
通 (1):不加電壓時,材料是透明的,連續光 (CW Input) 直接穿透過去。
斷 (0):施加電壓 後,強電場會改變材料的能隙,使其瞬間變成不透明(吸光),把光「吃掉」,輸出端就沒有光了。
EAM 的原理就是簡單粗暴的「吸光 vs. 透光」。這讓它體積極小(僅幾十微米)、速度極快,且比 MRM 擁有更好的熱穩定性。
EAM (電吸收調變器) 的材料
整合派:鍺矽 (GeSi)
代表:Celestial AI (Marvell 新併購)
特性:單晶片全整合 (Monolithic)。鍺可以直接生長在矽晶圓上,與 CMOS 邏輯電路做在同一顆晶片,實現最低成本與最高密度。
優勢:寬溫工作。對溫度變化的容忍度遠高於 MRM,無需複雜溫控。
效能派:磷化銦 (InP)
代表:Marvell (Inphi), Lumentum, Broadcom
特性:異質整合 (Heterogeneous)。InP 無法直接長在矽上,需透過鍵合 (Bonding) 技術貼合,製程複雜且成本高。
優勢:極致效能。調變效率極高(低電壓即可驅動),且能與DFB雷射整合為大名鼎鼎的 EML(Electro-absorption Modulated Laser),是長距離傳輸的霸主。

Source: Broadcom
右側(較長的長方形區域):是 DFB Laser (分佈回饋雷射)。
左側(較短且包含圓形接點的區域):是 EAM (電吸收調變器)。
2.4. 800G Pluggable Module Usage
在 800G 可插拔模組 (Pluggable Module) 的2025 DCI市場中,實由 VCSEL、SiPh (MZM) 和 EML(EAM)三分天下,而 MRM 幾乎缺席。
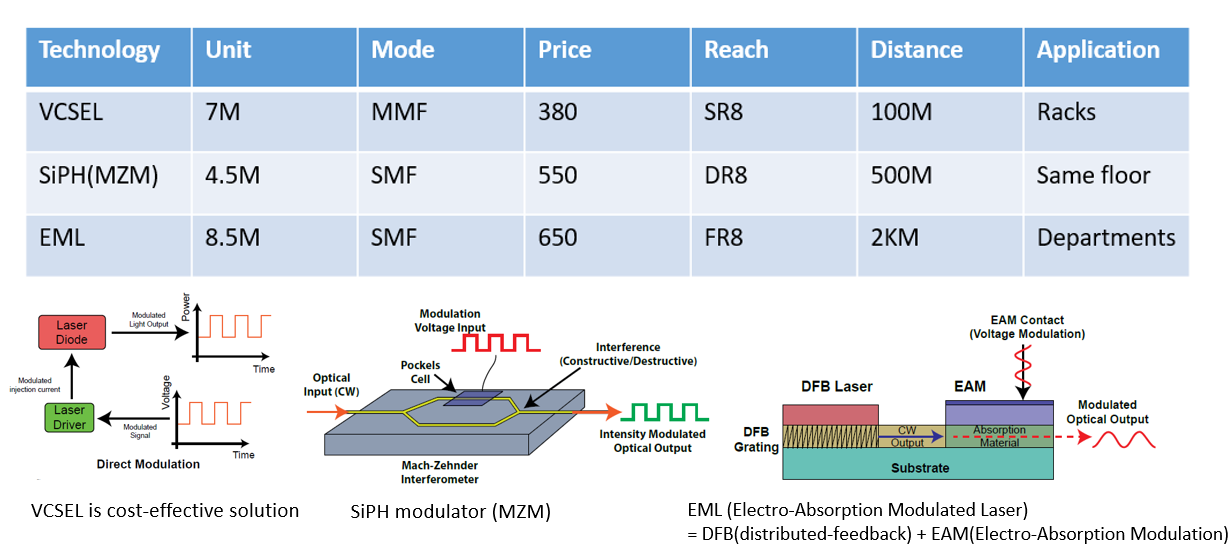
註: 2025年初的預估,僅供參考
短距離 (SR8, <100m):VCSEL (Vertical Cavity Surface Emission Laser)
技術:直接調變(Direct Modulation)雷射電流。
定位:成本與功耗最低,統治機櫃互連 (Racks) 市場。
中距離 (DR8, 500m):SiPh (MZM)
技術:利用 MZM 的干涉原理 進行調變。
定位:矽光子的主流戰場。雖然 MZM 體積較大,但在模組內空間足夠,且其熱穩定性遠勝 MRM,適合大規模資料中心互連。
長距離 (FR8/LR8, 2km+):EML (InP EAM)
技術:利用 EAM 的電吸收效應 進行調變。
定位:性能王者。訊號品質最佳,適合波分複用 (WDM) 與長距離傳輸。
為何 MRM 少用於模組? 雖然 MRM 極小且適合 WDM,但它對溫度極度敏感,需依賴加熱器 (Heater) 隨時微調共振點。在可插拔模組較寬裕的空間內,業界傾向使用 更穩定、不需複雜溫控的 SiPH(MZM) 或是成熟的EML(InP EAM),而非冒險使用嬌貴的 MRM。
2.5. MRM和EAM的觀點
矽光子在 AI Scale-Up (擴展互連) 領域的兩大陣營觀點。這是一場關於「極致密度」與「工程穩定性」的辯論:
MRM陣營的觀點
Source: LightMatter
MRM 陣營 ( Lightmatter, Ayar Labs, Intel, Nvidia)
核心信仰: 「密度為王,熱問題可控」。 他們認為 MRM 是物理上實現最高 I/O 密度的唯一解,並自信能透過電路設計克服熱敏感特性。
極致微縮:MRM 直徑僅約 15µm,遠小於 MZM,這讓它成為理論上唯一能滿足 XPU 邊緣超高密度需求的元件。
WDM 優勢:微環天生就是濾波器,不需要額外多工器 (Multiplexer) 就能實現多波長傳輸,極大化單纖頻寬。
熱問題回應:對於對手攻擊的熱敏感度,他們視為**「可管理的工程特徵」**。透過整合微型加熱器 (Resistive heater) 與閉迴路控制,將波長鎖定。雖然單個環需消耗 ~1mW,這是值得的代價。
EAM陣營的觀點
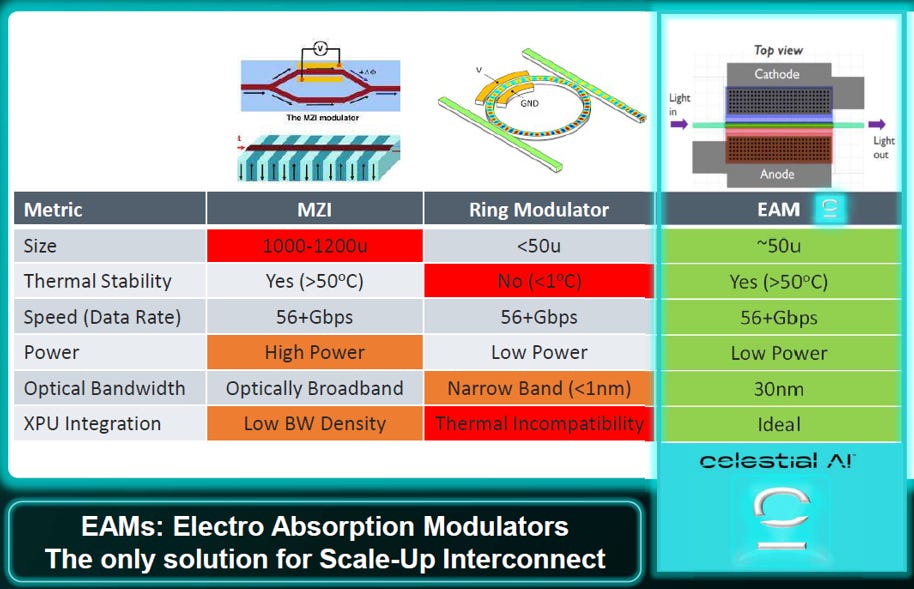
Source: Celestial AI
EAM 陣營 (Marvell/Celestial AI)
核心信仰: 「穩定至上,拒絕冒險」。 他們認為在 GPU 這種高熱環境下,EAM 才是那個兼顧性能與可靠性的「甜蜜點」。
攻擊對手:Celestial AI 在圖中直指 MRM 的致命傷是 “Thermal Incompatibility” (熱不相容),暗示在 GPU 旁靠加熱器控制波長是高風險的工程惡夢。
穩定霸主:EAM 利用光吸收原理,擁有 >50°C 的寬廣熱穩定區間,不需要像 MRM 那樣脆弱且複雜的溫控系統。
戰略定位:雖然 EAM 尺寸 (~50µm) 比 MRM 稍大,但已足夠小到可進行 3D 封裝,被該陣營標榜為擴展互連的「唯一解 (The only solution)」與「理想 (Ideal)」選擇。
這場CPO戰役本質上是 「物理極限 (MRM)」 與 「工程穩健 (EAM)」 的對賭。MRM 陣營賭的是他們的控制電路能完美駕馭熱漂移;而 EAM 陣營 (Marvell) 則賭客戶寧願要一個稍微大一點、但絕對穩定的方案。
2.6. BRCM TH-5 CPO(SiPH MZM)實測
Meta 對 Broadcom TH-5 Bailly CPO 交換機 進行的大規模可靠性 重點如下:
測試方法:
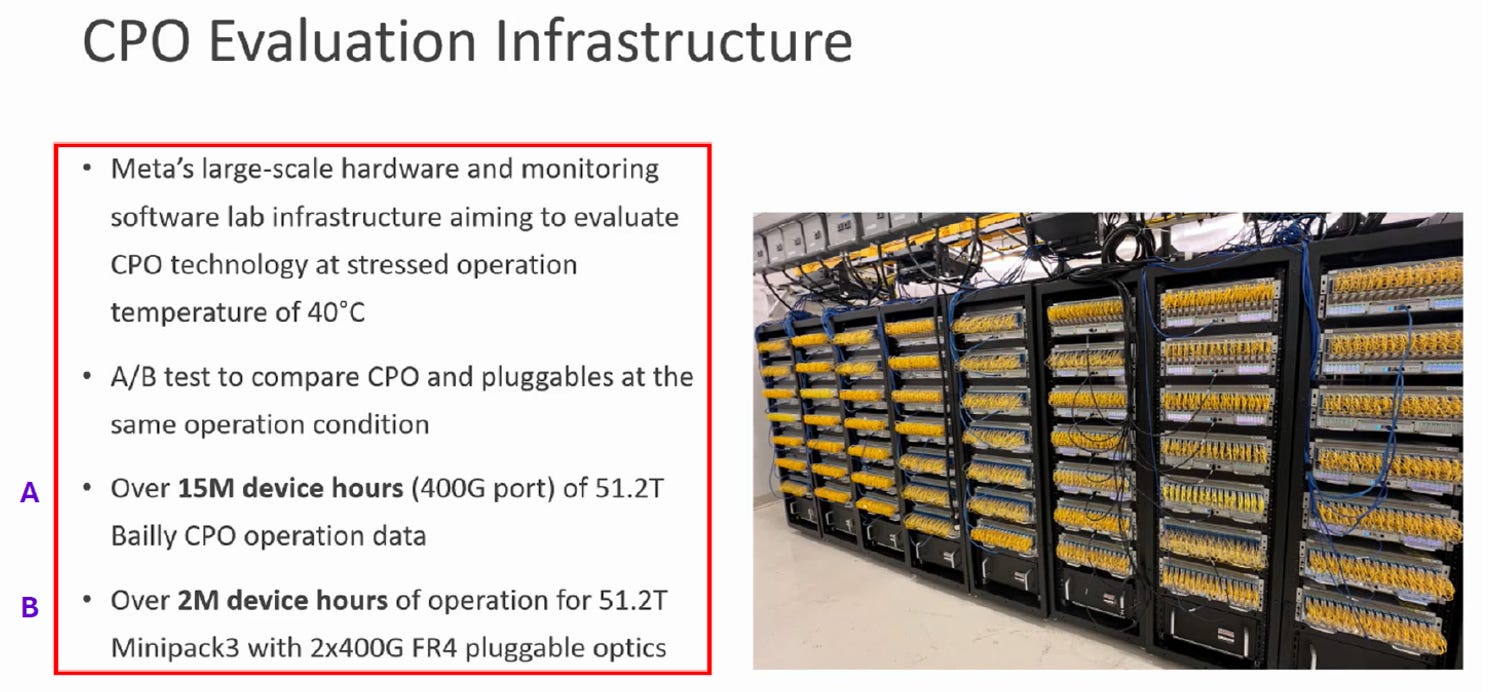
Source: Meta
直球對決 (A/B Test):
Meta 將 51.2T Bailly CPO (採用 Broadcom SiPh(MZM) 技術) 與傳統的 51.2T Minipack3 (採用 2x400G FR4 可插拔模組) 置於相同且嚴苛的 40°C 高溫環境 下進行壓力測試。
測試規模:
CPO 組 (Bailly):累積運行超過 1,500 萬 (15M) 小時 (以 400G 埠計算)。
對照組 (可插拔):累積運行約 200 萬 (2M) 小時。
Meta測試結果
1. 功耗
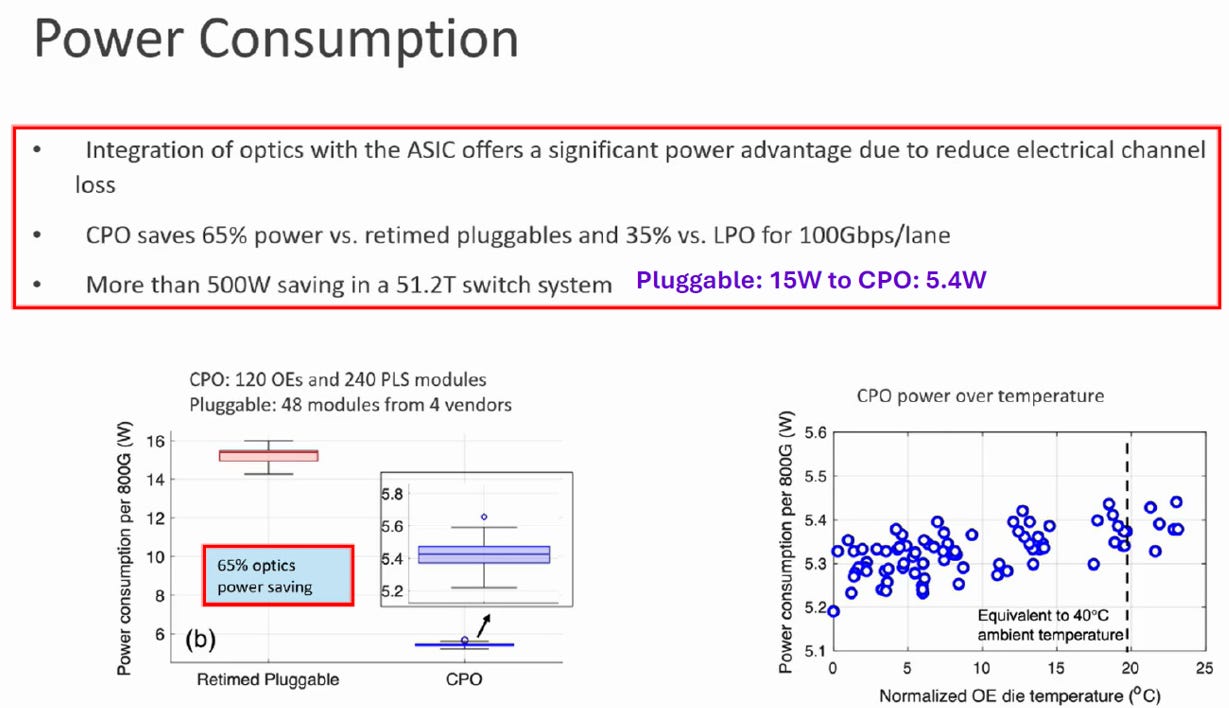
Source: Meta
單通道功耗驟降:
800G 頻寬時,CPO 僅需 5.4W,而傳統可插拔模組 (Pluggable) 高達 15W。
節能幅度:
對比傳統 Retimed 模組:節省 65% 電力。
對比 LPO (線性驅動) 模組:仍能節省 35%。
整機系統:
在一台 51.2T 的交換機系統中,採用 CPO 方案可總共節省超過 500W 的電力,這對資料中心的散熱設計是巨大的優勢。
高溫穩定性:
右下角圖表顯示,即便在模擬 40°C 的高溫壓力測試下,CPO 的功耗依然穩定維持在 5.2W ~ 5.5W 區間,並未因熱漂移而失控
2. ALFR(年度鏈路故障率, Annual Link Failure Rate)
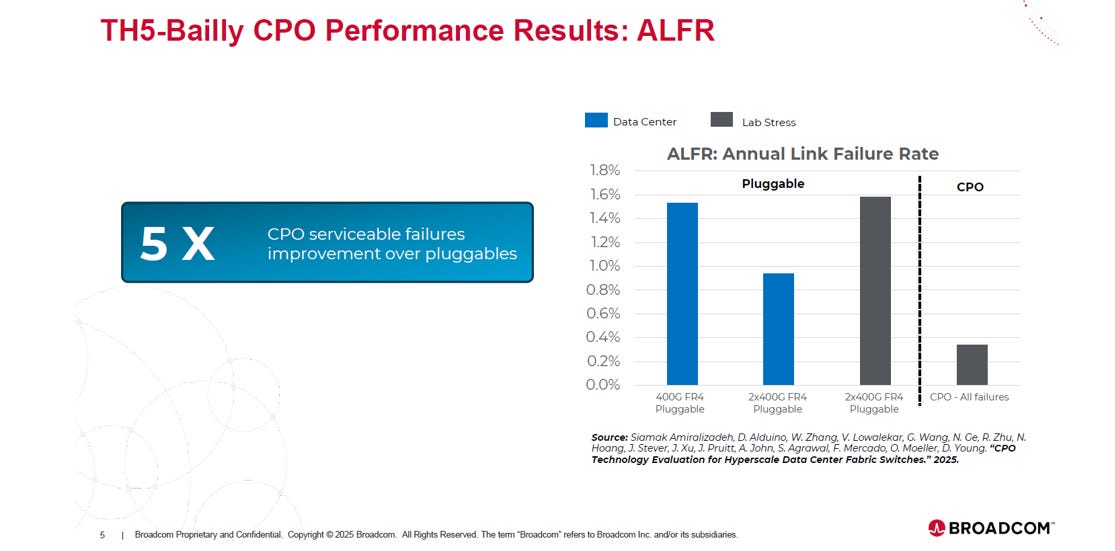
Source: Broadcom
可靠度大躍進: CPO 的可維修故障率 (Serviceable Failures) 相比傳統可插拔模組 (Pluggables) 改善了 5 倍 (5X)。
故障率對比:
傳統模組 (Pluggable):年故障率約在 1.0% ~ 1.6% 之間 (視 400G/2x400G 規格與測試條件而定)。
CPO 系統:年故障率大幅壓低至 約 0.3%。
這項數據打破了「光學整合進晶片會導致整機故障率飆升」的迷思。Broadcom 證明了 CPO 系統的穩定性不僅不輸給傳統模組,甚至更加可靠,大幅降低了資料中心的維運負擔
3. MTBF(平均故障間隔時間, Mean Time Between Failures)
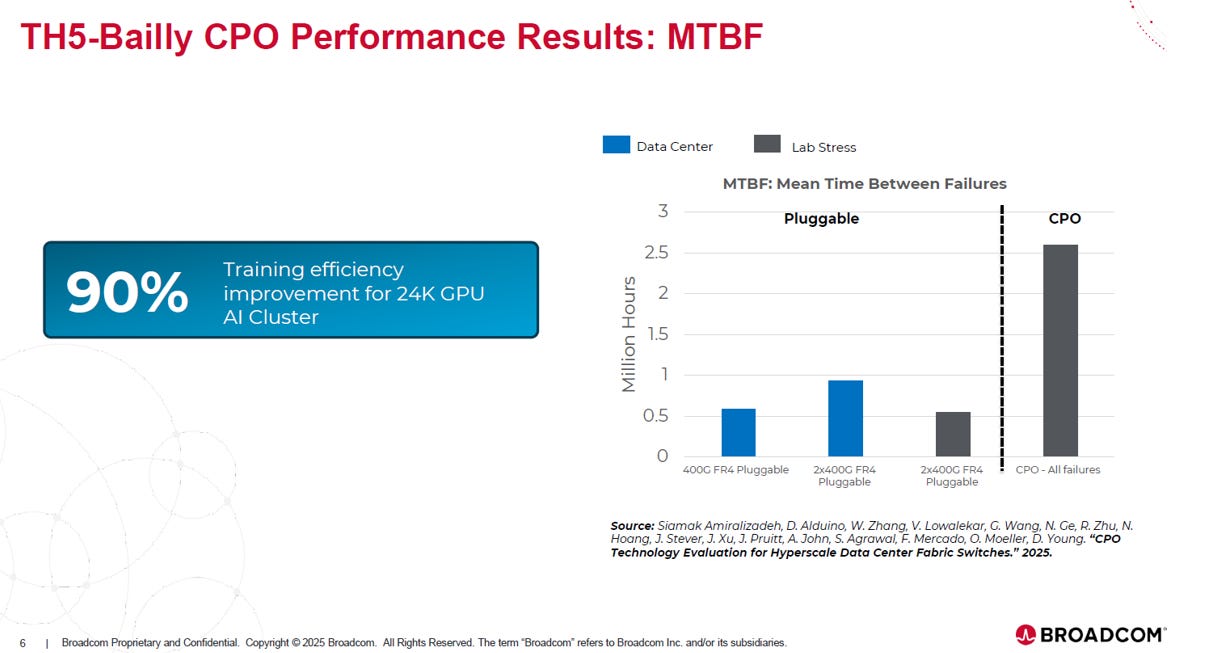
Source: Broadcom
可靠度輾壓傳統模組:
CPO 表現:MTBF 高達 250 萬 (2.5M) 小時以上。
傳統模組 (Pluggable):MTBF 僅約 50 萬 ~ 90 萬小時 (視規格而定)。
差距:CPO 的平均無故障運行時間是傳統模組的 3 倍以上。
對 AI 訓練的巨大價值:
圖中強調:在擁有 24,000 顆 GPU 的超大型 AI 叢集中,採用 CPO 能帶來 90% 的訓練效率提升 (Training efficiency improvement)。
原因:AI 模型訓練通常需要數週不間斷運行,任何單點故障都可能導致任務暫停或回滾 (Checkpoint restart)。CPO 極高的 MTBF 大幅降低了這種中斷風險,確保昂貴的算力資源能全速產出。
請AI畫的梗圖

3. Celestial AI 技術
3.1. Interconnect Bottleneck
AI 硬體擴展的兩大物理死結,也就是 互連瓶頸 (Interconnect Bottleneck):

Source: Celestial AI
岸邊密度牆 (The Beachfront Limit):
電子 (左圖):晶片的算力與容量是按面積 (mm²) 成長,但傳統銅線 I/O 只能擠在晶片四周的邊緣 (mm)。這導致「晶片越大,越餵不飽數據」,形成嚴重的 I/O 阻塞。
光學 (右圖):Celestial AI 利用光中介層,讓數據能從晶片底部的整個面積垂直進出 (mm²)。頻寬與算力同步以平方倍數擴展,徹底打破了邊緣限制。
距離延遲惡夢 (Latency vs. Distance):
電子:傳輸距離越長,延遲越高 (延遲 ~ 長度 x 1ns/mm),這限制了記憶體只能緊貼著 GPU。
光學:光速傳輸的延遲幾乎是常數且極低 (延遲 ~ 長度 x 0.02ns/mm)。這意味著記憶體可以被移到幾公尺外的機櫃 (Disaggregation),而 GPU 存取它的速度感覺像在旁邊一樣快,這是建構超大規模 AI 記憶體池的物理基礎。
3.2. Photonic Fabric
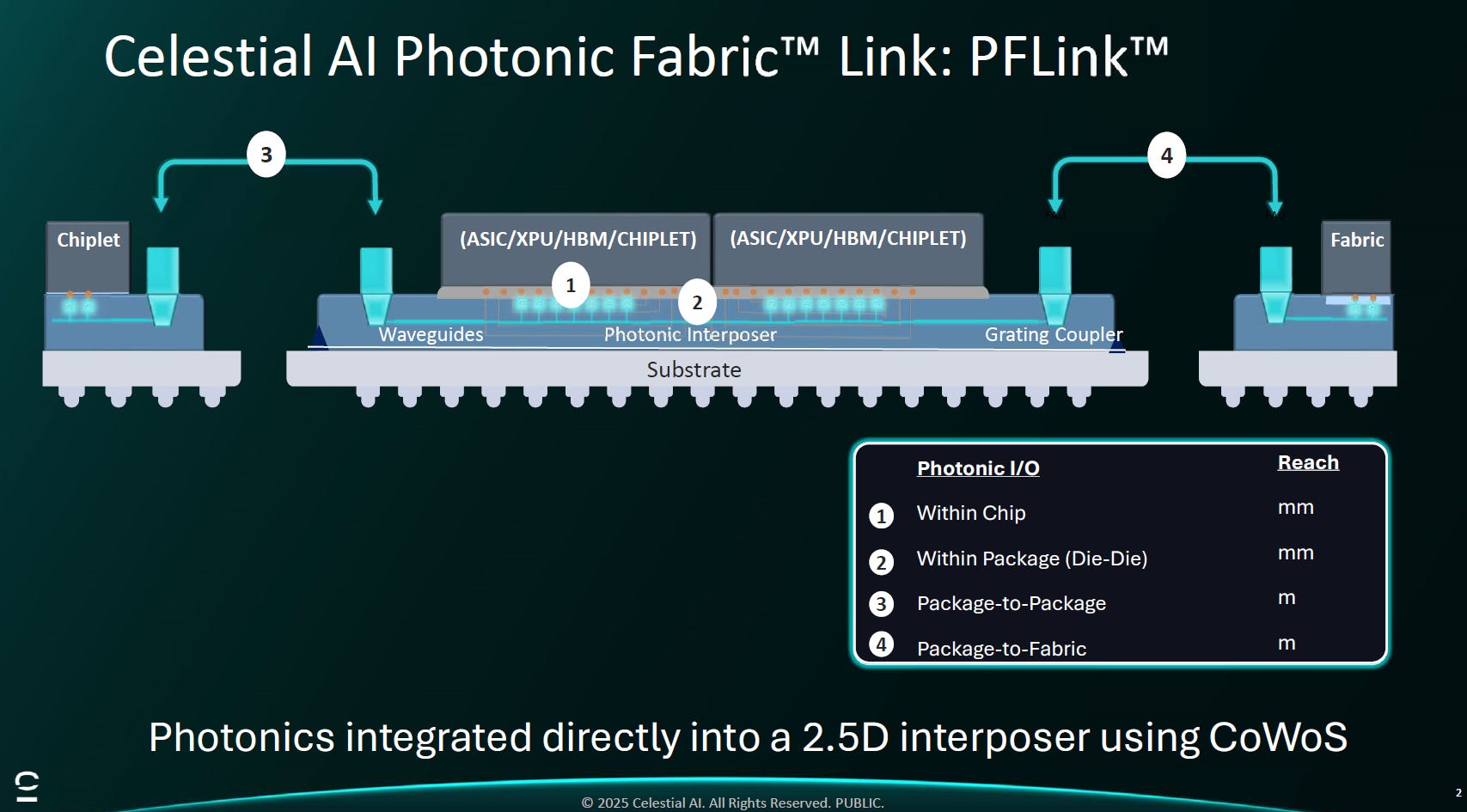
Source: Celestial AI
架構:基於 CoWoS-L
不同於將光模組放在晶片旁 (Side-car),Photonic Fabric 是直接埋在運算晶片 (ASIC/XPU) 與 HBM 底下。
整合方式:利用 TSMC CoWoS-L 封裝技術,將光波導與光元件整合在 2.5D 中介層內。
通訊範圍:這層光學織物同時處理 Chip-to-Chip (mm級) 到 Package-to-Package (m級) 的所有互連需求

Source: Celestial AI
核心:EIC + PIC /OMIB
這是 Marvell 收購它的技術關鍵。圖中剖面 顯示其光引擎 (PFLink™) 採用 3D 堆疊結構:
調變器:明確標示採用 EAM (電吸收調變器)。證實其為了在 GPU 高熱環境下運作,捨棄了熱敏感的 MRM,選擇了兼具小尺寸與熱穩定性的 EAM。
電晶片 (EIC):採用 TSMC 4/5nm 製程的控制晶片 (含 SerDes, TIA, Driver),直接堆疊在光晶片 (PIC) 之上,實現極短的電路徑。
光源:採用 ELS (外部雷射源),透過光纖陣列 (FAU) 引入,將熱源隔離。
目的:記憶體解構 (Memory Disaggregation)
這套技術的終極目標是讓 HBM 不再受限於 GPU 的物理邊緣,能透過光學連結建立龐大的遠端記憶體池 (Memory Pool),讓 AI 模型訓練突破單機容量限制。
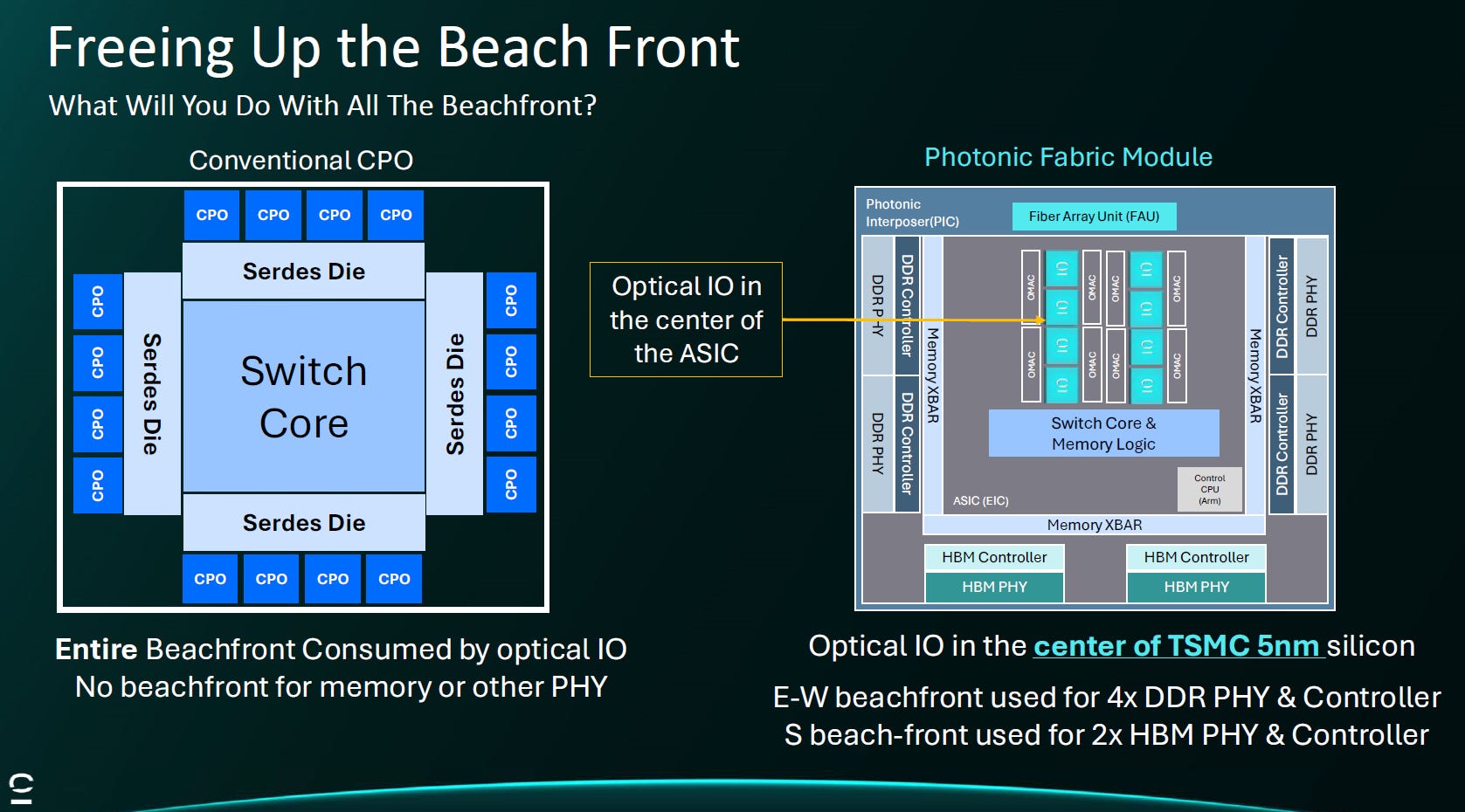
Source: Celestial AI
傳統困境 (Conventional CPO): 一般 CPO 方案將光引擎放在晶片四周邊緣。這導致晶片邊緣被光通訊介面完全佔滿 (Consumed),擠壓了記憶體 (HBM/DDR) 的 PHY 與控制器空間,造成「有算力、但記憶體頻寬不足」的窘境。
Celestial 解法 (Vertical Offload): 利用光中介層技術,將光 I/O 移至 ASIC 的正中心 (Center),透過底部的垂直互連直接進出數據。這將 I/O 模式從受限的「邊緣 (Edge)」轉變為廣闊的「面積 (Area)」。
釋放岸邊效益 (Freeing Up): 騰出來的晶片邊緣現在可以重新分配給最需要它的記憶體介面。圖中顯示,釋放後的邊緣可用於放置 4組 DDR 與 2組 HBM 控制器,實現了算力、光傳輸與記憶體頻寬的同步擴展,不再顧此失彼。
3.3. OMIB(Optical Multichip Interconnect Bridge)
OMIB (Optical Multichip Interconnect Bridge) 的構造與原理,直覺上OMIB的名稱就是 「光學版的 Intel EMIB(Embedded Multi-die Interconnect Bridge)」,但是用TSMC CoWoS-L先進封裝。
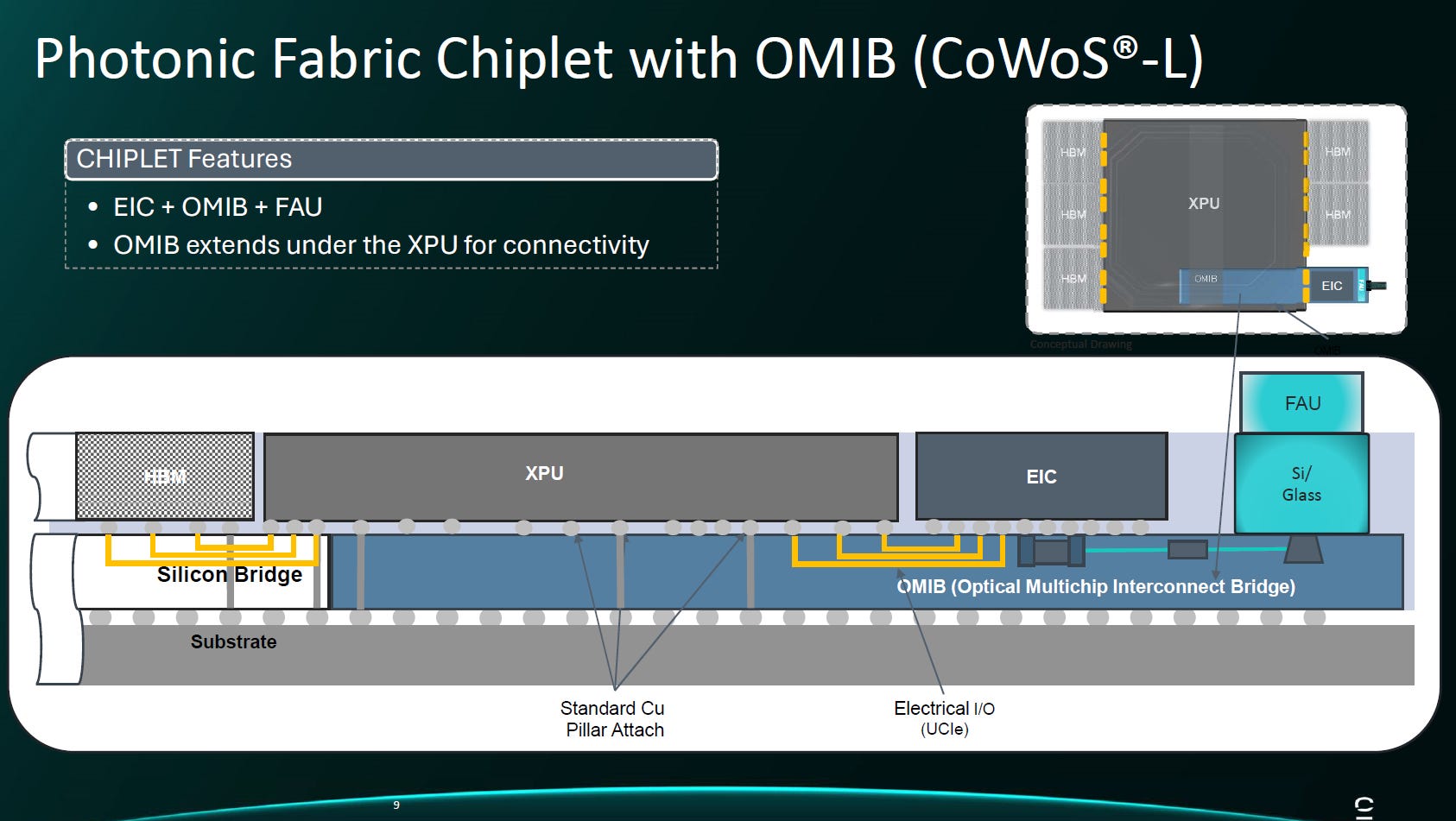
Source: Celestial AI
核心定義: OMIB 是一個埋入式(Embedded)的矽基橋接晶片。它就像 CoWoS-L的LSI(Local Silicon Interconnect),用來在基板內連接 GPU 和 HBM 一樣,OMIB 被用來在基板層級連接 XPU (運算晶片) 與 光學傳輸網路 (Photonic Fabric)。
關鍵創新:潛入晶片下方 (Under the Hood)
突破邊緣限制:圖中顯示 OMIB (藍色區塊) 直接延伸到了 XPU 的正下方。
垂直互連:XPU 不需要將訊號拉到擁擠的晶片邊緣 (Shoreline),而是透過底部的標準銅柱 (Standard Cu Pillar) 直接垂直向下傳給 OMIB。這徹底解決了 I/O 頻寬受限於晶片周長 (Beachfront density) 的物理瓶頸。
整合架構 (CoWoS-L)
技術基底:Celestial AI 採用了 TSMC 的 CoWoS-L 先進封裝技術。
完整模組:OMIB 不僅是橋接器,它上方還堆疊了負責控制的 EIC (電子晶片),側邊連接了 FAU (光纖陣列),形成一個完整的「光電轉換小晶片」模組。
OMIB 是 Celestial AI 借用了成熟的 CoWoS-L 埋入式橋接概念,將光通訊元件巧妙地隱藏在運算晶片的正下方,讓客戶無需大幅改動設計即可導入光傳輸。
3.4. Other solutions for Beachfront limitation
3.4.1 Lightmatter Passage M1000
相比於 Celestial AI 只是在基板裡埋入橋接晶片 (OMIB),Lightmatter 的 Passage™ M1000技術是革命性 (Revolutionary) 的:
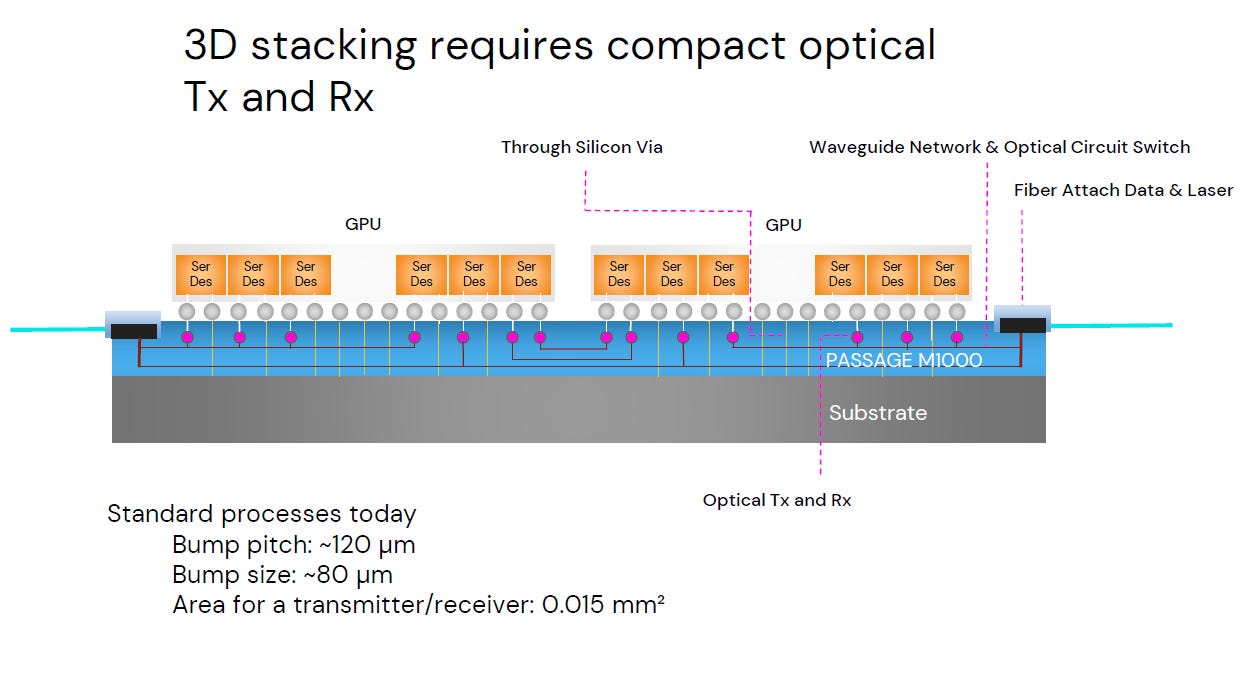
Source: Lightmatter
激進架構:晶圓取代 PCB (Wafer-scale) Lightmatter 不使用傳統有機基板,而是製造了一整片巨大的矽光晶圓 (Optical Interposer) 作為載體。客戶將 GPU 和 HBM 直接「種」在這片晶圓上,這意味著整台伺服器本質上變成了一顆「超級晶片」。
徹底消滅岸邊限制 (Zero Beachfront Constraint) 圖中顯示,光學收發器 (Tx/Rx) 均勻分佈在 GPU 的正下方。訊號透過 TSV (矽穿孔) 垂直打入底層的光波導網路,完全不需要擠在晶片邊緣。這讓 I/O 頻寬可以隨著晶片面積無限擴展。
內建光交換 (All-Optical Switching) 底層的藍色區塊不僅是傳輸線,還內建了 光路交換 (Optical Circuit Switch, OCS) 功能。這讓晶片間的通訊可以直接在「地下」完成,無需經過外部的交換機與光纖跳線,實現了極致的低延遲與高能效。
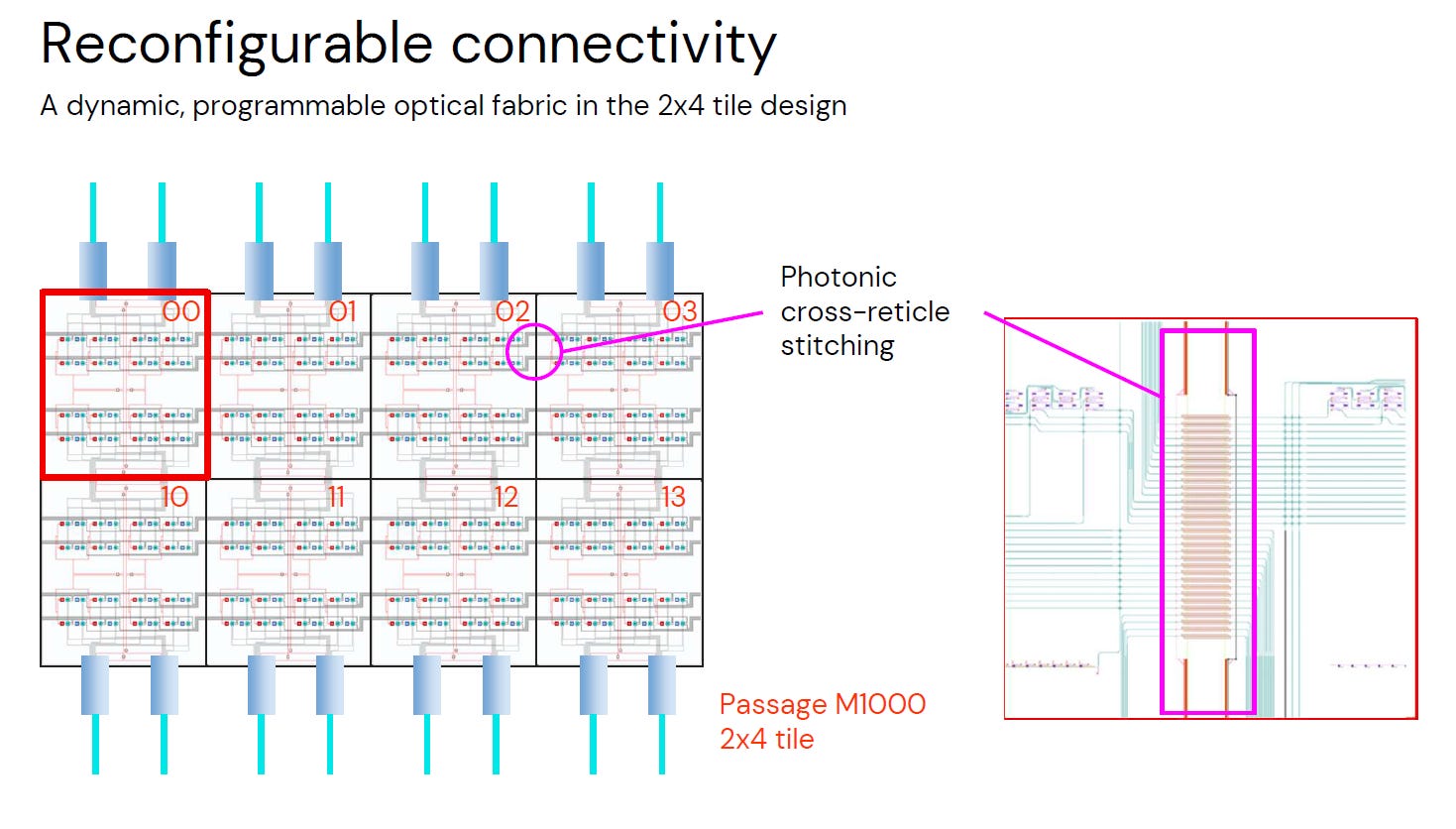
Source: Lightmatter
3.4.2. BRCM proposal
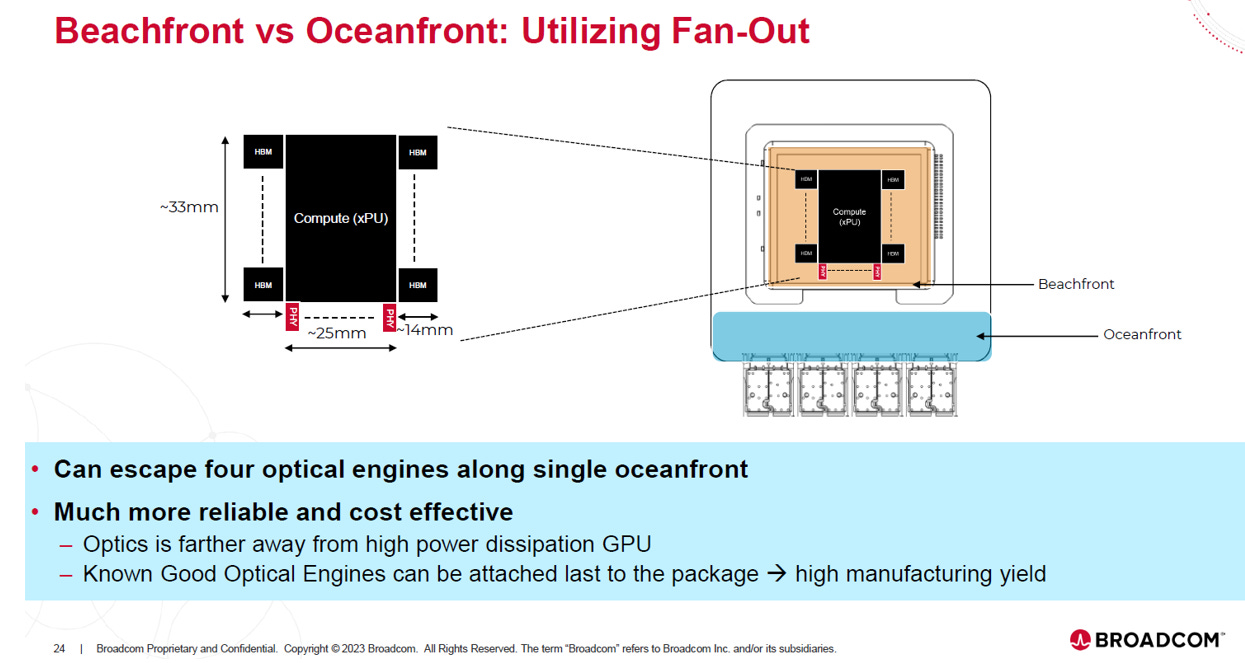
Source: Broadcom
這張投影片 展示了 Broadcom (博通) 解決晶片邊緣頻寬瓶頸 (Beachfront Limit) 的策略,其核心在於**「利用扇出型封裝 (Fan-Out) 擴大戰場」,但也伴隨著電氣路徑變長 (Longer E-path)** 的工程代價。
根本原因:MZM 體積太大
Broadcom 為了追求訊號穩定,堅持使用 Si-MZM。但 MZM 的物理尺寸 (長度 >1000µm) 遠大於競爭對手的 MRM 或 EAM,導致原本的晶片邊緣 (Standard Beachfront) 塞不下足夠數量的光引擎。
戰術:從 Beachfront 到 Oceanfront
為了安置這些巨大的 MZM,Broadcom 利用 Fan-Out (扇出型封裝) 技術,將封裝基板面積做得比晶片大,創造出更外圍、更寬闊的 “Oceanfront”。
這讓單邊能容納的光引擎數量翻倍 (例如達 4 組)。
代價與取捨:變長的 E-path
缺點:將光引擎推向外圍 “Oceanfront”,意味著 E-path (電氣路徑) 被迫拉長 (圖示約 14mm),增加了電訊號的傳輸損耗。
算盤:Broadcom 仗著業界最強的 SerDes 能力來補償這段損耗。他們寧願犧牲一點電氣效能,也要確保光引擎遠離高熱核心 (熱隔離),以換取 MZM 的高可靠度 與 量產良率。
總結: Broadcom 的 Oceanfront 策略是為了保住 MZM 路線所做的必要妥協。透過擴大封裝面積,他們成功解決了 MZM 的「佔地問題」與「散熱問題」,雖然 E-path 變長,但換來了系統級的穩定性與可製造性。
4. 補充
4.1 Photonic Fabric Main Application
Celestial AI 特別強調 Memory的應用,因為 AI 客戶的痛點已經轉移: 算力 (FLOPs) 已經夠便宜了,但要把資料搬進去運算 (Memory Bandwidth) 和存下巨大的模型 (Memory Capacity) 卻越來越難。
他們的解法公式是: OMIB (騰空間) + HBM-Cache 架構 (降成本) + PFLink (降延遲) = 無限擴充的 AI 記憶體層。

4.2. Marvell Structera CXL產品和應用
Marvell 收購 Celestial AI 之後,將自家的 Structera™ CXL 產品線 與 Photonic Fabric 結合,打造出新一代的光學記憶體系統。將 CXL 協定從「電的時代」帶入「光的時代」,藉此打破 AI 叢集的記憶體牆。

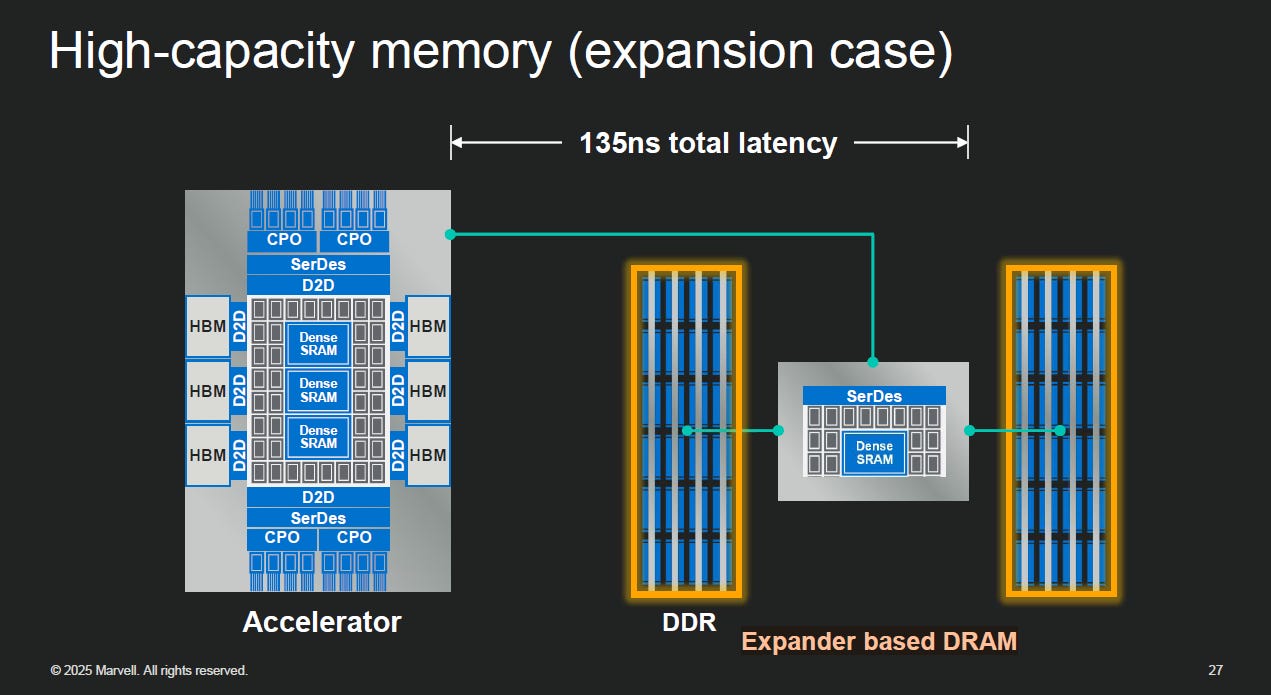
戰略方程式:CXL + UCIe + PFLink
這是兩家公司技術結合的完整路徑,實現了邏輯與物理的完美接力:
大腦 (Marvell): 使用 Structera™ CXL 控制器。它負責處理記憶體一致性、加密與管理,是系統的邏輯核心。
介面 (Joint): 透過 UCIe (Advanced) 介面。讓 Marvell 的控制器能以極低延遲與 Celestial AI 的光晶片 (EIC) 進行 Die-to-Die 溝通。
翅膀 (Celestial AI): 使用 PFLink™ 光學協定。將電訊號轉為光訊號,透過 OMIB 與光纖傳輸,實現跨機櫃的低延遲連接 (總延遲 ~135ns)
架構創新:以空間換取記憶體 (The Real Estate Trade)
Celestial AI 的核心價值不在於傳輸本身,而在於它如何改變晶片的佈局:
釋放岸邊 (Freeing the Beachfront): 傳統 CPO 佔用晶片邊緣,導致沒地方放記憶體。Celestial AI 利用 In-die (OMIB) 技術將光 I/O 移出晶片Beachfront。
記憶體最大化: 騰出的邊緣全部用於堆疊 HBM 與 DDR 控制器。
HBM-Cache 架構: 創造了 “HBM as Cache for DDR” 的層次結構,讓系統同時享有 HBM 的速度與 DDR (單模組 2TB) 的容量
物理實作:務實的微縮 (Pragmatic Scaling)
為了達成 In-die I/O,必須克服物理尺寸與熱限制:
元件選擇: 放棄了 Broadcom 使用的巨大 MZM (塞不進去) 和 Lightmatter 使用的熱不穩定 MRR (難以控制)。
解決方案: 採用 GeSi EAM (電吸收調變器)。它尺寸極小 (可高密度堆疊)、熱穩定 (Thermally Stable),且利用 TSMC CoWoS-L 成熟製程進行整合,具備量產可行性
Marvell 透過這次收購,從單純的「晶片供應商 (Selling Chips)」升級為「光學記憶體架構(Selling Architecture)」。他們現在能提供一套完整的 Optical CXL Appliance,解決 Google、Microsoft 等巨頭最頭痛的 AI 記憶體容量瓶頸。
4.3. 為何只有Celestial AI用EAM?
雖然 EAM 原理優點大家都懂,但要量產 GeSi EAM 極其困難,這構成了 Celestial AI 的技術壁壘。
IP 來源:
收購自 Rockley Photonics。Rockley 花費數年解決了鍺矽晶格不匹配 (Lattice Mismatch) 與暗電流 (Dark Current) 問題。
製程門檻:
為何 Ge PD(Power Detector) 容易,EAM 卻很難?雖然都用鍺 (Ge),但兩者難度天差地遠:
Ge PD (粗活): 只要能吸光就好 (深海區)。對晶格缺陷和能隙飄移的容忍度極高。
Ge EAM (精細活): 必須在「吸光/透光」的邊緣運作 (懸崖邊)。
需要極精準的 應力控制 (Strain Engineering) 和 成分配比。
Celestial AI 透過收購 Rockley Photonics,掌握了消除位錯與控制能隙的獨家 IP,這是其他晶圓廠尚未普及的技術。
專利保護:
由於擁有 Rockley 的專利組合,競爭對手若想模仿 GeSi EAM 路線,將面臨專利與製程參數重頭研發的雙重障礙。
Marvell 的戰略視角
Marvell 自己有 MZM (來自 Inphi),適合做長距離傳輸 (Switch)
Marvell 缺的是 EAM,適合做短距離高密度互連 (Compute)
Marvell 能夠用 EAM 技術鑽入 HBM 底部,結合自家的 DSP 與 CXL 控制器,打造出獨霸市場的 Optical CXL Fabric
4.4. Broadcom 的「雙刀流」策略
Broadcom 是務實主義者,OCP 2025 summit 的報告提出利用成熟的VSCEL,來做 NPO(基於 850nm/多模光纖),作為極致省電的備案。
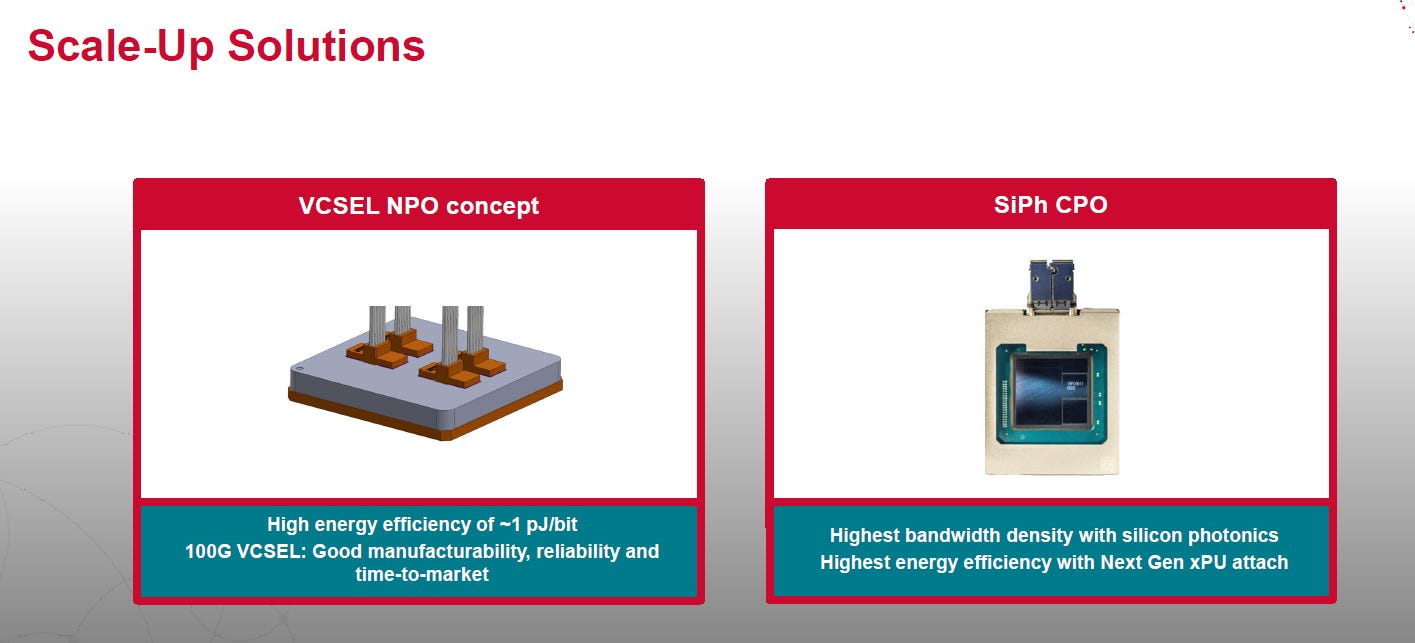

現在 (Switch CPO): 用 MZM (因為成熟、可靠)。但是pJ/bit高AEC。
未來 (AI Scale-Up): 準備了 VCSEL NPO作為對抗銅纜極限的備案。
這顯示了 Broadcom 靈活且防守嚴密的戰略,不押注單一技術。利用 VCSEL NPO 進攻短距離 AI 互連,同時用 MZM CPO 固守長距離交換機市場。
5. 後記(2026/1/28)
OMIB (Optical Multi-Chip Interconnect Bridge) 技術分析
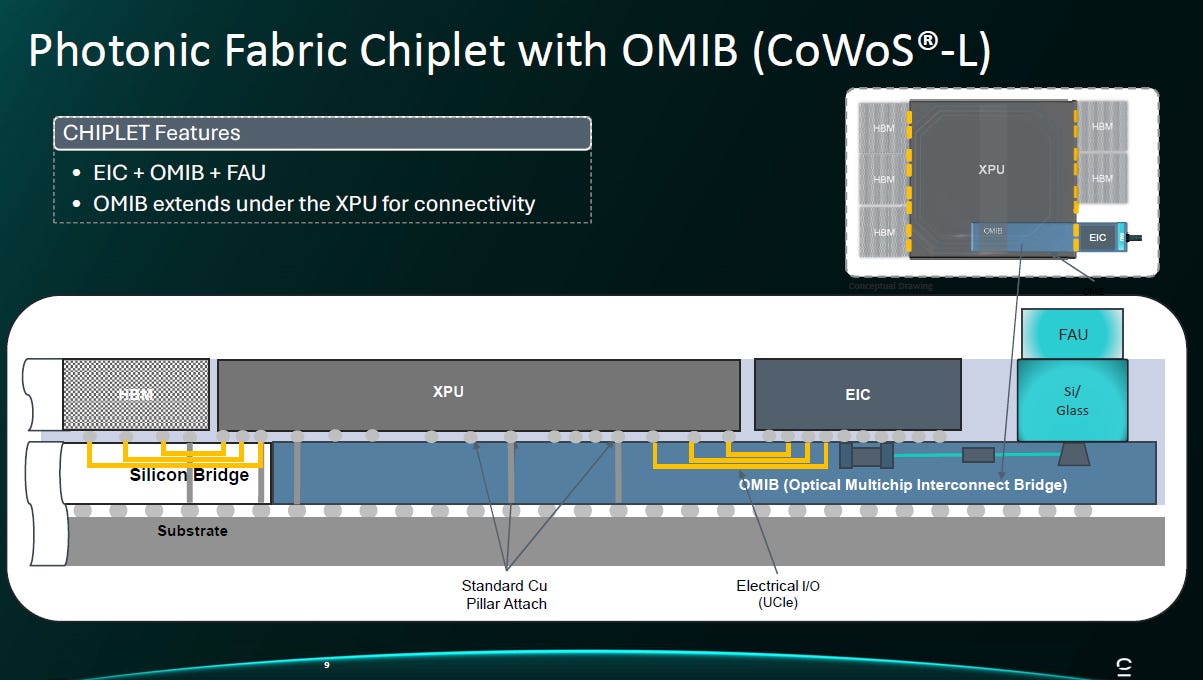
5.1. 執行摘要 (Executive Summary)
OMIB 是 Celestial AI Photonic Fabric™ 架構的核心元件,其本質為一顆 大型主動式矽光子積體電路 (Active PIC) 。它利用台積電 CoWoS-L 先進封裝技術,作為嵌入式的「矽光橋樑」,置於運算晶片 (XPU) 與基板之間 。OMIB 的革命性在於將光學 I/O 從晶片邊緣移至晶片正下方 (Vertical Area I/O),從而徹底打破了傳統晶片的「海灘前緣限制 (Beachfront Limitation)」。
5.2. 核心架構與定位 (Architecture & Positioning)
物理定位: OMIB 被嵌入在 CoWoS-L 的有機中介層 (Organic Interposer) 之中,物理位置處於 XPU/HBM (上層) 與 封裝基板 Substrate (下層) 之間 。
功能角色: 它同時扮演了「光學收發器」與「電氣橋樑」的雙重角色。
光學層:利用波導 (Waveguides) 與 EAM 調變器傳輸高速光訊號 。
電氣層:利用 TSV (矽穿孔) 為上方的 XPU 與 EIC 提供垂直電源與接地路徑 。
材料構成: OMIB 基於 SOI (Silicon-on-Insulator) 結構製造,利用矽與二氧化矽 (BOX, Buried OXide) 的折射率差異來傳導光訊號,並針對非光學區域進行結構優化 (如 Patterned SOI) 以利散熱與供電。
關鍵技術挑戰與解決方案 (Key Challenges & Solutions)
A. 打破 I/O 邊緣限制 (Solving Shoreline Limitation)
問題:傳統 CPO (Co-Packaged Optics) 仍需從晶片邊緣引出訊號,受限於晶片周長 (Shoreline),導致頻寬密度難以提升 。
OMIB 方案:實現 垂直區域 I/O (Vertical Area I/O)。OMIB 延伸至 XPU 的核心區域正下方,數據直接從 XPU 肚子底下的微凸塊 (Micro-bumps) 垂直注入 OMIB,不再需要繞道至晶片邊緣 。
B. 垂直供電難題 (The Power Delivery Challenge)
矛盾點:OMIB 面積巨大且位於 XPU 正下方,其矽基板與氧化層 (BOX) 本質上會阻斷來自底層基板的電源供應。
解決方案:引入 TSV (矽穿孔) 技術。儘管 CoWoS-L 的初衷是不用 TSV,但 OMIB 必須在非光路區域打上 TSV,建立垂直的電源 (Power) 與接地 (Ground) 通道,確保上方的 XPU 與 EIC 能獲得電力供應 。
C. 訊號驅動路徑 (Signal Driving Path: EIC then PIC)
架構:XPU 無法直接驅動光訊號。
流程:
XPU <—> OMIB:邏輯電訊號垂直向下傳至 OMIB 。
OMIB <—> EIC:電訊號經由 OMIB 內部的水平線路傳至 EIC (驅動晶片) 。
EIC <—> PIC:EIC 將訊號放大後,再次垂直向下驅動 OMIB 內的 EAM 調變器 (Tx) 或接收 PD 訊號 (Rx) 。
產業影響與協同設計 (Co-design Implications)
晶片佈局重構 (Floorplan Co-design): 由於 I/O 介面從邊緣移至中心,XPU 供應商 (如 NVIDIA, Broadcom) 必須配合 Celestial AI 重新設計晶片的 Floorplan,將 SerDes/UCIe 電路佈局在晶片中央以對準 OMIB 的接觸點。
熱管理策略 (Thermal Management): 由於 OMIB 夾在熱源 (XPU) 與散熱路徑中間,其設計需採用 局部 BOX (Patterned SOI) 策略:僅在光波導路徑保留絕緣層,其餘區域移除 BOX 以最大化 TSV 的導電與導熱效率。
結論 (Conclusion)
OMIB 是一個 「以 SOI 為基礎,具備 TSV 供電能力,並嵌入於 CoWoS-L 結構中的大型主動式 PIC」。它不僅僅是傳輸介質,更是一種改變晶片設計邏輯的架構創新。透過犧牲部分的製程複雜度 (如 TSV 與 Co-design),它換取了矽光子領域最關鍵的戰略優勢——徹底打破了傳統晶片的「海灘前緣限制 (Beachfront Limitation)」。