EP25. UCIe Over Optics

前兩期介紹了微軟 Azure 光學互連分類的兩個方法,本次報告介紹另一方法,"Slow and Wide",也是目前主流CPO多採用的方法,並且會以UCIe(Universal Chiplet Interconnect Express)開放標準為主,分享個人心得,歡迎討論。
1. 前提
1.1. Optical “Slow and Wide”
Microsoft Azure 的投影片將光學互連技術(Optical Technology)分為三個方法: EP23. 介紹了Fast and Narrow, 448G SerDes; EP24. 介紹了Slower and Wide, MicroLED Interconnect,這次介紹「Slow and Wide」
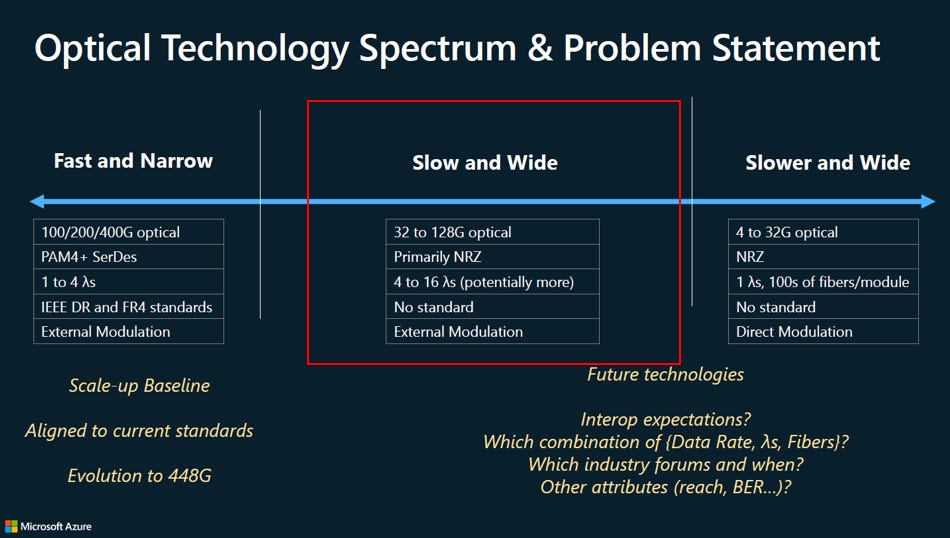
「Slow and Wide」 的核心策略是 「以多通道換取低功耗與低複雜度」:
不追求單通道極速(Slow): 採用技術較成熟、主要採用簡單且省電的 NRZ 編碼,單通道速率維持在中等的 32G-128G,避開了高速 PAM4 的高功耗問題。
靠多波長堆疊頻寬(Wide): 改用 4 到 16 個波長(甚至更多)並行傳輸(WDM,Wavelength Division Multiplexing),透過增加通道數量來達成所需的總頻寬。
最大隱憂: 目前 缺乏統一標準(No standard),業界對於該採用哪種速率與波長的組合尚未達成共識,導致互通性不明。本次介紹UCIe Over Optics,應該會成為業界的標準。
1.2. 光電元件的發展
來自 Yole Group 的圖表將光電元件的發展路徑分為兩大類,並依據單波長傳輸速率(Speed per lambda)與材料技術進行了詳細分類:
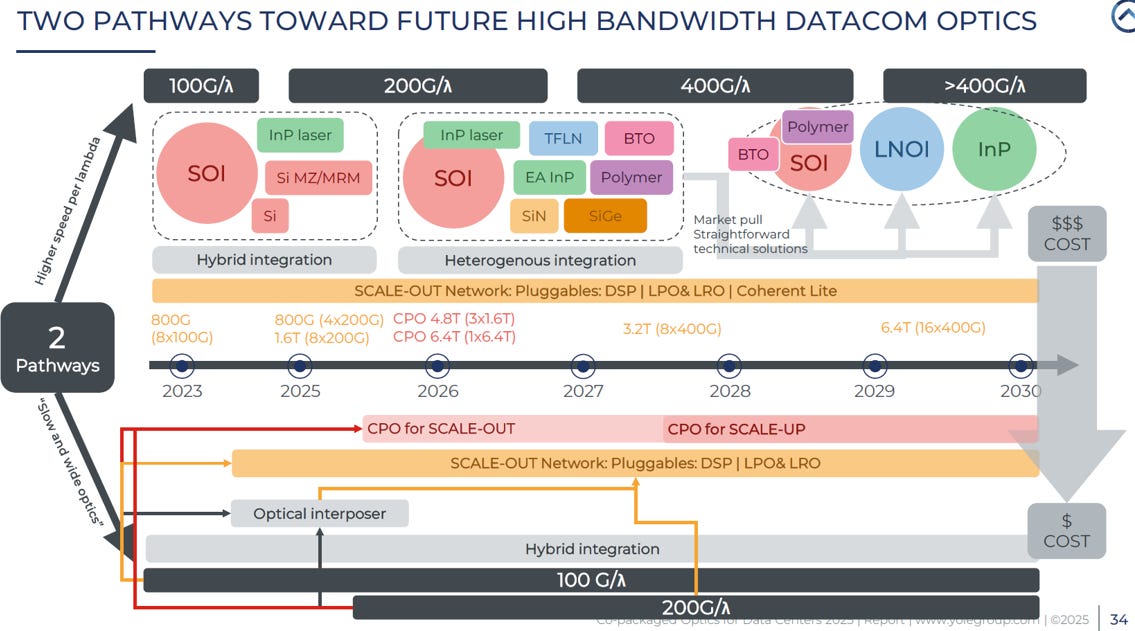
Fast & Narrow: 拚速度、換材料
策略: 不斷提升「單波長」傳輸速率(從 200G 邁向 400G 以上)
代價: 傳統矽光子(SiPH)不敷使用,必須引入 TFLN(薄膜鈮酸鋰)、LNOI 或 InP 等昂貴的新材料 (參考 EP23. 448G SerDes)。
特徵: 性能極致,但成本最高($$$)
Slow & Wide: 拚架構、走並行(Slow and Wide)
策略: 維持技術成熟且便宜的 100G/200G 速率,改用**「多通道並行」**
手段: 依賴 CPO(共同封裝光學) 和光中介層技術來提高整合度
特徵: 避開昂貴材料,主打低功耗與成本效益
這張圖表傳達了一個核心訊息:為了達成未來的高頻寬,光電產業界有兩條路可選。一是**「換材料」(用 TFLN/LNOI 拼單通道極速,但貴);二是「換架構」**(用 CPO 走 Slow and Wide,用成熟材料拼多通道,省電且控制成本)。
1.3. Chiplet and 異質整合時代的到來
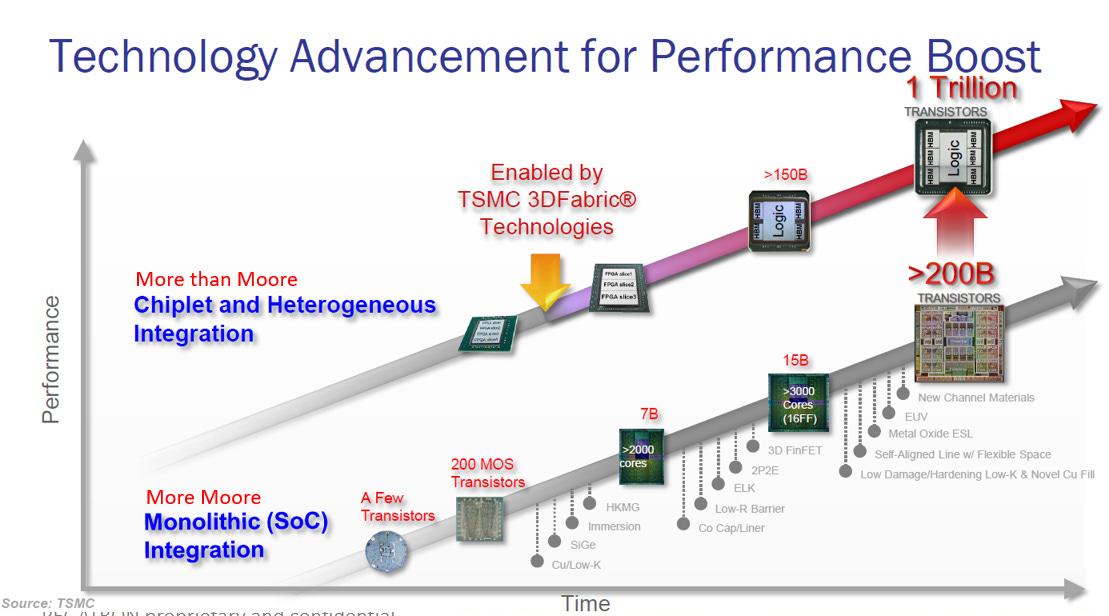
這張圖說明了半導體產業為何必須從單晶片(Monolithic)轉向 Chiplet(小晶片)與異質整合(Heterogeneous Integration),其背後的驅動力三大關鍵因素:
突破物理尺寸限制 (Reticle Limit): 曝光機的光罩面積上限約為 858 mm² (26 x 33 mm)。單晶片無法做得比這更大,唯有透過 Chiplet 拼接技術,才能製造出超過此面積的超級晶片(參考EP.11,12, 13)
優化成本與良率 (Cost & Efficiency): 大尺寸晶片良率低且昂貴。將其切分成小晶片 (Chiplet) 可提升良率,並允許將昂貴的先進製程 (運算核心) 與便宜的成熟製程 (I/O) 混搭,大幅降低製造成本。
滿足 AI 極致效能 (AI Performance): AI 運算需要海量電晶體 (邁向 1 萬億個) 與高速記憶體。異質整合透過先進封裝 (如 3DFabric) 將邏輯晶片與 HBM (高頻寬記憶體) 緊密連接,解決傳輸瓶頸,實現高效能運算。
令人驚訝,早在 60年前(1965), 高登·摩爾就預言了今天的發展:

預言內容: 他指出當製造單一大晶片變得不划算時,將系統拆解成**「較小的功能區塊」並「分開封裝互連」**會是更經濟的選擇。
完美對應: 這段話完全預告了現在的 Chiplet(小晶片)、先進封裝與 UCIe互連技術。
意義: 證明了異質整合併非背離摩爾定律,而是執行了摩爾 60 年前就預想好的「下半場策略」,用「分而治之」來延續效能成長與經濟效益。
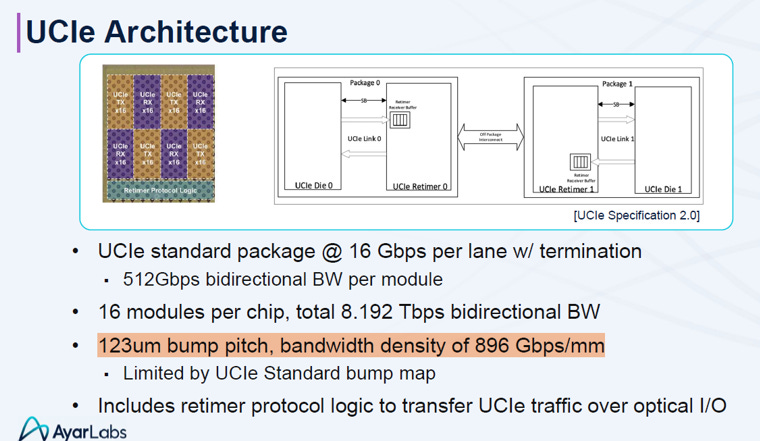
2. UCIe(Universal Chiplet Interconnect Express)
2.1. 歷史:從分裂走向統一
起源 (2022年3月): 由 Intel 發起並捐贈其 AIB (Advanced Interface Bus) 技術作為基礎,成立 UCIe 聯盟。
大一統 (巨頭集結): 集結了 台積電 (TSMC)、AMD、日月光 (ASE)、Google、Microsoft 等半導體製造、設計與終端巨頭,正式結束了各廠私有協定互不相通的「戰國時代」。
演進 (快速迭代): 短短兩年內從 1.0 (支援 2D/2.5D 封裝) 迅速演進至 2.0 (支援 3D 堆疊),確立了其作為 Chiplet 開放生態系唯一通用標準的地位。

2.2. 核心應用
「將單晶片 (SoC) 解構,重組為封裝級系統 (SiP)」

具體體現在:
混搭組裝: 允許將不同廠商、不同製程的功能區塊(如 CPU、GPU、I/O),像堆積木一樣在封裝內組裝。
標準介面: 扮演 「封裝內部的 USB/PCIe」 角色,解決各家小晶片互不相通的問題,是實現 AI 高算力與異質整合的關鍵標準。
2.3. 分層架構 (Layered Architecture)
UCIe 1.0 架構採用類似網路通訊的分層設計,以確保互通性與彈性,主要包含三層:
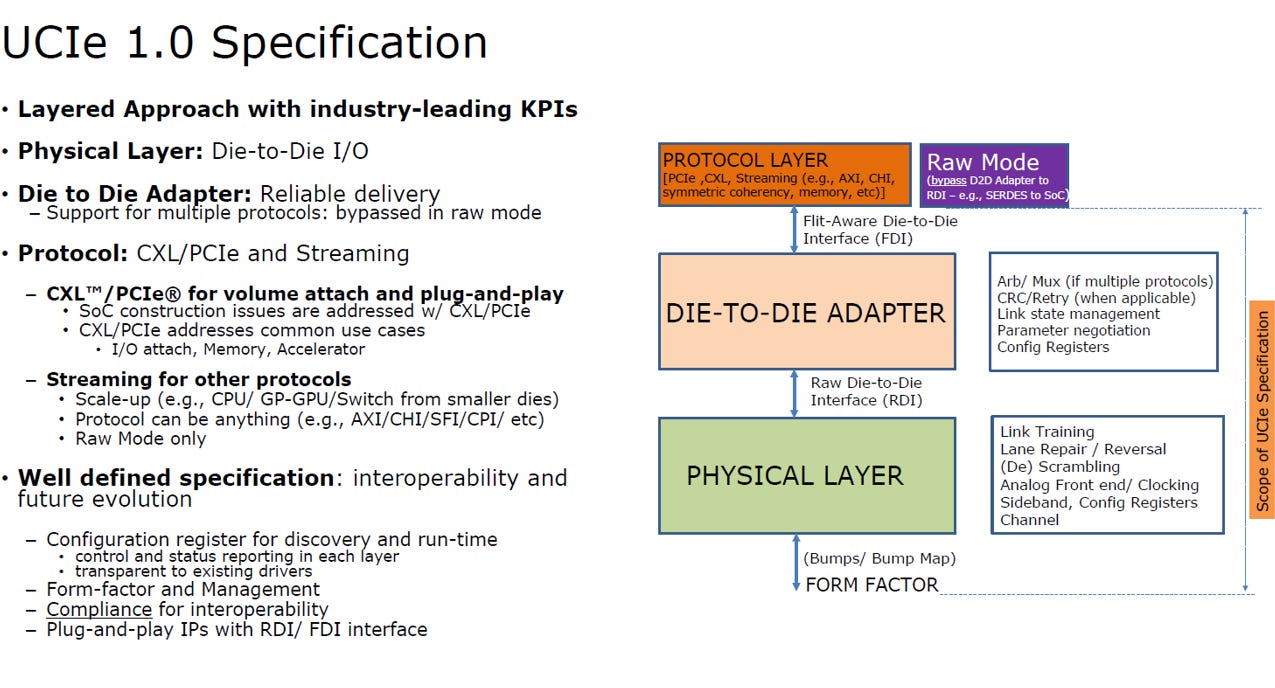
協定層 (Protocol Layer):
原生支援 PCIe 與 CXL 標準,確保軟體能「隨插即用」
支援 Streaming 協定,允許廠商自定義通訊方式
D2D 配接層 (Die-to-Die Adapter):
負責資料傳輸的可靠度,處理錯誤檢查 (CRC) 與重傳 (Retry) 機制
實體層 (Physical Layer):
負責實際的電氣訊號連接、時脈同步與線路修復 (Lane Repair)
特殊功能 (Raw Mode):
允許資料跳過中間的配接層直接傳輸,以犧牲部分糾錯功能換取極低延遲。
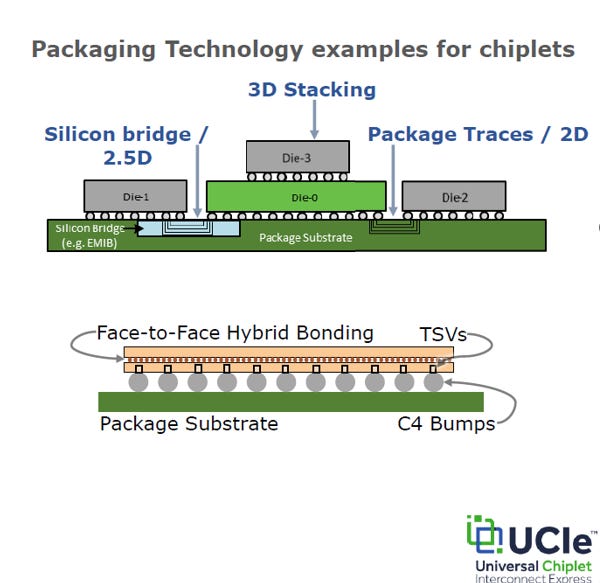
2.4. 與封裝技術的關係
UCIe 與封裝技術的關係可以比喻為:「封裝是道路,UCIe 是交通規則」。UCIe 制定了統一標準,讓晶片能適應不同的道路狀況:
UCIe 1.0 (平面世界):
UCIe-S 2D (標準封裝): 使用一般基板傳輸,成本最低,適合大眾化應用。
UCIe-A 2.5D (先進封裝): 使用矽中介層或矽橋接 (如 TSMC CoWoS; Intel EMIB),提供高頻寬和高密度,是目前 AI 晶片的主流。
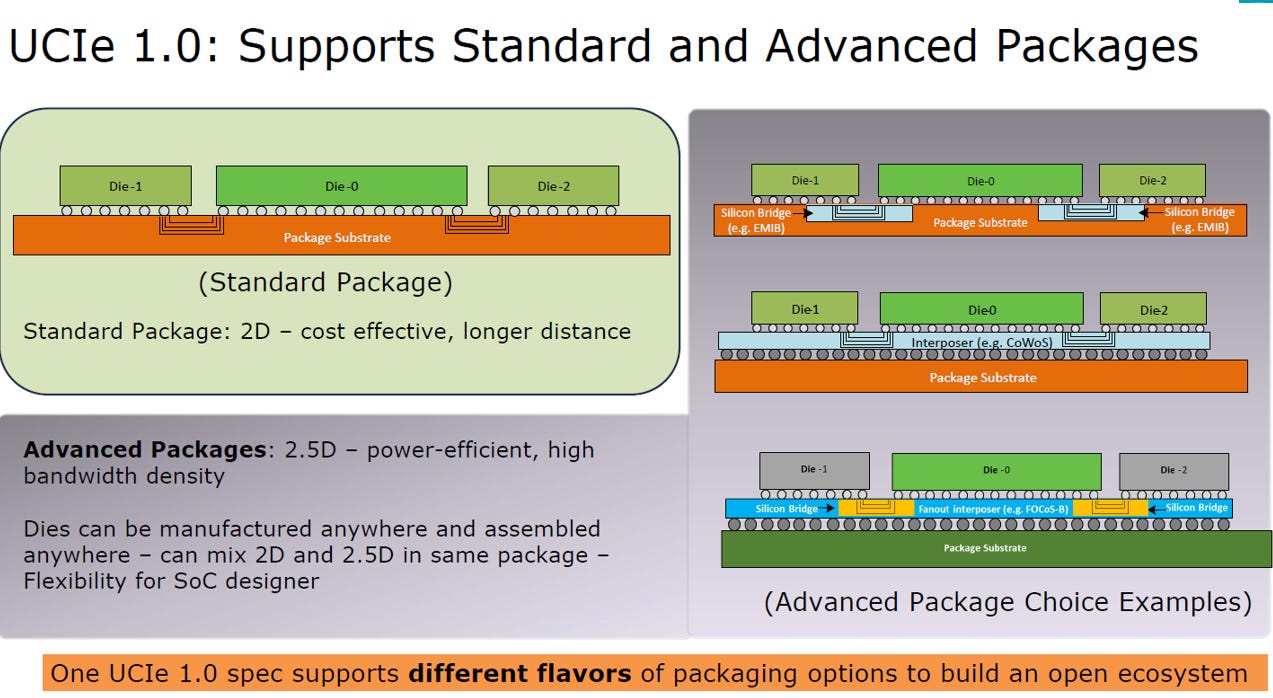
UCIe 2.0 (立體世界):
UCIe-3D 3D (垂直堆疊): 支援矽穿孔(Through Silicon Via,TSV)和混合鍵合 (Hybrid Bonding) 技術,實現晶片垂直堆疊,擁有最佳能效與最低延遲。
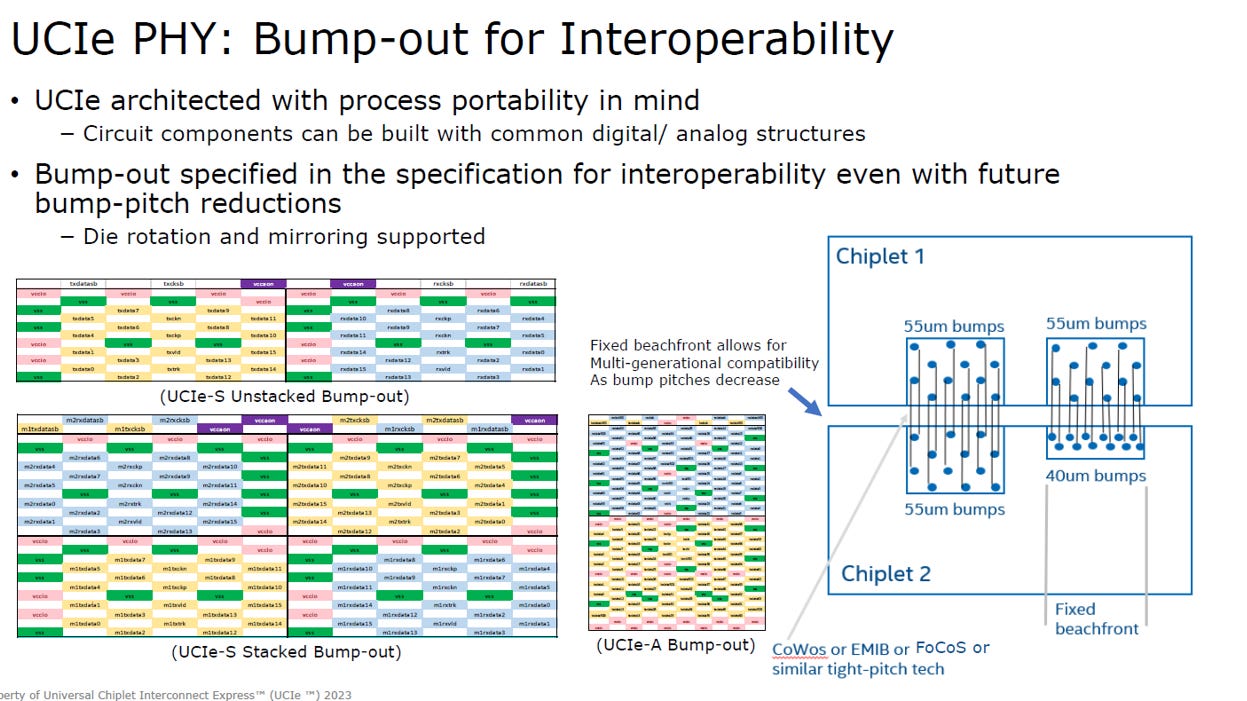
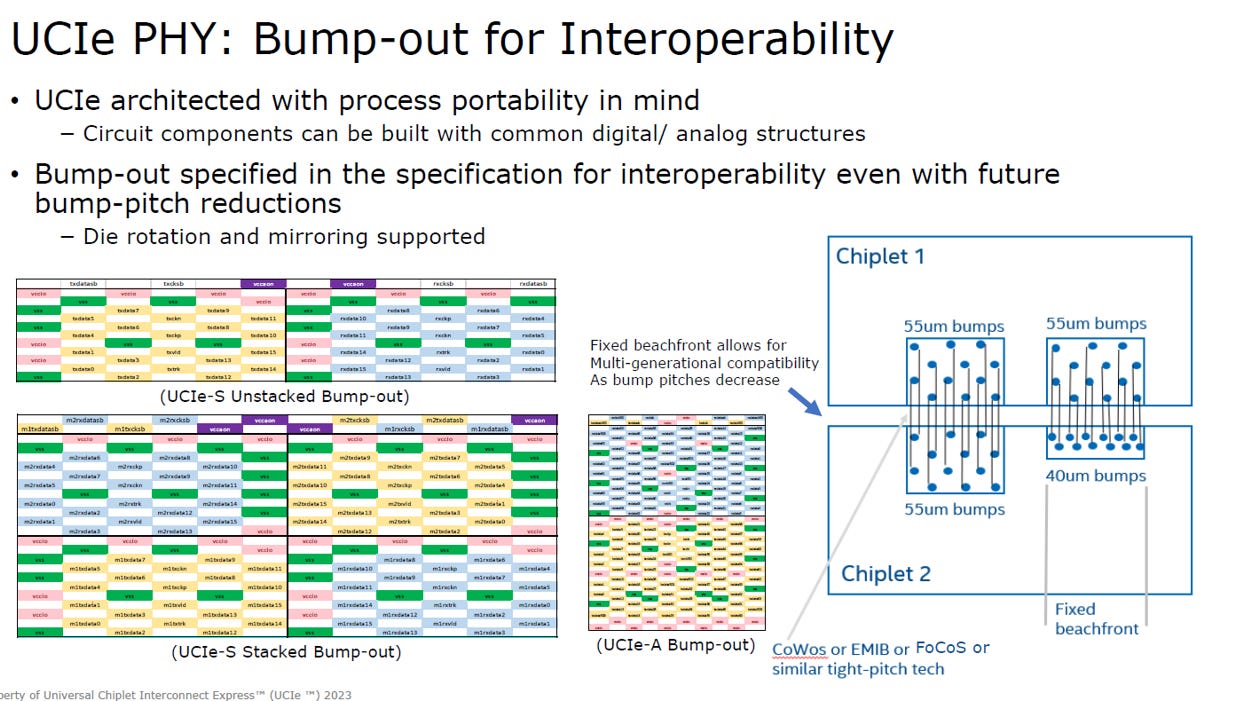
UCIe 也定義 Bump Map (凸塊排列圖) ,核心目的是實現「硬體層級的互通性」,確保不同廠商的晶片能精準物理對接:
2D/2.5D 策略 (固定海岸線):
規定介面的總寬度 (Beachfront) 必須固定。即使未來微凸塊間距 (Pitch) 縮小,新舊製程晶片仍能透過相同的介面寬度互連,保障跨世代相容。
3D 策略 (高密度矩陣):
針對垂直堆疊定義了鏡像對稱的訊號矩陣 (如 x80 模組),支援極微小的間距 (如 9um),以配合矽穿孔(Through Silicon Via, TSV) 和混合鍵合 (Hybrid Bonding, HB) 技術實現極致頻寬。
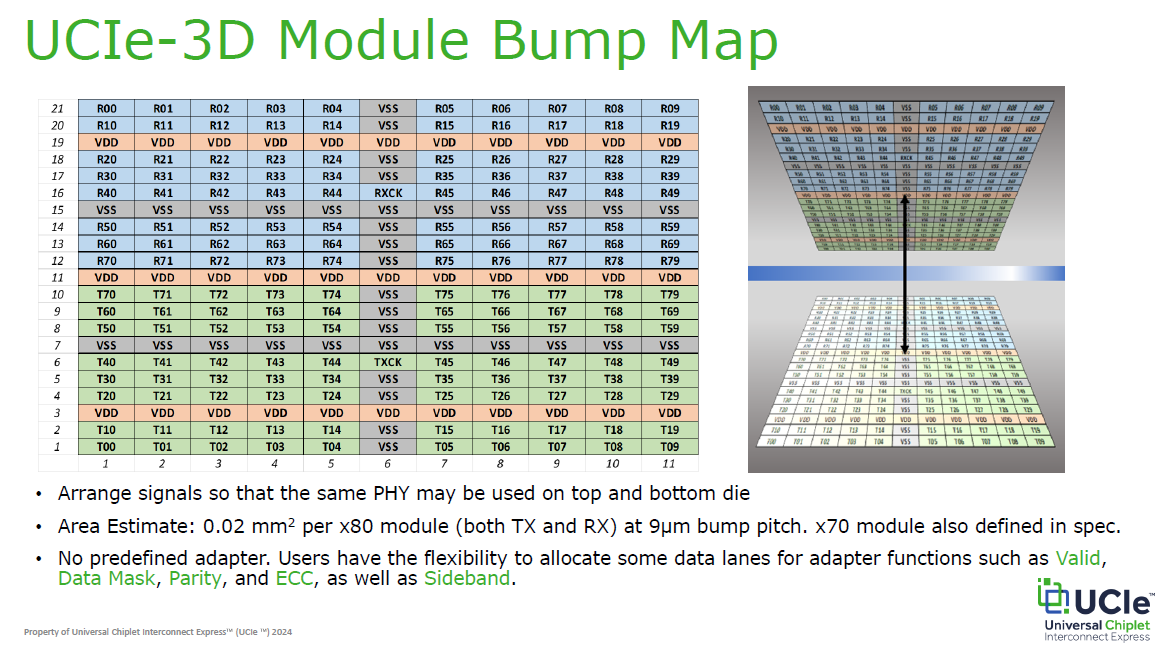
結論:
就像規定 PCIe 接頭的腳位一樣,UCIe 強制統一了晶片對接的物理地圖,讓「積木」能真正扣在一起。
2.5. PHY Spec
UCIe 實體層 (Physical Layer) 電氣特性簡述:

模組化架構 (Modular):
以「模組」為單位,支援 1、2 或 4 個模組 組合,可依需求彈性擴充總頻寬。
訊號設計 (Signaling):
資料 (Data): 採 單端訊號 (SE),以達成低功耗與節省面積。
時脈 (Clock): 採 差分訊號 (Differential),確保高速傳輸的穩定性。
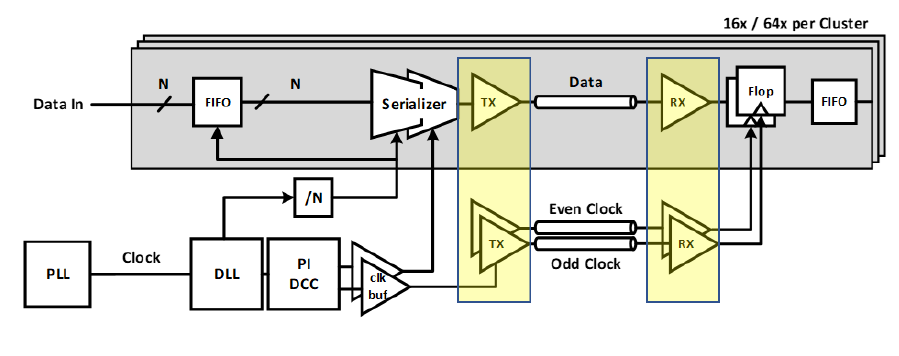
效能規格 (Performance):
速率: 支援 4 ~ 32 GT/s 多段速率,且必須向下相容。
頻寬: 先進封裝 (64 Lanes/模組) 的頻寬密度是 標準封裝 (16 Lanes/模組) 的 4 倍 (256 GB/s vs 64 GB/s)。
管理機制 (Management):
配置獨立且 永遠開啟 (Always-on) 的 側頻帶 (Sideband) 通道 (800 MHz),專責負責開機訓練、除錯與鏈路管理。
2.6. UCIe 3.0 關鍵指標
基於 UCIe 的規格定義,這三種封裝技術的差異可以用「維度」與「密度」來區分
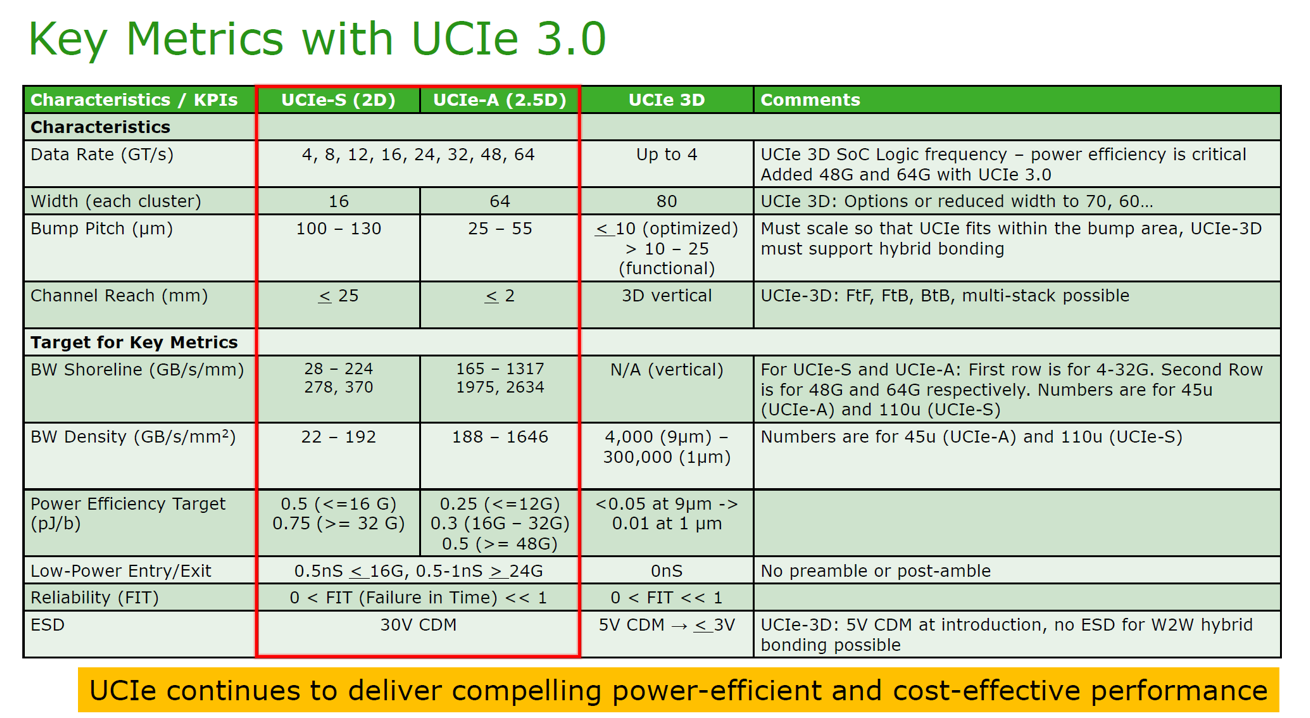
2D 標準封裝 (Standard Package) —— 「經濟實惠的平面道路」
技術特徵: 使用傳統的有機基板 (Organic Substrate) 進行連線。
關鍵指標: 凸塊間距 (Bump Pitch) 較寬 (100-130 μm),傳輸距離可長達 25 mm。
定位: 成本最低。適合對頻寬密度要求不高,但需要較長距離佈線或強調成本效益的晶片互連。
2.5D 先進封裝 (Advanced Package) —— 「高效能的高架快速道路」
技術特徵: 在基板與晶片之間加入中介層 (Interposer)、矽橋接 (Bridge) 或 高密度 RDL。
關鍵指標: 凸塊間距縮小至 25-55 μm,傳輸距離縮短至 2 mm。
定位: 頻寬密度高 (是 2D 的 10 倍以上)。這是目前 AI 晶片 (GPU + HBM) 的主流選擇,如 TSMC CoWoS 或 Intel EMIB。
3D 垂直封裝 (3D Integration) —— 「零距離的摩天大樓」
技術特徵: 使用 混合鍵合 (Hybrid Bonding) 技術,將晶片面對面直接堆疊,不使用傳統凸塊。
關鍵指標: 間距極微小 (< 10 μm),擁有極致的頻寬密度 (是 2.5D 的數百倍) 與最低功耗。
定位: 極致效能。用於 SoC 內部的垂直摺疊 (如 AMD 3D V-Cache, TSMC SoIC-X),實現幾乎無延遲的訊號傳輸。
總結:
從 2D -> 2.5D -> 3D,就是一條距離越來越短、密度越來越高、成本越來越貴的技術演進之路
2.7. Interconnect
2.7.1. In-Package Interconnect
這張 Benchmark 圖表確立了 UCIe 在互連技術中的王者地位,顯示其綜合效益(FOM) (頻寬密度 × 能效) 遠超傳統板級互連 (如 PCIe):
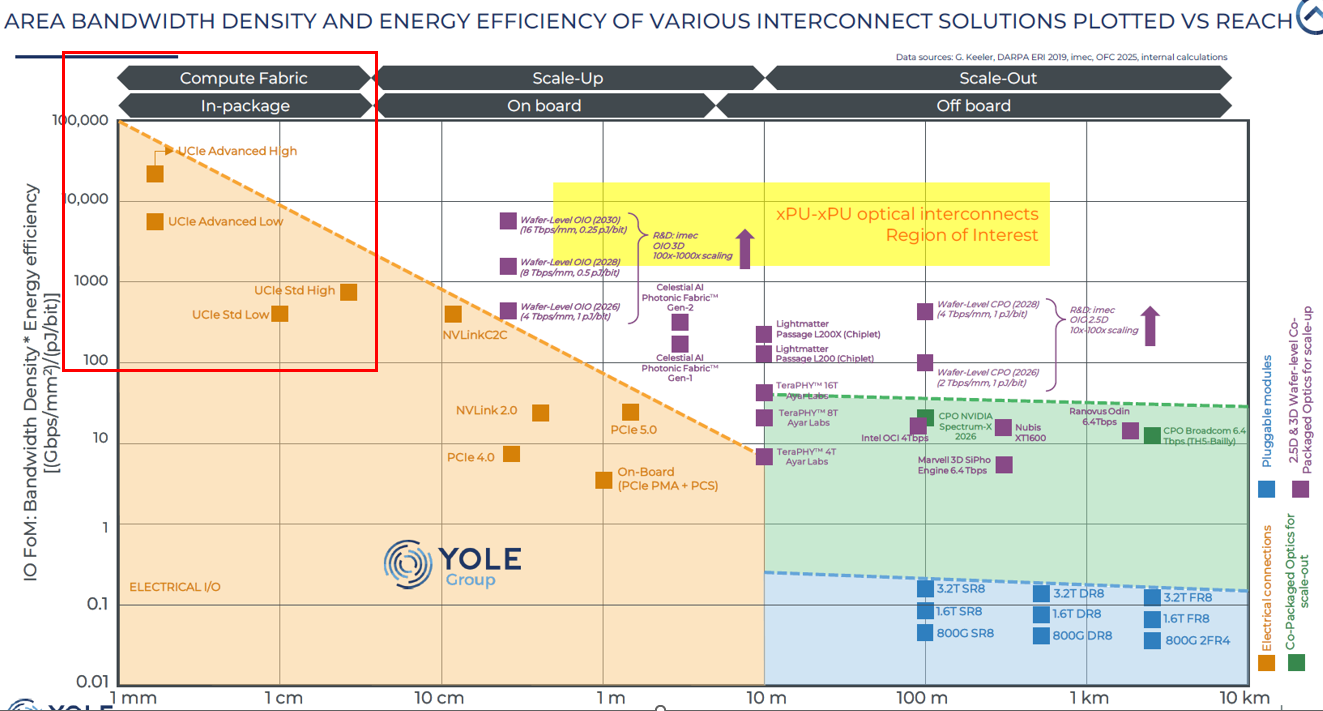
UCIe-A (Advanced) - 效能頂點:
位於圖表最左上角,代表在極短距離內擁有最高頻寬密度與最佳能效,是專為 AI/HPC 極致算力打造的頂級規格 (需搭配先進封裝)。
UCIe-S (Standard) - 中堅主力:
位於 UCIe-A 下方,雖效能略低於 A,但仍比板級的 PCIe 強大 10~100 倍,是兼顧成本效益與高效能的標準選擇 (使用標準封裝)。
結論:
圖表證明了**「距離越短,效益越高」**的物理鐵律,UCIe 透過將互連搬進封裝內 (In-package),達成了傳統技術無法企及的效能高度。
2.7.2. Off-Package Interconnect
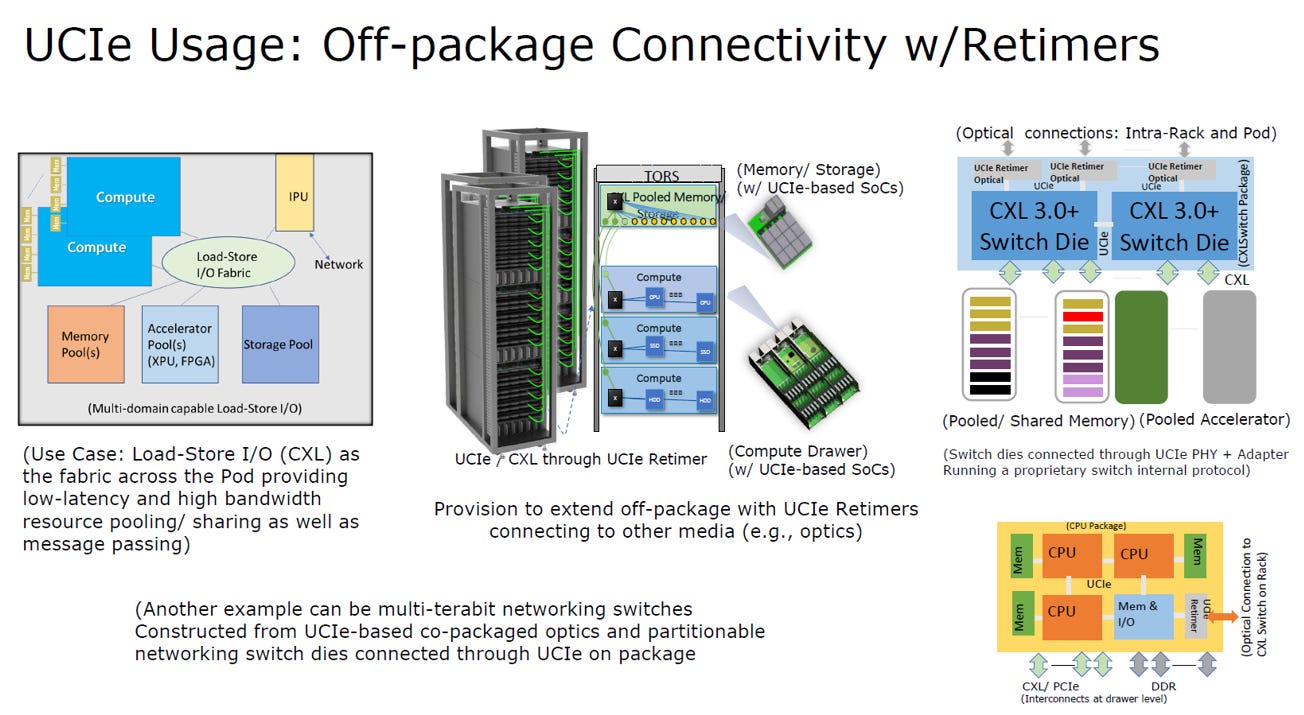
這張投影片展示了 UCIe 如何透過 Retimer(重定時器) 突破原本「僅限封裝內部(In-package)」的物理距離限制,實現 Off-package(封裝外) 甚至 機櫃級(Rack-level) 的高速互連。
突破封裝邊界,實現晶片級光互連
延伸距離 (Off-package): 原本僅限封裝內短距傳輸的 UCIe,透過 Retimer 進行訊號中繼與整形,可轉接至封裝外,通常與 光學元件 (Optical) 結合,實現長距離傳輸。
架構變革 (資源池化): 藉此技術,CPU 可透過 CXL 協定 直接存取遠端機櫃的記憶體或加速器池 (Resource Pooling),是實現未來 解構式伺服器 與 CPO (共同封裝光學) 資料中心的關鍵介面。
結論: Retimer 讓 UCIe 從「小晶片介面」升級為「機櫃級光互連入口」。
3. AyarLabs solutions
3.1. UCIe Optical Retimer
Ayar Labs TeraPHY™ 是全球首款實作 UCIe 光學重定時器 (Optical Retimer) 的小晶片,是將「電訊號轉為光訊號」的關鍵橋樑。

其核心亮點簡述如下:
光學橋樑 (Optical Gateway): 它扮演翻譯官的角色。一端透過 UCIe 介面 與主運算晶片 (如 CPU/GPU) 溝通,另一端則將訊號轉換為 光訊號 透過光纖傳輸,實現晶片對外的超高速互連。
微環技術 (Microring & DWDM): 採用獨家的微環諧振器技術,並結合 16 波長 DWDM (在一條光纖中傳送 16 個頻色)。這完美體現了 “Wide” (多通道並行) 的設計哲學,在極小的晶片面積上實現 8 Tbps 的雙向頻寬。
UCIe-S 的最佳範例: 作為 Retimer,它通常採用 UCIe-S (標準封裝) 規格。利用 UCIe-S 支援較長傳輸距離 (25mm) 的特性,將怕熱的Laser光學元件擺在封裝邊緣,遠離高熱的運算核心,巧妙解決了 「光學怕熱」 的物理難題。
3.2. UCIe Over Optics應用
以光代銅,解開散熱與距離的死結
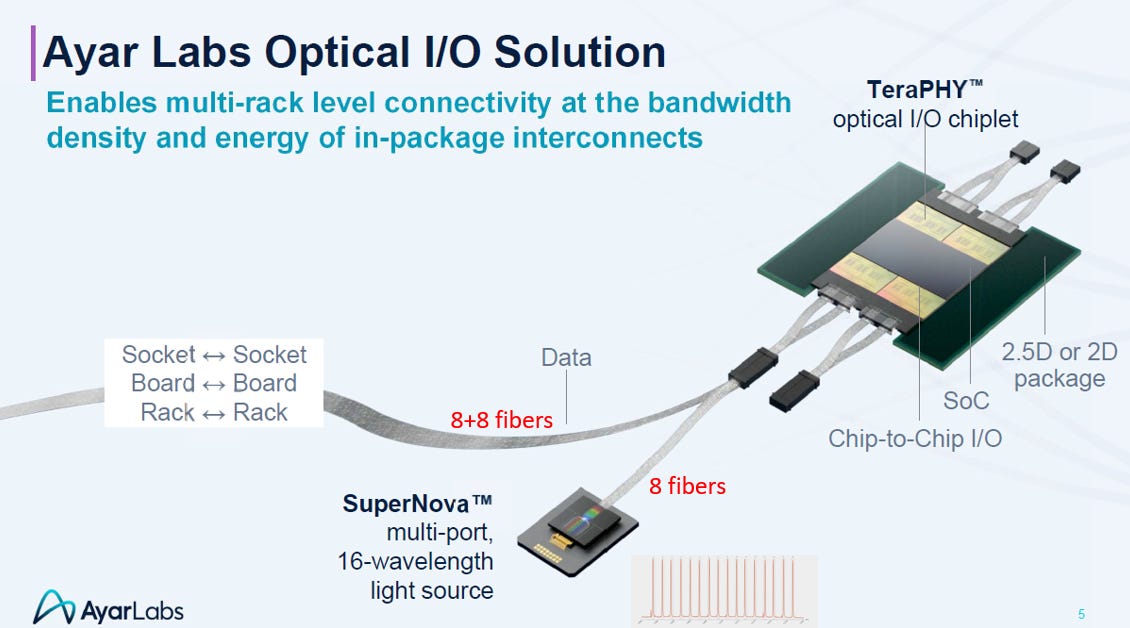
技術創新 (光電分離): 透過 UCIe 介面連接光學小晶片 (TeraPHY),並將最怕熱的雷射光源 (SuperNova) 獨立外置,完美解決了在封裝內整合光學元件的散熱難題

架構變革 (分散部署): 利用光纖的長距離傳輸能力,打破銅線 (DAC) 的距離限制。將原本必須擠在單一機櫃的 600KW 高熱叢集,分散部署到多個 100KW 的機櫃中,大幅降低了資料中心的冷卻與供電壓力。
3.3. TeraPHY 介紹
3.3.1. 架構組織
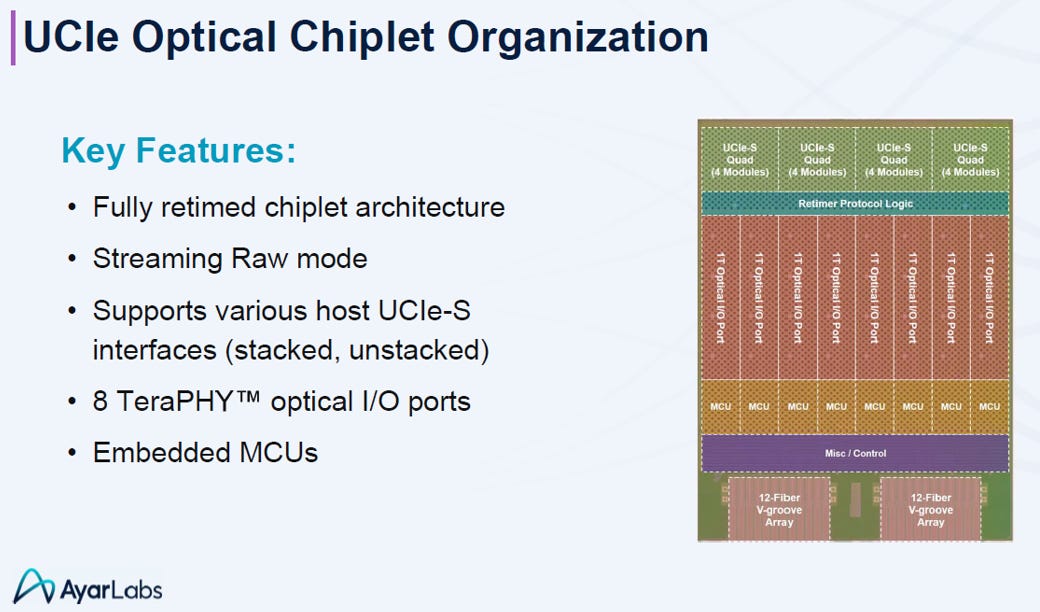
這張圖解構了 Ayar Labs 光學小晶片的內部設計,其特點為:
大頻寬入口 (UCIe-S): 利用 4個UCIe 標準封裝 的四模組(Quad)介面 (這是 UCIe 規範的最大組合),總共16(= 4x4)個模組,接收來自 ASIC 的海量電氣訊號。
低延遲核心 (Raw Mode): 採用 Streaming Raw Mode,可跳過冗餘協定層,確保訊號以最低延遲進行光電轉換。
光電引擎層 (8T + MCU): 內建 8 個 1Tbps Optical I/O Port(O/E: 光電引擎 ),且每個通道配有獨立 MCU 進行智慧校準,總雙向頻寬達 8 Tbps(= 8x1T)
物理對接: 透過底部的 2組 12-Fiber V-groove 陣列直接連接外部光纖
3.3.2. UCIe-S Quad(4 Modules)
「利用 4 個標準模組並行,打造平價的高速公路」
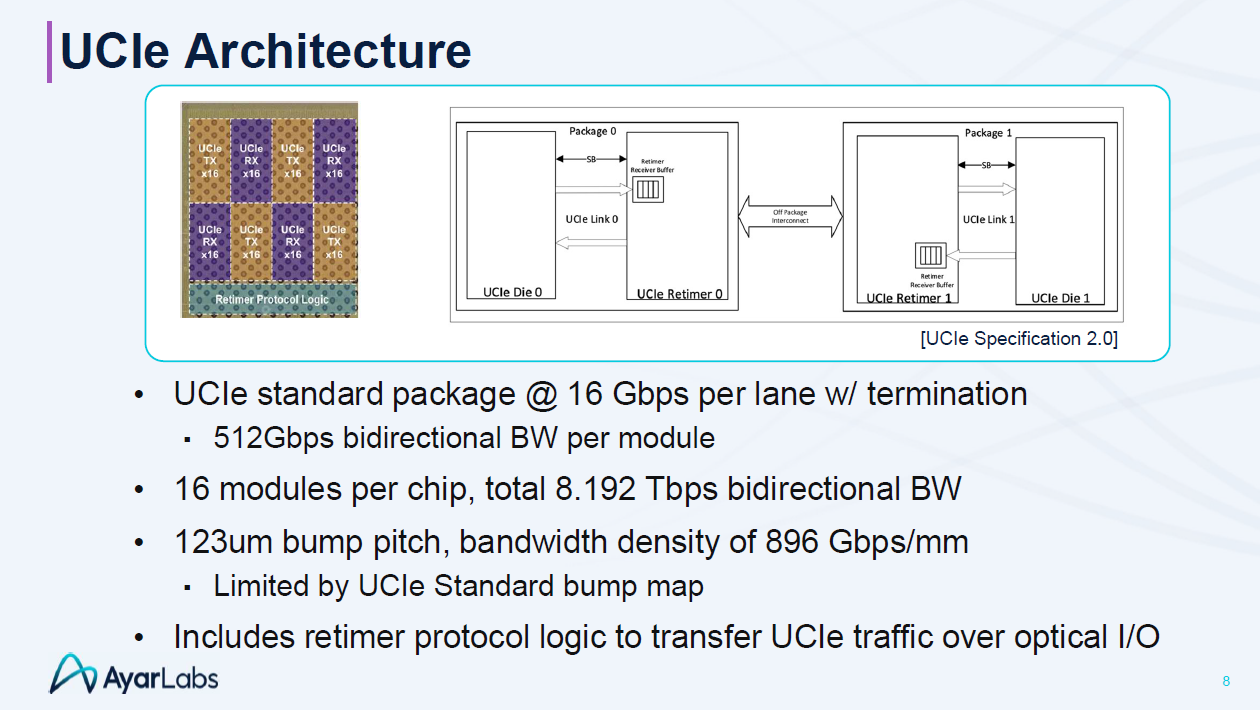
具體定義如下:
“S” (Standard Package): 代表採用標準封裝(2D 有機基板)
特徵: 凸塊間距較寬 (Slide 中為 123 μm),BW density 僅為0.896Tbps/mm(< 1Tbps/mm),但成本比 CoWoS 低廉許多,技術成熟。
“Quad” (四模組配置): 代表將 4 個 UCIe 模組 捆綁成一個邏輯連結 (Link)
通道: 1 個標準模組有 16 條通道,每個通道的速度為16Gbps,Quad 配置則擁有 64 條 (16 x 4) 通道。
頻寬效益 :
單一模組雙向頻寬為 512 Gbps( = 2x16x16Gbps)
Quad (4 模組) 的總頻寬可達 2 Tbps( =4x512Gbps)
3.3.3. Retimer Protocol Logic
Retimer Protocol Logic 是將標準 UCIe 電訊號轉換為 1T 光學訊號的控制中樞
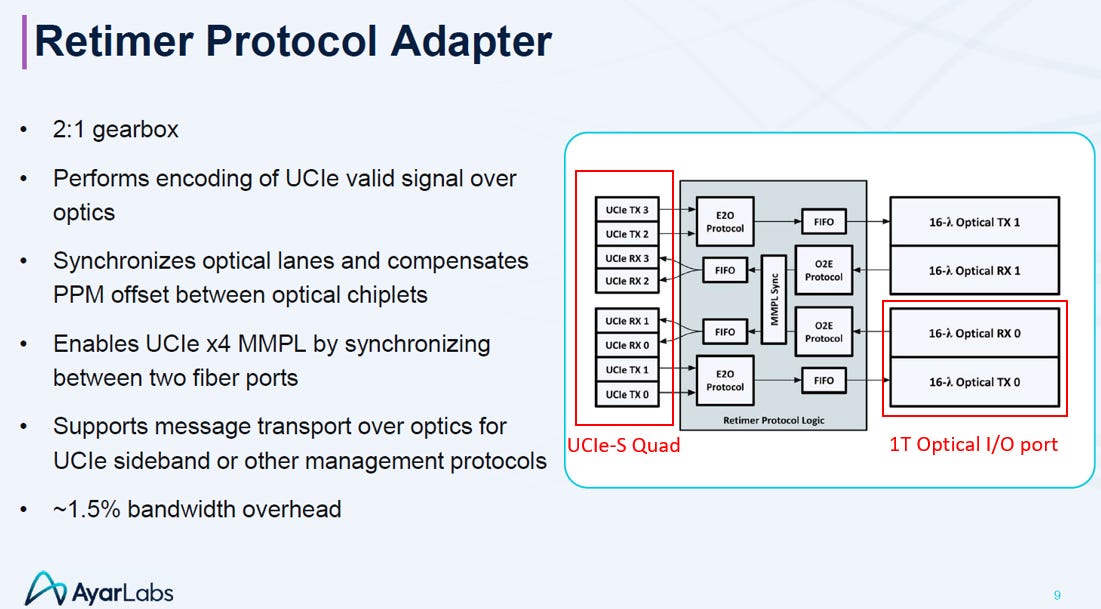
其運作核心簡述如下:
電光轉換與變速 (Translation & Gearbox):
扮演 SerDes lite 的角色,透過 2:1 Gearbox (變速箱) 機制,將寬並行的 UCIe-S 電子訊號,轉換並匹配至高速的光學傳輸介面。
速率轉換: 將 2 條 UCIe 電氣通道 (各 16 Gbps) 合併,驅動 1 個 光波長 (Lambda),使其速率達到 32 Gbps
設計策略 (Slow and Wide):
電氣端: 維持 16 Gbps 低速,以適應低成本的標準封裝
光學端: 32 Gbps 屬於光通訊的甜蜜點,可使用簡單省電的 NRZ 調變,無需昂貴的 DSP
模組聚合與同步 (Aggregation):
利用 MMPL(Multi-Module Physical Layer)同步技術,將 4 個獨立的 UCIe 模組「黏」在一起,協同驅動雙埠光纖介面,達成 1 Tbps 的總頻寬。
極致效率 (Efficiency):
內建 FIFO 處理時脈誤差 (PPM offset) 補償,且轉換過程僅消耗 ~1.5% 的頻寬 (Overhead),確保資料傳輸的低延遲與最大吞吐量
3.3.4. 1T Optical I/O Port(O/E)
Ayar Labs 1T 光學 I/O 埠架構簡述:
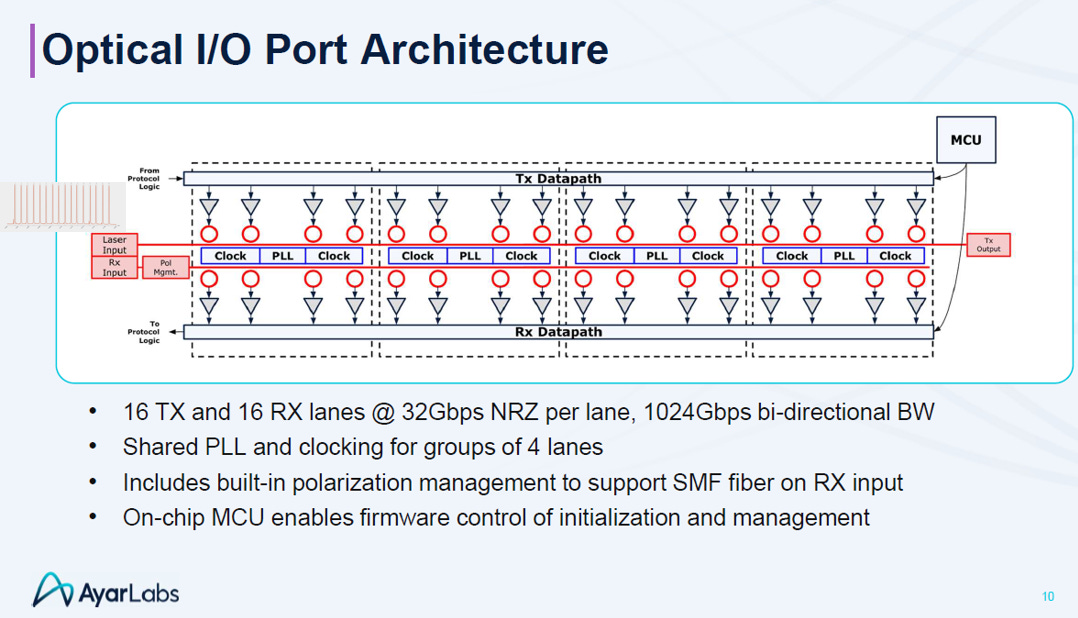
這是實現 電訊號 ↔ 光訊號 物理轉換的核心引擎,具備三大特點:
1T 頻寬規格:
配置 16 TX + 16 RX 通道,每通道採用 32 Gbps NRZ 調變,透過多通道並行達成 1024 Gbps (1 Tbps) 的雙向總頻寬。
微環技術核心:
利用 微環諧振器 (Microring Resonators) 進行光訊號的寫入 (TX) 與讀取 (RX),實現高密度的 DWDM 傳輸。(請參考EP14. SiPH MRM介紹)
優化設計 (能效與穩定):
省電架構: 每 4 個通道共用一組 PLL 與時脈電路,降低功耗
穩定管理: 內建 偏振管理 (Polarization Mgmt.) 以支援標準光纖,並配置 MCU 進行即時校準與溫控,確保光學元件在最佳狀態運作。
結論:
這是將 “Slow and Wide” 策略物理實現的關鍵模組,用低速並行的 NRZ 訊號換取高效穩定的 1T 光互連。
3.3.5. 2x12-Fiber V-groove Array
Ayar Labs 光纖介面配置簡述:
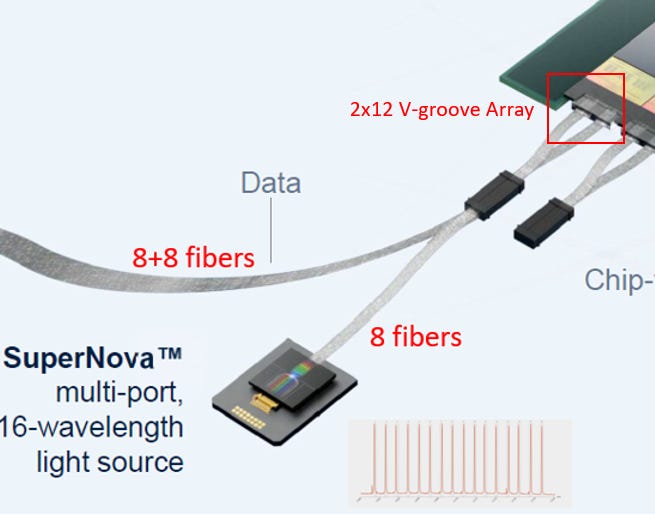
2 組 12 芯 V 型槽陣列 (2x12 V-groove Array) 共提供 24 根光纖,精準支援 8 個 1T 光學埠 的運作,其分配邏輯如下:
總量分配:
每個光學埠 (Port) 需使用 3 根光纖,因此 8 個埠 x 3 根 = 24 根光纖,完美對應物理接口數量。
單埠光纖功能 (1+1+1):
1 根 雷射輸入 (Laser In): 引入外部 SuperNova 的光源 (供光)
1 根 資料發送 (TX): 輸出光訊號
1 根 資料接收 (RX): 輸入光訊號
結論:
透過精密的 3 根一組 配置,實現了外置光源供電與雙向高速傳輸的完整光路
4. 結語
雖然Ayar Labs TeraPHY™ 宣稱是全球首款實作 UCIe 光學重定時器 (Optical Retimer) 的小晶片,但另一家新創Lightmatter,他們的 L200在技術層面上,確實是超越 TeraPHY 的 UCIe 光學 retimer另一個解決方案,請參考Lightmatter官網資料:

TeraPHY和L200的差異在於規模與速度的級別完全不同:
總頻寬 (4倍差異):Lightmatter L200 提供高達 32 Tbps 的巨量頻寬,而 Ayar Labs TeraPHY 8T 為 8 Tbps (比較 Nvidia NVL5: 14.4Tbps)
速度 (3倍與1.5倍):L200 的電氣入口速率快 3 倍 (48Gbps/lane 對 16Gbps/lane),光學出口速率快 1.5 倍 (50G對 32G)
物理規模 (2.5倍):L200 動用了 2.5 倍的波長通道數 (320 對 128) 和光纖數量 (20 對 8) 來達成目標。
產品定位:Ayar Labs 走的是**「高能效的標準化元件」路線;Lightmatter 走的是「極致堆疊的高密度平台」**路線(1.5Tbps/mm)
這兩家新創的核心價值,都在於證明了 「標準 UCIe over Optics」 是打破 AI Scale-up 物理瓶頸的黃金路徑。
具體而言,就是確立以下的新典範:
釋放運算核心: 讓昂貴的 AI 晶片只需輸出「寬且慢 (Wide & Slow)」的標準 UCIe 電訊號(低功耗、易設計),是系統架構的最優解,不再讓運算晶片被高速 SerDes 的物理極限綁架。
解構傳輸距離: 利用光通訊徹底消除銅線的距離與功耗限制,讓 AI Scale-up叢集不再受限於機櫃內的範圍。
建立工業標準: 讓 UCIe over Optics 成為像 PCIe 一樣可信賴的工業標準,實現 AI 算力資源的無縫池化與無限擴展。
5. 補充說明
5.1. L200光學引擎的總頻寬32Tbps推導說明
總頻寬與通道計算
總頻寬 (Total Bandwidth): 規格標示 32 Tbps。這是雙向加總,也就是發送 (Tx) 16 Tbps + 接收 (Rx) 16 Tbps
通道數計算: 單通道有效頻寬為 50 Gbps (對應規格中的 56 Gbps NRZ,扣除編碼開銷)。
計算式:16 Tbps / 50 Gbps = 320 Lanes (通道)。
這與圖片中 EIC 提供的 “320 High Speed SerDes” 數據完全吻合(沒有像TeraPHY做2:1 Gearbox)
電氣層介面
EIC 功能: 來自AlphaWave 的晶片擔任 UCIe-S Retimer,SerDes Lite的轉換,並包含驅動 L200 光子晶片 (PIC) 的 Driver/TIA。
通道分組: 320 個 SerDes 通道來自 320 個 UCIe-S 通道。
模組配置: 320 通道分為 20 個模組,每個模組 16 通道 (x16)。物理上可能是 5 個 Quad-Modules (由 4 個小模組組成),即 5 * 4 * 16 = 320。
Data Rate 轉換: UCIe-S的data rate = 48Gbps; Retimer處理後為50Gbps(SerDes-Lite, OH = 4.2%)
頻寬驗證: 320 * 50 Gbps = 16,000 Gbps = 16 Tbps (單向)
光纖總數計算
波長分配: 320 個通道驅動 320 個波長 (lambda)。每根光纖承載 16 個不同波長
訊號光纖數: 320 / 16 = 20 根光纖
總光纖數組成 (3:1 架構):
發送光纖 (Tx Fibers): 20 根 (承載 16 Tbps 輸出)。
接收光纖 (Rx Fibers): 20 根 (承載 16 Tbps 輸入)。
雷射光源光纖 (External Laser Source, ELS): 20 根 (為矽光子晶片提供外部光源)
總和: 20 (Tx) + 20 (Rx) + 20 (ELS) = 60 Total Fibers
總結表
單通道速率: 50 Gbps (56G NRZ)
總通道數 (Lanes): 320 (源自 EIC SerDes)
總頻寬: 32 Tbps (雙向)
波長分波: 每根光纖 16 波長
光纖總數: 60 (含 Tx, Rx, 以及外部雷射輸入)
介面: UCIe-S (Die-to-Die 連接)
5.2. L200 BW density > 1.5Tbps/mm 說明
EIC is from Alphawave, followed UCIe-S:

與AyarLabs TeraPHY比較:
關於 L200 Optical Engine 架構分析的簡述:
核心規格: L200 為 32 Tbps 雙向 (BiDi) 矽光子引擎,採用 56G NRZ 調變技術。
電氣介面: 使用 AlphaWave EIC 方案,透過 320 個 UCIe-S 通道 (每通道有效 48Gbps) 進行 Die-to-Die 連接與 Retimer 功能。
光路架構: 採用 16 波長 (WDM) 分波多工。光纖配置為 3:1 架構,總計 60 根光纖 (20 Tx + 20 Rx + 20 外部雷射輸入)。
頻寬密度: 相比 AyarLabs (TeraPHY) 的 16Gbps 速率,L200 因單通道速率提升 3 倍 (至 48Gbps+),其頻寬密度 (BW Density) 估算可達 2.6 Tbps/mm 以上,證明大於 1.5 Tbps/mm 的設計完全可行。