EP23. 448G SerDes

在EP22.中提到NVL144 和 NVL576,其中NVLink版本分別是6和7。官網好像沒說明差異。看到TrendForce的文章,他們預估其特性,其中NVL7會用到400G SerDes。剛好OIF開放了今年448G workshop的資料,看了幾篇文章,分享心得,歡迎討論。
1. SerDes roadmap
1.1. NVLink 技術演進
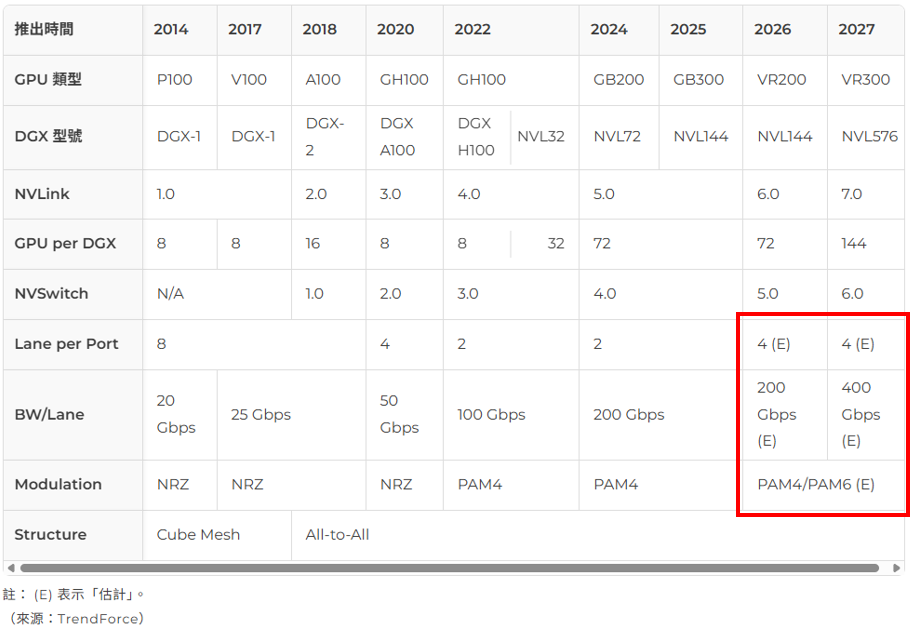
通道數量的增長(Lane per Port)
NVL5.0 每埠通道數為 2,NVL6.0開始每埠通道數估計增加到4,提升兩倍的聚合頻寬。
頻寬躍升(BW/Lane)
NVLink 7.0 的每通道頻寬估計將達到 400 Gbps,是 NVLink 6.0 (200 Gbps) 的兩倍。
調變技術(Modulation)
NVLink 7.0為了降低對頻道頻寬(PCB Backplane)要求,估計會採用PAM6調變。
1.2. Switch IC 技術演進
和NVLink技術演進類似,先提升SerDes速度,再提高lane的數目
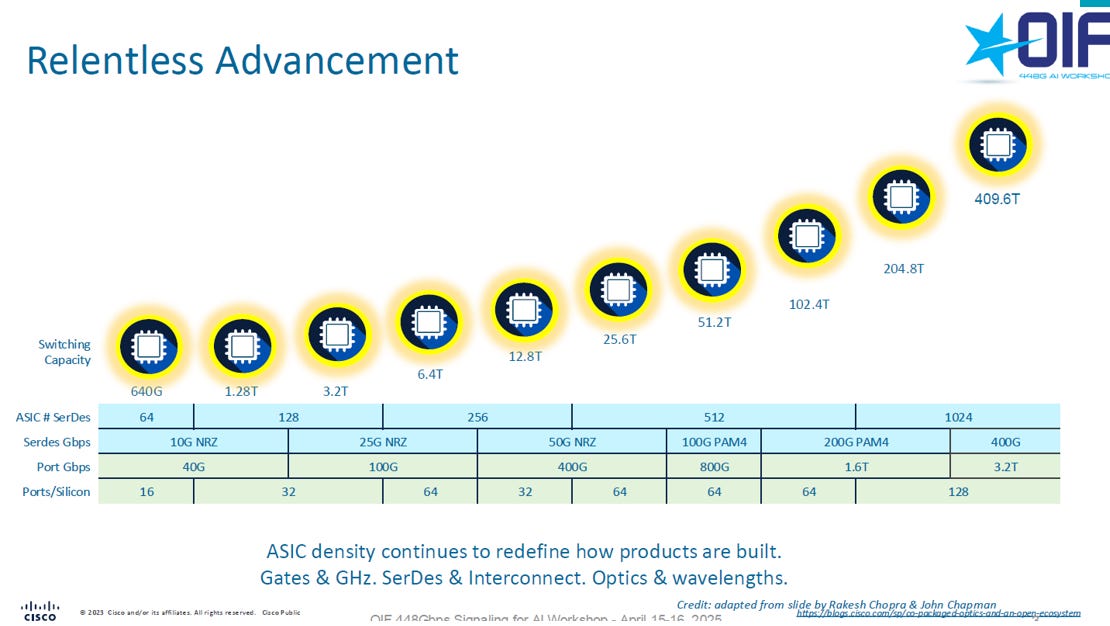
目前最新的102.4T的Switch,是基於SerDes = 200G, Lane數目=512。
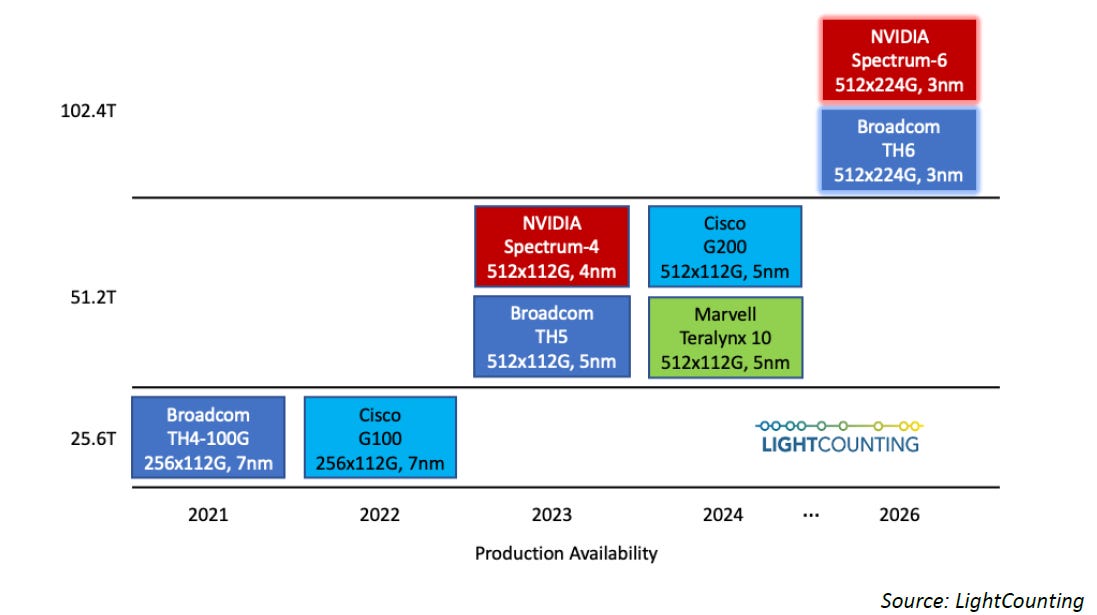
1.3. SerDes增長趨勢
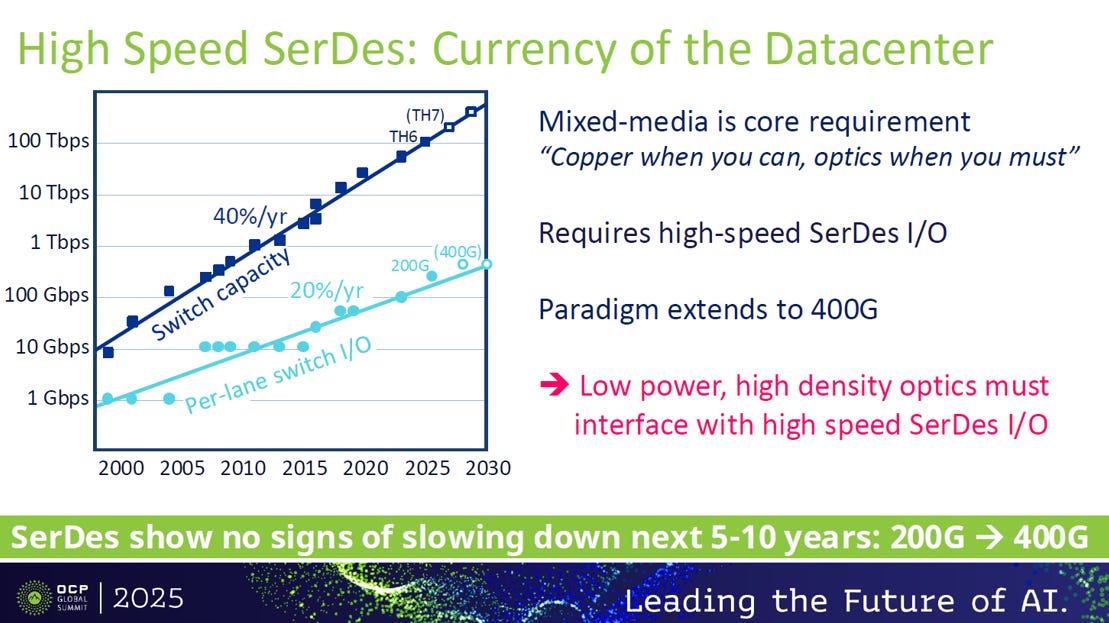
資料中心網路頻寬,特別是交換機容量(年增 40%)和每通道 I/O 速率(年增 20%),正持續高速增長。
高速 SerDes (串行/解串器) 是實現這些速率(目標:從 200G 到 400G)的核心技術
資料中心設計必須採用「銅纜優先,光纖必需」的混合媒介策略,要求低功耗、高密度的光學元件與高速 SerDes 介面連。
總結來說:SerDes 是資料中心的命脈,且在未來 5-10 年內將持續加速,推動速率邁向 400G
1.4. SerDes(Serializer/Deserializer) Block Diagram
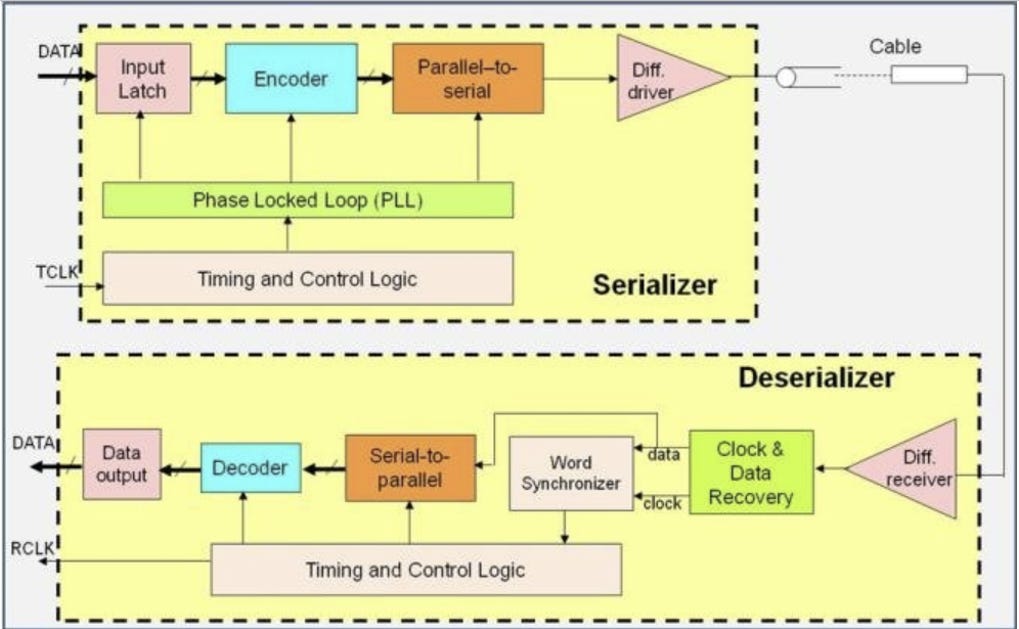
SerDes (串行器/解串器) 的核心功能是將數據從並行轉換為串行傳輸,並在接收端將其還原:
串行器 (Serializer/Tx): 將寬位元的並行數據,通過 編碼 和 PLL (鎖相迴路) 產生的時鐘,轉換成單線路的高速串行數據輸出
解串器 (Deserializer/Rx): 從接收到的高速串行數據中,利用 CDR (時鐘和數據恢復) 單元,提取時鐘並同步數據,然後將其轉換回原始的並行數據輸出。
目的: 透過這種方式,解決高速、長距離傳輸中,多條線路導致的數據時序偏差 (Data Skew) 和電磁干擾 (EMI) 問題。
2. 448G Electrical Issues
2.1. Keysight experiment
儀器大廠 Keysight使用自家設備(M8199B 任意波形產生器和 UXR RealTime示波器),進行 448G 通道考量 (448G Channel Considerations) 實驗:
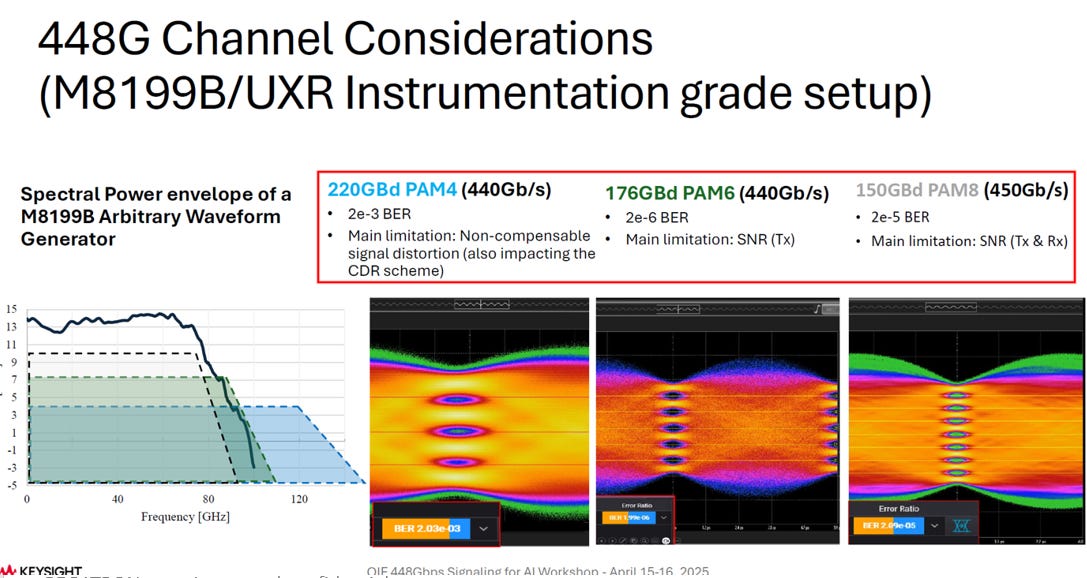
Keysight 的實驗展示了在下一代超高速率(448G 級別)傳輸中,不同調變技術的優缺點:
PAM4 (220 GBd) 雖然速率高,但訊號衰減帶來的 BER 太高 (2e-3),可能難以實際應用
PAM6 (176 GBd) 在這個實驗設置中表現出最好的 BER (2e-6),但其核心限制是發射端的訊噪比
PAM8 (150 GBd) 雖然是最低符號率,但對訊噪比的要求極為嚴苛,導致 BER 仍高達 2e-5
實驗結果指出,在 448 Gb/s 的速率級別,PAM6 達到了相對可接受的 BER (2e-6),使其成為一個強有力的候選技術,而 PAM4 和 PAM8 則因各自的訊號衰減或對 SNR 要求過高而面臨更大的挑戰。
2.2. 頻寬需求
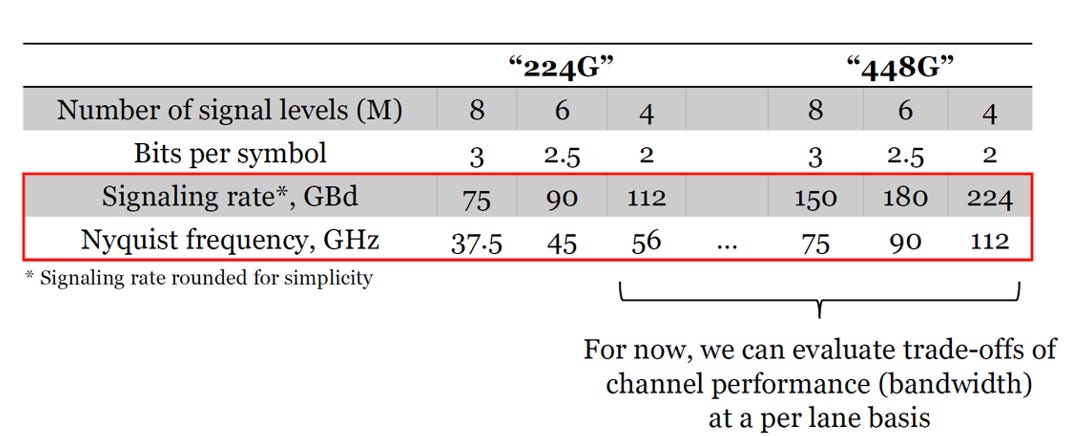
數據速率 (Bit Rate) 決定公式:
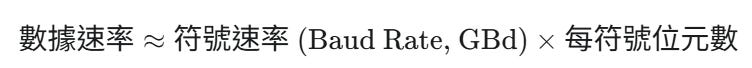
奈奎斯特頻率 (Nyquist Frequency) 決定公式:
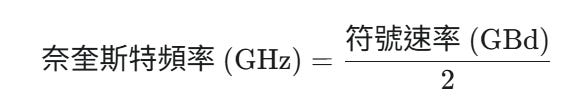
此頻率代表傳輸該信號所需的最小通道頻寬
不同的通道響應 vs. PAM4,6,8的Insertion Loss(IL)
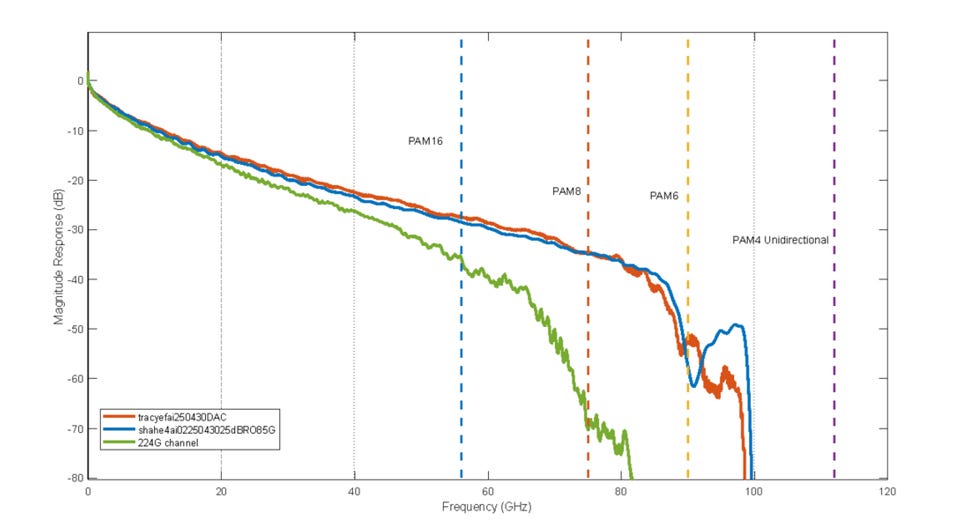
頻寬限制: 圖中的通道(特別是綠線,”224G channel” 當然不合448G的要求)隨著頻率增加,訊號衰減急劇變大,表示通道頻寬嚴重不足
階數影響:
PAM4 (112 GHz)頻寬需求太高,在該通道上訊號衰減極大,傳輸幾乎不可行。
PAM8 (75 GHz) 所需頻寬需求最低。
下面這張投影片是分析在 448G 的連接中,使用 銅纜通道的可行性,並得出關鍵結論:

架構: 訊號經由 ASIC、PCB、CPC 連接器和銅纜線傳輸,目標距離超過 1 公尺
關鍵限制: 插入損耗 (Insertion Loss) 是決定銅纜互連可行性的主導因素
調變比較與結論
PAM4 (212.5G Baud):因符號率極高,產生了 >80 dB 的巨大插入損耗,導致不可行 (Not feasible)
PAM6 (170G Baud) 和 PAM8 (141.6G Baud):透過降低符號率,大幅降低了插入損耗(分別為 >50 dB 和 >40 dB)。儘管這兩種方案所需的 SNR 更高,但損耗的改善更為關鍵
最終結論: 448G 銅纜互連中,PAM4 是個不可行的方案 (PAM4 is a non-starter)
2.3. SNR 需求
在固定信號強度 (448 Gb/s per lane) 的前提下,不同 PAM 調變技術(PAM-4、PAM-6、PAM-8)的 SNR(訊噪比)對 BER(位元錯誤率) 的影響及其面臨的挑戰:
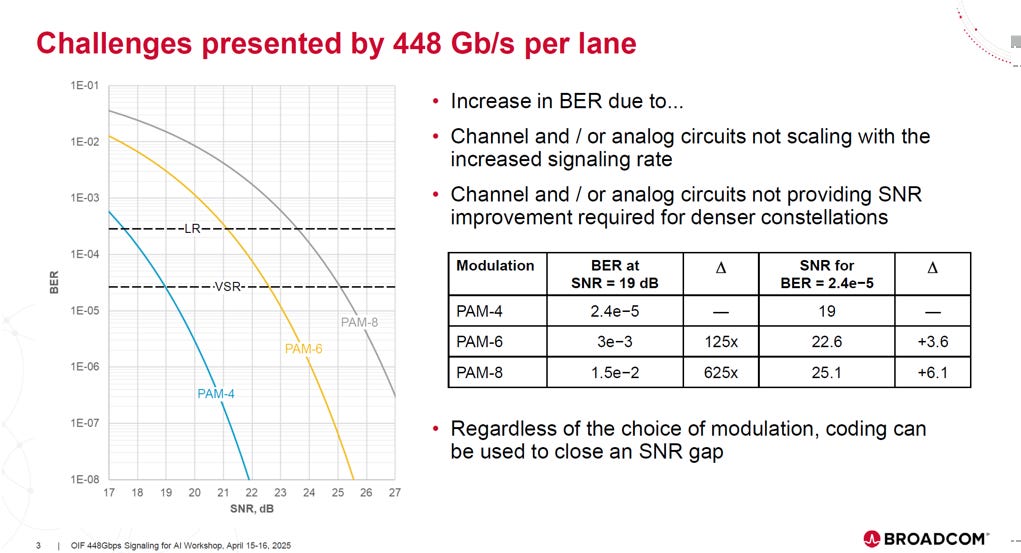
問題核心 (SNR vs. BER): 高速傳輸的通道和類比電路難以跟上訊號速率擴展,導致訊號質量差,SNR (訊噪比) 不足。
高階 PAM 的代價: 訊號階數越高(PAM-8 > PAM-6 > PAM-4),對 SNR 的要求越苛刻。為了達到相同的低錯誤率 (BER),PAM-8 比 PAM-4 需要額外 6.1 dB 的 SNR。
解決方案: 由於物理通道難以提供所需的 SNR 提升,設計者必須使用 DSP的技術,如等化器,FEC (前向錯誤修正) 等,來彌補高階 PAM 帶來的 SNR 差距,從而實現目標的低 BER。
2.4. Noise Sources
關於高速鏈路雜訊源的簡述:

鏈路性能目標: 位元錯誤率 (BER) 取決於 SNR (訊噪比),而 SNR 則取決於總雜訊功率 (σn2) (假設固定信號功率)
雜訊來源: 總雜訊功率 (σn2) 由多個獨立來源組成,包括:
訊號干擾: 符號間干擾 (ISI,主要來自反射)。
串擾: 近端串擾 (NEXT) 和遠端串擾 (FEXT,來自相鄰通道)
設備雜訊: 發射器 (σtx2) 和接收器 (σrx2) 自身的雜訊與時基誤差
通道與雜訊的關係
插入損耗 (IL) 和 ILD 是最關鍵的通道缺陷,它們不僅造成訊號衰減,還會導致雜訊增強 (noise enhancement),放大接收器和串擾雜訊
回波損耗 (RL) 差則主要增加 ISI (反射)
要提高鏈路性能,必須從優化通道的 IL、ILD 和 RL 開始,以最小化所有獨立雜訊源,從而最大化 SNR。
2.5. MLSD(Maximum-Likelihood Sequence Detector)
下面這張「鏈路框圖 (Link block diagram)」展示了實現 448 Gbps/lane 速率時,發射端 (Transmitter) 和接收端 (Receiver) 複雜的訊號處理流程。
在這個超高速、高損耗的環境中,MLSD (Maximum-Likelihood Sequence Detector, 最大似然序列偵測器) 扮演了關鍵角色。
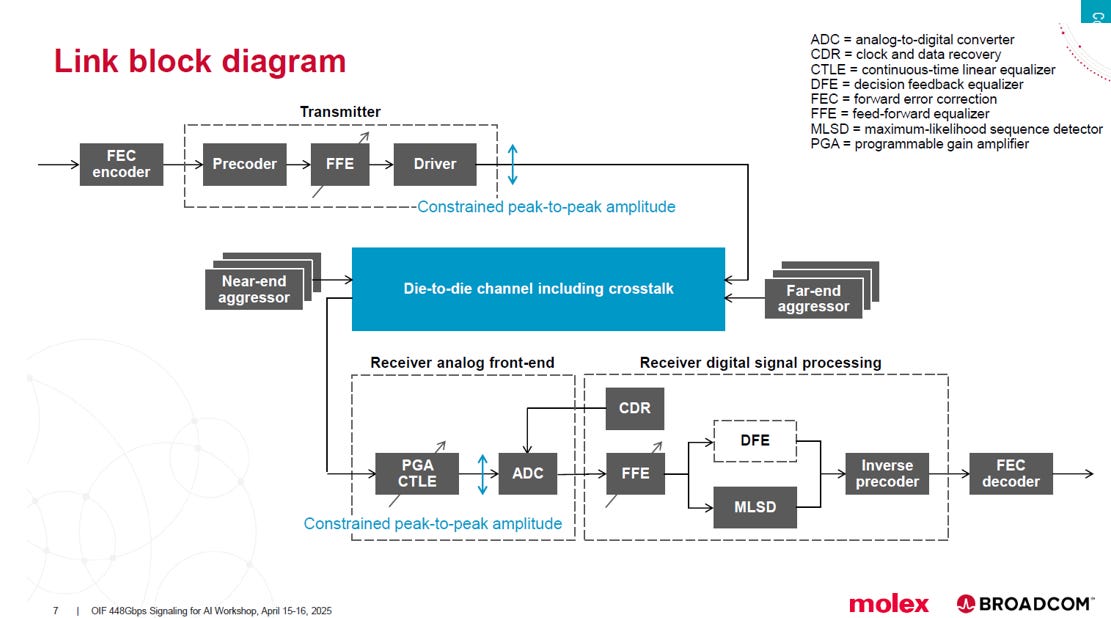
MLSD (最大似然序列偵測器) 是一個在接收端使用的進階數位訊號處理 (DSP) 技術:
功能: 它不是單獨判斷每個訊號,而是考慮連續的符號序列,並根據統計原理推測發射端最有可能發出的原始數據序列
必要性: 在 224G/448G 這樣極高速率下,通道損耗導致 SNR 極低。傳統的均衡器 (如 DFE) 無法有效消除殘餘的符號間干擾 (ISI)
價值: MLSD 能在低 SNR 環境中提供最佳的判決準確度,有效處理殘留的 ISI,是確保鏈路能達到目標低 BER 性能的必須解決方案。
1 米 DAC 通道 MLSD 應用範例
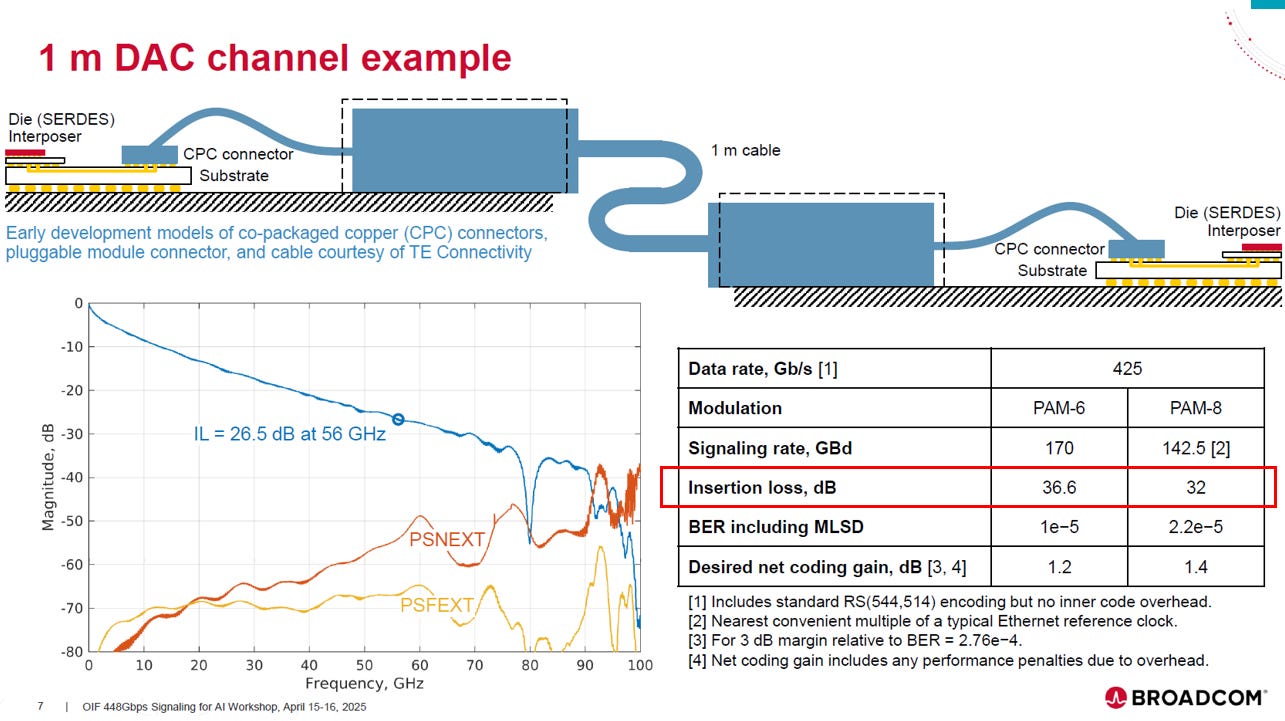
挑戰: 在 425 Gb/s 的速率下,即使是 1 米 DAC 通道,高頻處仍有 30-40 dB 的顯著插入損耗和串擾
MLSD 效果: 在這個高損耗環境中,MLSD 作為接收端的關鍵 DSP,成功地將 BER(位元錯誤率)控制在1e-5 到2.2e-5 的範圍內
結論: MLSD 的應用證明,它是實現超高速率 (425G/lane) 鏈路性能的關鍵技術,能將高損耗通道轉化為 FEC(前向錯誤修正)可處理的低錯誤率,確保鏈路可靠運行
註: PAM8 雖然插入損耗最低 (32 dB),但其 BER 略差,再次確認了它對 SNR 的高敏感性。 這也符合Keysight的實驗結論,PAM6是銅介質傳輸的最佳選擇。
註: 請參考補充說明,關於MLSD和FEC協作。
2.6. Connector issues
傳統連接器(如 OSFP)在高速率下所面臨問題:
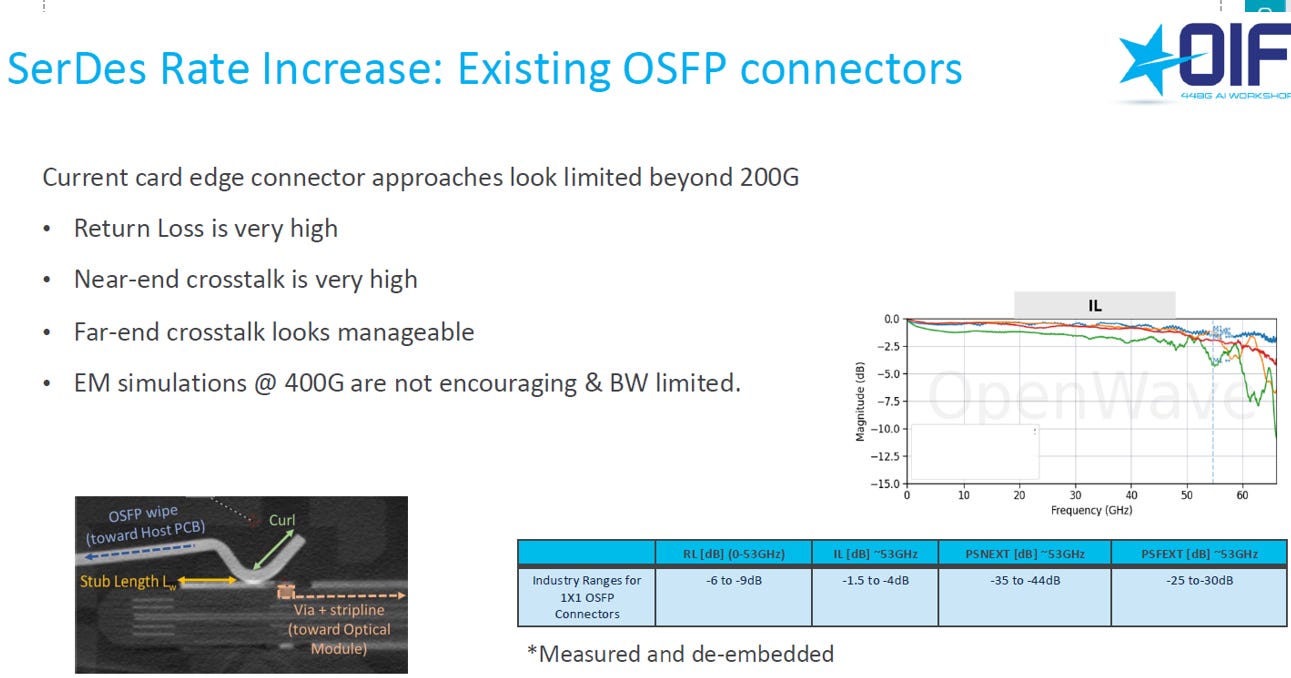
速率限制: 傳統連接器的方法在速率超過 200G 時,性能受到嚴重限制,難以支持 400G 訊號。
主要缺陷:
回波損耗 (RL) 非常高: 由於連接器的物理結構(如短截線 Stub),造成訊號反射嚴重,惡化訊號完整性
近端串擾 (NEXT) 非常高: 連接器內通道間隔離不足,導致鄰近訊號干擾嚴重
結論: 由於高反射 (RL) 和高串擾 (NEXT),傳統連接器難以在下一代 400G/448G 訊號速率下維持可靠的訊號完整性。
2.7. OIF HD 連接器專案

時間與目標: 於 2025 年 Q1 啟動,是 OIF 「節能介面 (EEI)」 研究方向的一部分
目的: 旨在解決下一代 AI/ML 和資料中心中,超高速率 (448G/224G) 連接器面臨的高密度、低功耗、低延遲和訊號完整性等挑戰
意義: 該專案代表業界正在尋求突破性的新連接器標準,以取代傳統設計的限制,支持未來的 3.2T 及更高速率光網路技術的市場採用。
Project Targets

傳統限制: 現有連接器採用 單排 (1D) 或 兩排 (1.5D) 的線性佈局 (例如 OSFP 的 8 條或 OSFP-XD 的 16 條通道),這種結構已限制了通道密度
HD 目標 (2D): 新的 HD 連接器概念目標轉向 二維矩陣 (2D) 結構,以實現:
極高密度: 支援 64 對訊號通道
極高總速率: 實現 12.8T 或 25.6T 的總傳輸速率(比較: NV B200 7.2Tbps(單向))
極小間距: 觸點間距為 0.5 mm
結論: 從 1D/1.5D 轉向 2D 佈局是實現通道數量和總速率飛躍的關鍵,以應對 AI/ML 對極致頻寬的需求。
HD Scale-up 應用

關於 HD Scale-up 應用和 12.8T 可插拔光學模組的簡述:
需求: Scale-up應用需要比Scale-out高約 10 倍的頻寬。
解決方案: 透過採用 OIF 推動的高密度 2D 連接器(支援 64 對通道)技術
目標: 實現 12.8T 甚至 25.6T 的超高容量可插拔光學模組 (PLO, PLuggable Optics)
優勢: 這些 PLO 具有高容量、緊湊尺寸(適用於 GPU/Scale-up 交換機)和低成本/Gbps 的優勢,能滿足未來 AI/ML 運算的極致互連需求
Example
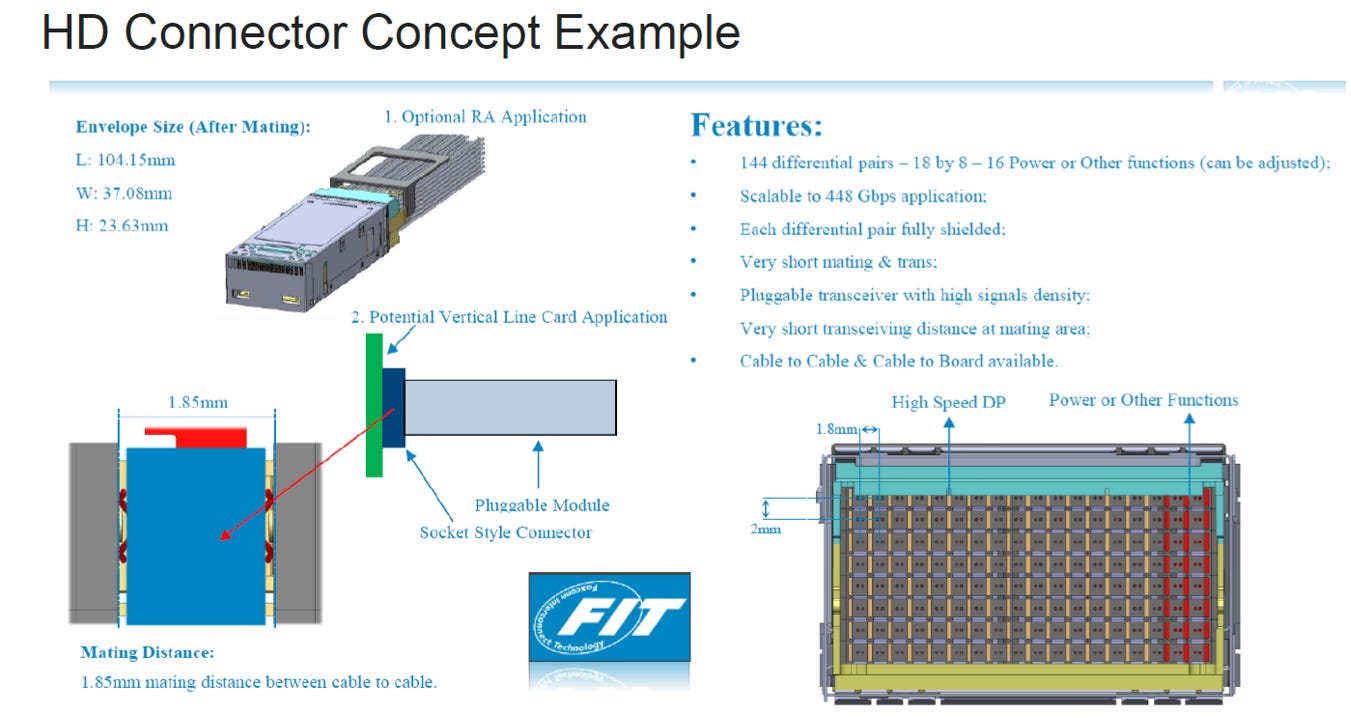
設計核心: 這是一個高密度連接器概念,旨在實現極致的訊號密度和高速傳輸能力
關鍵規格
支援 144 對差分訊號,密度遠高於傳統連接器
可擴展至 448 Gbps/lane 應用
訊號完整性保障
每個差分訊號對都進行了完全遮蔽 (fully shielded) 以控制串擾
對接距離極短 (1.85 mm),以最大限度減少連接器自身的損耗和反射
該範例展示了實現未來 12.8T/25.6T 總速率所需的超高密度、全面遮蔽和極短傳輸路徑的連接器設計標準
3. 448G Optical issues
3.1. Modulator(E/O)
Modulator受448G影響最嚴重,所以特別研究此元件。
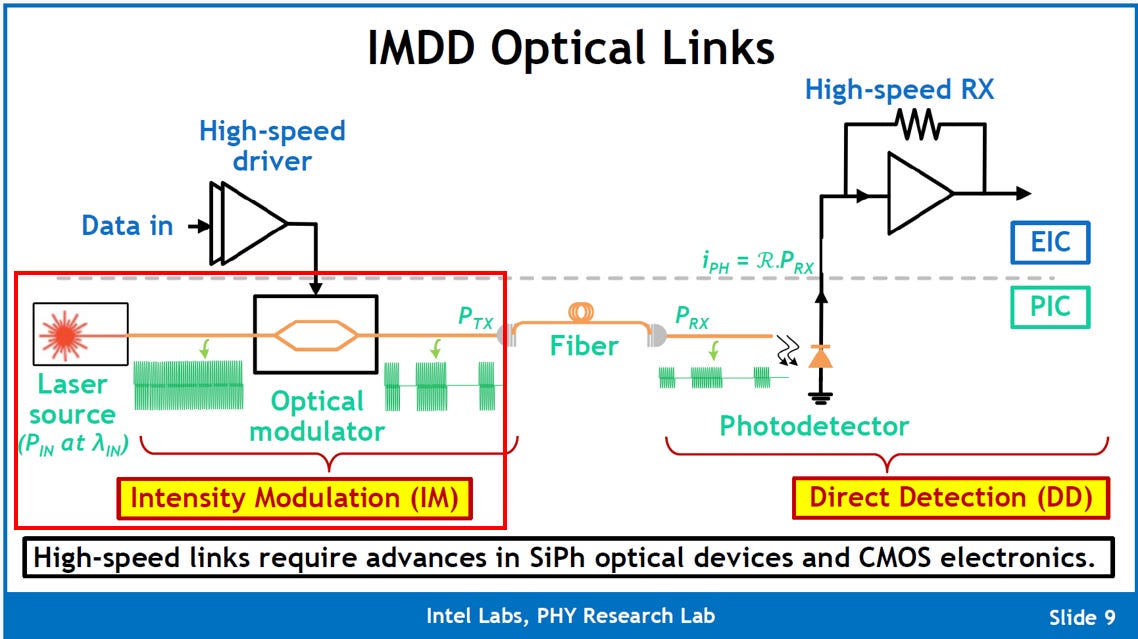
400G/通道 技術平台與主流調變器介紹
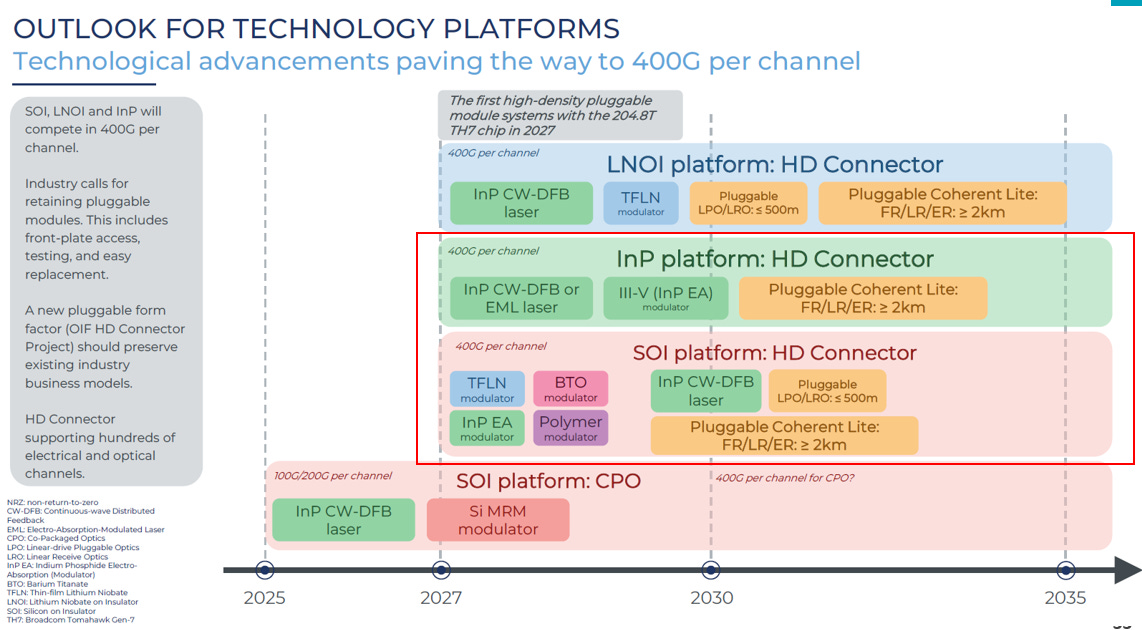
在光通信業界,實現 400G/通道速率主要有兩大技術平台在競爭,並各自有其主流調變器:
InP 平台 (磷化銦):
主流技術: EML (電吸收調變雷射, DFB+EAM) 和 DFB +MZI 調變器 (ILMZ)。
優勢: 技術成熟、性能穩定、可集成雷射 (光源),且具有高頻寬。EML 是當前高性能應用中的主力軍。
SOI 平台 (絕緣層上矽 / 矽光子):
主流技術: TFLN (薄膜鈮酸鋰) 調變器。
優勢: 具有極高頻寬、低損耗、低成本和大規模集成潛力,是矽光子平臺用來追趕 InP 性能的關鍵技術。
總結: InP EML 是穩定且性能可靠的主流方案,而 TFLN/InP ILMZ 則憑藉其超高頻寬和優異的線性度,是未來實現更複雜、更長距離 400G/通道應用(如 Coherent Lite)的重要競爭者。
ILMZ(Integrated Laser Mach-Zehnder) Demo
Marvell 和 Lumentum 在 OFC 2025 上合作展示的業界領先技術:單通道 400G PAM4 電轉光 (electrical-to-optical) 鏈路


核心成果: 在 OFC 2025 上,成功展示了業界首個單通道 400G PAM4 電轉光鏈路 (實際速率約 448G)。
技術合作:
Marvell (電氣端): 提供了高速的 DAC 和 Driver,產生 225 GBd 的 PAM4 電氣訊號。
Lumentum (光學端): 提供了 DFB-MZI 等集成光學元件,負責將電氣訊號轉換為高品質的光學訊
參考Demo視頻: Lumentum and Marvell Showcase Industry’s First 450G demo at OFC 2025
EML(Electro-absorption Modulated Laser) Demo
Coherent 和 Ciena 在 OFC 2025展示的技術,是關於使用 差分電吸收調變雷射 (Differential EML, D-EML) 實現 400G PAM4 傳輸的成果。
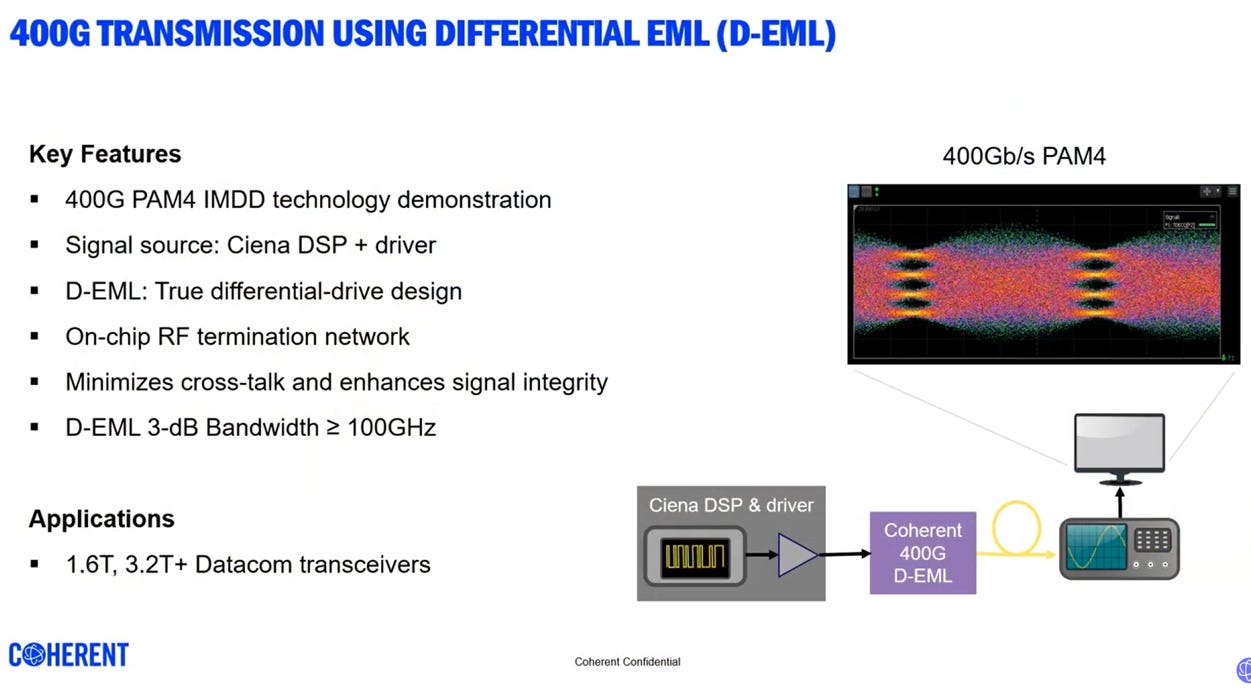
參考Demo視頻: Coherent | 400G Differential Electro-absorption Modulated Laser (D-EML) at OFC 2025
另外,Broadcom也公開他們400G EML的產品。
註: 請參考補充說明,關於高速矽光子三大物理層面的核心問題
3.2. 448G 訊號的調變技術選擇與權衡
電氣通道 (Electrical Channels):偏好 PAM6/8
原因: PAM4 (224 GBd) 在銅纜/連接器中會產生極高的插入損耗 (>80 dB),因此不可行(除非電氣通道距離和前面兩個Demo一樣,非常短)。
選擇: 必須採用 PAM6 或 PAM8 來降低符號率,以降低通道插入損耗,提高可行性。
光學通道 (Optical Channels):偏好 PAM4
原因: 新一代光學調變器(如 EML/MZI/TFLN)的頻寬足夠支持 PAM4 的 224 GBd 速率
選擇: PAM4 對 SNR (訊噪比) 的要求在所有 PAM 階數中最低,是達成可靠 BER 的首選
總結: 電氣通道受限於「損耗 (Loss)」,被迫選擇低符號率的 PAM6/8;而光學通道受限於「SNR」,故在頻寬足夠下選擇低 SNR 門檻的 PAM4。
Marvell在會議上提出用DSP GearBox,用來做PAM6 和 PAM4的轉換,但需要額外功耗。

註: 到了 3.2T 世代,還要搞 CPC(Co-Packaged Copper) + Flyover + OSFP ! 反映了傳統光通訊產業(賣模組的、賣連接器的)正在拼命抵抗 CPO 的「垂直整合」
4. Others
這張投影片由Microsoft Azure 提出,旨在定義未來光學技術的發展,並將其分為三個主要類別:
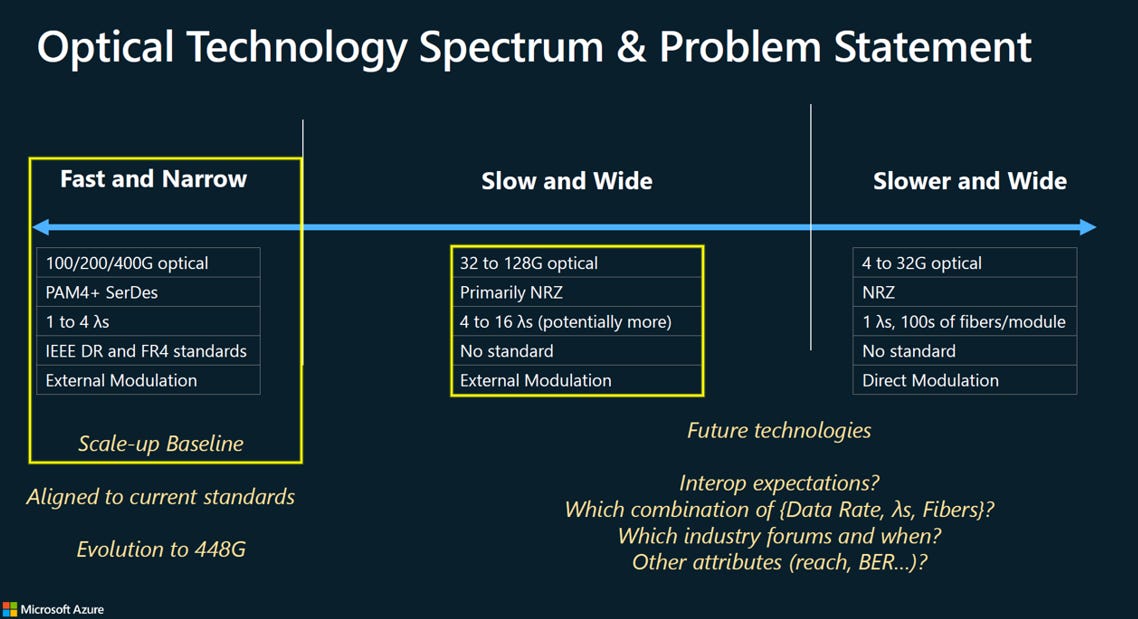
根據圖中資訊,適用於短距離且與 Fast & Narrow 不同的技術,主要集中在 Slow and Wide 和 Slower and Wide 這兩個類別:
Slow and Wide (32G - 128G)
特點: 犧牲單通道速率(使用 NRZ 調變),但利用WDM的方法,增加了通道數量(4 到 16 個 波長)
優勢: 這種方案可能提供比 Fast & Narrow 更高的通道密度和總體頻寬密度,同時在單通道速度上對 DSP/SerDes 的要求較低,可能降低功耗
Slower and Wide (4G - 32G), 例如 Microsoft 的 MOSAIC 專案
特點: 單通道速率極低,但採用單一波長,並在單個模組內使用數百條光纖。
優勢: 由於使用了最簡單的 NRZ 和 直調變,且速度極低,這會是一個成本和功耗最低的解決方案。它適用於極短距離、超高密度的互連,例如在 ASIC 附近的共同封裝光學 (CPO) 或光引擎
結論
Fast & Narrow (400G, PAM4): 專注於速度,是當前的基準。
Slow and Wide (NRZ, 4-16 波長) 和 Slower and Wide (NRZ, 數百條光纖 ): 專注於密度和低成本,通過犧牲單通道速度來換取極大的通道數量,以滿足未來極短距離、大規模並行互連的需求。
4.1. Slow and Wide Example
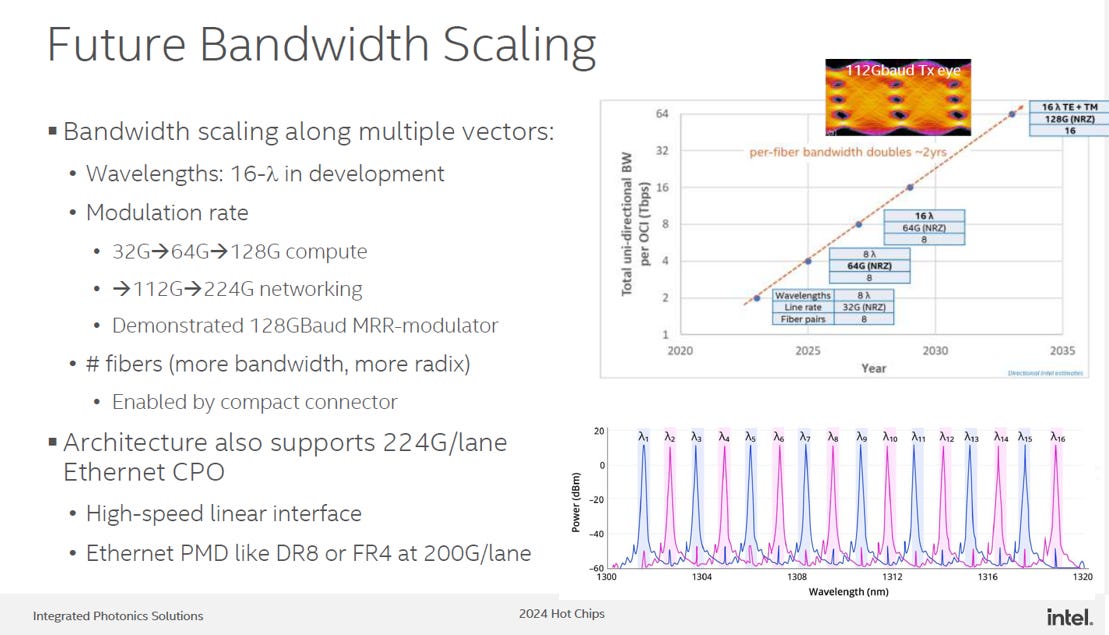
核心概念: 該路線圖體現了 Slow and Wide 策略,即通過增加通道數量而非追求極致單通道速率來提升總頻寬
關鍵目標: 透過使用 16 個波長 和 128G NRZ 調變(相對較慢且簡單),實現單光纖總頻寬高達 4 Tbps(加上極化)
優勢: WDM(Wavelength Division Multiplexing)的方法,特別適用於CPO用的MRM(Micro Ring Modulator,請參考EP14. SiPH MRM)
4.2. Slower and Wide Example
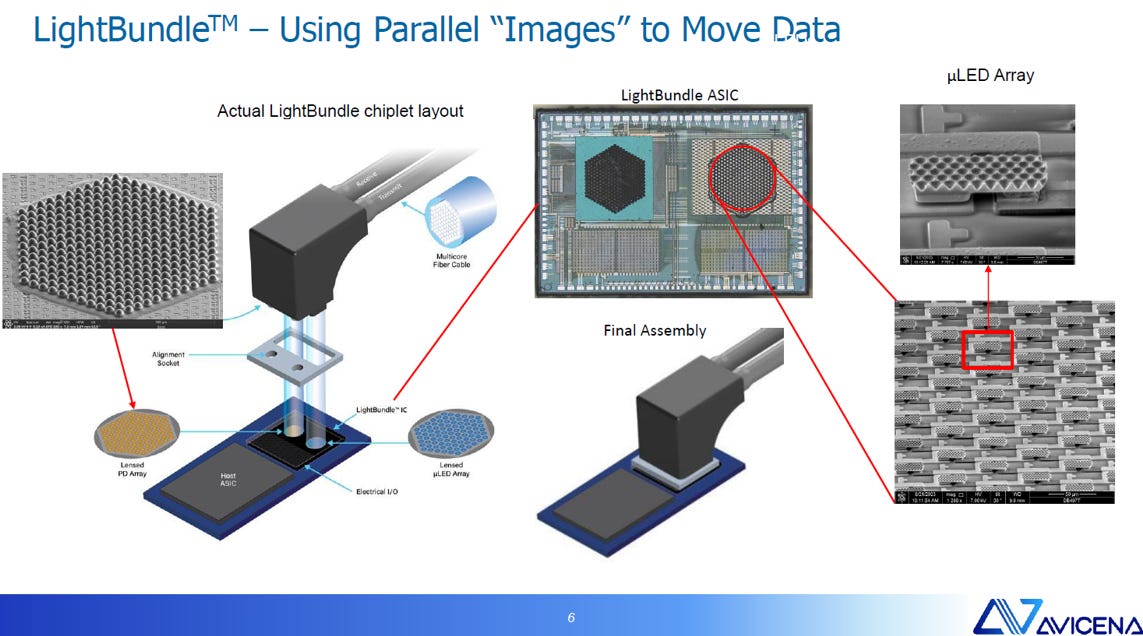
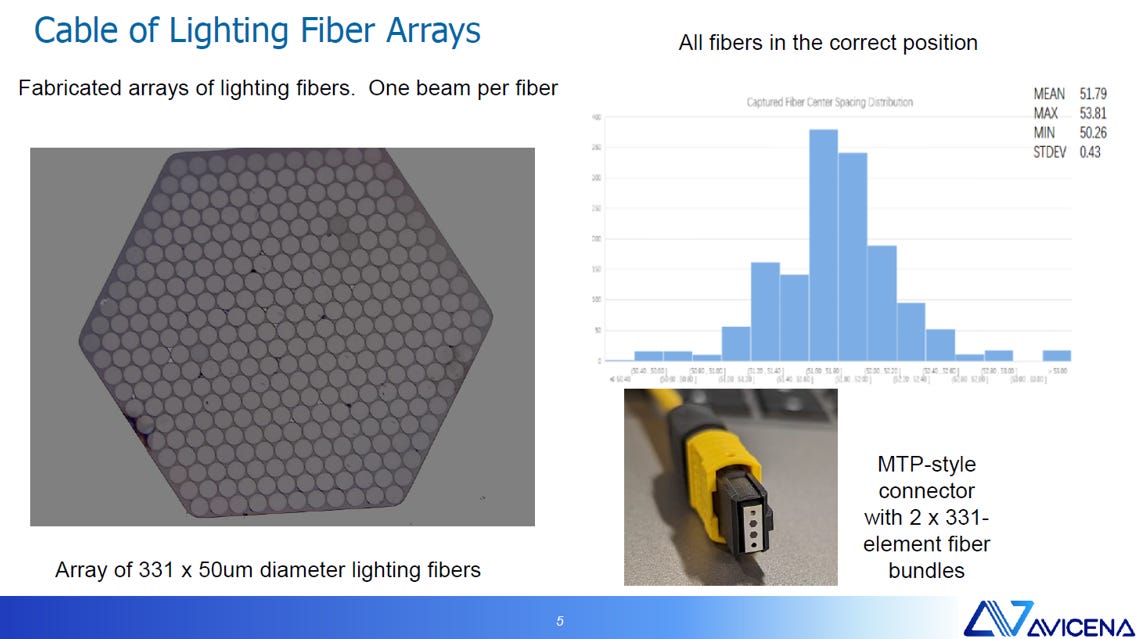
Avicena LightBundle™與 Microsoft MOSAIC 專案相似性的簡述:
核心理念: 兩者都採用 Slower and Wide (慢而寬) 的架構,即放棄極高單通道速率 (如 400G PAM4),轉向低速、大規模並行傳輸。
技術實現: 均使用 微型 LED 陣列 (MicroLED Array) 作為光源,將數據轉換為數百個並行光點(“圖像”),通過多芯光纖束進行傳輸。
主要優勢: 由於通道速率低,系統可以移除高功耗的 SerDes、DSP 和 FEC 電路,從而實現超低功耗、高密度和極短延遲的互連,特別適用於 AI/ML 系統的晶片級互連。
Avicena 的 LightBundle™ 和 Microsoft 的 MOSAIC 都是利用 微型 LED 和多通道並行來實現極低功耗、高密度、短距離互連的 Slower and Wide 技術範例。
可以觀看這段影片了解 MOSAIC 專案如何打破光學與銅纜的權衡。Disrupting the AI infrastructure with MicroLEDs
註: 請參考EP24 和 EP25,再詳細介紹Slow and Wide 和 Slower and Wide。
5. 補充說明
5.1. MLSD 與 DFE 的差異
兩者處理 ISI (符號間干擾) 的核心哲學截然不同:
核心邏輯:扣除 vs. 預測
DFE (決策反饋等化器) 採用「扣除法」,它將 ISI 視為雜訊。一旦判斷出前一個符號,就立即算出它產生的殘餘電壓並從當前訊號中減去。
MLSD (最大概似序列偵測) 採用「預測法」,它將 ISI 視為資訊。它利用通道記憶(Channel Memory)效應造成的符號間相關性,觀察一整串序列的波形來推算最可能的路徑
效能增益
DFE 沒有額外的 SNR 增益,且一旦判錯容易導致連續錯誤 (Error Propagation)。
MLSD 則能將 ISI 轉化為有用的能量,提供理論上的漸近增益 (Asymptotic Gain),在強 ISI 通道下最高可達 3 dB
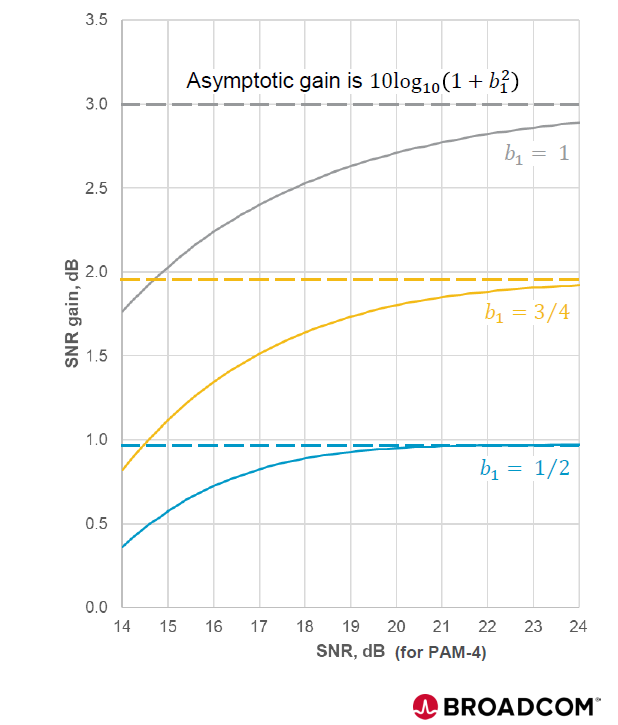
註: b1是 部分響應 (Partial Response) 的目標係數 。它量化了通道中「後一個符號」干擾「當前符號」的程度,也就是前後符號之間的 相關性 (Correlation) 強度
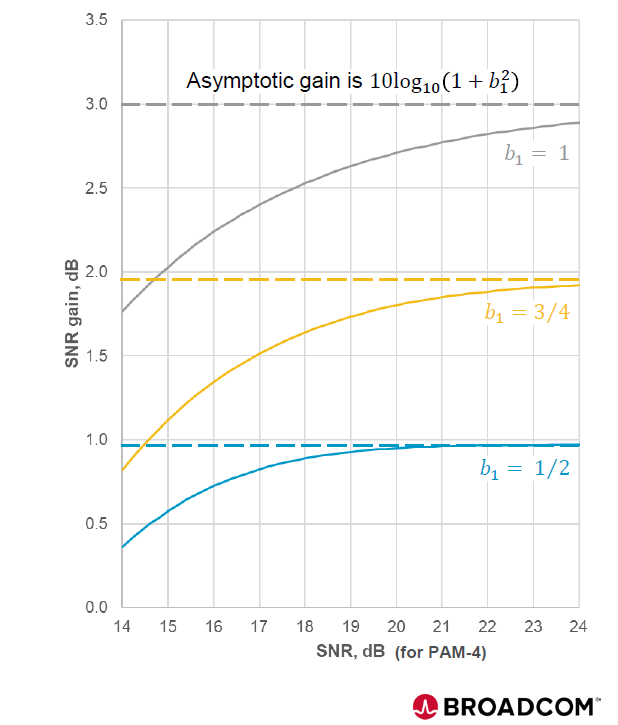
448G 的實作選擇
DFE 在 448G 頻寬下已不足以應對。MLSD 成為必須,但為了節省功耗,Broadcom 採用 Hard-Output MLSD (只輸出 0/1,不輸出信心指數),這樣既能獲得 MLSD 的 3dB 增益(理論值),又不需要處理 Soft-Decision 的複雜運算
5.2. 224G 如何升級至 448G
從 IEEE 802.3dj (224G) 演進到 448G,技術路徑主要經歷了三個關鍵改變:
調變格式從 PAM-4 轉向 PAM-6
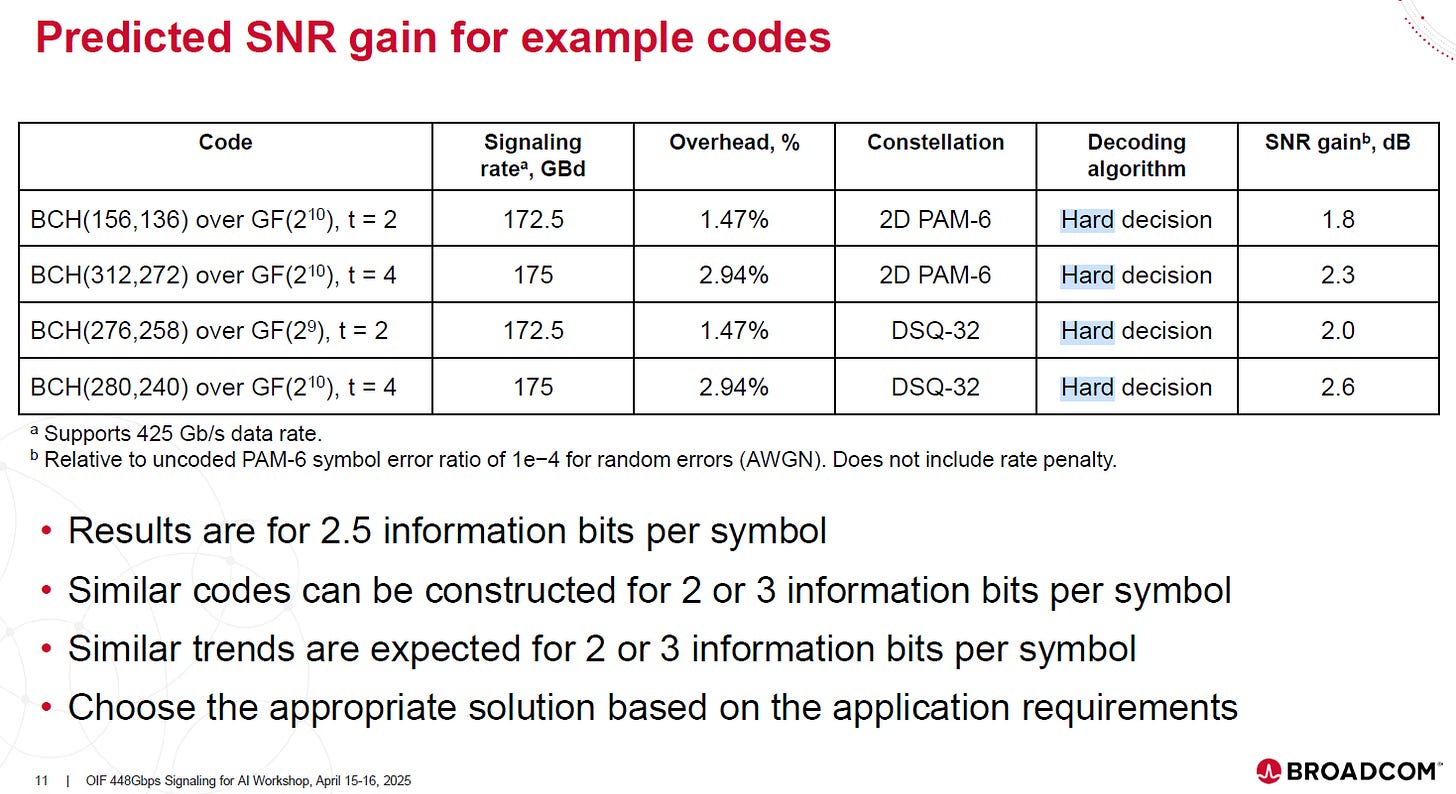
為了避免使用 PAM-4 時 Nyquist 頻率飆升至無法實現的 112 GHz,448G 改用 PAM-6 。這將 Signaling Rate 控制在 170 GBd (Nyquist 頻率約 85 GHz),以符合現有通道材料的物理極限 。雖然 PAM-6 的 SNR 天生比 PAM-4 差了 3.6 dB,但這是換取頻寬可行性的必要犧牲 。
FEC 從 Hamming 升級為 BCH
為了彌補 PAM-6 帶來的 SNR 缺口,Inner FEC 從 224G 的簡單 Hamming Code 升級為糾錯能力更強的 BCH Code (如 BCH(312,272)) 。這個改變能提供約 2.3 dB 的額外增益 。Broadcom 特別強調採用 Hard-Decision (硬判決) 解碼算法,以避免 Soft-Decision 帶來的高功耗與設計複雜度

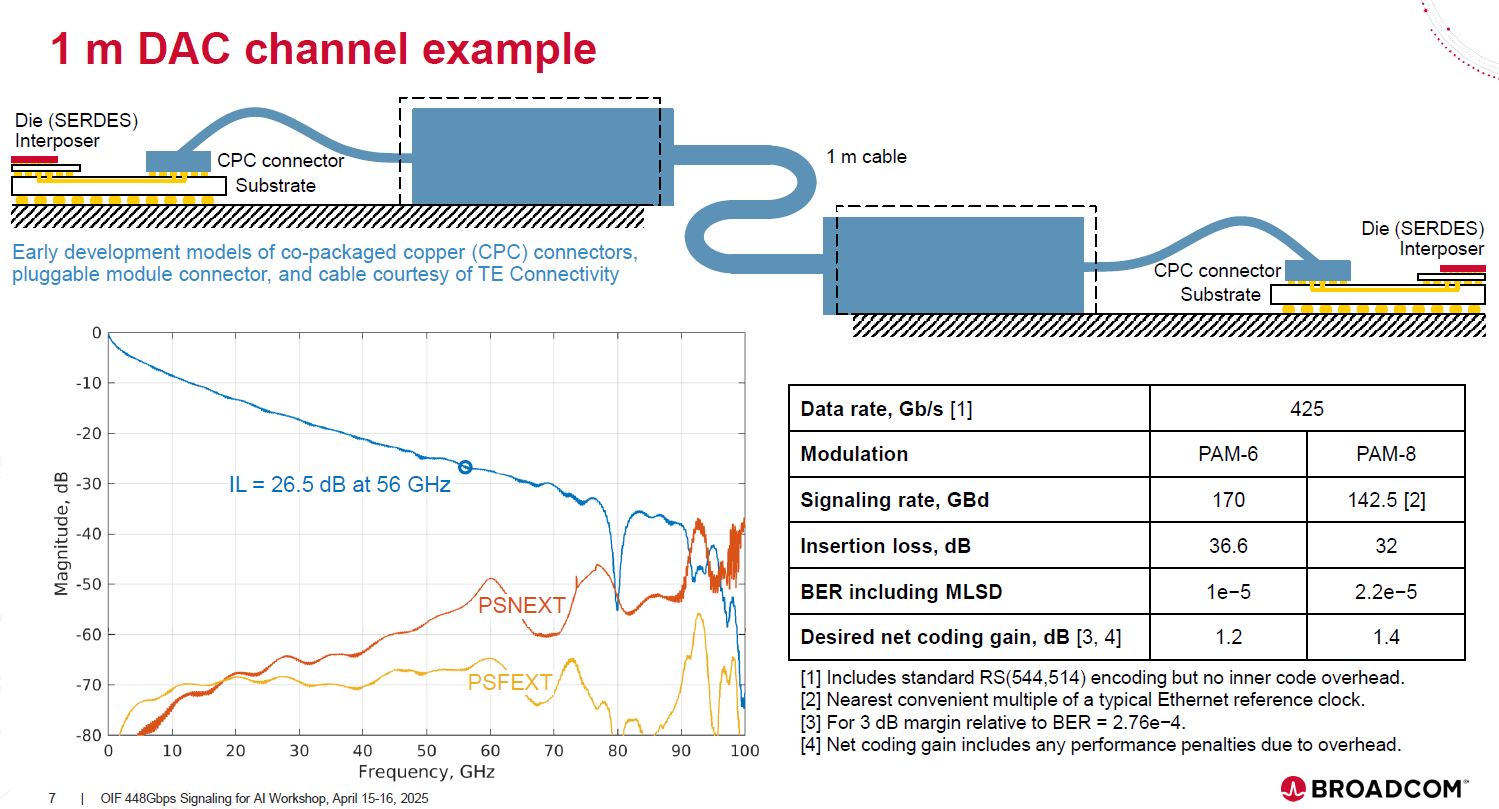
互連依賴 MLSD 與 Inner Code 的組合
在 448G 下,1 米長的被動銅纜 (DAC) 損耗高達 36.6 dB 。單靠傳統 EQ 已無法運作,必須同時啟用 MLSD (處理 ISI) 加上 BCH Inner Code (處理隨機錯誤),才能將誤碼率 (BER) 壓低至 1e-5 的可用範圍
5.3. 高速矽光子三大物理層面的核心問題
矽材料的物理極限 (Optical Limit)
問題: 傳統矽 (Silicon) 波導在處理高功率雷射時(224/448G SNR需求),會產生雙光子吸收效應 (TPA),導致光訊號非線性損耗大增,光傳不遠且效率變差。
對策: 必須引入 SiN (氮化矽),因為它幾乎不吸光,能承受高功率傳輸
電光頻寬的瓶頸 (Bandwidth Limit)
問題: 單通道速率衝上 200G+ 時,傳統矽光調變器 (Si Modulator) 的物理頻寬已達極限,硬衝會導致訊號失真嚴重。
對策: 需要更強的材料如 TFLN (薄膜鈮酸鋰) 來突破頻寬天花板,或者利用 WDM (波分複用) 增加車道數來分擔流量。
封裝寄生效應的阻礙 (Electrical Limit)
問題: 在 224G 速率下,電子晶片 (EIC) 與光子晶片 (PIC) 之間只要有一點點距離 (如打線或凸塊),產生的寄生電容與電阻 (RC Delay) 就會把高頻訊號「吃掉」。
對策: 必須採用如TSMC SoIC-X (Hybrid Bonding),讓晶片直接銅對銅垂直堆疊,消除傳輸距離以保全訊號完整度。
(參考EP14. SiPH MRM介紹)
總結
224G/448G 的挑戰在於「矽材料本身不夠用了 (損耗/頻寬)」以及「傳統封裝太慢了 (電阻電容)」,因此必須引入新材料 (SiN/TFLN) 與 先進3D封裝 (SoIC)。
6. 後記
NVIDIA 在 CES 2026 的最新發佈與技術細節:

NVLink 6 採用的是 400G /lane SerDes 速率 !!
這確實打破了業界原先的預測(TrendForce 圖表中對 VR200 的估計)。業界原先認為 NVIDIA 會走「Lane Doubling (通道翻倍)」的保守路線,但 NVIDIA 選擇了更激進的「Speed Doubling (速率翻倍)」路線。
可能原因 - 線纜密度的物理極限:
NVL72 機櫃背面已經使用了超過 5,000 條銅纜。如果採用「Lane Doubling (200G x 4 lane)」,線纜數量將會翻倍,這在物理空間、重量和氣流阻擋上都是災難性的。只有將單條線的速度拉高到 400G,才能在「不增加線纜數量」的前提下讓頻寬翻倍。
OIF 才剛開始 Study 448G,NV 怎麼做到的?
封閉生態系 (Proprietary Loop):
OIF 制定 448G 標準是為了讓 Broadcom 的 Switch 能接 Intel 的 CPU,還要能接各种光模塊,必須考慮極高的相容性 (Interoperability) 和各種惡劣環境。
NVLink 6 的兩端全是 NVIDIA 自己的晶片(GPU 端是 Rubin,Switch 端是 NVLink 6 Switch)。NVIDIA 可以使用非標準的 Custom SerDes,甚至可能使用了類似 PAM-6 或更激進的調變技術,只要這兩顆晶片能溝通就行,不需要管別人。
液冷是關鍵 (Liquid Cooling):
400G/lane 的訊號衰減和發熱非常可怕。OIF 還在研究如何用風冷或低功耗達成。
但 NVIDIA 在 Rubin 平台直接規定 NVLink 6 Switch 必須採用液冷。這等於是用暴力的散熱手段,解決了 400G SerDes 高溫導致的訊號不穩問題,這是通用標準組織無法預設的條件。