EP17. Scale-Up Ethernet(SUE)簡介

在Hotchips 2025看到Broadcom的介紹,如何改進TH5(Tomahawk 5)成為TU(Tomahawk Ultra),以滿足Scale-Up網路的要求。
摘要內容分享,歡迎討論。
1. Collective Communication
1.1. 基本概念
Collective Communication(集合通訊) 指的是一組處理ranks (例如 GPU、CPU、XPU 等)之間的通訊模式。
collective operations 涉及「一對多、多對一、多對多」等群組操作。
在 HPC(高效能運算) 與 AI 訓練叢集 中,這是平行程式設計模型的核心,特別是分布式深度學習需要大量 梯度同步 與 參數交換。
1.2 常見Patterns
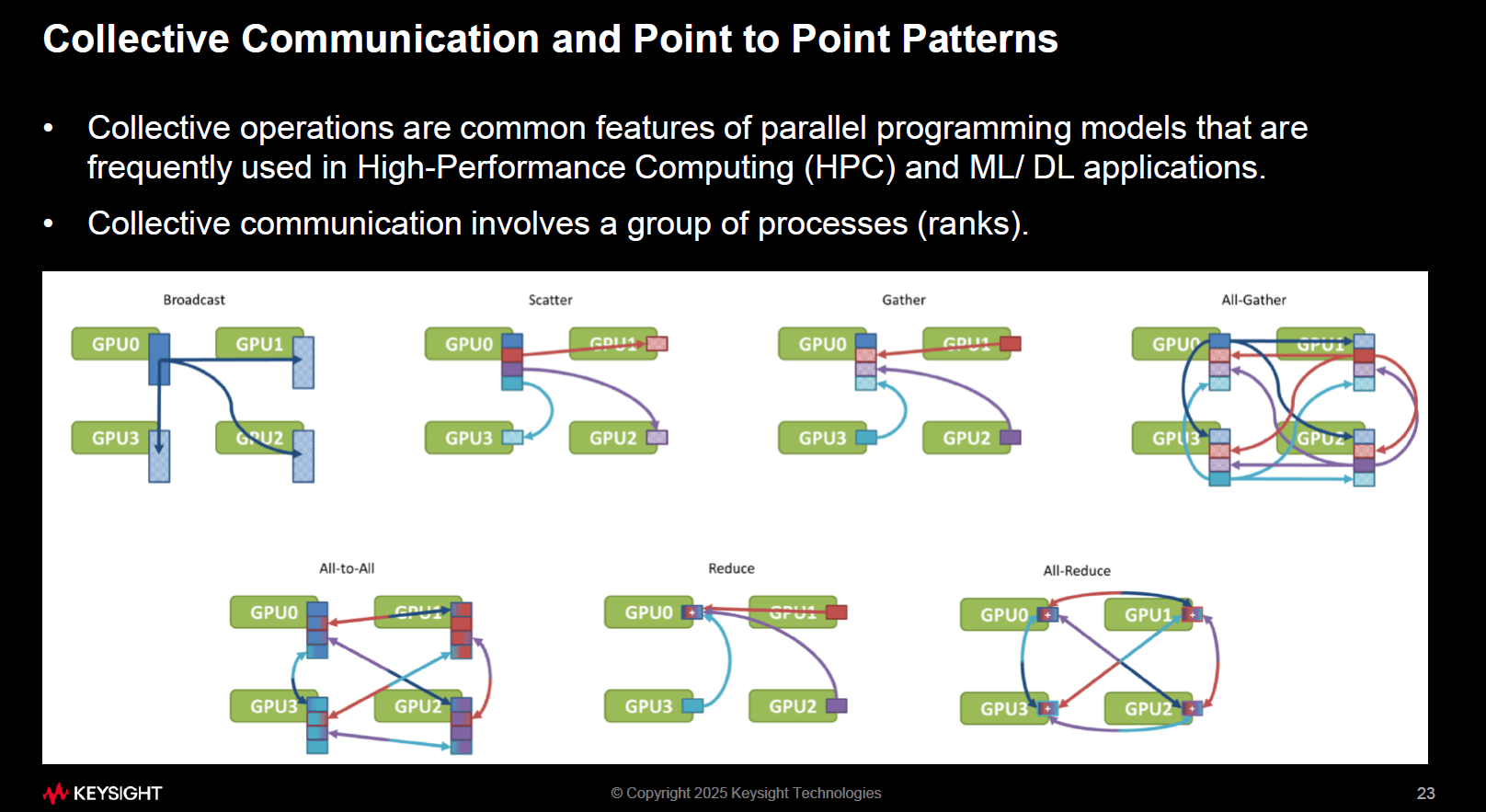
Broadcast
一個 GPU/Rank 把資料傳給所有其他節點
典型應用:將新的 model weights 廣播給所有工作節點
Scatter
一個節點把不同的資料分片分配給多個節點
典型應用:分割 dataset,分派給多個 GPU
Gather
多個節點的資料彙整到一個節點
典型應用:收集不同 GPU 的中間計算結果
All-Gather
每個節點收集到所有其他節點的資料
典型應用:在訓練中同步 activation(激活值) 或中間結果
All-to-All
每個節點把自己的資料分片傳給所有其他節點,並從其他節點收集
典型應用:MoE(Mixture of Experts)模型中的token shuffle(token 洗牌/重分配)
Reduce
把多個節點的資料合併(sum, max, average 等),集中到一個節點
典型應用:計算 loss gradient 的總和
All-Reduce
把所有節點的資料做合併,並把結果分發回所有節點
最重要的 Collective,在分布式 AI Training中用來做 梯度同步。
例如:每個 GPU 計算 local gradient → All-Reduce → 得到 global gradient → 更新參數。
1.3. 分層架構中的角色
Application Layer(應用層)
位置:最上層,由 AI 框架(TensorFlow、PyTorch、JAX…)呼叫
功能:提供 AllReduce、Broadcast、Gather、Scatter、Barrier 等 集體運算接口
特點:
使用者/演算法看到的是 「function call」
不需要知道底層網路怎麼跑
Middleware / Collective Libraries
位置:介於 Application 和 Transport/Link 之間
代表:NCCL (NVIDIA)、RCCL(AMD)、OneCCL (Intel)、MPI(Message Passing Interface,用於HPC)
功能:
把 collective API 翻譯成實際傳輸動作
選擇最佳路徑:
Scale-Up → 用 NVLink/UALink/SUE
Scale-Out → 用 InfiniBand/RoCE/UEC
決定演算法(Ring AllReduce / Tree AllReduce / Hierarchical AllReduce)
👉 Middleware 是集體通訊的「排程員」
Transport Layer
位置:節點之間傳輸資料的協定層
代表:TCP(傳統可靠傳輸)、UDP(RoCEv2 基礎)
功能:
定義 資料包怎麼傳(可靠性、順序、流量控制)
主要用於 Scale-Out(因為要跨 switch/路由)
Scale-Up 不經過 Transport(因為是直連)
Link / Physical Layer
位置:最底層,點對點的連接與實體介質
代表:NVLink、UALink、PCIe、CXL、Ethernet PHY
功能:
定義 bit 怎麼傳(信號編碼、誤碼檢測)
提供「高速通道」,上層協定用它來搬運資料
總結關係
Application Layer (Collective):定義「要做什麼運算」(AllReduce, Broadcast)
Middleware:決定「怎麼做最好」,選擇演算法與底層路徑
Transport Layer:定義「跨節點如何傳輸資料」(Scale-out)
Link/Physical Layer:定義「位元怎麼在電線/光纖上跑」
👉 可以想成:Collective Communication 是
Application 提需求 → Middleware 拆任務 → Transport/Link 負責送貨 → Physical 提供馬路。
1.4. 在 HPC 與 AI Cluster 的重要性
HPC:模擬、科學計算需要不同 rank 共享數值結果,確保全域一致
AI Cluster:深度學習模型需要巨量 GPU 平行訓練,collective 通訊是 Data Parallel 與 Tensor Parallel 的基礎
Data Parallel:每個 GPU 訓練一部分資料,但需要頻繁 All-Reduce(梯度同步)
Tensor Parallel:將大模型 tensor 切分到多個 GPU,需要 All-to-All / All-Gather
Pipeline Parallel:跨節點傳輸 activations,對應 Scatter / Gather
對網路的挑戰
頻寬需求極高:
例如 1k Hz 的同步,每 GPU 需要上百 GB/s 等級,接近 HBM 記憶體頻寬
延遲敏感:
All-Reduce 等操作必須在數百 ns 到數 µs 內完成,否則 GPU idle,浪費算力
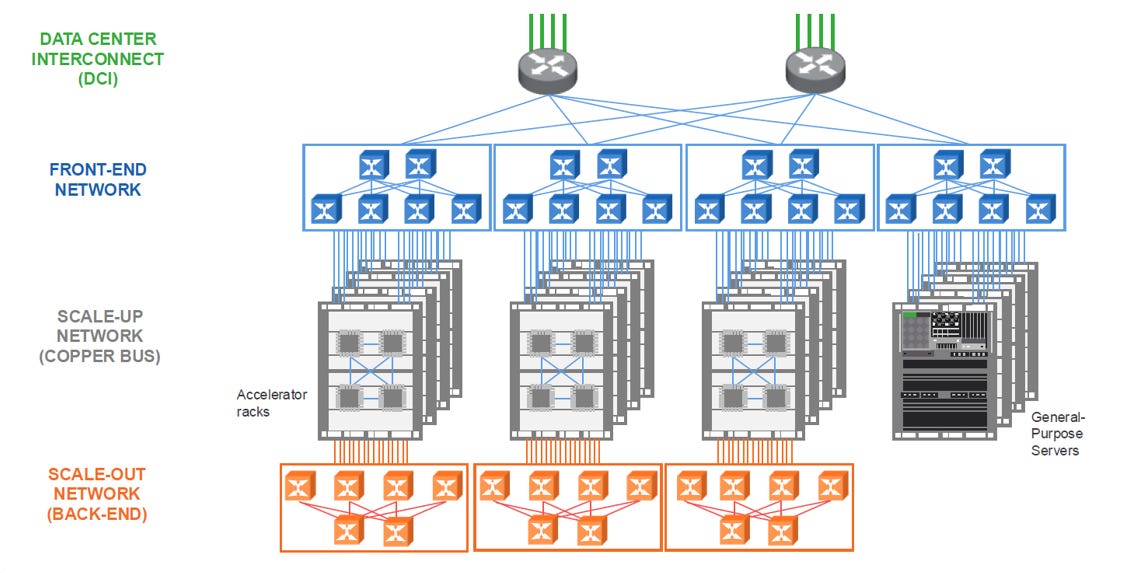
網路架構:
Scale-Up Fabric(如 NVLink, UALink, XPU Direct):ns 級延遲,適合 Tensor Parallel
Scale-Out Fabric(如 InfiniBand, RoCE, Ultra Ethernet):µs 級延遲,適合 Data Parallel
Front-End Network (FE):資料讀取與分派
總結
Collective Communication 是 AI Cluster與 HPC 的血液循環。
沒有高效的 collective operations,GPU cluster 難以放大至數千顆 GPU 進行同步運算
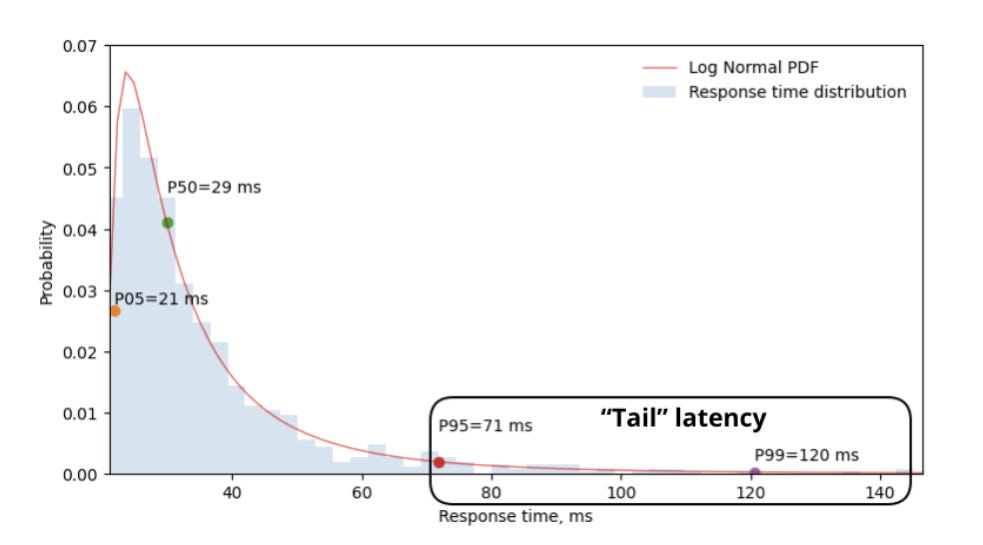
1.5. Traffic 特徵
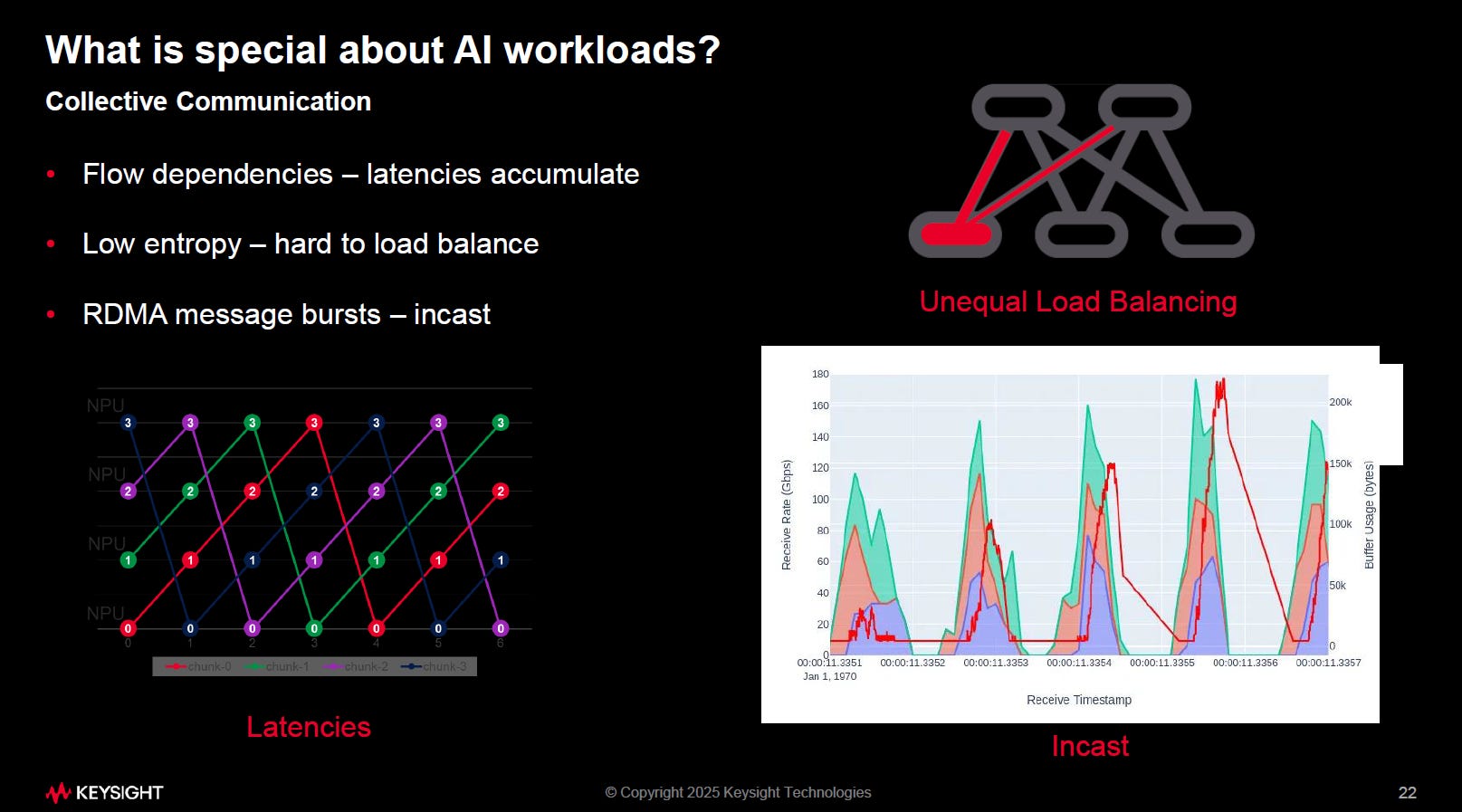
Flow Dependencies(流程相依,延遲累積)
訓練過程中的 collective 操作(如 All-Reduce)必須等待所有 rank 資料到齊才能進行。
一個節點延遲會拖累整體 → Tail latency累積效應
在圖中可見多個 chunk 的傳輸相依,造成 pipeline delay
Low Entropy(低熵流量,難以負載均衡)
流量模式高度規律(例如每一層都要做同步),不像一般資料中心工作負載有隨機性。
難以靠 hash 或 ECMP 達到良好 load balancing → 容易出現「不均勻負載」
RDMA Message Bursts – Incast(訊息突發,導致擁塞)
在 All-Reduce / All-Gather 等操作中,會同時有許多 RDMA 傳輸 burst
造成 Incast 問題:多個來源同時傳給同一目的,導致 Buffer 壅塞、丟包、重傳
上圖右下顯示突發流量下的 buffer 使用與接收速率,呈現尖峰
1.6. HPC和AI Cluster的差異
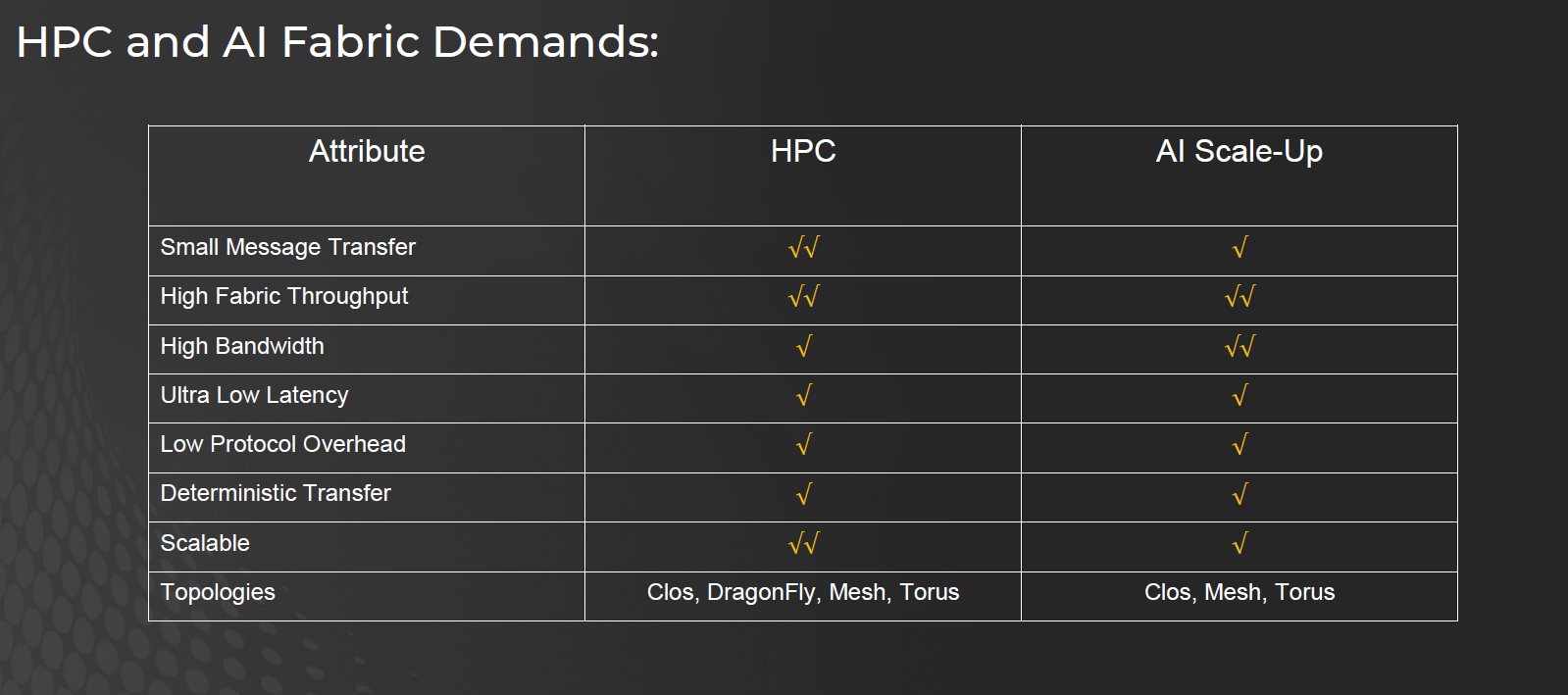
HPC (High-Performance Computing)
偏向 小訊息傳輸,強調 低延遲、低協定負擔、確定性傳輸。
網路拓撲多樣(Clos、DragonFly、Mesh、Torus),方便大規模擴展
適合科學模擬、MPI 等需要精確同步的工作
AI Scale-Up
偏向 大訊息傳輸(梯度、參數),核心需求是 高頻寬與高吞吐。
延遲要求稍寬鬆,但仍需 ns–µs 級
常用拓撲:Clos、Mesh、Torus;更多依賴 Scale-Up Fabric (NVLink/UALink/SUE)
適合大規模深度學習訓練與推理
HPC = latency-driven,小訊息同步;
AI Scale-up = bandwidth-driven,大訊息交換
HPC 排名依據:以 Top500 為主,看 Linpack (FP64) 性能、大規模 可擴展性,以及 能效 (Green500)。重點是 雙精度科學計算能力。
AI Cluster 排名依據:以 MLPerf 為主,看 訓練完成時間、推理吞吐與延遲,以及 Collective Communication 效率與能效。重點是 大模型訓練/推理速度。
👉 HPC 比算力,AI Cluster 比吞吐
2. Broadcom SUE(Scale-Up Ethernet)
2.1. Ethernet 的短版

延遲差距
以太網交換晶片的 hop latency 大約在 250–400ns,跨伺服器甚至會到 微秒等級。
Scale-Up 互聯(像 NVLink、UALink)要求是 幾 ns ~ 數十 ns,才能支援 tensor slicing 的即時同步。
👉 Ethernet 太慢,差 1–2 個數量級
小封包效能不足
Ethernet 本質上設計給「大封包、長流量」,即使有優化,小封包還是要經過 序列化、封包化、FEC 編碼解碼。
Scale-Up fabric 是 flit(flow control unit) 級直連傳輸,完全不需要封包拆裝。
👉 Ethernet 天生不擅長小訊息傳輸
可靠性非原生
Ethernet 要靠 PFC/ECN這類附加機制,才能做到近乎 lossless
Scale-Up 協定(NVLink/UALink)則是 硬體層級保證零丟包(壅塞造成),flow control 內建在鏈路協定裡
👉 Ethernet 的 lossless 是「補救式」,不是天生屬性
協定開銷偏高
Ethernet 封包 header、序列化延遲、pipeline 轉發,都會造成額外 overhead
Scale-Up fabric 協定極簡,只針對 GPU–GPU/CPU–GPU 設計,沒有這些額外負擔
👉Ethernet 在高頻寬下 header overhead 雖小,但對超低延遲需求還是顯著
總結
Ethernet 的現狀已經很強,可以用在 Scale-Out(跨伺服器,µs 級集群通訊),但
延遲太高
小封包效能差
Lossless 不是原生
協定開銷過大
因此,它 無法滿足 Scale-Up (GPU–GPU/CPU–GPU 直連) 的需求。
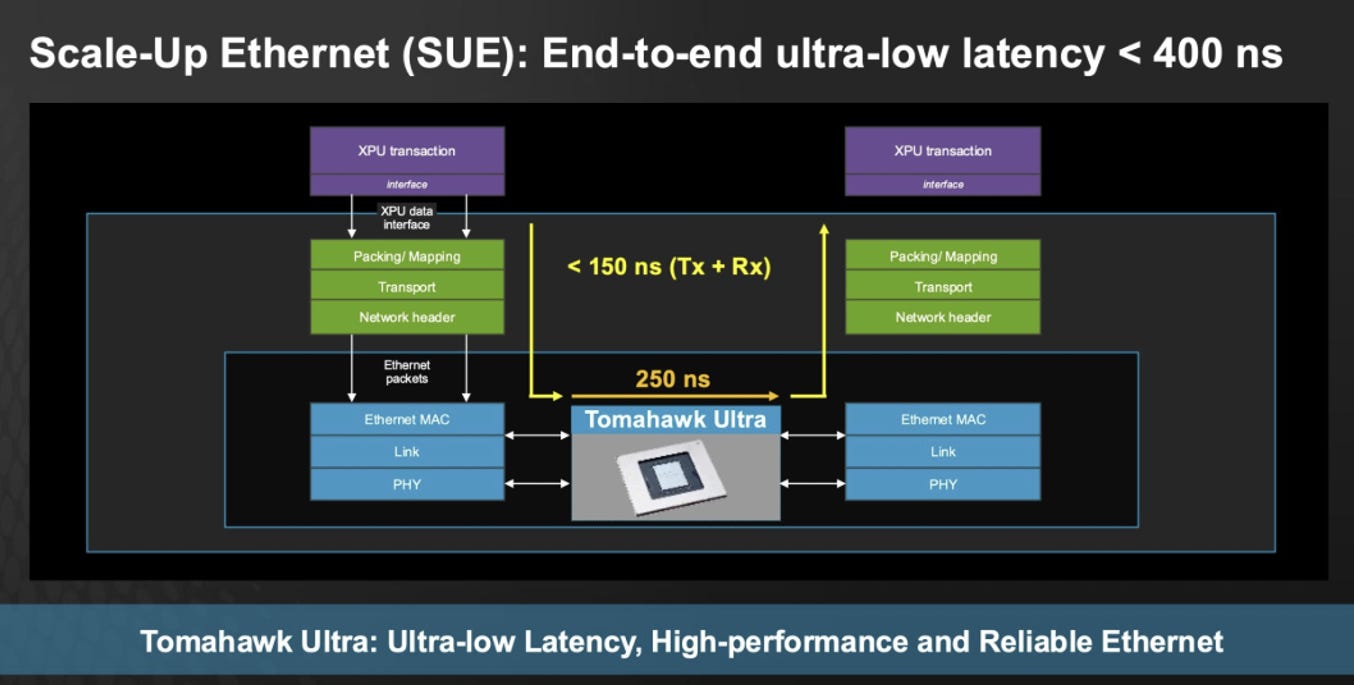
2.2. Tomahawk Ultra(TU) 解決方案

Performance(效能)
250ns latency:hop 延遲約 250ns,針對 AI/HPC collective traffic 優化。
51.2T @ 64B:交換容量可達 51.2 Tbps,小封包吞吐量保持高效能
77 Bpps:封包處理能力可達 每秒 770 億個封包(64B)
👉 說明 TU 在「小封包高頻率 + 低延遲」環境能支撐 HPC/AI 負載
Efficiency(效率)
In-Network Collectives(INC):支援在交換器內部直接做部分 collective 運算(類似 Nvidia SHARP in-network reduction),減少 GPU 間需要傳的資料量。
Optimized Ethernet Headers:減少協定開銷,降低 header overhead 對 AI 小訊息傳輸的影響。
👉 提升 AI collective 的帶寬利用率。
Reliability / Lossless(可靠性 / 無丟包)
LLR (Link Level Retry):針對物理通道誤碼 (SNR 問題) → 進行鏈路級重傳,確保正確性。
CBFC (Class-Based Flow Control):針對壅塞 (congestion) → 分類流控,避免 buffer overflow,提升 lossless 能力。
👉 同時解決 channel error 與 congestion loss 兩種來源
Congestion Control(壅塞控制)
Broadcom 提出自家演算法(如 Adaptive Routing, ECN + CNP 改良, CBFC)
避免 incast、HOL blocking,並改善大規模 GPU collective 下的 tail latency
👉 讓多機同步(AllReduce/Broadcast)時,流量不會卡在某些節點
Programmable Visibility / Telemetry(可程式化可視化 / 遠端監控)
內建 即時網路遙測,可偵測壅塞、封包延遲、路徑利用率
支援 programmable pipeline,方便雲端/AI 運營商調整流控策略
Topology Aware Routing(拓樸感知路由)
針對 AI/HPC 網路拓樸(Clos、Dragonfly、Fat-Tree),提供 最佳化路由選擇
避免流量集中在特定鏈路,提升全域網路利用率
總結
Tomahawk Ultra (TU) 的定位核心就是 SUE (Scale-Up Ethernet)
它強調的 250ns latency、INC、LLR/CBFC lossless、topology-aware routing,本質上都是在補 Ethernet 的短板,讓挑戰NVLink/UALink
換句話說,Broadcom 是要把 Ethernet 變成 同時能做 Scale-Up + Scale-Out 的統一底層。
3. SUE Key Technology介紹
3.1. Latency比較

總結:
NVLink:效能最好,但封閉 (NVLink Fusion 開放版本,允許異質 XPU 廠商接入)
UALink:想成為開放式 NVLink,還在起步
SUE:延遲雖高於 NVLink/UAL,但勝在 Ethernet 相容性,方便雲大廠直接部署。
3.2. AllReduce 運算
傳統 All-Reduce (Ring 為例)
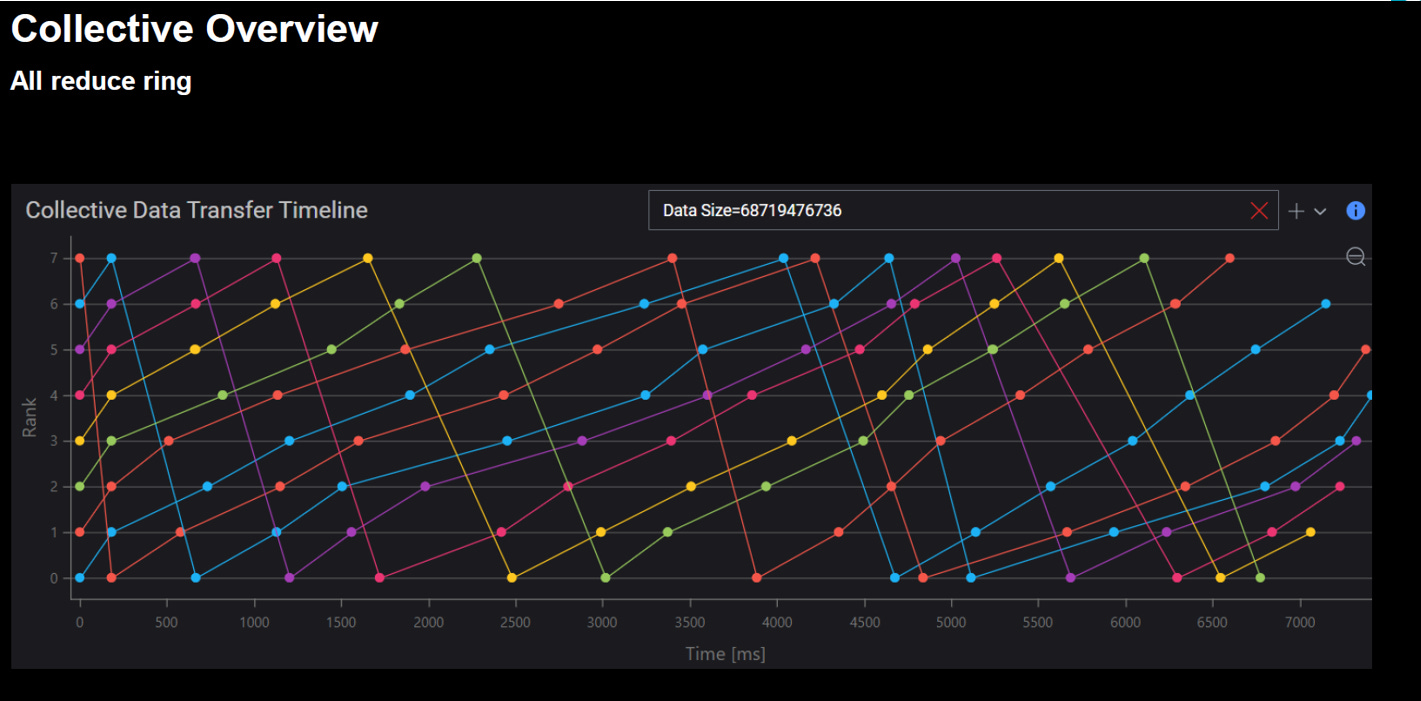
流程
每個 XPU(GPU/CPU/加速器)先算出本地 gradient
collective library(NCCL/MPI/RCCL)把梯度切分成 chunk
透過 ring/樹狀拓樸,逐 hop 傳遞並加總
最後每個 XPU 都得到完整結果
特徵
計算與通訊都在 XPU 上完成
資料在多個 hop 間傳遞,每個節點都要參與計算 + 轉發
TU All-Reduce (In-Network Collectives, INC)
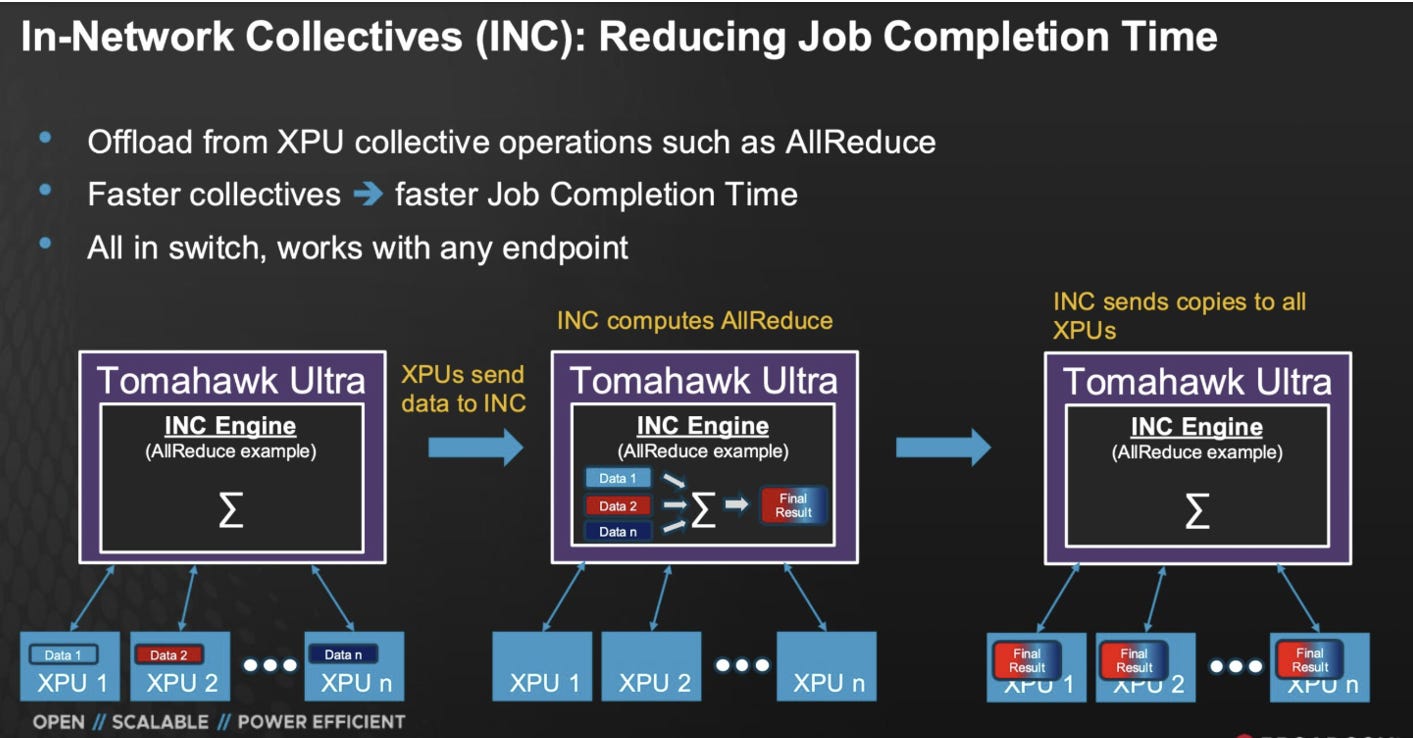
流程
XPU 直接把本地梯度送進 Tomahawk Ultra switch
INC 引擎 (內建於 TU ASIC) 在網路層執行 All-Reduce(例如加總)
Switch 完成計算後,把最終結果一次性廣播回所有 XPU
特徵
計算 offload:collective 運算由 switch 處理,不佔用 XPU
流量減少:每個 XPU 只需送一次 + 收一次。
低延遲:資料在 switch 內聚合,避免多 hop 累積
優點
更快完成時間 (Job Completion Time, JCT):少了中間 hop 延遲
釋放 XPU 資源:XPU 專心算,不必忙著轉發和加總
網路利用率更高:避免傳統 ring 中的重複傳輸
👉 Broadcom 推 INC 的目的,就是讓 Ethernet switch 不只是傳輸,還能幫忙計算 collective,針對 AllReduce 加速。
3.3. Link Layer Retry(LLR)

定位
LLR 是插在 MAC 層之上(如上圖)的一個可選協定層。
目的是 補足 FEC 的不足,降低誤碼後帶來的高延遲重傳。
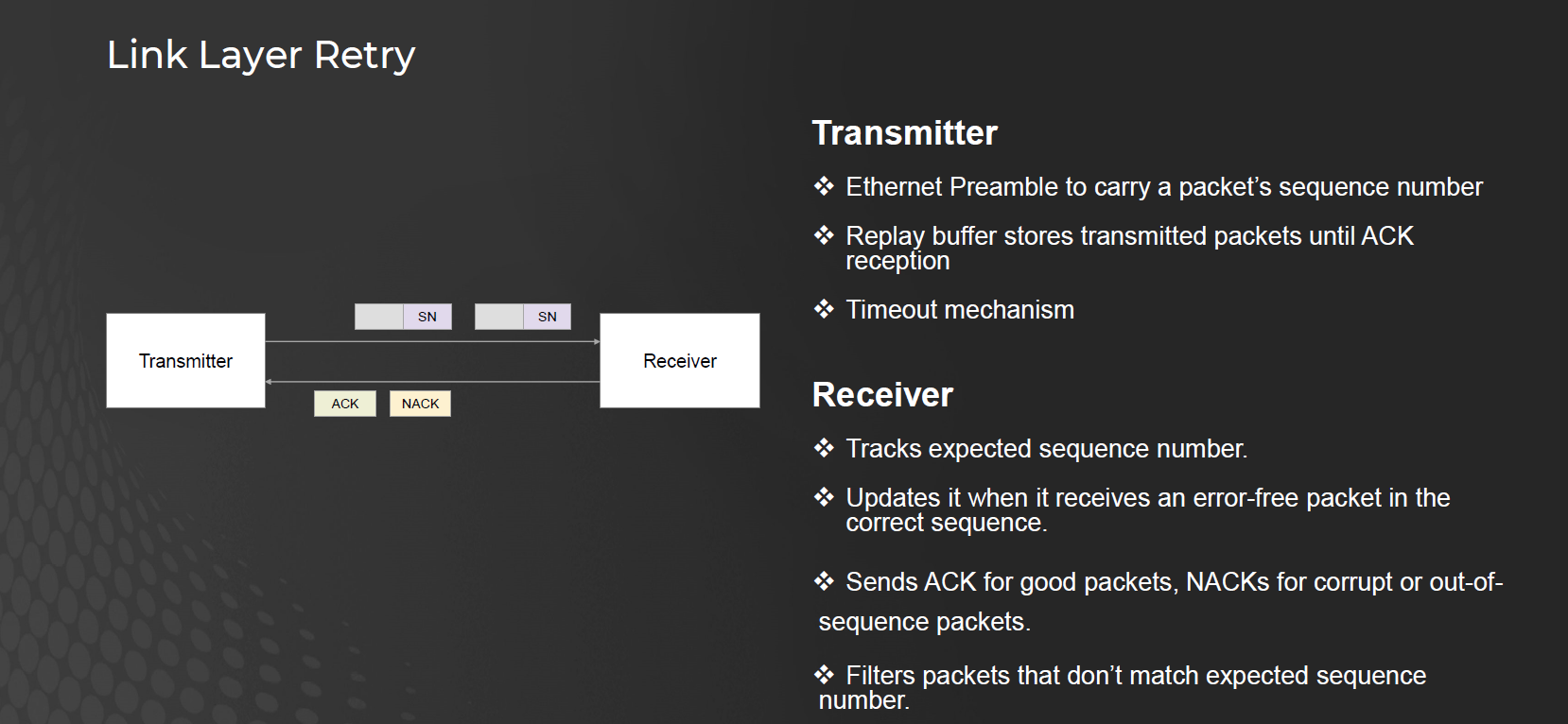
運作原理
傳送端 (Transmitter)
對每個封包加上 序號 (Sequence Number, SN)
將已傳送的封包放在 replay buffer 中,直到收到 ACK
若收到 NACK 或 timeout,會立即重傳
接收端 (Receiver)
追蹤 期望序號,確認封包順序。
對正確無誤的封包發送 ACK。
對損壞或序號錯亂的封包發送 NACK。
丟棄不符合期望序號的封包。
優勢
降低端到端 Retransmission 開銷:不必等到 TCP/應用層才發現錯誤再重傳,延遲大幅縮短。
提升可靠性:適合高頻寬、高 BER 環境(如 224G PAM4 SerDes)
總結
LLR = Link 層的小型重傳機制。
它不是取代 FEC,而是 與 FEC 互補:
FEC 修隨機錯誤。
LLR 處理突發錯誤、序號錯亂。
最大好處:減少高延遲端到端重傳,提升 HPC/AI 網路的穩定性與低延遲特性
3.4. Credit Based Flow Control(CBFC)
CBFC 是 Broadcom 在 Tomahawk Ultra 針對 AI/HPC 提出的機制,本質上是把 傳統 Scale-Up fabric (NVLink/UALink) 的 credit-based flow control 搬到 Ethernet。
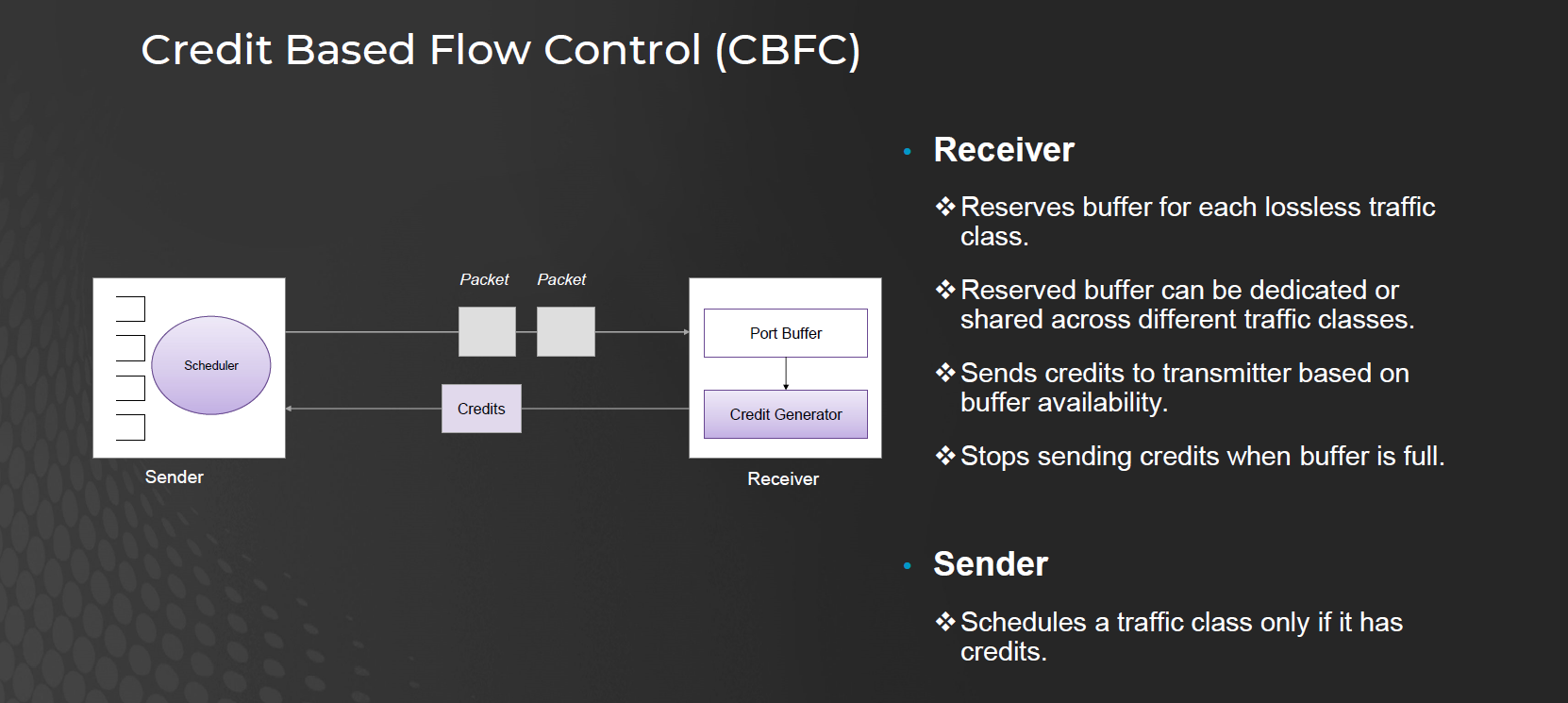
運作方式
Receiver
為每個「lossless traffic class」保留 buffer。
Buffer 可以是獨佔或多 class 共用。
根據 buffer 可用度發送 credits 給傳送端。
如果 buffer 滿了 → 停止發送 credits。
Sender
只有在有 credit 時,scheduler 才能發送封包。
Credit 用完 → TX 停止傳送,避免 buffer overflow。
👉 效果:保證 零丟包 (lossless),因為 TX 永遠不會送超過 RX 能收的資料
與傳統方法(PFC,ECN)比較
PFC (Priority Flow Control)
機制:用 PAUSE frame 停止傳送。
問題:粗粒度、容易 HOL(Head-of-Line) blocking。
ECN (Explicit Congestion Notification)
機制:壅塞時打標記,通知 sender 降速。
問題:反應慢,仍可能丟包。
CBFC (Credit Based Flow Control)
機制:receiver 發送 credits,sender 只有在有 credit 時才能傳送。
優點:零丟包、細粒度、延遲低,最接近 NVLink/PCIe 的硬體式 flow control
PFC 粗糙、ECN 延遲大,CBFC 才是針對 AI/HPC Scale-Up 的最佳解法
3.5. AI Fabric Header(AFH)
設計動機 (Motivations)
HPC / AI Scale-Up 需要大量 memory load-store 操作,payload 往往很小。
傳統 Ethernet + IP header 太大(20B+),開銷過重。
線路效率 (wire efficiency) 是關鍵,必須降低 header overhead
AFH 的特色
精簡化 header,直接覆蓋在 Ethernet MAC header 上,只保留必要欄位。
地址欄位縮小(2B 或 4B),可作為:
Device ID
Local identifier
或直接映射成 IP address。
Switch forwarding 對剩餘 bytes agnostic(忽略處理),保留靈活性。
完全相容 Ethernet MAC → 容易部署

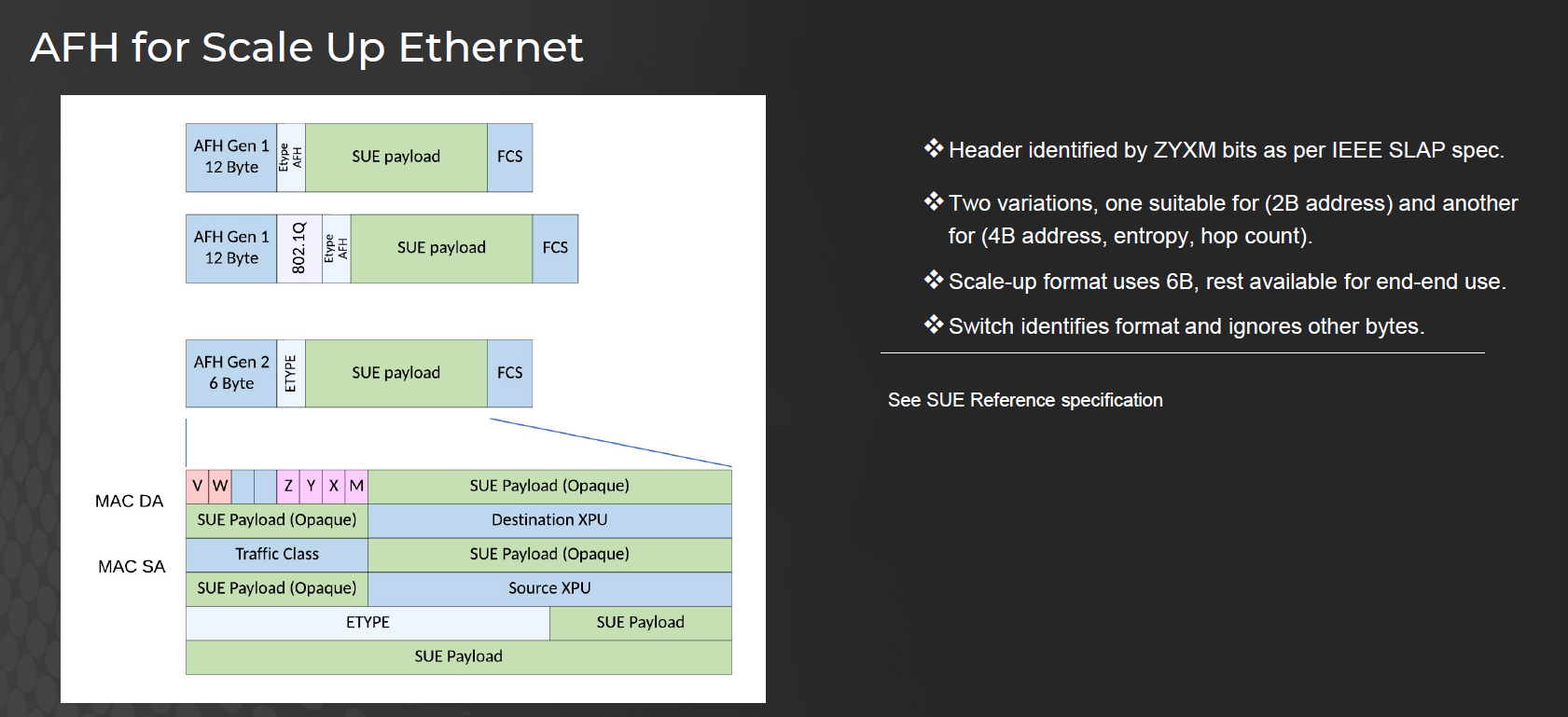
AFH 格式演進
Gen 1:12B header(包含 VLAN、ETYPE)。
Gen 2:縮減為 6B header,只留下必要 routing/traffic class 欄位。
識別方式:利用 IEEE SLAP 規範中的 ZYXM bits 區分 AFH。
Switch 只識別 AFH 部分,其他 bytes 給 end-to-end 使用。
優點
大幅減少 header overhead,提升 小封包傳輸效率。
支援 AI Scale-Up fabric (SUE) 的需求,對應 memory-like load-store 模式。
維持 Ethernet 兼容性,方便雲大廠採用。
總結
AFH = Ethernet 的精簡 header for AI/HPC。
它的核心是 降低封包開銷、提高線路效率、保持 Ethernet 相容性,讓 Scale-Up Ethernet (SUE) 更接近 NVLink/UALink 的傳輸模式