EP 30. Ethernet Update

上回我們探討了 PCIe 7.0 的極速狂飆,這次我們將視角轉向連網技術的基石——Ethernet。從底層 SerDes 的 ADC 革命,到上層 AI Fabric 的融合架構 (Converged Fabric),Ethernet 正經歷一場前所未有的技術蛻變。為什麼 NVIDIA 最新的 CX-9 網卡還停留在 800G?SNDR 又是如何取代 Jitter 成為訊號品質的新霸主?讓我們一探究竟。
1. Background
1.1. Ethernet Roadmap
AI 的需求正在加速Ethernet訊號標準化的進程,Ethernet 標準正加速朝更高頻寬演進,重點如下:
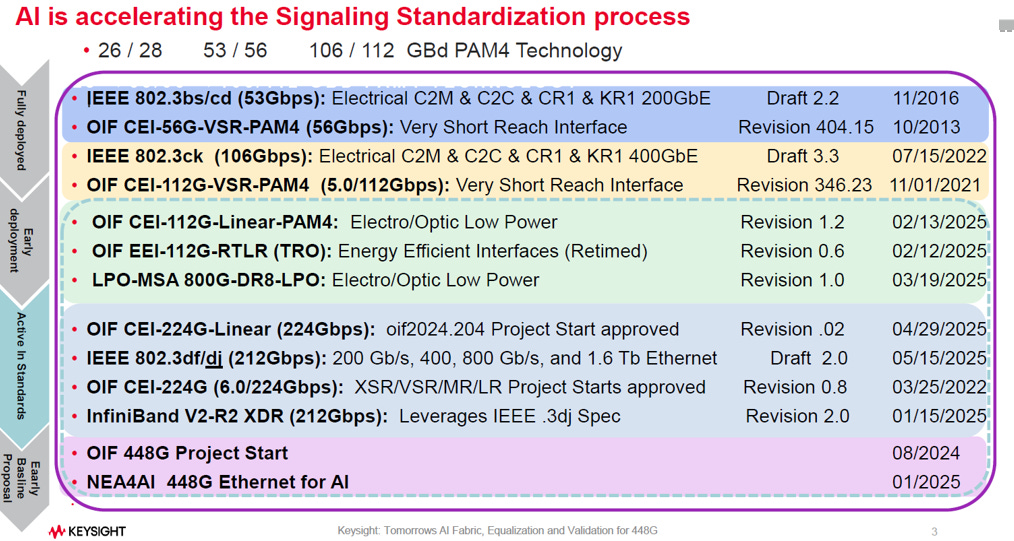
已成熟 (Fully Deployed):
單通道 100G 技術已普及,主要支援 400G 和 800G 乙太網路。
制定中 (Active In Standards):
目前標準化的重心是 單通道 200G (IEEE 802.3dj),預計於 2026 年 7 月至 8 月 正式發布標準,以實現 1.6T 的超高速乙太網路
InfiniBand XDR(下一代技術,單通道速率約 212Gbps)計畫直接利用 IEEE 802.3dj 所定義的物理層(PHY)電氣訊號標準,共用底層 SerDes 技術,以加速開發並降低成本。
未來規劃 (Future):
業界已開始針對 單通道 448G 進行早期提案,為下一代 AI 網路做準備。(參考EP23. 448G SerDes介紹)
NEA4AI = New Ethernet Applications for AI
Nvidia在今年CES展示Rubin platform,其中ConnectX-9 仍然用800Gbps。

CX-9 維持 800G 是受限於主機介面,而非網路技術:
卡在 PCIe 頻寬 (瓶頸): 目前的 PCIe 6.0 x16 插槽,實際頻寬極限只能餵飽 800G 的網卡,無法支撐 1.6T 的資料量(> 64Gbpsx16 = 1.024Tbps)。這也是為什麼業界迫切需要 PCIe 7.0 (128 GT/s) 的原因,只有到了 PCIe 7.0,單一 x16 插槽才能真正釋放 1.6T 網卡的潛力。
技術用於「減道」而非「總速」: CX-9 確實使用了先進的 200G/lane 技術,但它是配置成 4 條 200G (4x200G = 800G)
目的: 用更少的通道(4條 vs 舊款8條)達成同樣的速度,以降低功耗和簡化佈線。
註: 沒有 IB Switch? = 只是沒有「新款」IB 晶片,Rubin 仍沿用 Quantum-X800,但 NVIDIA 顯然想藉此機會大推 Spectrum-6 乙太網路交換器
市場對頻寬的需求(You need Bandwidth)正在迫使技術更新的週期變得越來越短:
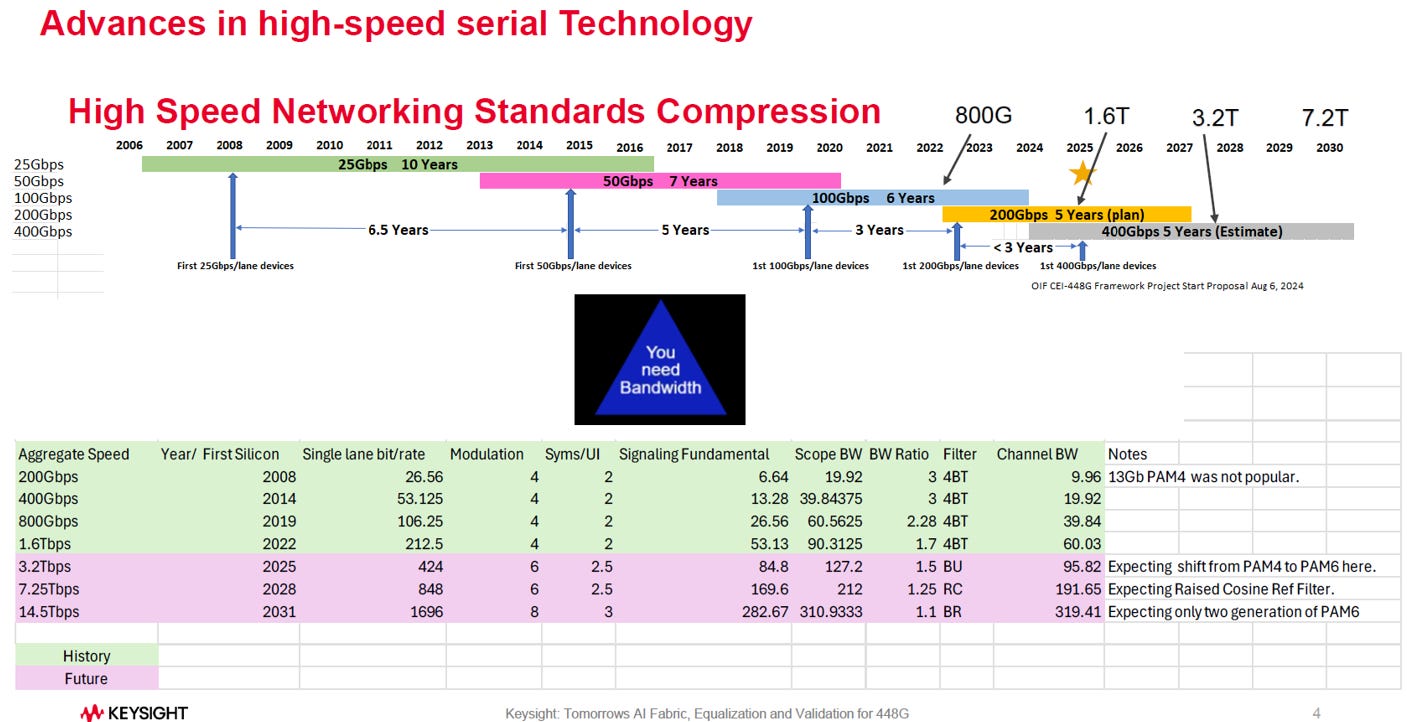
標準制定週期大幅縮短
每一代新速率標準的推出間隔正在急劇縮短
從 25G 到 50G 通道花了 6.5 年。
從 100G 到 200G 通道縮短至 3 年。
預計未來從 200G 到 400G 通道的過渡將 小於 3 年
技術演進路線圖
目前階段 (Green, ~1.6Tbps): 主流技術使用 PAM4 調變,單通道速率達到 212.5 Gbps (對應 1.6T 乙太網路)。
未來轉折 (Purple, 3.2Tbps+): 為了達到 3.2Tbps (2025年) 及更高的總頻寬,技術將發生重大變革。預計單通道速率將提升至 424 Gbps,並且調變技術將從 PAM4 轉向 PAM6 (Pulse Amplitude Modulation 6-level)
長遠展望 (14.5Tbps): 到 2031 年,預計單通道速率將達到 1696 Gbps,並可能採用 PAM8 調變。
為了應對 AI 與資料中心對頻寬的渴求,高速介面技術的更新換代速度正在加快,且即將迎來從 PAM4 到 PAM6 的技術跨越。(參考EP23. 448G SerDes介紹)
1.2. OIF (Optical Internetworking Forum) 簡介
OIF 是一個由成員驅動的全球性組織,已有超過 25 年的歷史,擁有 150 多家成員公司。其核心宗旨是 「加速光網路技術的市場採用」。
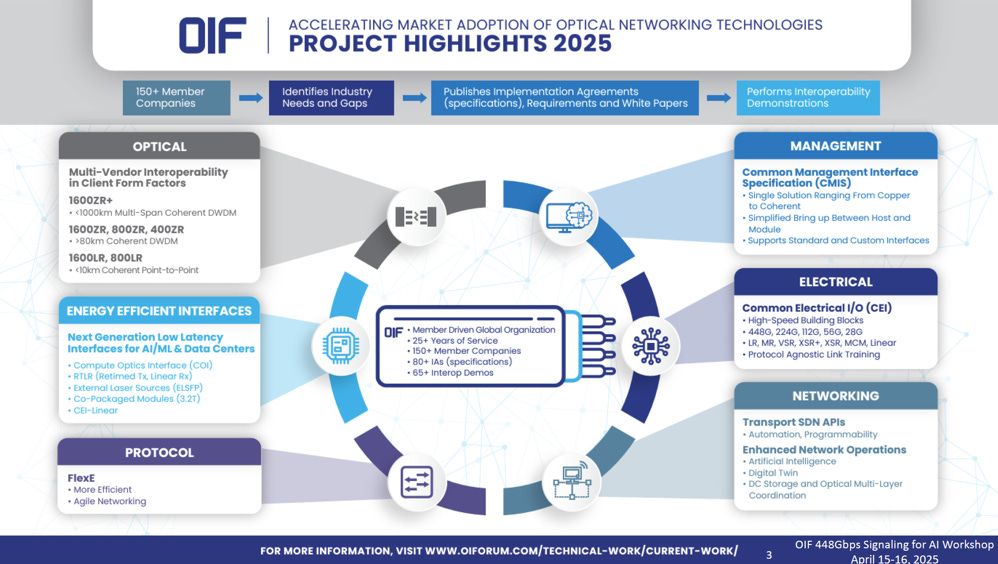
重點技術領域
電氣介面 (Common Electrical I/O, CEI): 定義高速建構模組,如 CEI-448G、224G,這對下一代 AI 網路至關重要
光學 (Optical): 推動多廠商在客戶端外型規格(如 1600ZR+)的互通性。
管理介面 (Management): 制定 CMIS (Common Management Interface Specification),簡化主機與模組間的溝通。
能效介面 (Energy Efficient Interfaces): 針對 AI/ML 資料中心開發低延遲、低功耗介面(如 LPO/CPO 技術)
OIF 與 IEEE 802.3 的關係
OIF 與 IEEE 802.3 雖然都是定義網路規範的組織,但兩者是 「互補且共生」 的關係,而非競爭。
角色定位不同:先鋒 vs. 標準
OIF (加速者/先鋒): OIF 通常走在前面,專注於底層 「電氣介面, CEI)」 的快速定義。它發布的是「實作協議 (IA)」,讓廠商在正式標準定案前就能開發相容的晶片與模組。
例如:圖片中提到的 CEI-224G 和 CEI-448G,就是為了支援未來 Ethernet 速率所做的底層電氣訊號規範。
IEEE 802.3 (官方標準制定者): IEEE 定義完整的 Ethernet 「標準 (Standards)」,包含邏輯層、物理層等。IEEE 的標準制定過程嚴謹且漫長,目的是確保全球範圍的廣泛互通。
技術依賴:CEI 是 Ethernet 的基礎
Ethernet (IEEE 802.3) 的物理層標準,往往會直接引用或參考 OIF 制定的電氣規範 (CEI)。
晶片到模組 (Chip-to-Module) 的橋樑: 當 IEEE 定義 800G 或 1.6T Ethernet 時,交換器晶片如何與光模組溝通的電氣訊號(SerDes),通常是參考 OIF 的 CEI 規範。
實例:
IEEE 802.3df/dj (1.6T Ethernet) 需要單通道 200G/224G 的技術。
這直接對應到 OIF 正在進行的 CEI-224G 專案。
同樣地,IEEE 未來的 400G 單通道研究,也將依賴 OIF 目前啟動的 CEI-448G 作為基礎。
互通性測試 (Interop)
OIF 的另一個重要功能是舉辦 Interop Demos。在 IEEE 標準正式發布前,OIF 會先讓各家廠商帶著自己的原型機(晶片、光模組、線纜)進行對接測試。這些測試結果會回饋給業界,幫助 IEEE 標準更成熟,也讓市場對新技術更有信心。
1.3. 速度數值差異
802.3dj: 212Gbps/lane vs. 200Gbps/lane
使用者要的是 200G (Data Rate): 這是淨流量。
線路必須跑 212.5G (Line Rate): 為了保證訊號在高頻下的正確性,物理層必須加入 FEC (前向錯誤更正碼, RS(544,514)) 和Transcoding(257B/256B)。這多出的 12.5G 就是用來裝這些物理開銷(Overhead)。

OIF CEI-224Gbps vs. IEEE 802.3dj 212Gbps
OIF 叫 224G (標稱值): 這是一個「規格級別」的統稱。代表這顆 SerDes 晶片的能力上限約在 224G,可以向下支援 Ethernet 的 212.5G,也可以支援其他協定。
IEEE 叫 212.5G (精確值): 這是乙太網路協議中定義的「實際工作頻率」。
InfiniBand 和 ITU-T OTN 不再單獨開發獨有的物理層,而是直接「搭便車」,沿用 IEEE 定義好的 PHY,以分攤高速SerDes開發成本
1.4. Ethernet命名規則
Ethernet 的命名規則看似複雜,其實是遵循一個標準公式:nTYPE-LLLm。
只要拆解這個公式,就能立刻知道該介面的速度、傳輸介質、距離以及通道數量

n (Data Rate):傳輸速率
這是最直觀的部分,代表介面的頻寬。
例如:100G (100 Gbps), 400G, 800G 等
TYPE (Modulation Type):調變類型
BASE:代表 Baseband (基頻) 傳輸。目前絕大多數乙太網路標準都使用 BASE。
L (First Letter):介質或波長 (關鍵分類)
這是辨識該介面用途(是用銅線還是光纖?跑多遠?)最重要的字母:
電氣/銅線介面:
C (Copper): Twin axial Copper。通常指 DAC (Direct Attach Cable) 銅纜,用於機櫃內短距連接。
K (Backplane): 背板。指訊號在 PCB 電路板上傳輸,不用纜線,用於機箱內部刀鋒伺服器或模組間的連接。
T (Twisted pair): 雙絞線。即傳統的 RJ-45 網路線。
光纖介面 (依波長/距離區分):
S (Short): 短波長 (850 nm)。搭配多模光纖 (Multimode),距離較短(如 SR)。
L (Long): 長波長 (1310 nm)。搭配單模光纖 (Single mode),距離較長(如 LR)。
E (Extra long): 超長波長 (1550 nm)。用於超長距離傳輸(如 ER)。
F (Fiber): 通用光纖標示(較少見,通常會指定 S, L, E)。
(補充:雖然紅框未列出,但在左側範例中有出現 V (Very Short) 和 D (DR),分別代表極短距和資料中心內距)。
L (Second Letter):編碼方式
R (Scrambled): 代表使用 64B/66B (或其衍生的 256B/257B) 擾碼編碼。這是現代高速乙太網路最主流的編碼。
X (External): 使用外部來源編碼 (如 8B/10B),常見於較舊的標準。
m (Last Number):通道數量 (Lanes)
代表由幾條實體通道(Lanes)組成這個總頻寬。
無標示 (空白): 1 條通道 (Serial)。
4: 4 條通道。
8: 8 條通道。
實戰解讀範例 (根據圖片左側列表)
800GBASE-KR8
800G: 速率 800 Gbps。
K: Backplane (背板傳輸,機箱內 PCB 走線)。
R: Scrambled coding。
8: 由 8 條 100G 的通道組成。
800GBASE-CR8
C: Copper (DAC 銅纜)。
意思: 用 8 條銅纜通道連接的 800G 介面。
800GBASE-SR8
S: Short wavelength (短距光纖)。
意思: 使用多模光纖的 800G 介面,通常距離在 50m~100m 左右(參考左下角表格,SR 在 OM4 光纖可達 100m)。
800GBASE-VR8
V: Very Short (極短距)。因應資料中心內部更密集的 Server-to-TOR (Top of Rack) 連接需求,為了降低成本和功耗而生的規格
意思: 比 SR 更短的光纖連接,通常用於 30m~50m 範圍(參考左下角表格)。
1.5. Ethernet結構
這張圖表 非常清晰地展示了 IEEE 802.3 標準下的 Ethernet 結構,特別是將 OSI 模型的「實體層 (Physical Layer)」 拆解成了更細部的功能區塊:
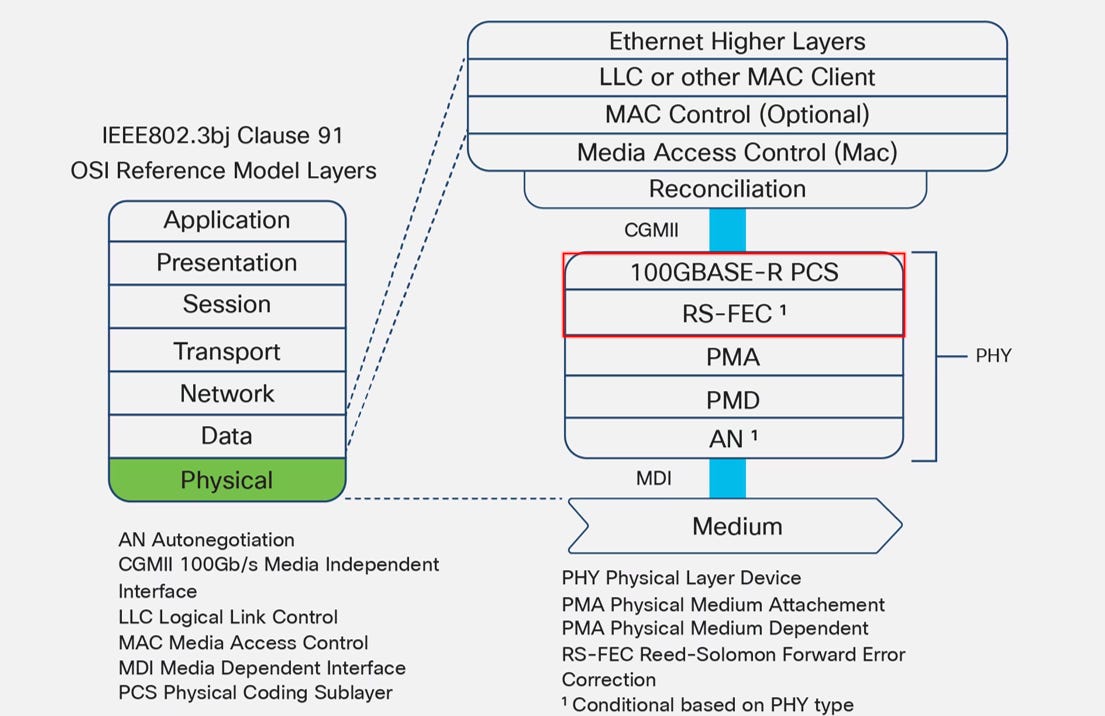
簡單來說,它就像一個**「精密的物流中心」**流水線:
MAC (大腦 / 訂單處理):
位於最上層。只負責邏輯控制(如:這筆資料要寄給誰、MAC 地址是幾號),完全不關心外面是用光纖還是銅線傳輸
PCS + FEC (包裝 / 加固): 數位訊號處理的核心
PCS (編碼): 把資料切塊並編上序號 (64B/66B 或 256B/257B),確保接收端能讀懂。
RS-FEC (防護): 加上糾錯碼。因為高速傳輸路上一定會有雜訊導致資料破損,這一層負責先加上「修復工具包」,讓接收端能自動修復錯誤。
PMA + PMD (卡車 / 運輸): 位於最底層。
PMA (搬運): 把平行的數位資料轉成超高速的序列訊號 (SerDes)。
PMD (驅動): 實際接觸線材的介面,負責把訊號打入中。
Ethernet 運作的流水線: MAC (打包裹) -> PCS (寫編號/編碼) -> FEC (加防撞泡棉/糾錯) -> PMA (裝上卡車/序列化) -> PMD (開上高速公路/傳輸)。
2. Transceiver Update
2.1. 架構
以106/112 Gbps (即單通道 100G) 的設計為例,介紹高速 SerDes Transceiver (收發器) 的內部架構。 (參考EP23. 448G SerDes介紹)
這是一個非常經典的 ADC-based SerDes 架構圖。在高速訊號(如 112G PAM4)中,這是目前的主流設計。(參考EP29. PCIe 7.0 )
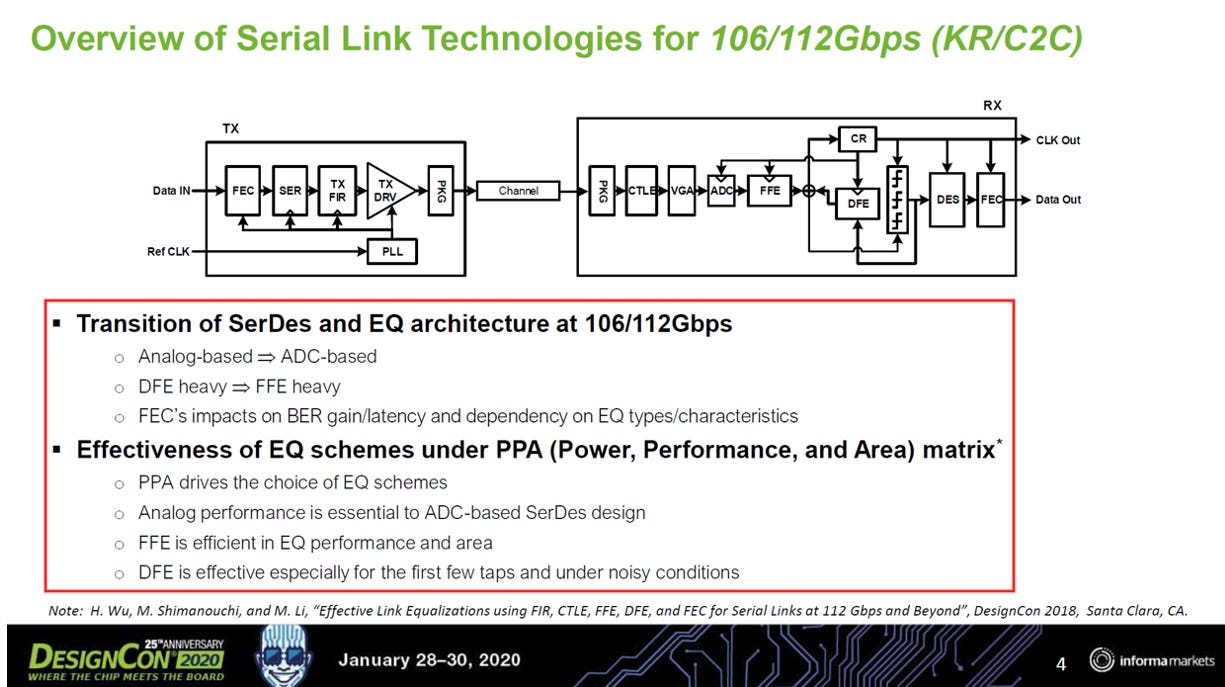
發送端 (TX - Transmitter)
左側方塊是發送端,負責將數位資料「發射」出去。
FEC (Forward Error Correction): 先把資料加上糾錯碼。
SER (Serializer): 序列化。將低速、平行的內部資料流,轉成單條高速的序列訊號。
TX FIR (Finite Impulse Response filter): 這是發送端的等化器(Pre-emphasis)。
目的: 因為預知訊號在傳輸過程會衰減,所以先在發送端「預先扭曲」訊號(例如增強高頻部分),抵消通道的損耗。
TX DRV (Driver): 驅動器。增強訊號強度,將電壓打入通道
接收端 (RX - Receiver)
右側方塊是接收端,這是設計最複雜、最困難的地方。它的任務是從充滿雜訊的通道中把訊號「救回來」。
A. 類比前端 (Analog Front End)
CTLE (Continuous Time Linear Equalizer): 第一道濾波器。這是一個類比電路,負責初步補償高頻訊號的衰減。
VGA (Variable Gain Amplifier): 可變增益放大器。調整訊號的「音量」(電壓擺幅),確保訊號強度剛好適合進入 ADC,不會太大(削波)或太小(被雜訊淹沒)。
B. 數位核心 (The ADC Revolution)
這是 112G 世代最大的變革點。
ADC (Analog-to-Digital Converter):
在以前的低速時代(NRZ),訊號處理多在類比領域完成。
但在 112G PAM4 時代,訊號太複雜,必須用ADC 將類比電壓直接取樣成數位數值。
一旦變成數位訊號(0101...),就可以利用強大的 DSP(數位訊號處理器)來運算。
FFE (Feed Forward Equalizer): 數位等化器。在數位領域消除碼間干擾 (ISI)。圖中註解提到,現在的架構趨勢是 “FFE heavy”,意即依賴 FFE 來處理大部分的失真。
DFE (Decision Feedback Equalizer): 決策回授等化器。用來消除剛判斷完的訊號對下一個訊號的殘留干擾。
CR / CDR (Clock Recovery): 從雜亂的數據中提取出乾淨的時脈 (Clock),讓系統能同步運作。
關鍵技術轉型 (Transition at 112Gbps)
紅框內的文字揭示了從 56G 到 112G 的三大設計典範轉移:
Analog-based → ADC-based:
過去: 依靠類比電路判斷 0 或 1。
現在: 就像拍一張高解析度照片 (ADC),然後用 Photoshop (DSP) 修圖。這樣可以處理更複雜的 PAM4 訊號與雜訊。
DFE heavy → FFE heavy:
過去: 依賴強大的 DFE 來消除反射。但 DFE 在高速下很難做(Timing 閉合困難)。
現在: 轉而依賴長抽頭的 FFE(線性等化器),雖然 FFE 會放大雜訊,但配合強大的 FEC 和 DSP 是更有效率的解法。
PPA (Power, Performance, Area) 的權衡:
雖然 ADC 架構功耗較高,但為了達到 112G 的性能要求(Performance),這是必要的代價。
FFE 相較於複雜的 DFE,在晶片面積(Area)上更有效率。
Equalization (等化器) 在高速傳輸系統中的核心作用
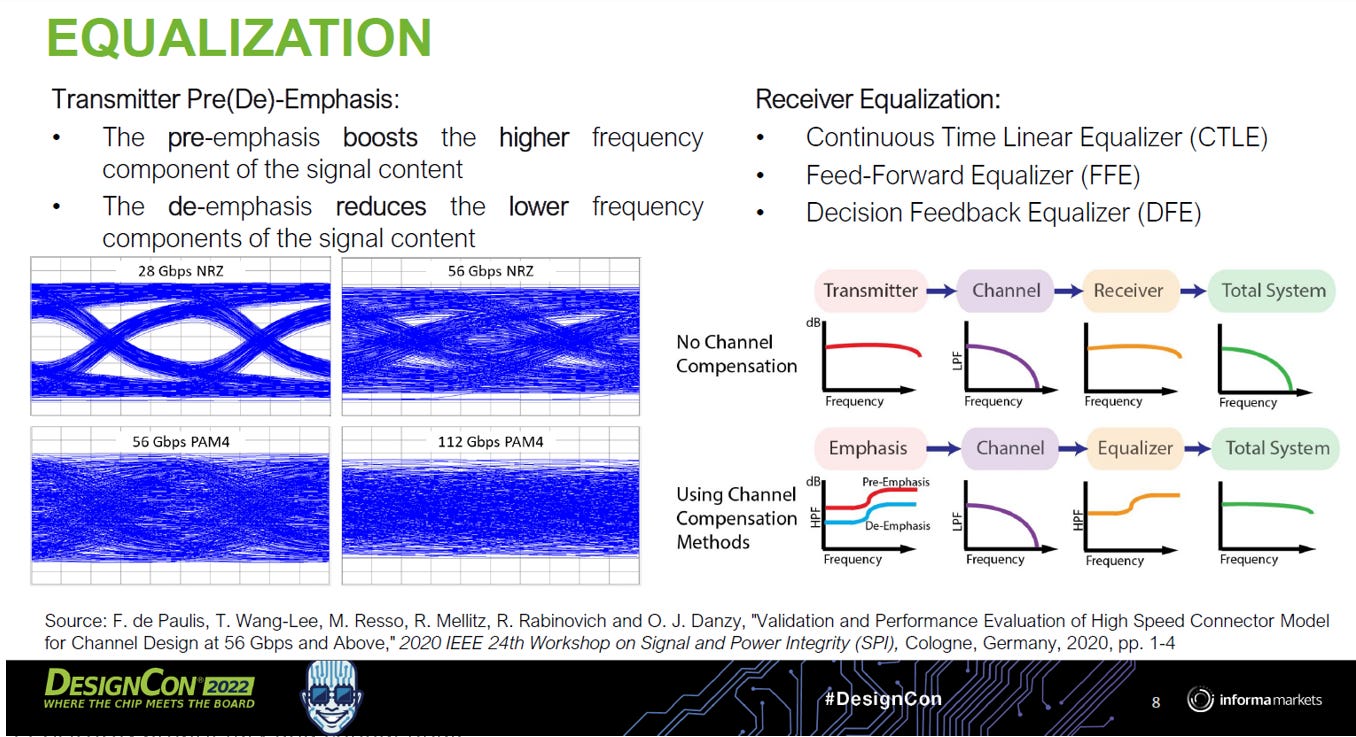
Equalizer 的功能就是「逆轉」傳輸通道造成的訊號損傷,把閉上的「眼睛」重新撐開
問題:通道是個「低通濾波器 (LPF)」
物理現象: 當訊號通過 PCB 走線或纜線(Channel)時,高頻成分衰減得特別快,而低頻成分衰減較少。這在物理上就像一個低通濾波器。
後果 (No Channel Compensation): 如第一排圖示,原本平坦的發射訊號,經過通道後高頻掉下來了。這會導致訊號邊緣變「糊」,在眼圖上就表現為眼睛閉合(如左側 112G PAM4 的圖,糊成一團雜訊)。
原理:缺什麼,補什麼
Equalizer 的核心數學原理是**「反向補償」**。
既然通道會吃掉高頻,Equalizer 就在高頻「加強」。
目標: 讓「發送端 + 通道 + 接收端」的總頻率響應變回平坦的一條線
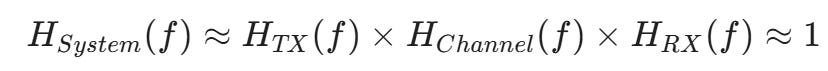
實作:發射端與接收端的聯手夾擊
A. 發射端 (Transmitter) - 預知與預強
在訊號送入爛通道之前,先進行「預處理」。
Pre-emphasis (預加強): 直接增強訊號的高頻成分(Boost high frequency)。
De-emphasis (去加強): 壓低訊號的低頻成分(Reduce low frequency)。這通常比較容易實現,因為降低振幅比放大振幅(需要更多電壓餘裕)簡單。
效果: 您可以看到右下角第二排的第一個圖,發送出的訊號不再是平的,而是高頻翹起來的,為了抵消接下來的路損。
B. 接收端 (Receiver) - 修正與還原
訊號抵達接收端後,通常已經變形,這時需要 RX Equalizer 來搶救。
CTLE (連續時間線性等化器): 類比電路。它是一個高通濾波器,專門放大高頻,把被通道壓扁的高頻訊號拉回來。
FFE (前饋等化器): 數位/類比皆可。利用延遲線消除 ISI (碼間干擾)。
DFE (決策回授等化器): 利用「已經判斷出的值」來預測並抵消對下一個 bit 的干擾。它非常強大,因為它不會像 CTLE 那樣放大雜訊。
2.2. SNDR(Signal-to-Noise-and-Distortion Ratio)
從 NRZ 演進到 PAM4,訊號的「敵人」從時間軸上的抖動 (Jitter) 變成了 電壓軸上的雜訊 (Noise/Distortion)。(參考EP29. PCIe 7.0 )
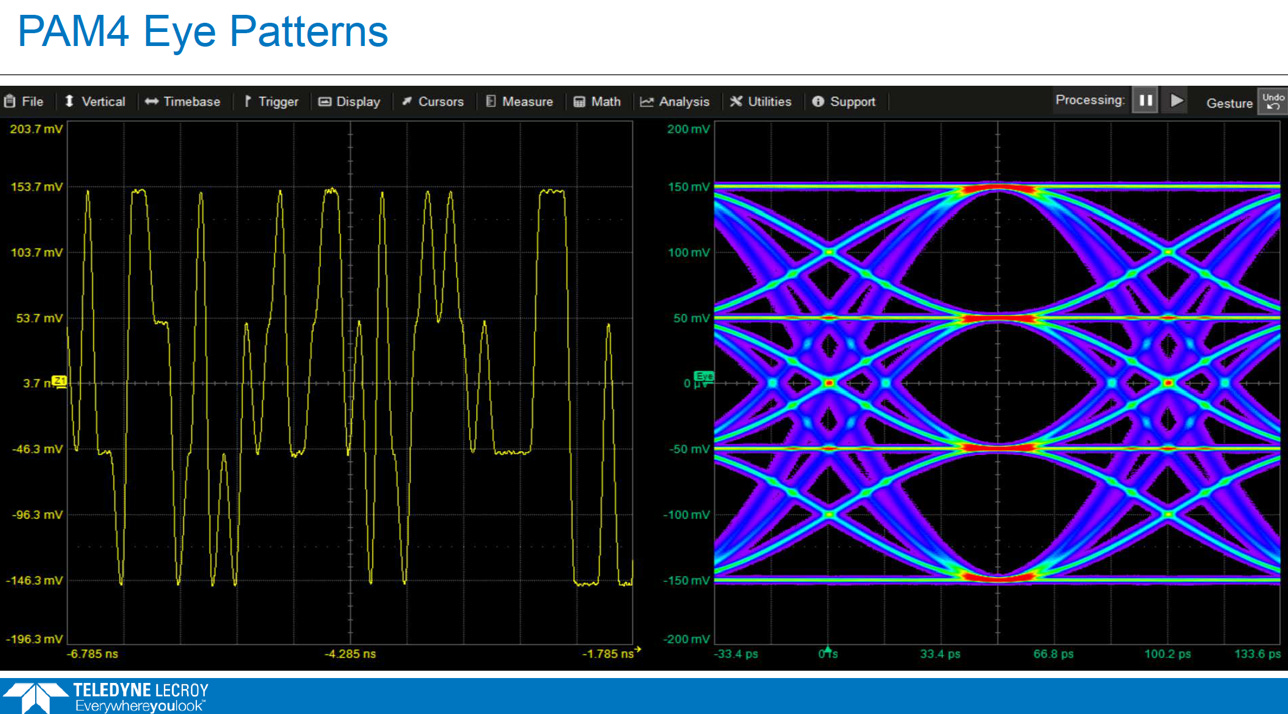
為什麼重點變了? (Jitter vs. Noise)
NRZ 時代 (只有 0, 1):
眼圖只有一個大眼睛。電壓餘裕(Voltage Margin)很大,訊號很強壯,不怕一點點雜訊。
致命傷: 時脈如果不準(Jitter 太大),會在邊緣取樣錯誤。所以大家都在拼命算 TJ, RJ, DJ。(參考EP28. Jitter)
PAM4 時代 (00, 01, 10, 11):
眼圖變成了三個咪咪眼。電壓區間被切成 1/3,每個眼睛的高度(Eye Height)只剩下原本的 33% 甚至更少。
致命傷: 只要電路上有一點點雜訊(Noise)或非線性失真(Distortion),眼睛就閉上了。這時光看 Jitter 已經不夠,必須看「垂直方向」乾不乾淨。
SNDR 的核心概念:把「好訊號」跟「壞雜訊」分開
SNDR (Signal-to-Noise-and-Distortion Ratio) 的目的,就是用一個數字告訴你:「你的訊號裡,有用的成份比沒用的雜訊強多少?」
公式如下

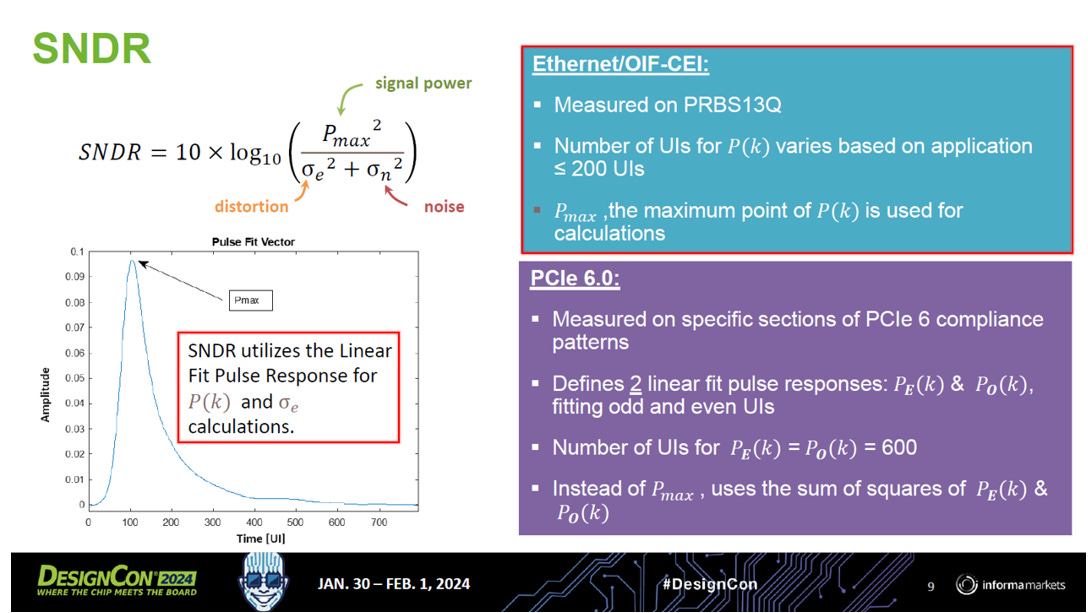
Ethernet vs. PCIe 6.0
Ethernet / OIF-CEI (網通標準):
計算長度: 脈衝響應 P(k) 最長算到 200 UIs。
訊號強度: 直接取脈衝的最高點 Pmax 來當分子。
意義: 網通訊號經過長距離傳輸,著重於主訊號的峰值強度能否蓋過雜訊。
PCIe 6.0 (匯流排標準):
計算長度: 更長,算到 600 UIs。
精細度: 因為 PCIe 更加敏感,它把 Pulse 分成 奇數 PO 和 偶數 PE 兩組來擬合。
訊號強度: 不只看最高點,而是看整個脈衝響應的平方和 (Sum of Squares)。
意義: 這能更全面地評估包含反射在內的總能量品質。
2.3. LFPR(Linear Fit Pulse Response, 線性擬合脈衝響應)
計算 SNDR 的核心確實是**「先求出完美的標準,再反推雜訊」**,流程如下:
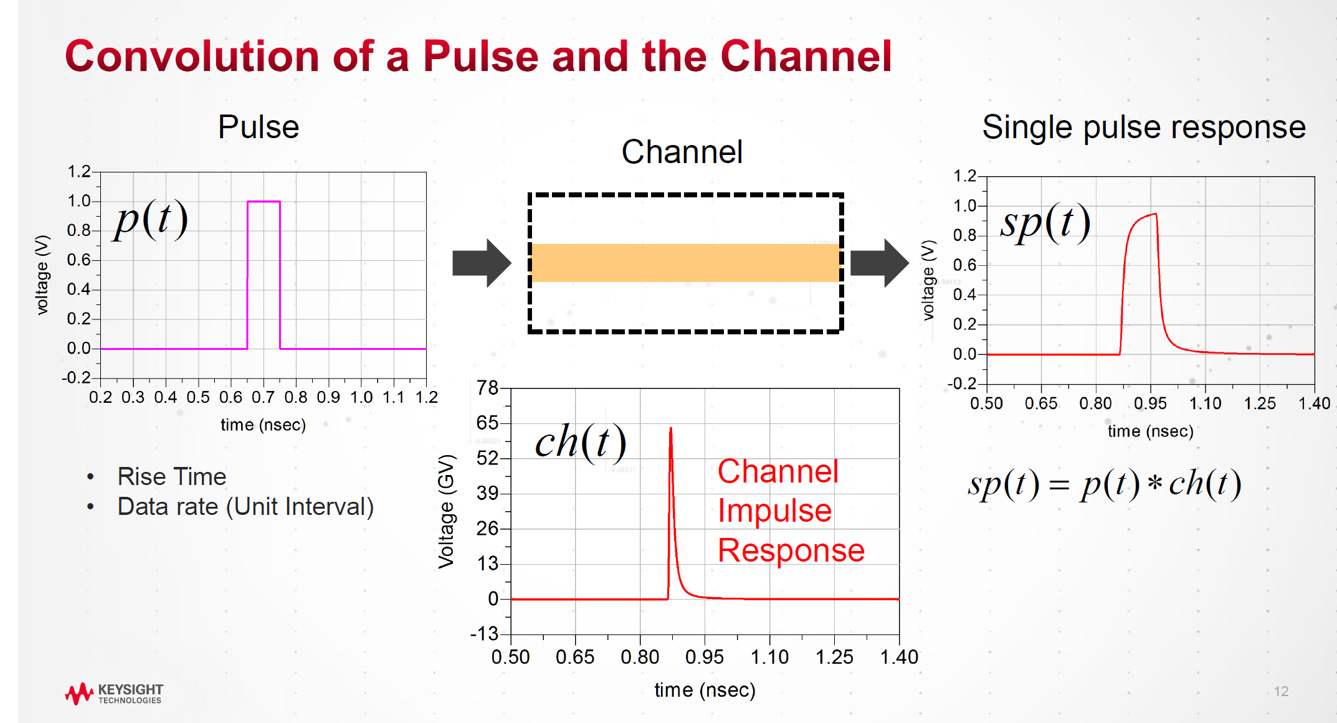
假設線性非時變 (LTI, Linear Time Invariant):
認定訊號傳輸遵循「卷積 (Convolution)」原理,即輸出訊號是由無數個單脈衝響應 ( SP(k) )(Single Bit Response, SBR) 疊加而成的。(以下討論,用P(k)表示 SBR)
擬合標準 (Pmax):
利用 LFPR 數學方法(最小平方法),從充滿雜訊的實測波形中,逆向還原出那條「乾淨的理想脈衝曲線 P(k) 」。這條曲線的最高點,就是代表訊號強度的Pmax。
分離雜訊 (Noise Extraction):
訊號 (Signal): 即算出來的Pmax。
雜訊 (Noise/Distortion): 用「實際量到的波形」減去「還原的理想波形」,剩下的殘差就是雜訊。
兩者相比,即得到 SNDR。
LFPR 物理意義
LFPR 的運算過程,可以不用微分的數學方式,求出脈衝曲線 P(k):
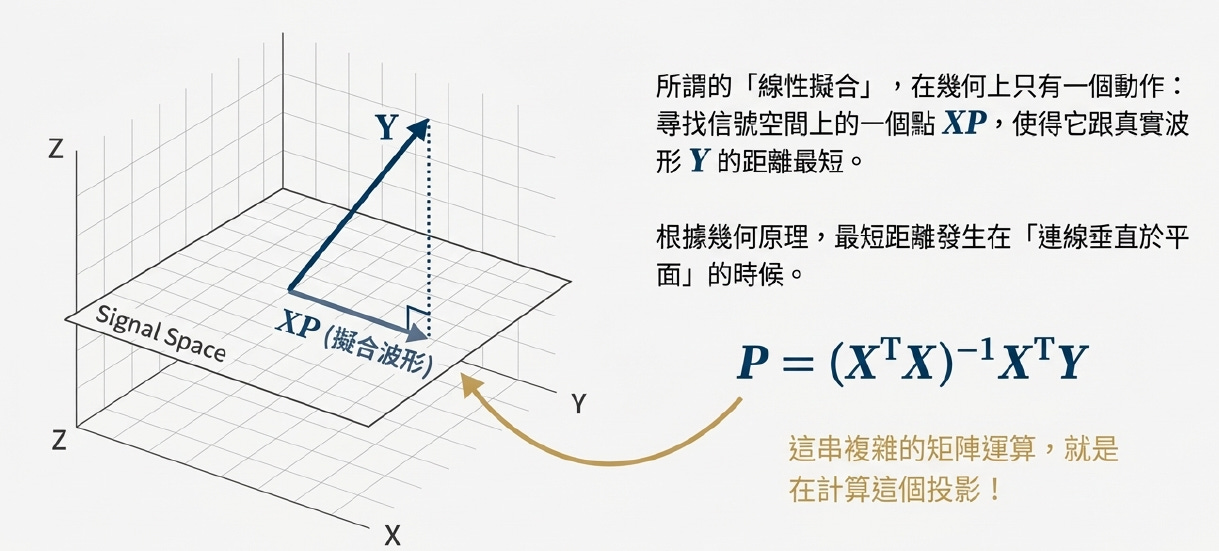
在物理與幾何上就是將**「真實量測到的波形」,垂直投影到一個由「理想訊號」**所構成的平面上,藉此把「好的訊號」跟「壞的雜訊」切得乾乾淨淨。
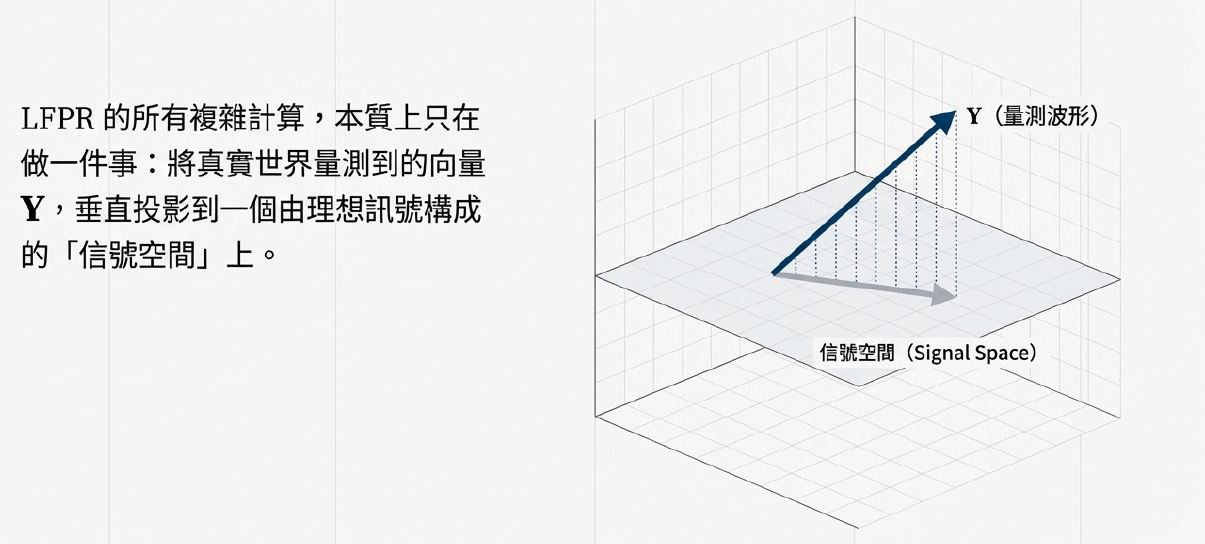
核心動作:線性擬合 = 垂直投影
LFPR 的數學計算(最小平方法),本質上只做了一個幾何動作:尋找最近的影子 。
它將真實世界充滿雜訊的波形向量 (Y),垂直投影到一個理想的「信號空間 (Signal Space)」上 。
投影下來的那個「影子」,就是我們要的純線性成分 (XP)。
三個關鍵向量的物理/幾何對照
將公式 Y = XP + E 轉化為直觀的幾何圖像
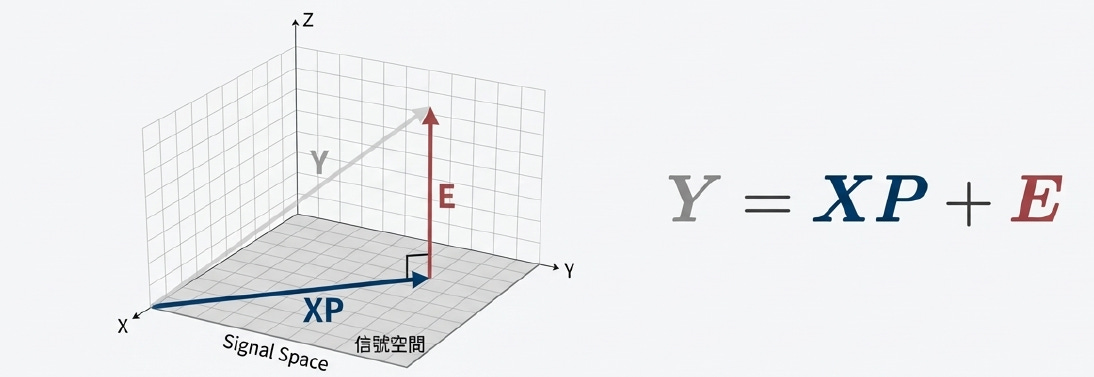
Y (觀察向量 / 量測波形):
物理意義: 示波器抓到的真實電壓,混雜了訊號、雜訊和失真 。
幾何圖像: 懸浮在空間中的一個箭頭,沒有落在平面上 。
XP (投影向量 / 擬合波形):
物理意義: 純線性成分,即 SNDR 的分子(Signal)6。
幾何圖像: 躺在「信號空間」平面上的影子,是 Y 在這個理想世界中最像的分身 。
E (正交誤差向量 / 雜訊):
物理意義: 非線性失真與雜訊,即 SNDR 的分母(Noise)
幾何圖像: Y 到平面的**「垂直高度」**。這是所有線性模型無法解釋的殘餘
正交性: 為什麼這個觀點重要?
這不只是畫圖好看,而是有嚴格的物理保證:正交性 (E和XP內積為0)
因為投影是「垂直」的,所以分離出來的誤差 E與信號空間 XP 完全不相關 。
這保證了我們已經把所有能算作「線性訊號」的東西都榨乾了(萃取到 XP裡),剩下的 E 就是純粹的垃圾(非線性雜訊 + 熱雜訊)。
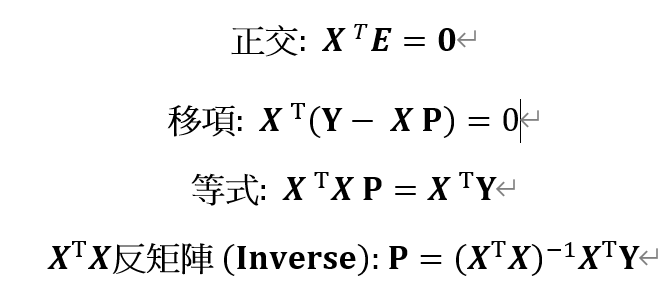
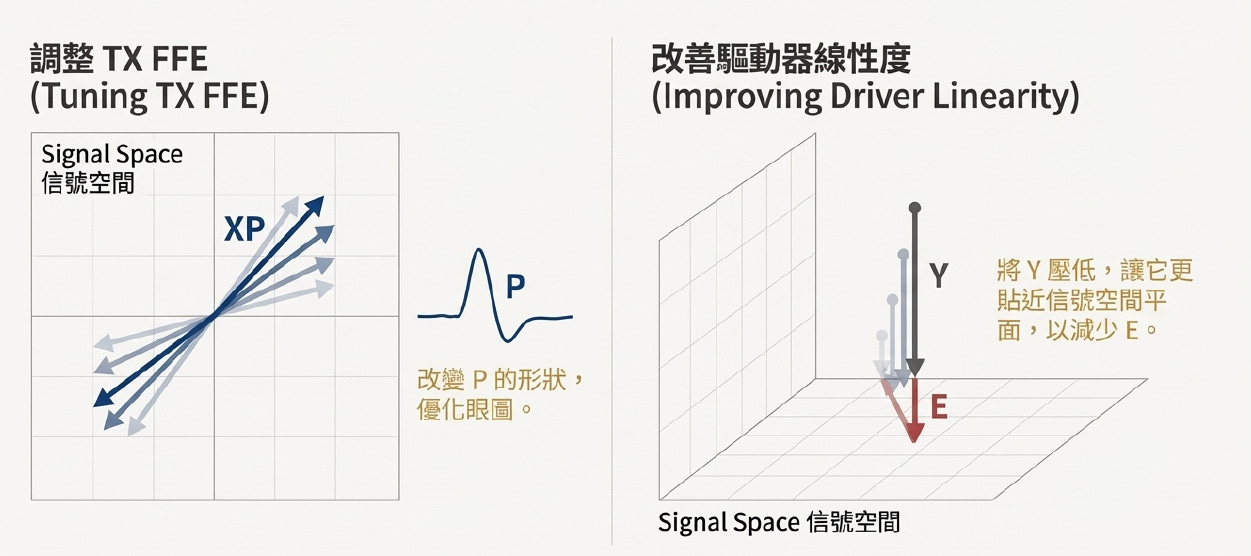
工程調校的幾何意義
調整 TX FFE: 就是在改變影子的形狀 P,讓它更漂亮 。
改善驅動器線性度: 就是把懸浮的 Y 壓低,讓它離地面(信號空間)更近,直接減少高度 E(即減少雜訊) 。
LFPR 就是利用最小平方法,將混雜的真實訊號 Y,投影到理想信號空間 X,從而將線性響應 (XP) 與 非線性雜訊 (E) 完美分離的幾何過程 。
3. AI Applications
3.1. Infrastructure
典型的高效能 AI 資料中心網路架構(AI Data Center Networking Infrastructure)
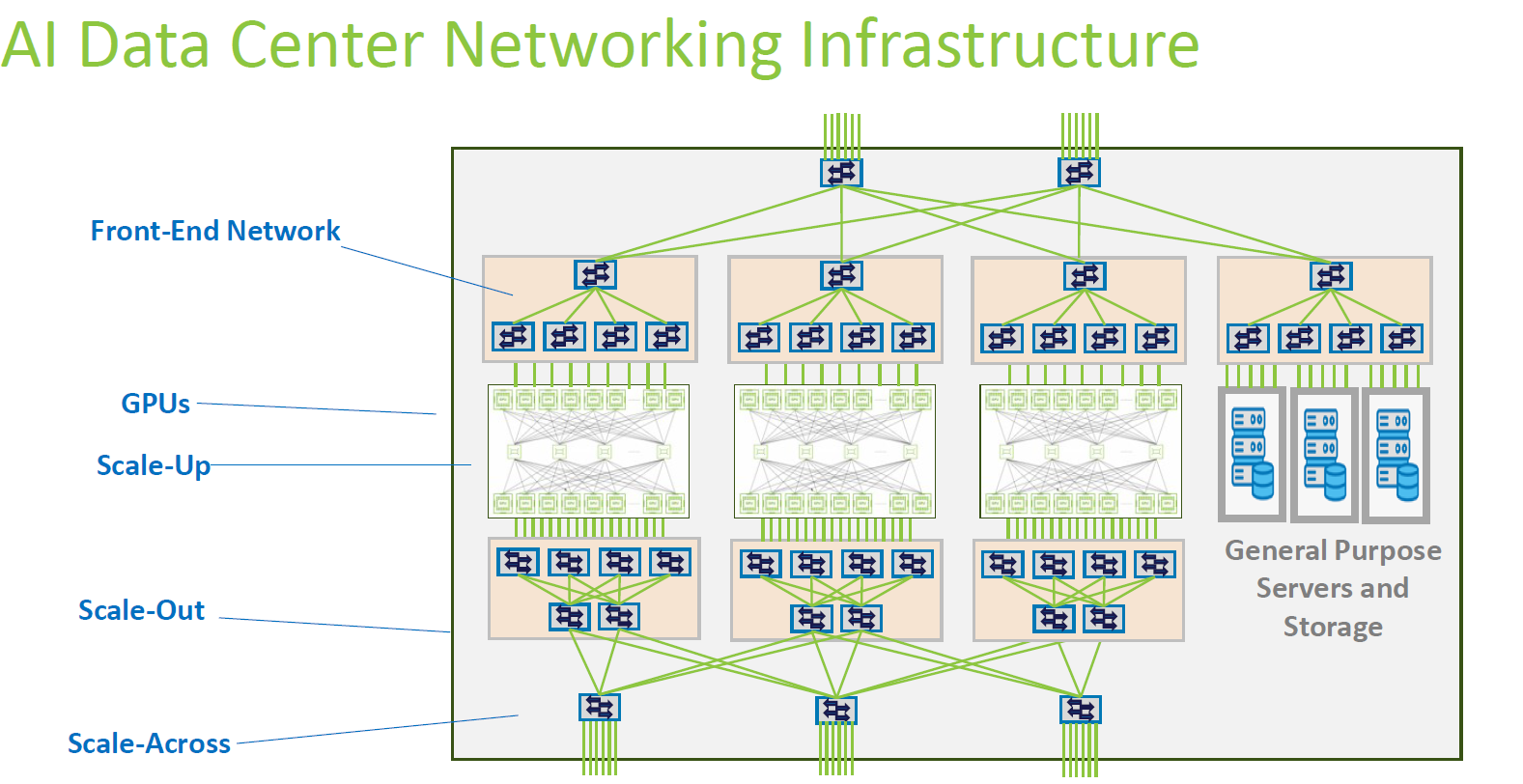
前端與後端網路的分離 (Front-End vs. Back-End)
Front-End Network (前端網路):圖中上方的網路
功能:負責一般的控制平面(Control Plane)流量、用戶接入、以及與通用伺服器(General Purpose Servers)和存儲設備(Storage)的數據傳輸。
協定:通常使用標準的 Ethernet (TCP/IP)。
特點:強調兼容性與管理便利性,頻寬需求相對較低(相較於 AI 計算網路)。
Back-End Network (後端網路/AI Fabric):圖中下方連接 GPU 的網路。
功能:專門用於 GPU 之間的參數同步(Parameter Synchronization)與梯度交換(Gradient Reduction)。
特點:極致的高頻寬、低延遲、無損傳輸(Lossless)。
三種擴展維度 (Three Dimensions of Scaling)
Scale-Up (節點內擴展):
位置:圖中 “GPUs” 區塊內部的密集連線。
意義:指的是單一台伺服器(Node)內,多個 GPU 之間的互連。
技術:通常採用私有高速協定,如 NVLink/NVSwitch, UALink, 或OCP ESUN/SUE。這讓多顆 GPU 能共享記憶體空間,行為像是一顆巨大的虛擬 GPU。
Scale-Out (節點間擴展):
位置:連接不同 GPU 伺服器機箱的第一層交換機網路。
意義:將多台 AI 伺服器組成一個 Pod 或 Cluster。
技術:通常使用 InfiniBand,RoCEv2 (Ethernet) 或 UEC。這裡的重點是利用 RDMA 技術降低 CPU 負載並減少延遲。
Scale-Across (跨叢集/跨層級擴展):
位置:圖中最底層的網路連接。
意義:指將規模進一步擴大,連接多個 Pod 或將算力擴展到整個資料中心層級(Spine-Leaf 架構的更上層)。這通常涉及到長距離的光纖傳輸(Coherent modulation)與更複雜的流量調度。
3.2 Converged Fabric ?
軟體工程師的痛點與期待(from Meta)
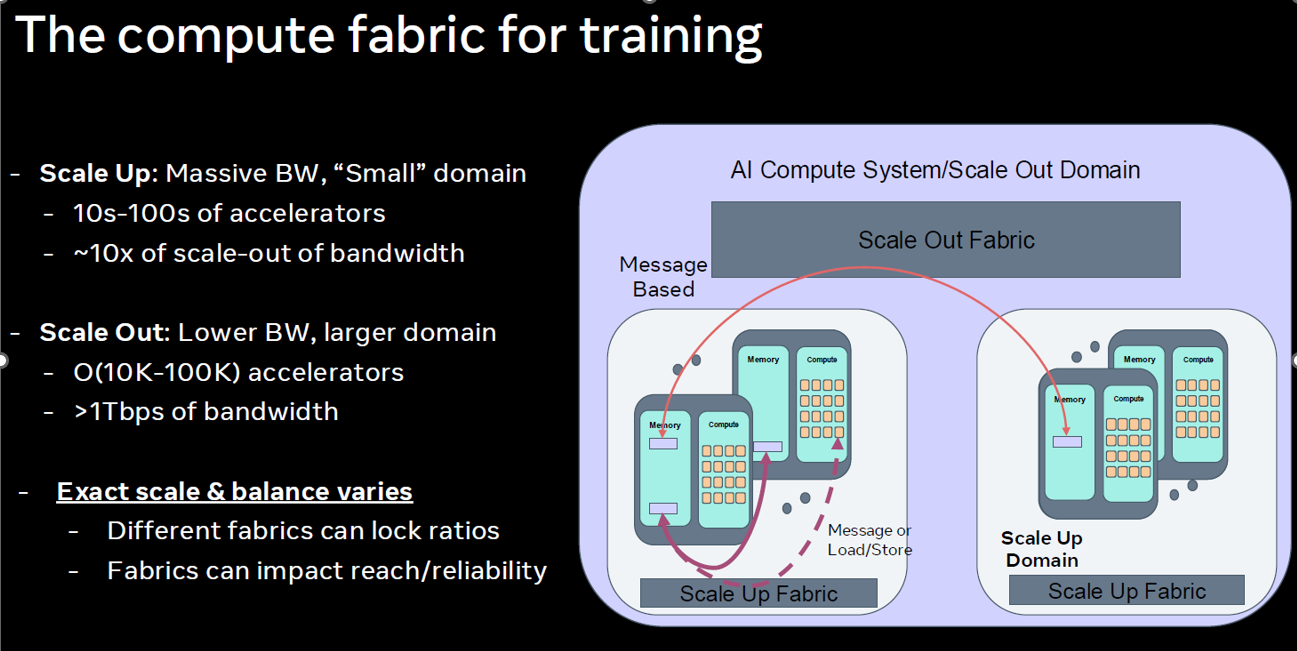
目前 AI 叢集被物理限制割裂成兩個世界,導致軟體開發極其痛苦:
Scale-Up (單機/機櫃內):
行為:Load/Store (記憶體語義, Memory Semantic)。
體驗:像存取本機記憶體一樣簡單、快速。GPU 之間可以直接讀寫對方的 HBM (如 NVLink)。
Scale-Out (跨機櫃):
行為:Message Based (網路語義, Network Semantic)。
體驗:必須將資料打包、傳送、解包 (Send/Recv)。延遲高,且需要複雜的通訊函式庫 (MPI/NCCL, Message Passing Interface/NVIDIA Collective Communications Library)。
SW 的期待:軟體工程師希望消除這條界線。他們夢想中的 Converged Fabric 是讓整個資料中心(成千上萬顆 GPU)看起來像一台擁有統一記憶體的超級電腦。無論資料在哪,都能用 Load/Store 指令直接存取,無需關心底層是走銅線還是光纖。
要達成這個夢想,網路必須同時具備以下的特性(OCP 2025 Summit):

兼具兩種語義:既能跑網路封包(Network Semantic),又能跑記憶體指令(Memory Semantic) 。
小封包低延遲:記憶體存取通常只有 64B~256B,網路通常處理 1500B 以上。用大卡車載一根針,效率極差。
極致可靠性:網路掉包重傳是可以接受的,但記憶體讀取失敗會導致程式崩潰 (Crash)。
BRCM/OCP的解決方案:
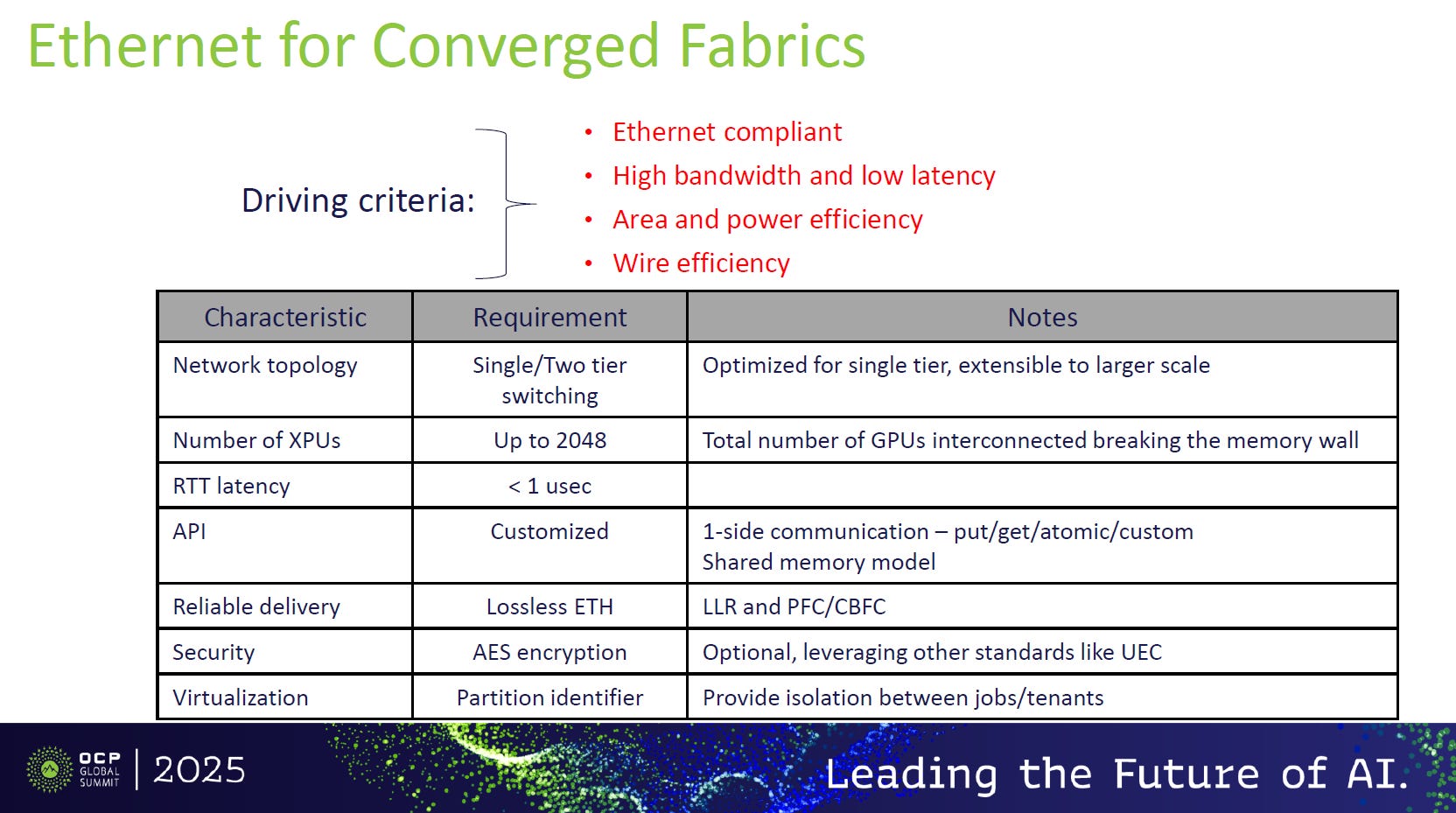
開放陣營 (Open Standard) 對抗 NVIDIA 封閉生態的終極戰略:「全乙太網 AI 架構 (All-Ethernet AI Infrastructure)」: SUE/ESUN + UEC = Converged Fabric
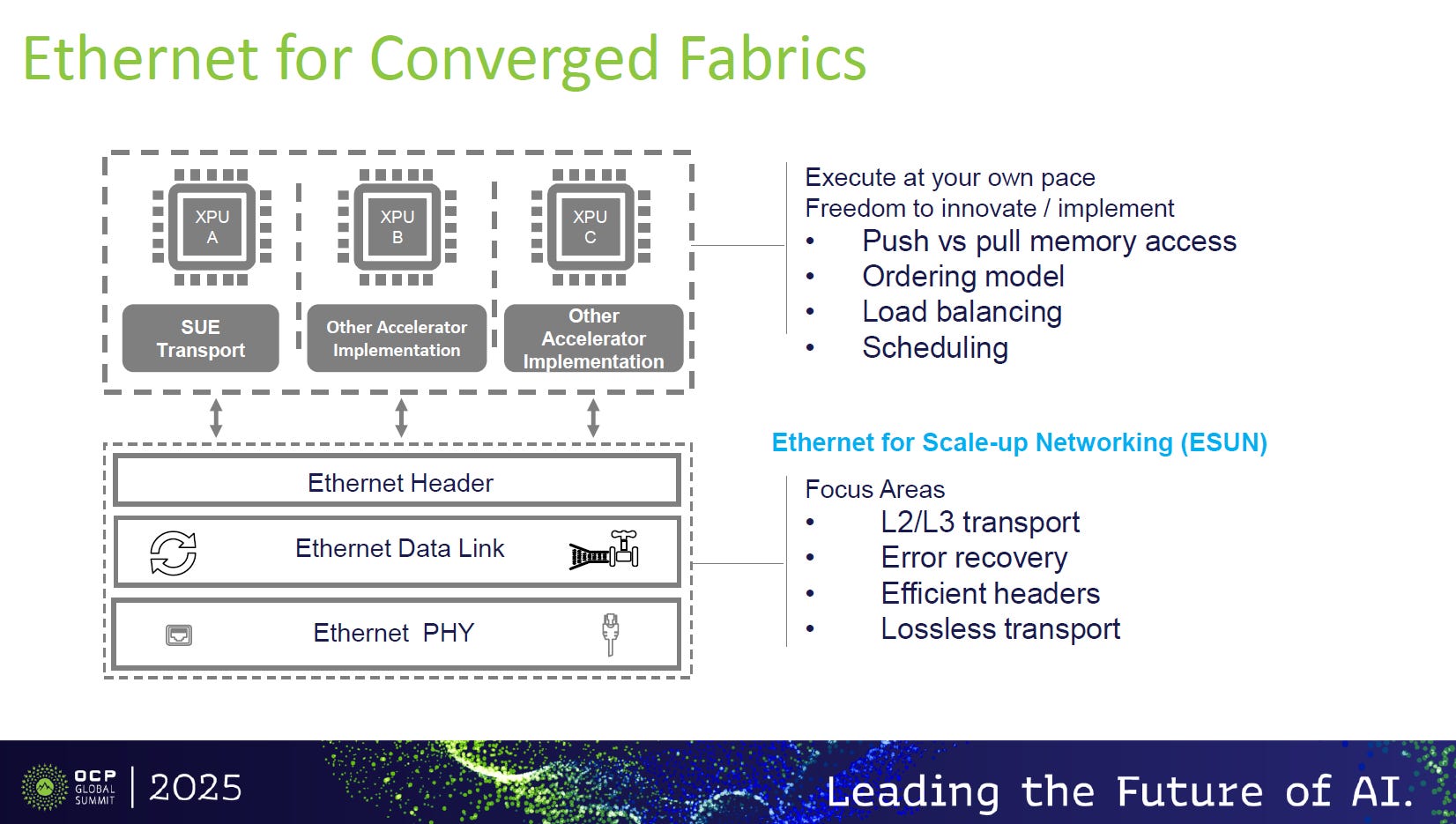
Scale-Up 端:SUE / ESUN (取代 NVLink)
定位:記憶體擴展 (Memory Semantic)。
任務:在機櫃或 Pod 層級 (Up to 2048 XPUs) 模擬「共享記憶體」。
核心能力:
提供 < 1us 的超低延遲與硬體級無損保證 (LLR)。
讓乙太網支援 Put/Get/Atomic 指令,軟體寫入遠端就像寫入本地。
Scale-Out 端:UEC (取代 InfiniBand)
定位:網路擴展 (Network Semantic)。
任務:在跨機櫃、跨資料中心的萬卡規模,提供最高效率的傳輸。
核心能力:利用 Packet Spraying (封包噴灑) 與先進擁塞控制,解決傳統乙太網在長距離負載下的頻寬浪費問題,達到 90%+ 的鏈路利用率。
Converged Fabric (融合架構)
無縫接軌:資料從 GPU 出來都是乙太網封包。短距離走 SUE 協定 (低延遲),長距離走 UEC 協定 (高吞吐),中間不需要透過 Gateway 進行昂貴的協定轉換 (Translation Tax)。
統一生態:打破單一廠商鎖定。AMD、Intel 或自研晶片都能透過標準交換機 (如 Broadcom Tomahawk) 組建成高效能叢集。
請參考EP17. SUE簡介,EP21. OCP Global Summit